0x01 参考文章
Go二进制文件逆向分析从基础到进阶——MetaInfo、函数符号和源码文件路径列表
Go二进制文件逆向分析从基础到进阶——Tips与实战案例(包含之前文章的传送门)
主要研究go 1.16.8版本,原因自然是某软件的go version是这个版本,而且只分析了Windows x64。
整个解析基本都是参考的J!4Yu的分析文章,添加了一些golang的源码片段,作为解析的依据,也方便大家针对其他版本的golang进行分析(因为发现自己分析的版本与J!4Yu的分析已经有一些不同了),另外也参照了go_parser编写了自己的解析脚本goparse,虽然现在IDA 7.6支持了golang的解析,但是脚本还是能多解析出一些内容来的。
0x02 moduledata
在源码中的定义是在go\src\runtime\symtab.go
//go 1.16.8
type moduledata struct {
pcHeader *pcHeader
funcnametab []byte
cutab []uint32
filetab []byte
pctab []byte
pclntable []byte
ftab []functab
findfunctab uintptr
minpc, maxpc uintptr
text, etext uintptr
noptrdata, enoptrdata uintptr
data, edata uintptr
bss, ebss uintptr
noptrbss, enoptrbss uintptr
end, gcdata, gcbss uintptr
types, etypes uintptr
textsectmap []textsect
typelinks []int32 // offsets from types
itablinks []*itab
ptab []ptabEntry
pluginpath string
pkghashes []modulehash
modulename string
modulehashes []modulehash
hasmain uint8 // 1 if module contains the main function, 0 otherwise
gcdatamask, gcbssmask bitvector
typemap map[typeOff]*_type // offset to *_rtype in previous module
bad bool // module failed to load and should be ignored
next *moduledata
}
module的介绍可以参考七夕—Go二进制文件逆向分析从基础到进阶——MetaInfo、函数符号和源码文件路径列表中的7.moduledata部分,但是高版本会有一些区别,第一个pcHeader改成了指针,因此只占8字节,参考文章中pcHeader是Slice类型,会占0x18字节。
后续紧跟的funcnametab、cutab、filetab、pctab、pclntable、ftab(PS:pclntable和ftab指向同一个地址)都是分析golang程序有用的,不过可以通过pcHeader中的字段计算出对应的值,因此这个也是我的脚本中用于判断pcheader和moduledata是否有效的依据。
moduledata各字段的offset也可以先通过查找字符串runtime.moduledata,再查找该name结构体的引用来寻找到对应的struct类型,从而确定各字段的类型以及偏移(name结构体,struct类型都在下文中介绍)。
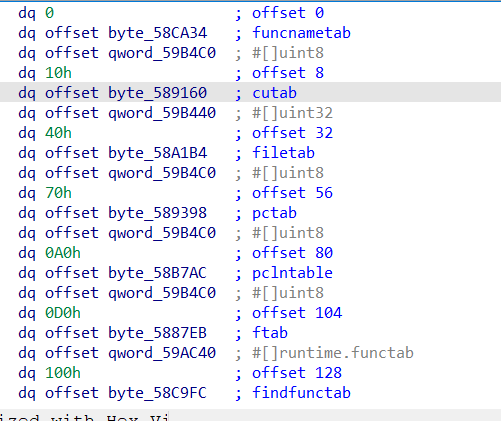
moduledata结构体中对于go逆向有关的信息是pcHeader、typelinks、itablinks,这三个也是我的解析脚本中单独定义类进行解析的。
#moduledata.py
self.pcHeader = pcHeader.pcHeader(self.pcHeader_addr,self.start_addr)
self.typelinks = typelink.TypeLinks(start_addr+ptrSize*40,self)
self.itablinks = itablink.ItabLinks(start_addr+ptrSize*43,self)
0x03 pcHeader
在源码中的定义是在go\src\runtime\symtab.go(go 1.16版本之后存在的定义)
//go 1.16.8
type pcHeader struct {
magic uint32 // 0xFFFFFFFA
pad1, pad2 uint8 // 0,0
minLC uint8 // min instruction size
ptrSize uint8 // size of a ptr in bytes
nfunc int // number of functions in the module
nfiles uint // number of entries in the file tab.
funcnameOffset uintptr // offset to the funcnametab variable from pcHeader
cuOffset uintptr // offset to the cutab variable from pcHeader
filetabOffset uintptr // offset to the filetab variable from pcHeader
pctabOffset uintptr // offset to the pctab varible from pcHeader
pclnOffset uintptr // offset to the pclntab variable from pcHeader
}
其中magic的值在Go 1.16之前是0xFFFFFFFB,Go 1.16到17是0xFFFFFFFA,Go 1.18是0xFFFFFFF0。
通过查看golang源码对比文件src/debug/gosym/pclntab.go(PS:低版本没有pcHeader的定义)可以知道不同版本的magic值(写文档时是Go 1.18)
git diff remotes/origin/release-branch.go1.15 master -- src/debug/gosym/pclntab.go
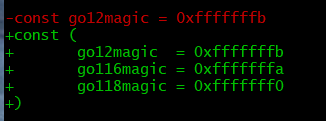
在IDA中,在Names视图中runtime_pclntab,即pcHeader结构体
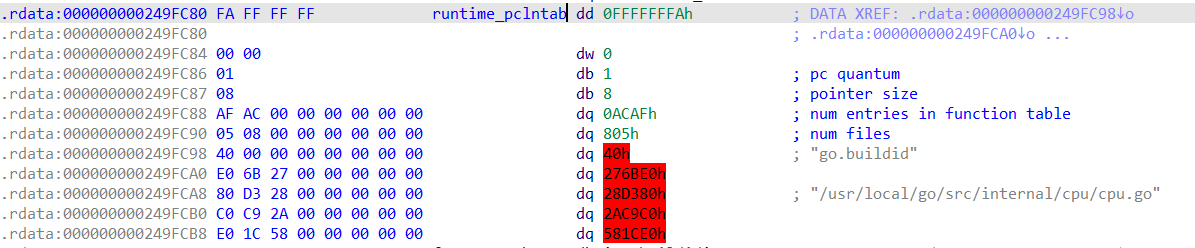
红色的IDA未进行解析(纠正一下,初次分析二进制程序的时候是解析的,使用的是IDA专门为golang设置的offset值,但是重新打开数据库时未识别出该数据库对应的是golang的程序,因此未加载,所以显示红色出错),分别是funcnameOffset~pclnOffset
nfunce和nfiles是funcnametab和filetab的个数
funcnameOffset~pclnOffset都是记录的偏移量,偏移的基址则是pcHeader的首地址,因此moduledata中的tab与pcHeader中的Offset的对应关系如下:(pcHeader.start_addr表示pcHeader的首地址)
moduledata.funcnametab.addr = pcHeader.start_addr + pcHeader.funcnameOffset
moduledata.cutab.addr = pcHeader.start_addr + pcHeader.cuOffset
moduledata.filetab.addr = pcHeader.start_addr + pcHeader.filetabOffset
moduledata.pctab.addr = pcHeader.start_addr + pcHeader.pctabOffset
moduledata.pclntable.addr = pcHeader.start_addr + pcHeader.pclnOffset
moduledata.ftab.addr = pcHeader.start_addr + pcHeader.pclnOffset
3.1 pclntable与ftab
在moduledata中存在两个slice,分别是pclntable和ftab,他们的首地址是一样的,但包含的数据是存在一些区别的。
pclntable包含ftab,在moduledata中定义可以知道pclntable是byte类型的slice,ftab是functab类型的slice,pclntable前面部分的数据即ftab,每条数据都是functab类型,后面即是_func类型的数据,但是每个_func类型数据之间是存在pcdata和funcdata的数据的,根据每个_func中的npcdata和nfuncdata的大小确定,其中pcdata是相对于pctab的偏移量,funcdata是绝对地址。另外需要注意的是golang源码中解析_func主要是通过了另一个结构体funcInfo,因为_func中的数据记录的都是偏移量,计算出绝对地址需要根据moduledata中对应table的首地址(不过解析脚本中是通过pcHeader来计算出的table首地址,原因是pcHeader有magic值,方便进行二进制搜索从而定位)。
//src\runtime\symtab.go
type functab struct {
entry uintptr
funcoff uintptr
}
type funcInfo struct {
*_func
datap *moduledata
}
//src\runtime\runtime2.go
type _func struct {
entry uintptr // start pc
nameoff int32 // function name
args int32 // in/out args size
deferreturn uint32 // offset of start of a deferreturn call instruction from entry, if any.
pcsp uint32
pcfile uint32
pcln uint32
npcdata uint32
cuOffset uint32 // runtime.cutab offset of this function's CU
funcID funcID // set for certain special runtime functions
_ [2]byte // pad
nfuncdata uint8 // must be last
}
functab类型很简单,entry是函数地址,funcoff则是对应的_func类型的地址相对于functab的偏移。另外有一个小的注意点提一下,moduledata中的ftab是slice类型,ftab.len的值相当于记录了函数的个数,而pcHeader中nfunc,同样是记录的函数的个数,实际情况会是ftab.len=pcHeader.nfunc+1,函数的个数是nfunc的值,而ftab.len多1是因为在所有functab之后,还有一个lastpc的指针,占用0x8字节,一个functab占用0x10字节,ftab.len多的1就是需要多存储一个lastpc指针。
_func是了解函数的主要结构体
- entry:函数入口地址
- nameoff:函数名称字符串相对于funcnametab的偏移。
- args:函数参数占用的字节数,此处包含了返回值
- deferreturn:函数中调用call runtime_deferreturn的地址相对于entry的偏移量
- pcsp:没有了解= =
- pcfile:相对与pctab的偏移,用于计算出函数所在文件路径的字符串的地址
- pcln:相对于pctab的偏移,用于计算出函数所在文件中的行数
- npcdata:在nfuncdata后面pcdata数据的个数,每个pcdata占4个字节(在windows 64位的情况下,其他情况未了解)
- cuOffset:该函数所属CU在整个cutab中的起始下标
- funcID:没有了解= =
- nfuncdata:在pcdata后面funcdata数据的个数,每个funcdata占8个字节(在windows 64位的情况下,其他情况未了解)
3.1.1 函数名称计算
pcHeader中计算出funcnametab的首地址,再加上_func.nameoff即可计算出函数名称字符串的地址,解析脚本中代码片段如下:
#func.py
self.funcname = idc.get_strlit_contents(pcheader.funcname_addr+self.nameoff)
golang源代码中解析函数名的代码片段
//src\runtime\symtab.go
func cfuncname(f funcInfo) *byte {
if !f.valid() || f.nameoff == 0 {
return nil
}
return &f.datap.funcnametab[f.nameoff]
}
func funcname(f funcInfo) string {
return gostringnocopy(cfuncname(f))
}
//src\runtime\string.go
func gostringnocopy(str *byte) string {
ss := stringStruct{str: unsafe.Pointer(str), len: findnull(str)}
s := *(*string)(unsafe.Pointer(&ss))
return s
}
//src\runtime\symtab.go
//另一个单独指定nameoff读取funcname的方法
func cfuncnameFromNameoff(f funcInfo, nameoff int32) *byte {
if !f.valid() {
return nil
}
return &f.datap.funcnametab[nameoff]
}
3.1.2 函数所属文件以及行号的计算
pcfile和pcln都是基于pctab的偏移,而读取pctab中的数据,需要了解varint编码和zigzag整数压缩编码。
对于pctab中的值,需要先varint解码,再zigzag解码,最后值加上-1来得到最终的pcvalue,解析脚本中代码片段如下:
#common.py
def read_pcvalue(addr):
val = read_varint(addr)
val = zig_zag_decode(val)
val += -1
return val
def read_varint(addr):
val = 0
shitf = 0
while True:
tmp = ida_bytes.get_byte(addr)
addr += 1
val |= (tmp&0x7f) << (shitf & 31)
if tmp & 0x80 ==0:
break
shitf += 7
return val
def int32(val:int):
return int.from_bytes((val&0xffffffff).to_bytes(4,'little'),'little',signed=True)
def uint32(val:int):
return int.from_bytes((val&0xffffffff).to_bytes(4,'little'),'little',signed=False)
def zig_zag_decode(val):
return int32(-(val&1) ^ (val>>1))
def zig_zag_encode(val):
return (val<<1) ^ (val>>31)
当然知道这些值如何解析是根据golang中的源码得知,golang源码中的片段如下(如果高版本不适用了可再查看对应源码文件来分析):
//src\runtime\symtab.go
func pcvalue(f funcInfo, off uint32, targetpc uintptr, cache *pcvalueCache, strict bool) (int32, uintptr) {
if off == 0 {
return -1, 0
}
// Check the cache. This speeds up walks of deep stacks, which
// tend to have the same recursive functions over and over.
//
// This cache is small enough that full associativity is
// cheaper than doing the hashing for a less associative
// cache.
if cache != nil {
x := pcvalueCacheKey(targetpc)
for i := range cache.entries[x] {
// We check off first because we're more
// likely to have multiple entries with
// different offsets for the same targetpc
// than the other way around, so we'll usually
// fail in the first clause.
ent := &cache.entries[x][i]
if ent.off == off && ent.targetpc == targetpc {
return ent.val, 0
}
}
}
if !f.valid() {
if strict && panicking == 0 {
print("runtime: no module data for ", hex(f.entry), "\n")
throw("no module data")
}
return -1, 0
}
datap := f.datap
p := datap.pctab[off:]
pc := f.entry
prevpc := pc
val := int32(-1)
for {
var ok bool
p, ok = step(p, &pc, &val, pc == f.entry)
if !ok {
break
}
if targetpc < pc {
// Replace a random entry in the cache. Random
// replacement prevents a performance cliff if
// a recursive stack's cycle is slightly
// larger than the cache.
// Put the new element at the beginning,
// since it is the most likely to be newly used.
if cache != nil {
x := pcvalueCacheKey(targetpc)
e := &cache.entries[x]
ci := fastrand() % uint32(len(cache.entries[x]))
e[ci] = e[0]
e[0] = pcvalueCacheEnt{
targetpc: targetpc,
off: off,
val: val,
}
}
return val, prevpc
}
prevpc = pc
}
// If there was a table, it should have covered all program counters.
// If not, something is wrong.
if panicking != 0 || !strict {
return -1, 0
}
print("runtime: invalid pc-encoded table f=", funcname(f), " pc=", hex(pc), " targetpc=", hex(targetpc), " tab=", p, "\n")
p = datap.pctab[off:]
pc = f.entry
val = -1
for {
var ok bool
p, ok = step(p, &pc, &val, pc == f.entry)
if !ok {
break
}
print("\tvalue=", val, " until pc=", hex(pc), "\n")
}
throw("invalid runtime symbol table")
return -1, 0
}
func step(p []byte, pc *uintptr, val *int32, first bool) (newp []byte, ok bool) {
// For both uvdelta and pcdelta, the common case (~70%)
// is that they are a single byte. If so, avoid calling readvarint.
uvdelta := uint32(p[0])
if uvdelta == 0 && !first {
return nil, false
}
n := uint32(1)
if uvdelta&0x80 != 0 {
n, uvdelta = readvarint(p)
}
*val += int32(-(uvdelta & 1) ^ (uvdelta >> 1)) //zigzag解码
p = p[n:]
pcdelta := uint32(p[0])
n = 1
if pcdelta&0x80 != 0 {
n, pcdelta = readvarint(p)
}
p = p[n:]
*pc += uintptr(pcdelta * sys.PCQuantum)
return p, true
}
func readvarint(p []byte) (read uint32, val uint32) { //varint解码
var v, shift, n uint32
for {
b := p[n]
n++
v |= uint32(b&0x7F) << (shift & 31)
if b&0x80 == 0 {
break
}
shift += 7
}
return n, v
}
根据pcln读取到pcvalue之后,对应的值就是行号了,而函数所属文件的绝对路径字符串则还需要进一步计算,根据pcfile读取到的pcvalue定义为fileno,该值的含义是相对于本函数所属CU中的下标偏移,因此pcfile相对于整个cutab中的下标值就是_func.cuOffset+fileno,而cutab是uint32类型的slice,因此每一项占4个字节,所以最终pcfile对应的值的地址计算公式为:fileoff_addr = pcheader.cutab+(_func.cuOffset+fileno)*4,读取该地址的值,是相对于filetab的偏移。解析脚本中代码片段如下:
#func.py
if self.pcfile !=0:
ida_offset.op_plain_offset(addr+ptrSize+offset_size*4,0,pcheader.pctab)
fileno = common.read_pcvalue(pcheader.pctab+self.pcfile)
if fileno == -1:
self.filename = "?"
else:
fileoff_addr = pcheader.cutab+(self.cuOffset+fileno)*4
fileoff = common.get_dword(fileoff_addr)
ida_offset.op_plain_offset(fileoff_addr,0,pcheader.filetab)
if fileoff != 0xffffffff:
self.filename = idc.get_strlit_contents(pcheader.filetab+fileoff).decode('utf-8')
else:
self.filename = "?"
else:
self.filename = "?"
if self.pcln != 0:
ida_offset.op_plain_offset(addr+ptrSize+offset_size*5,0,pcheader.pctab)
self.line = common.read_pcvalue(pcheader.pctab+self.pcln)
else:
self.line = -1
在golang源代码中解析函数所属文件以及行号的代码片段如下:
//src\runtime\symtab.go
func funcline(f funcInfo, targetpc uintptr) (file string, line int32) {
return funcline1(f, targetpc, true)
}
func funcline1(f funcInfo, targetpc uintptr, strict bool) (file string, line int32) {
datap := f.datap
if !f.valid() {
return "?", 0
}
fileno, _ := pcvalue(f, f.pcfile, targetpc, nil, strict)
line, _ = pcvalue(f, f.pcln, targetpc, nil, strict)
if fileno == -1 || line == -1 || int(fileno) >= len(datap.filetab) {
// print("looking for ", hex(targetpc), " in ", funcname(f), " got file=", fileno, " line=", lineno, "\n")
return "?", 0
}
file = funcfile(f, fileno)
return
}
func funcfile(f funcInfo, fileno int32) string {
datap := f.datap
if !f.valid() {
return "?"
}
// Make sure the cu index and file offset are valid
if fileoff := datap.cutab[f.cuOffset+uint32(fileno)]; fileoff != ^uint32(0) {
return gostringnocopy(&datap.filetab[fileoff])
}
// pcln section is corrupt.
return "?"
}
3.1.3 函数信息汇总
通过上面的解析,可以获得函数的信息如下:
- 函数入口地址
- 函数名称
- 函数参数的大小
- 函数所属文件
- 函数所在文件中的行号
其中函数所属文件与行号在逆向分析是作用不大,但是大多数软件都会使用网上开源的组件,那么知道了调用的函数是开源代码中的,即可直接根据文件和行号进行源码查看,而无需通过汇编理解。
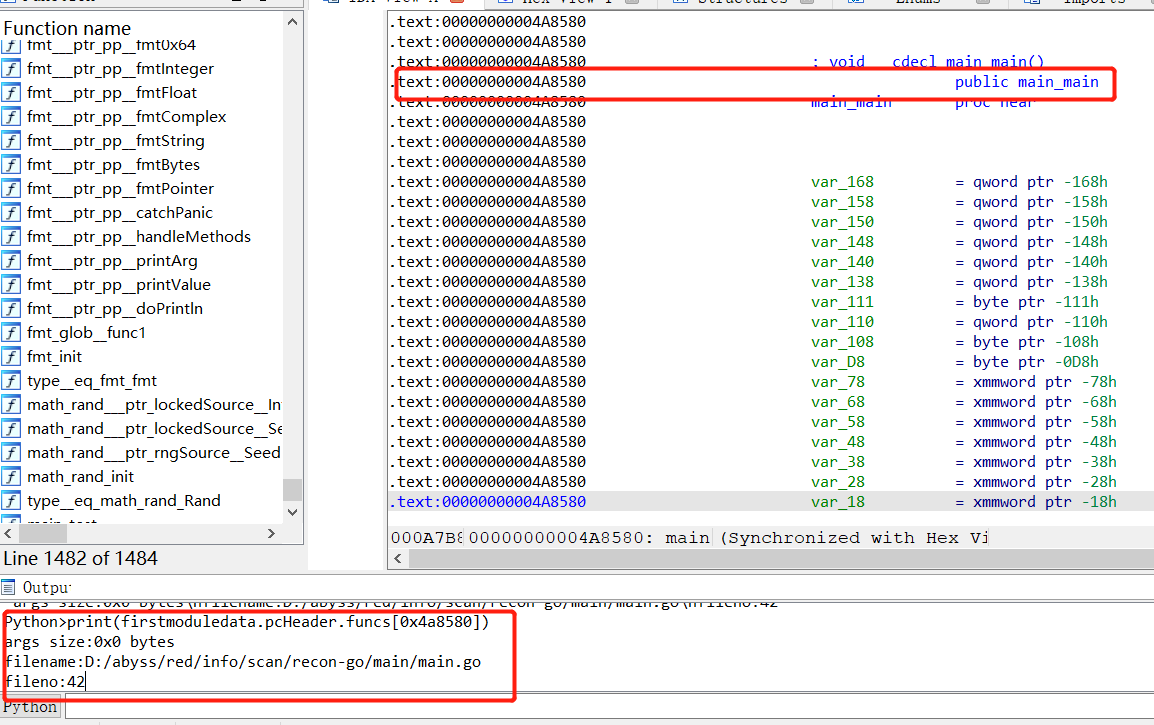
上述的函数信息,在解析pcHeader之后,进行了汇总,存储为字典对象funcs,key是函数的entry。
在IDA中使用效果:
0x04 typelink
typelink是int32类型的slice,存储的是相对于moduledata.types的偏移,每一个对应一个类型,每个类型起始数据都是rtype结构体,后续则根据rtype.kind以及rtype.tflag来判断后续是否有数据以及如何解析。(先根据kind判断是否为Composite Type,再根据tflag判断是否为Uncommon Type)。
一个Type的整体结构如下(盗一下参考链接里的图)

Type的Kind可以有Basic Type和Composite Type两种,而其分类如下(盗一下参考链接里的图)

4.1 rtype
rtype的定义如下,另外需要跟src\runtime\type.go:/^type._type保持一致
//src\reflect\type.go
// rtype must be kept in sync with ../runtime/type.go:/^type._type.
type rtype struct {
size uintptr
ptrdata uintptr // number of bytes in the type that can contain pointers
hash uint32 // hash of type; avoids computation in hash tables
tflag tflag // extra type information flags
align uint8 // alignment of variable with this type
fieldAlign uint8 // alignment of struct field with this type
kind uint8 // enumeration for C
// function for comparing objects of this type
// (ptr to object A, ptr to object B) -> ==?
equal func(unsafe.Pointer, unsafe.Pointer) bool
gcdata *byte // garbage collection data
str nameOff // string form
ptrToThis typeOff // type for pointer to this type, may be zero
}
//src\reflect\type.go
type nameOff int32
type typeOff int32
关注的字段为:
- size:该类型所占字节
- tflag:标志位
- kind:所属种类,见上图Basic Type和Composite Type
- str:类型名称,nameOff类型实际为int32,该值是相对于moduledata.types的偏移量
- ptrToThis:指向该类型的指针类型,typeOff 类型实际为int32,该值是相对于moduledata.types的偏移量
4.1.1 kind与tflag解析
kind解析,根据掩码进行与操作,判断相应的值,kind的可用定义以及掩码的定义在golang的代码中如下:
//src\reflect\type.go
const (
kindDirectIface = 1 << 5
kindGCProg = 1 << 6 // Type.gc points to GC program
kindMask = (1 << 5) - 1
)
type Kind uint
const (
Invalid Kind = iota
Bool
Int
Int8
Int16
Int32
Int64
Uint
Uint8
Uint16
Uint32
Uint64
Uintptr
Float32
Float64
Complex64
Complex128
Array
Chan
Func
Interface
Map
Ptr
Slice
String
Struct
UnsafePointer
)
根据掩码kindmask可知,kind的值的低4位用于表示kind的类型,kind对应的类型已经定义为了const,分别是0x0~0xf,因此取kind的低4位来确定rtype对应的Kind类型。
解析脚本代码如下:
#typelink.py
def get_kind(self):
# src/reflect/type.go#kindMask
TYPE_KINDS = ['Invalid Kind','Bool','Int','Int8','Int16','Int32','Int64','Uint','Uint8','Uint16','Uint32','Uint64','Uintptr','Float32','Float64','Complex64','Complex128','Array','Chan','Func','Interface','Map','Ptr','Slice','String','Struct','UnsafePointer']
kindMask = (1 << 5) - 1
return TYPE_KINDS[self.kind & kindMask]
tflag解析,根据掩码进行与操作,判断对应flag的值,flag的定义在golang代码中如下:
//src\reflect\type.go
const (
// tflagUncommon means that there is a pointer, *uncommonType,
// just beyond the outer type structure.
//
// For example, if t.Kind() == Struct and t.tflag&tflagUncommon != 0,
// then t has uncommonType data and it can be accessed as:
//
// type tUncommon struct {
// structType
// u uncommonType
// }
// u := &(*tUncommon)(unsafe.Pointer(t)).u
tflagUncommon tflag = 1 << 0
// tflagExtraStar means the name in the str field has an
// extraneous '*' prefix. This is because for most types T in
// a program, the type *T also exists and reusing the str data
// saves binary size.
tflagExtraStar tflag = 1 << 1
// tflagNamed means the type has a name.
tflagNamed tflag = 1 << 2
// tflagRegularMemory means that equal and hash functions can treat
// this type as a single region of t.size bytes.
tflagRegularMemory tflag = 1 << 3
)
- tflagUncommon : 表示存在uncommon type部分的数据(当然如果是Composite Type,则更在Composite Type数据后面,否则是跟在rtype数据后面)
- tflagExtraStar : 表示类名之前是否会包含,实际测试发现许多类型名称会存在 号,有些是表示指针类型,有些则是因为存在tflagExtraStar,因此通过注释定义类型名称时,如果是tflagExtraStar的,则将名称前的 * 替换为 # 存入注释中。
- tflagNamed : 表示类型存在名称
- tflagRegularMemory :未了解
解析脚本代码如下:
#typelink.py
def parse_tflag(self):
# src/reflect/type.go#tflag
tflagUncommon = 0x1
tflagExtraStar = 0x2
tflagNamed = 0x4
tflagRegularMemory = 0x8
self.tflag_comm = 'tflag:'
if self.tflag & tflagUncommon != 0:
self.uncommon = True
self.tflag_comm += "Uncommon;"
else:
self.uncommon = False
self.tflag_comm += "Common;"
if self.tflag & tflagExtraStar !=0:
self.tflag_comm += "Star Prefix;"
if self.tflag & tflagNamed !=0:
self.tflag_comm += "Named"
if self.tflag & tflagRegularMemory !=0:
self.tflag_comm += "equal and hash func can treat"
#判断*号的代码片段
if "Star Prefix" in self.tflag_comm and name_str[0] == '*':
name_str = '#' + name_str[1:]
4.1.2 str(name结构体)与ptrToThis解析
ptrToThis比较简单,ptrToThis的值+moduledata.types,则是指向另一个rtype首地址,直接判断地址是否解析过,未解析则解析该类型。
str+moduledata.types,是指向一个name数据的首地址,先看下name数据在golang源码中的定义与解释:
//src\reflect\type.go
// name is an encoded type name with optional extra data.
//
// The first byte is a bit field containing:
//
// 1<<0 the name is exported
// 1<<1 tag data follows the name
// 1<<2 pkgPath nameOff follows the name and tag
//
// The next two bytes are the data length:
//
// l := uint16(data[1])<<8 | uint16(data[2])
//
// Bytes [3:3+l] are the string data.
//
// If tag data follows then bytes 3+l and 3+l+1 are the tag length,
// with the data following.
//
// If the import path follows, then 4 bytes at the end of
// the data form a nameOff. The import path is only set for concrete
// methods that are defined in a different package than their type.
//
// If a name starts with "*", then the exported bit represents
// whether the pointed to type is exported.
type name struct {
bytes *byte
}
第一个字节也是flag位,根据掩码进行判断,分别表示name是否导出,后续是否跟tag与pkgpath的值(这两个解析脚本未进行解析,当时没关注)
第二、三字节是表示name字符串的长度,根据解释可以知道该长度值是大端存放的。
第四字节开始就是name的字符串
解析脚本如下:
#typelink.py
#解析flag
def parse_flag(self):
EXPORTED = 0x1
HAS_TAG = 0x2
HAS_PKGPATH = 0x4
self.flag_comm = "flag:"
if self.flag & EXPORTED:
self.is_exported = True
self.flag_comm += "exported;"
if self.has_tag & HAS_TAG:
self.has_tag = True
self.flag_comm += "has tag;"
if self.flag & HAS_PKGPATH:
self.has_pkgpath = True
self.flag_comm += "has pkgpath"
# 计算长度
self.len = (ida_bytes.get_byte(name_addr+1)<<8)|ida_bytes.get_byte(name_addr+2)
#获取字符串
def get_name(self):
name = ""
if self.len > 0:
try:
name = self.name.decode('utf-8')
except Exception as err:
print(hex(self.rtype.start_addr),hex(self.start_addr))
traceback.print_stack()
return name
4.2 ptrType
golang源码中的定义如下:
//src\reflect\type.go
type ptrType struct {
rtype
elem *rtype // pointer element (pointed at) type
}
rtype后面跟一个指针,指向该指针类型的原始类型。
4.3 structType
golang源码中的定义如下:
//src\reflect\type.go
type structType struct {
rtype
pkgPath name
fields []structField // sorted by offset
}
type structField struct {
name name // name is always non-empty
typ *rtype // type of field
offsetEmbed uintptr // byte offset of field<<1 | isEmbedded
}
rtype后面跟一个name类型的pkgpath,name类型的解析见 4.1.2中的介绍,后面是structField的slice类型,代表的是该struct所包含的字段
structField对应的是一个字段,包含了name(字段名)、typ(字段类型)、offsetEmbed(主要关注字段在整个struct中的偏移)
name是name类型,解析见4.1.2,typ是指向另一个rtype的首地址。
offsetEmbed,最低位是表示改字段isEmbdded,offsetEmbed右移一位即是字段在struct中的偏移量了。
解析脚本如下:
self.offset = self.offsetEmbed >> 1
self.is_embeded = (self.offsetEmbed&1 != 0)
4.4 sliceType
golang源码中的定义如下:
//src\reflect\type.go
type sliceType struct {
rtype
elem *rtype // slice element type
}
rtype后面跟一个指针,指向slice存储的类型。
4.5 arrayType
golang源码中的定义
//src\reflect\type.go
type arrayType struct {
rtype
elem *rtype // array element type
slice *rtype // slice type
len uintptr
}
elem表示的是数组每个对象的类型,slice则是存储所有对象使用的slice,也就是slice中的elem与array中的elem指向的是同i一个类型。
4.6 funcType
golang源码中的定义
//src\reflect\type.go
// A *rtype for each in and out parameter is stored in an array that
// directly follows the funcType (and possibly its uncommonType). So
// a function type with one method, one input, and one output is:
//
// struct {
// funcType
// uncommonType
// [2]*rtype // [0] is in, [1] is out
// }
type funcType struct {
rtype
inCount uint16
outCount uint16 // top bit is set if last input parameter is ...
}
inCount、outCount分别是输入参数和返回值的个数,根据解释可以知道在uncommonType数据(如果存在的话,不存在就是紧跟在funcType数据后面),是一个[]rtype,分别根据in和out的个数,指向对应的rtype。
4.7 interfaceType
golang源码中的定义
//src\reflect\type.go
type interfaceType struct {
rtype
pkgPath name // import path
methods []imethod // sorted by hash
}
type imethod struct {
name nameOff // name of method
typ typeOff // .(*FuncType) underneath
}
pkgpath是name类型,解析见4.1.2;interface的接口定义的方法通过methods进行存储,imethod中的name和typ则与rtype中的str和ptrToThis一样,都是基于moduledata.types的偏移,因此:
imethod.name_addr = imethod.name + moduledata.types,解析见4.1.2
imethod.typ = imethod.typ + moduledata.types,指向一个funcType
4.8 mapType
golang源码中的定义
//src\reflect\type.go
type mapType struct {
rtype
key *rtype // map key type
elem *rtype // map element (value) type
bucket *rtype // internal bucket structure
// function for hashing keys (ptr to key, seed) -> hash
hasher func(unsafe.Pointer, uintptr) uintptr
keysize uint8 // size of key slot
valuesize uint8 // size of value slot
bucketsize uint16 // size of bucket
flags uint32
}
rtype后面三个指针,均指向其他的rtype,key和elem分别是键的类型和值的类型,bucket未理解。
4.9 chanType
golang源码中的定义
//src\reflect\type.go
type chanType struct {
rtype
elem *rtype // channel element type
dir uintptr // channel direction (ChanDir)
}
type ChanDir int
const (
RecvDir ChanDir = 1 << iota // <-chan
SendDir // chan<-
BothDir = RecvDir | SendDir // chan
)
func (t *rtype) ChanDir() ChanDir {
if t.Kind() != Chan {
panic("reflect: ChanDir of non-chan type " + t.String())
}
tt := (*chanType)(unsafe.Pointer(t))
return ChanDir(tt.dir)
}
func (d ChanDir) String() string {
switch d {
case SendDir:
return "chan<-"
case RecvDir:
return "<-chan"
case BothDir:
return "chan"
}
return "ChanDir" + strconv.Itoa(int(d))
}
elem表示的该chan的类型,dir则是表示方向,也是通过掩码进行判断,1表示Recv,2表示Send,3表示双向。
解析脚本代码片段如下:
#src\reflect\type.go
def get_direction(self):
recvDir = 0x1
sendDir = 0x2
self.directions = []
if self.dir & recvDir:
self.directions.append('recv')
if self.dir & sendDir:
self.directions.append('send')
return "channel direction:" + "&".join(self.directions)
4.10 uncommonType
golang源码中的定义
//src\reflect\type.go
type uncommonType struct {
pkgPath nameOff // import path; empty for built-in types like int, string
mcount uint16 // number of methods
xcount uint16 // number of exported methods
moff uint32 // offset from this uncommontype to [mcount]method
_ uint32 // unused
}
type method struct {
name nameOff // name of method
mtyp typeOff // method type (without receiver)
ifn textOff // fn used in interface call (one-word receiver)
tfn textOff // fn used for normal method call
}
uncommmonType的pkgPath同其之前遇到的pkgPath有点区别,不是name类型而是nameOff,因此需要加上moduledata.types。
mcount,xcount分别是总的方法个数和导出的方法个数。
moff则是指向一个method数组,长度为mcount,方法名method.name解析同uncommmonType.pkgPath,mtyp也是基于moduledata.types的偏移,指向一个funcType。
ifn和tfn则是基于moduledata.text的偏移量,分别指向函数的入口地址,两个函数的区别没有深究,实际测试时也发现有些是指向的同一个地址。
0x05 itablink
itab是interface table,在moduledata中的定义类型为[]*itab,因此先解析为slice,之后根据每个指针单独去解析itab,每个itab都是一个接口,一个实现该接口的类型,该类型实现接口的函数入口地址。
golang源码中的定义
//src\runtime\runtime2.go
type itab struct {
inter *interfacetype
_type *_type
hash uint32 // copy of _type.hash. Used for type switches.
_ [4]byte
fun [1]uintptr // variable sized. fun[0]==0 means _type does not implement inter.
}
inter指向的是4.7解析的interfaceType,_type指向实现该接口的类,根据interfaceType中的methods属性,可以知道interfaceType总共定义了多少接口,再按照个数尝试读取itab.fun指向的地址,知道读到地址为0的时候停止。
解析脚本中将fun的个数和interface定义的函数个数以注释的形式输出在itab._(未使用的字段)。
解析脚本代码片段如下:
#itablink.py
self.interface = typelink.parsed_types[self.inter]
if not typelink.has_parsed(self.type_addr):
typelink.parse_type(self.type_addr)
self.funcs = []
for i in range(self.interface.method_slice.len):
func_addr = common.get_qword(self.start_addr+ptrSize*(3+i))
if func_addr != 0:
self.funcs.append(func_addr)
else:
break
ida_bytes.set_cmt(self.start_addr+ptrSize*2+4,"Unused;Func num:%d,Interface num:%d" % (len(self.funcs),self.interface.method_slice.len),False)

