0x00 获取type
1.1 根据地址获取type
调用过goparse的main.py,会创建一个firstmduledata的对象。
some_type = firstmoduledata.typelinks.parsed_types[0x1747fe0]
1.2 根据kind分类type
在moduledata中解析所有rtype,根据kind形成字典,每个kind下面再根据rtype.name_str形成字典,需要手动调用firstmoduledata.parse_typelink(),后来实际测试发现会存在相同的name,因为类型名称只是包名.类型名,所以最后一个解析到的会覆盖之前的,这个小Bug就没改了,重复的则可以通过地址来获取确定的type。
解析脚本如下
#moduledata.py
def parse_typelink(self):
self.rtypes = {}
for addr in self.typelinks.parsed_types.keys():
rtype = self.typelinks.parsed_types[addr]
kind = rtype.get_kind()
if kind not in self.rtypes.keys():
self.rtypes[kind] = {}
self.rtypes[kind][rtype.name_str] = rtype
1.3 手动解析type
firstmoduledata.typelinks.parse_type(addr)
会存在一些未在typelink表里的,如未定义名称的struct等,需要手动调用parse_type进行解析。
0x01 StructType
在StructType中可以知道所有field的名称、类型、偏移,因此利用这些值在逆向时提供帮助,手动一个个查看太累了。
2.1 输出struct信息
def show_struct(self):
struct_info = "type %s struct{" % self.name_str
for field in self.fields:
field_info = "\n\t%s %s offset %d" % (field.field_name.get_name(),field.type.name_str,field.offset)
struct_info += field_info
struct_info += "\n}"
print(struct_info)
2.2 自动生成IDA结构体
在IDA中生成结构体
#typelink.py#StructType
def generate_struct(self):
field_infos = []
for field in self.fields:
name = field.field_name.get_name()
name = name.replace('#','').replace('.','_').replace('*',"_ptr_")
offset = field.offset
nbytes = field.type.size
if field.type.name_str == '#string':
field_info_addr = {"name":name+"_addr","offset":offset,"nbytes":8}
field_info_len = {"name":name+"_len","offset":offset+8,"nbytes":8}
field_infos.append(field_info_addr)
field_infos.append(field_info_len)
else:
field_info = {"name":name,"offset":offset,"nbytes":nbytes}
field_infos.append(field_info)
fields_num = len(field_infos)
struct_name = self.name_str.replace('#','').replace('.','_').replace('*',"_ptr_")
idx = ida_struct.add_struc(idaapi.BADADDR,struct_name,False)
struc = ida_struct.get_struc(idx)
for i in range(fields_num):
if i < fields_num-1:
if field_infos[i]['nbytes'] != field_infos[i+1]['offset']-field_infos[i]['offset']:
print("%s type size(0x%x) is not equal its size(0x%x) in struct,offset is 0x%x" % (field_infos[i]['name'],field_infos[i]['nbytes'],field_infos[i+1]['offset']-field_infos[i]['offset'],field_infos[i]['offset']))
field_infos[i]['nbytes'] = field_infos[i+1]['offset']-field_infos[i]['offset']
ida_struct.add_struc_member(struc,field_infos[i]['name'],field_infos[i]['offset'],ida_bytes.FF_DATA,None,field_infos[i]['nbytes'])
0x02 itablink
//runtime\malloc.go
type itab struct {
inter *interfacetype
_type *_type
hash uint32 // copy of _type.hash. Used for type switches.
_ [4]byte
fun [1]uintptr // variable sized. fun[0]==0 means _type does not implement inter.
}
//runtime\runtime2.go
type iface struct {
tab *itab
data unsafe.Pointer
}
//runtime\malloc.go T2I应该是Type to Interface
func convT2I(tab *itab, elem unsafe.Pointer) (i iface) {
t := tab._type
if raceenabled {
raceReadObjectPC(t, elem, getcallerpc(), funcPC(convT2I))
}
if msanenabled {
msanread(elem, t.size)
}
x := mallocgc(t.size, t, true)
typedmemmove(t, x, elem)
i.tab = tab
i.data = x
return
}
类型转换为interface,interface就是上述定义的iface结构体。itab结构体就是itablinks解析的单个的对象,源码里看到通过itab获取类型的rtype,再根据rtype的size来动态申请内存用于存储对象,最后iface的tab指向itab,data指向具体的结构体数据。
3.1面对对象编程
讲到接口,必定是面向对象编程,而写面向对象编程时,接收者可以是某个结构体或者该结构体的指针,从汇编的角度看下两种的区别,以及golang自动转换的效果。
3.1.1 指针类型的函数,无法自动转化为非指针类型的
栗子:
package main
import (
"fmt"
)
type Person struct {
name string
age int
}
type iPerson interface {
compare(Person) bool
}
func (p *Person) init(name string, age int) error {
fmt.Println("Person init")
p.name = name
p.age = age
return nil
}
func (p *Person) compare(b Person) bool {
if p.age > b.age {
return true
} else {
return false
}
}
func main() {
var p Person
var iperson iPerson
p.init("aaa", 18)
iperson = p
iperson.compare(p)
}
可以看到接口iPerson是compare,但是转化成接口的类型是Person,而不是*Person,golang也不会自动帮你转换,因为接收者(receiver)是指针类型的,那么是可以修改接收者的值的,但是转换为非指针类型,在调用时,已经是值拷贝了,即使在内部代码将接收者转换为指针,依然是无法修改接收者的值的。
因此在iperson=p这段代码的报错,第一行编译报错,第二行是vscode的提示(忘了装的哪个插件还是自带的)
Person does not implement iPerson (compare method has pointer receiver)
cannot use p (variable of type Person) as iPerson value in assignment: missing method compare (compare has pointer receiver)compilerInvalidIfaceAssign
3.1.2 非指针类型转化为指针类型
还是上面的栗子,只是修改了compare函数的接收者。
func (p Person) compare(b Person) bool {
if p.age > b.age {
return true
} else {
return false
}
}
编译(go1.16.8)是成功的,拖入IDA进行分析
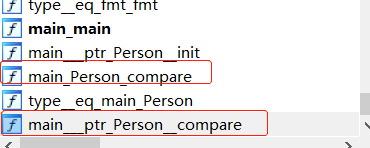
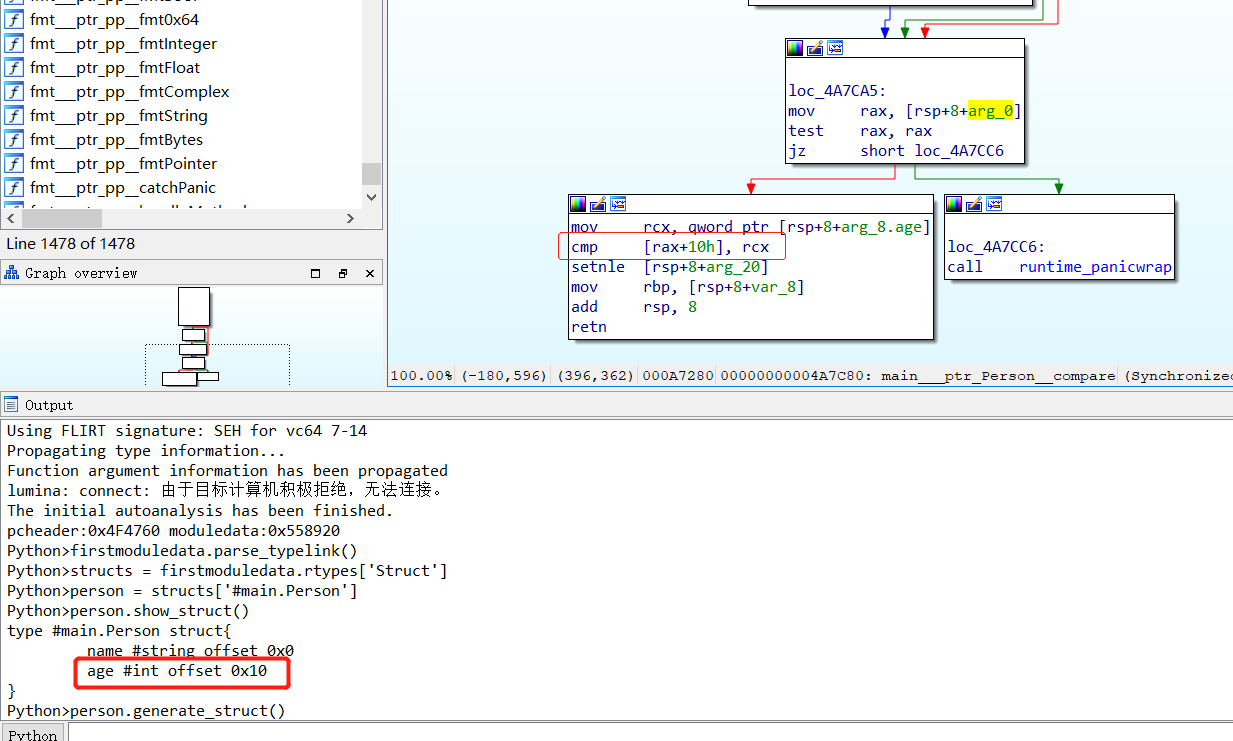
发现自动生成了一个recevier为指针的函数。
查看funcinfo,查看pcfile的值,是autogenerated,也说明是golang自动生成的,函数名称是(*Person).compare。
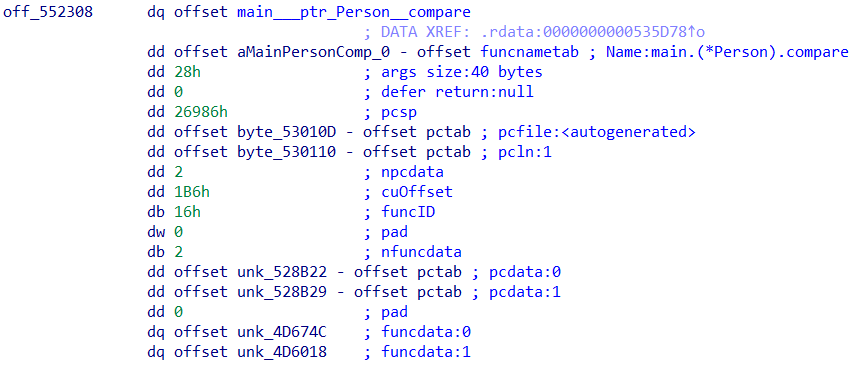
再看下具体的函数,先是(Person).compare

先利用脚本解析一下typelinks,然后根据名称获取对应struct,获取struct的表示形式。
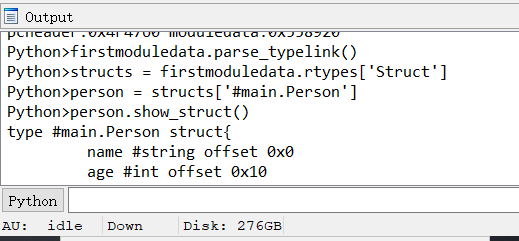
代码是获取了两个参数的地址,进行了比较,就是两个Person的age属性比较,现在参数是Person结构对象,非指针,因此两个对象都是在栈上的(go 1.17之前是栈传递参数),现在利用脚本生成Person struct,然后将栈空间对应变量内存类型设置为Person结构体。进入(Person).compare栈空间(双击arg_参数即可)。
#生成IDA结构体
person.generate_struct()
内存偏移0x8(偏移0的地方是返回地址,IDA也自动解析为了r)处定义为Person结构体(快捷键 Alt+Q)。
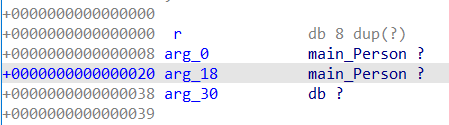
回到View界面,代码就清晰了。

实际情况其实基本没用,因为参数传递感觉更多的是结构体指针,实际数据都在堆中,所以还是通过show_struct()之后自己比较偏移看读取的是什么属性吧。
再看下golang自动生成的代码,因为比较的参数还是Person结构体,按照上述操作将参数类型进行修改。arg_0是偏移0x8处的对象,也就是接收者*Person,是个指针,因此只能通过看偏移量确定读取的值,这里根据show_struct()的结果知道读取的是age的值。
3.2 接口的表示形式
3.1和3.2只是支线任务,聊一下golang自动生成的代码,感觉最好还是不要依赖golang自己生成代码,需要的自己写出来。
现在回到main函数,看下接口到底如何实现,这里只展示主要的main函数汇编代码。
var_68= qword ptr -68h
var_60= qword ptr -60h
var_58= qword ptr -58h
var_50= qword ptr -50h
var_38= qword ptr -38h
var_30= xmmword ptr -30h
var_20= qword ptr -20h
var_18= qword ptr -18h
var_10= qword ptr -10h
var_8= qword ptr -8
sub rsp, 68h
mov [rsp+68h+var_8], rbp
lea rbp, [rsp+68h+var_8]
;var_38就是main函数中的变量p,p是Person结构体,占内存空间0x18,下面就是清空了0x18字节的内存。
mov [rsp+68h+var_38], 0
xorps xmm0, xmm0
movups [rsp+68h+var_30], xmm0
;上述代码相当于var p Person,首地址是var_38
lea rax, [rsp+68h+var_38] ;rax = &p,因为init函数的接收者类型是*Person
mov [rsp+68h+var_68], rax
lea rax, aAaa ; "aaa"
mov [rsp+68h+var_60], rax
mov [rsp+68h+var_58], 3
mov [rsp+68h+var_50], 12h
;上述类似于从右往左传入参数,只是这里是先空留出的栈空间再赋值的,而不是通过push操作完成。
call main___ptr_Person__init
;等同于main___ptr_Person__init(rax,"aaa",3,0x12)
;接收者作为第一个参数,"aaa"和3是golang内的string类型表示,字符串+长度,0x12即18
;因此go代码就是p.init("aaa", 18)
mov rax, [rsp+68h+var_38]
mov rcx, qword ptr [rsp+68h+var_30]
mov rdx, qword ptr [rsp+68h+var_30+8]
mov [rsp+68h+var_20], rax
mov [rsp+68h+var_18], rcx
mov [rsp+68h+var_10], rdx
;将var_38的Person数据存储到var_20处
lea rax, go_itab_main_Person_main_iPerson ;itab结构体
mov [rsp+68h+var_68], rax
lea rax, [rsp+68h+var_20];Person结构体
mov [rsp+68h+var_60], rax
call runtime_convT2I
;等同于runtime_convT2I(*itab,*Person),该函数见上文
;将var_20出的Person转换为接口iPerson
;拷贝var_38的值到var_20,以及执行runtime_convT2I等于golang代码:iperson = p
mov rax, [rsp+68h+var_58]
mov rcx, [rsp+68h+var_50]
;var_58和var_50是返回值,即iperson,结构体是iface,var_58指向itab,var_50指向mallocgc申请的内存空间中
mov rdx, [rsp+68h+var_38]
mov rbx, qword ptr [rsp+68h+var_30]
mov rsi, qword ptr [rsp+68h+var_30+8]
mov rax, [rax+18h]
;根据iface.itab的偏移量来获取*Person对接口中某个函数的具体实现,可以看下文截图,这里rax指向了(*Person).compare
mov [rsp+68h+var_68], rcx
;rcx指向的是iface.data,是一个unsafe.Pointer,即指向的Person结构体数据,是接口iperson的
mov [rsp+68h+var_60], rdx
mov [rsp+68h+var_58], rbx
mov [rsp+68h+var_50], rsi
;rdx、rbx、rsi即指向的p的Person结构体数据
call rax
;执行compare函数
mov rbp, [rsp+68h+var_8]
add rsp, 68h
retn
看下go_itab_main_Person_main_iPerson的具体值,可以明确偏移0x18处即函数(*Person).compare

3.3 Any类型:interface{}
如果参数类型是interface{},可以代表任何类型,虽然都是interface,但其实这里不是iface结构体了,而是eface,已经与itab无关了。
//src\runtime\runtime2.go
type eface struct {
_type *_type
data unsafe.Pointer
}
也就是第一个参数不是指向itab,而是指向rtype了。
栗子:
package main
import "fmt"
func test_interface(arg interface{}) {
switch v := arg.(type) {
case int:
fmt.Printf("arg is int:%d\n", arg)
case string:
fmt.Printf("arg is string:%s\n", arg)
default:
fmt.Println(v)
}
if data, ok := arg.(string); ok {
fmt.Println("convert to string:" + data)
}
}
func main() {
a := 1
test_interface(a)
test_interface("aaa")
var p [3]int = [3]int{1, 2, 3}
test_interface(p)
}
3.3.1 传值
main函数的汇编代码如下
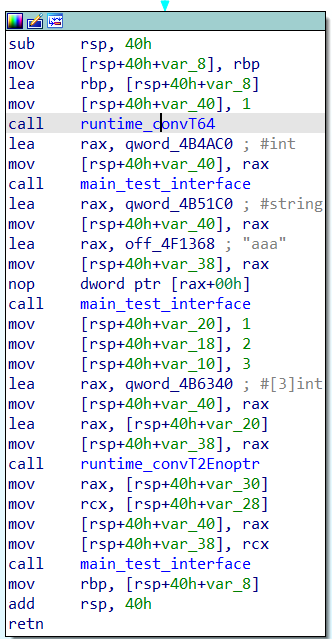
test_interface(a)和test_interface(p)调用的是局部变量,需要将值转换成指针,并且指向的数据不是在栈中,所以在iface.go中存在一些转换的函数,如convT64、convTstring、convTslice等,复杂的类型通过convT2Enoptr来转换
//src\runtime\iface.go
func convT64(val uint64) (x unsafe.Pointer) {
if val < uint64(len(staticuint64s)) {
x = unsafe.Pointer(&staticuint64s[val])
} else {
x = mallocgc(8, uint64Type, false)
*(*uint64)(x) = val
}
return
}
func convT2Enoptr(t *_type, elem unsafe.Pointer) (e eface) {
if raceenabled {
raceReadObjectPC(t, elem, getcallerpc(), funcPC(convT2Enoptr))
}
if msanenabled {
msanread(elem, t.size)
}
x := mallocgc(t.size, t, false)
memmove(x, elem, t.size)
e._type = t
e.data = x
return
}
3.3.2 type判断
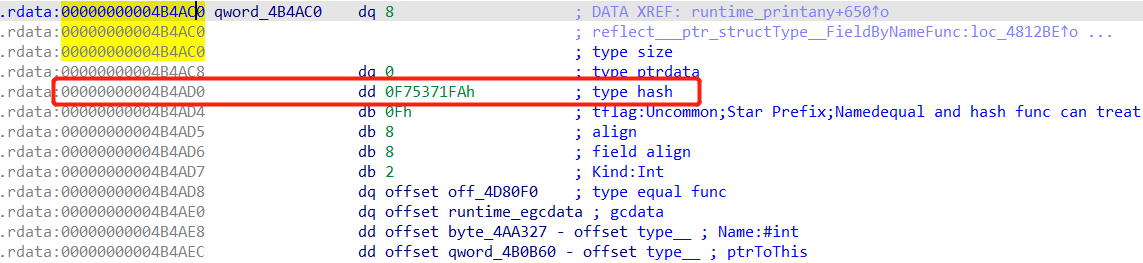
在test_interface函数中有一个switch判断传入参数的类型,其实是通过eface._type.hash进行比较判断的。
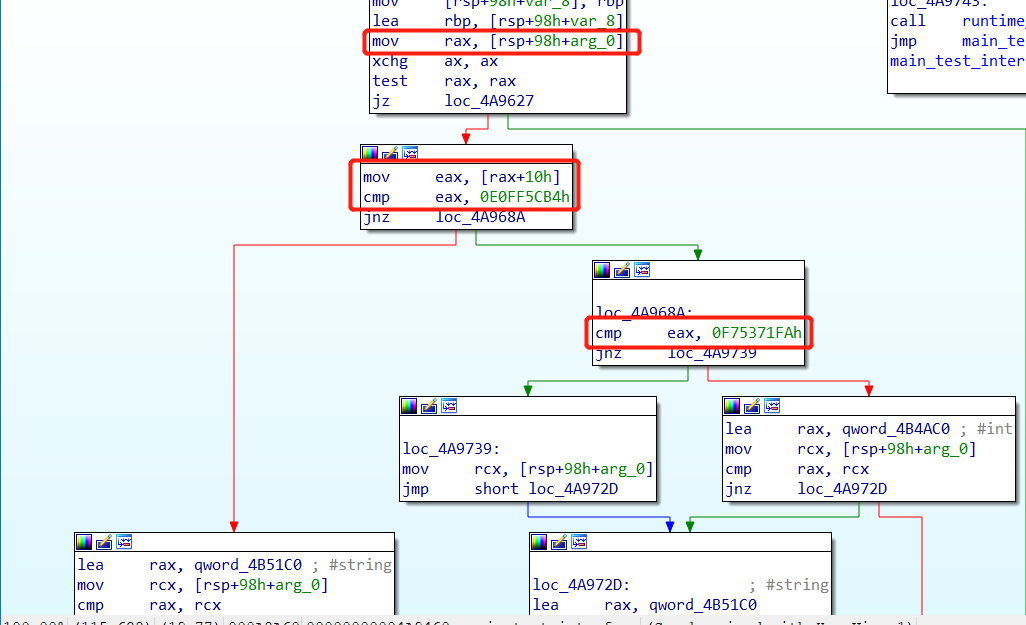
eface结构体占0x10字节,前8字节是arg_0(即eface._type),后8字节是arg_8(即eface.data)
获取_type的0x10的偏移,就是rtype.hash,分别同int和string类型的hash进行比较来判断类型。
string的rtype
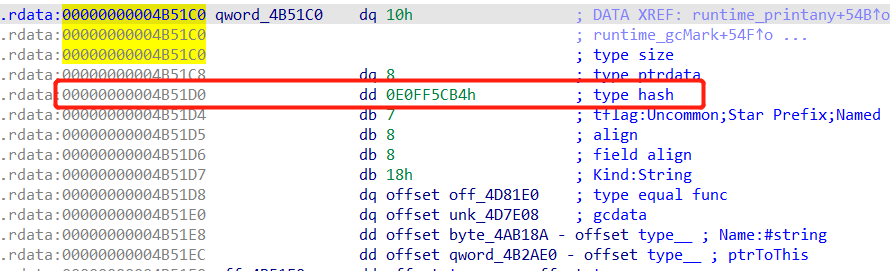
int的rtype
3.3.3 类型转换
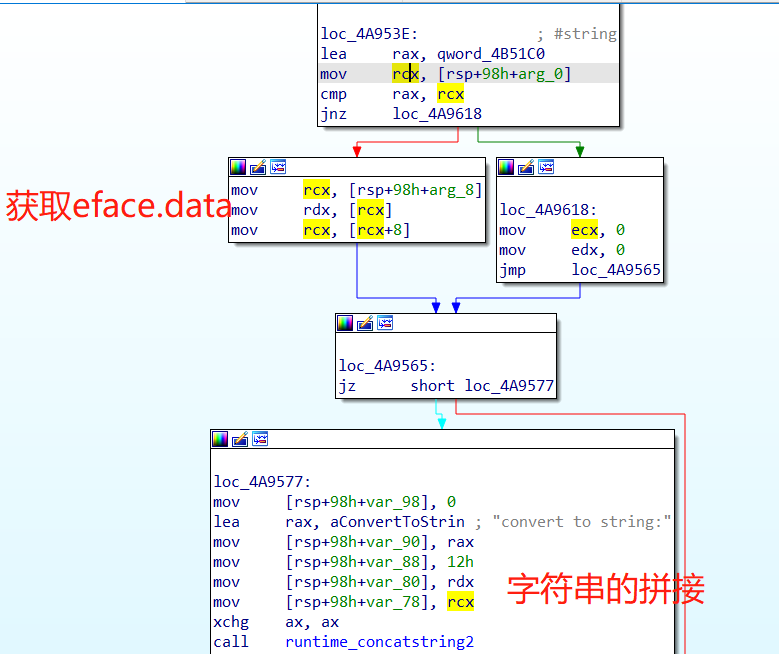
test_interface函数中尝试将arg转换为string类型,成功即输出字符串的值,汇编中发现直接判断的eface._type与string的type地址是否相同,相同则eface.data就是字符串指针了。
0x03 symtab解析-go 1.18
symtab(go1.16)详细解析参照GO逆向分析小结-symtab解析,goparse中已经更新,不同版本有不同的tag,至于1.17我先偷个懒。
4.1 moduledata
//go 1.18.1
//src\runtime\symtab.go
type moduledata struct {
pcHeader *pcHeader
funcnametab []byte
cutab []uint32
filetab []byte
pctab []byte
pclntable []byte
ftab []functab
findfunctab uintptr
minpc, maxpc uintptr
text, etext uintptr
noptrdata, enoptrdata uintptr
data, edata uintptr
bss, ebss uintptr
noptrbss, enoptrbss uintptr
end, gcdata, gcbss uintptr
types, etypes uintptr
rodata uintptr
gofunc uintptr // go.func.*
textsectmap []textsect
typelinks []int32 // offsets from types
itablinks []*itab
ptab []ptabEntry
pluginpath string
pkghashes []modulehash
modulename string
modulehashes []modulehash
hasmain uint8 // 1 if module contains the main function, 0 otherwise
gcdatamask, gcbssmask bitvector
typemap map[typeOff]*_type // offset to *_rtype in previous module
bad bool // module failed to load and should be ignored
next *moduledata
}
相比于go 1.16.8,多了两个属性
- rodata uintptr
- gofunc uintptr // go.func.*
4.2 pcHeader
//go 1.18.1
//src\runtime\symtab.go
type pcHeader struct {
magic uint32 // 0xFFFFFFF0
pad1, pad2 uint8 // 0,0
minLC uint8 // min instruction size
ptrSize uint8 // size of a ptr in bytes
nfunc int // number of functions in the module
nfiles uint // number of entries in the file tab
textStart uintptr // base for function entry PC offsets in this module, equal to moduledata.text
funcnameOffset uintptr // offset to the funcnametab variable from pcHeader
cuOffset uintptr // offset to the cutab variable from pcHeader
filetabOffset uintptr // offset to the filetab variable from pcHeader
pctabOffset uintptr // offset to the pctab variable from pcHeader
pclnOffset uintptr // offset to the pclntab variable from pcHeader
}
多了一个textStart属性,主要用于后续pclntab的解析,因为记录函数地址的entryoff从绝对地址变为了偏移地址,偏移起始地址为textStart。
4.3 pclntable与ftab
moduledata.pclntable和pcHeader计算出来的pclntab地址一致。
//go 1.18.1
//src\runtime\symtab.go
type functab struct {
entryoff uint32 // relative to runtime.text
funcoff uint32
}
//go 1.18.1
//src\runtime\runtime2.go
type _func struct {
entryoff uint32 // start pc, as offset from moduledata.text/pcHeader.textStart
nameoff int32 // function name
args int32 // in/out args size
deferreturn uint32 // offset of start of a deferreturn call instruction from entry, if any.
pcsp uint32
pcfile uint32
pcln uint32
npcdata uint32
cuOffset uint32 // runtime.cutab offset of this function's CU
funcID funcID // set for certain special runtime functions
flag funcFlag
_ [1]byte // pad
nfuncdata uint8 // must be last, must end on a uint32-aligned boundary
}
相比于go 1.16.8的版本,entry变为entryoff,类型也从uniptr类型转换为uint32,从地址变为了偏移量,起始地址是.text的首地址(记录于moduledata.text/pcHeader.textStart)。
args参数需要提一下,golang源码的备注可能忘记改了,现在args仅表示传入的参数所占字节数,不包括返回值的。
另外原本pad是两个字节,现在拿出了一个字节作为flag属性,未深入了解,可以参考源码
//go 1.18.1
//src\runtime\symtab.go
type funcFlag uint8
const (
// TOPFRAME indicates a function that appears at the top of its stack.
// The traceback routine stop at such a function and consider that a
// successful, complete traversal of the stack.
// Examples of TOPFRAME functions include goexit, which appears
// at the top of a user goroutine stack, and mstart, which appears
// at the top of a system goroutine stack.
funcFlag_TOPFRAME funcFlag = 1 << iota
// SPWRITE indicates a function that writes an arbitrary value to SP
// (any write other than adding or subtracting a constant amount).
// The traceback routines cannot encode such changes into the
// pcsp tables, so the function traceback cannot safely unwind past
// SPWRITE functions. Stopping at an SPWRITE function is considered
// to be an incomplete unwinding of the stack. In certain contexts
// (in particular garbage collector stack scans) that is a fatal error.
funcFlag_SPWRITE
// ASM indicates that a function was implemented in assembly.
funcFlag_ASM
)
4.4 typelink
4.1 rtype
//go 1.18.1
//src\reflect\type.go
// name is an encoded type name with optional extra data.
//
// The first byte is a bit field containing:
//
// 1<<0 the name is exported
// 1<<1 tag data follows the name
// 1<<2 pkgPath nameOff follows the name and tag
//
// Following that, there is a varint-encoded length of the name,
// followed by the name itself.
//
// If tag data is present, it also has a varint-encoded length
// followed by the tag itself.
//
// If the import path follows, then 4 bytes at the end of
// the data form a nameOff. The import path is only set for concrete
// methods that are defined in a different package than their type.
//
// If a name starts with "*", then the exported bit represents
// whether the pointed to type is exported.
//
// Note: this encoding must match here and in:
// cmd/compile/internal/reflectdata/reflect.go
// runtime/type.go
// internal/reflectlite/type.go
// cmd/link/internal/ld/decodesym.go
type name struct {
bytes *byte
}
根据注释,第一个字节的flag解析没有变化,但是后续跟着的字符串长度从原先的2个字节变为了varint-encoded。同样tag和pkgpath暂时不解析,逆向时暂时没用到。


