这是一篇NDSS 2021年发表的论文,相关的代码也已经开源,应该是目前比较全面的研究第三源安全的论文,刚好最近也在做软件供应链安全相关的事情,趁着五一假期翻译了一下。很巧的是OpenSSF(SASL也是它们的项目之一)也在4月28号也发布了一篇文章也在号召社区一同来做动态检测,也在Github上开源了相关代码,OpenSSF目前开源的项目只做了安装和导入时候的动态检测,相对简单一些。
由于“网不好的原因”,国内基本都是使用镜像的源,但是各家的同步机制还不一样,又引入了新的风险,例如官方都已经删除了恶意包,但是国内的源上还有,特别是豆瓣的python源,简直就是“毒库”,相关样本基本都可以在上面找到,连一个官方联系方式都找不到;阿里云、腾讯云、清华源能好一些,发邮件之后还能及时删除。在做相关检测时候一定要注意这点,要不然会掉坑里。以下为论文正文。
摘要
包管理器已经成为现代软件开发过程的重要组成部分,它们允许开发人重用第三方代码、共享自己开发的代码、最小化他们的代码库,并简化构建过程。然而,在最近的报告中显示,包管理器已经被攻击者滥用来分发恶意软件,给开发人员和最终用户带来重大的安全风险。例如,在Npm中的eslint-scope,它是一个每周下载量高达数百万次的包,它会窃取开发的凭证 。为了检测近期攻击者使用的供应链方面的漏洞和信任关系,我们提出了一个定性评估解释型语言包管理器功能和安全特性的框架。在定性评估的基础上,我们使用了以下分析技术,例如元数据分析、静态分析和动态分析。经过我们的评估,发现了339个新的恶意包程序,同时提交给对应的官方维护者,进行删除。官方确认了了339个报告中的278个,占比82%,其中有三个包的下载量超过十万次,同时我们也获得了CVE编号,用来帮助感染者快速清除这些恶意包。论文讲述了为解释型语言定制程序分析工具的难点,同时并将我们的流水线提供给社区,用来保护供应链安全。
I 说明 (INTRODUCTION)
很多现代web应用程序是通过解释型语言开发的,应为它们有丰富的库和包。注册表(也可以成为包管理器)像PyPI、Npm和RubyGems,官方提供了一个集中的存储库,开发人员可以搜索和安装附加包来帮助开发。例如:开发web程序时,python提供了Django、Web2py和Flask这样的库,可以快速开发。它们不仅提高了开发过程的效率,同时还创建了一个协作和共享源码的大型社区。不幸的是,攻击者已经找到方法来攻击这些社区,通过伪造或者在下载量较大的包里面植入恶意代码,窃取凭证、安装后门,甚至进行挖矿。
这些问题不仅仅影响小的web应用程序,还包括大型网站、企业、甚至政府组织,他们都依赖于这些语言来开发内部或者外部程序。攻击者可以通过发布恶意包来攻击他们。例如,在npm源中的eslint-scope,这是一个每周有数百万次下载的依赖包,被用来窃取开发者证书。类似的还有RubyGems源中的rest-client,它的下载量超过一亿次,它会在web服务器留下RCE的后门。
这些攻击展示了攻击者如何通过软件供应链攻击来攻击。安全研究员已经发现了这种攻击,并提出了一些解决方案来解决类似问题。Zimmerman等人系统的研究了609个已知的安全问题,揭示了Npm生态中存在巨大的安全风险。另一方面,BreakApp可以隔离不可行的包,来防御对证书的窃取和敏感数据的访问,但是还是不能阻止挖矿程序和后门。此外,还有很多解决方案,假设存在信任关系,并侧重于查找包中的错误,而不是恶意包。更糟糕的是,一些攻击是非常邪恶的,他们会利用社会工程学来伪装自己,首先发布一个“有用的”包,然后等待目标来使用它,然后再进行更新,植入恶意代码。尽管很多安全研究人员正在积极研究这些攻击方法并提出解决方案,但是这些方法都临时性的或者一次性的解决方案。更好的方法是了解软件供应链滥用程序,以及攻击者是如何利用它们的。 同时这个方法必须能够客观的比较不同生态系统中安全的现状。
为此,我们提出了一个框架,强调了关键功能、安全机制、利益相关者和修复技术,用来比较分析不同的注册生态系统。我们使用这个框架来查看注册中心提供了那些特性,执行了那些安全原则,如何在不同方之间委托信任,以及注册中心为后续攻击提供了那些补救措施和应急计划。通过我们的研究来提供切实可行的方案,注册表维护人员可以使用现有的工具和安全原则来实现这些措施,这将提高整个包管理生态的安全性。我们构建了MALOSS,这是一个为解释语言定制的流水线,我们使用它来研究包管理器的安全性,我们也开源了这个流水线,用来帮助社区分析和识别可疑包。
我们通过MALOSS研究了Pypi、Npm和RubyGems上超过100万个包,并在PyPi中识别出7个恶意包,在Npm中识别出41个恶意包,在Ruby中识别了291个恶意包。我们向对应的社区提交了相关报告,并删除了278个,占比超过82%。被检测出的恶意包中有3个安装量超过10万,它们被分配了CVE编号。我们将展示一个深入的研究案例,来展示MALOSS的检测能力,展示这些恶意包的复杂性,以及他们的感染方式、功能和持久化。此外,为了研究这些恶意包的影响,我们使用Passive dns数据来评估这些恶意软件包的安装范围。最后,我们提出了可行性方案,来帮助提高包管理器的整体安全性和保护软件供应链,例如在客户端添加拼写错误检查,以减少开发人员犯错。
II 背景(BACKGROUND)
注册表是代码共享平台,在软件开发过程中起着至关重要的作用。我们首先来区分四个角色,涉及管理、开发和使用来自注册中心的包,即注册中心维护人员(RMs)、包维护人员(PMs)、开发人员(Devs)和最终用户(Users)。然后,我们提出了注册滥用的概念,并表明现有的研究不能解决供应链攻击的上升趋势。我们将进一步深入研究安全漏洞并明确在保护注册表方面的挑战。
II-A 主要利益相关者(Primary Stakeholders)
我们在Fig 1中概述了主要涉众的特征,以及他们在包管理器生态中的简化关系。注意,涉众是一个角色,可以是个人。
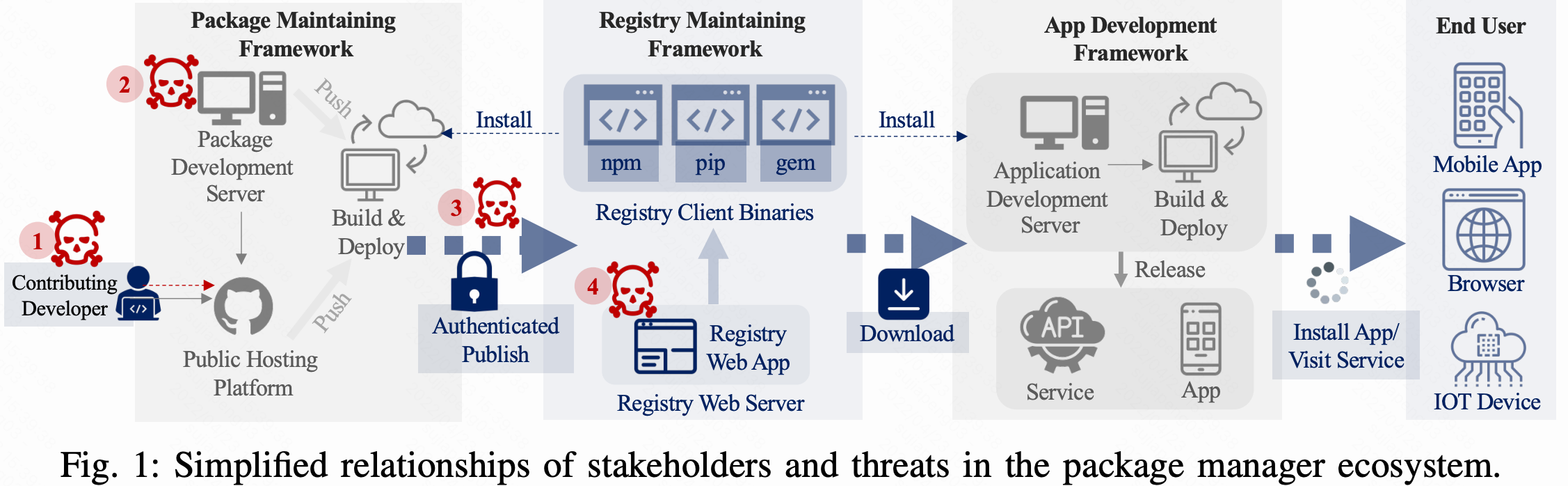
注册中心维护人员
注册表维护者管理注册表框架,并负责运行注册表,注册表是托管由包维护人员(PMs)开发的包的集中存储库。注册表为开发人员提供搜索和安装功能,来帮助他们在注册表中维护相关包。注册表通常由两部分组成:管理和服务包的web应用程序(例如pypi.org)和提供对应的客户端使用程序(例如pypi)。注册表维护者要求包维护者(PMs)在发布包之前进行注册。另一方面,开发人员(Devs)可以通过注册表查询和安装(读取),无论他是否注册。
包维护者
包维护人员管理包框架,负责开发、维护和管理包。包维护者通常使用像Github这样的代码托管平台来管理他们的代码,并与其他贡献者一起协作。他们可能会收到来自对他们项目感兴趣的贡献者的拉取请求,从而允许社区支持其增强和维护,他们可以使用持续集成和持续部署(CI/CD)的流水线来自动化发布(构建和部署)。
开发人员
开发人员使用应用程序开发框架,同时也是发布包的消费者。他们负责找到正确的软件包并在开发中使用,并将产品发布给最终用户。开发人员关注于他们的软件中的功能,并重用来自注册中心的包来实现通用功能。此外,开发人员需要解决重用包中的问题,例如已知的漏洞和不兼容性。
最终用户
虽然没有直接和注册中心交互,但最终用户任然是生态系统中重要的利益相关者。用户处于下游,在浏览器、移动设备或物联网设备上使开发者开发的服务或应用。用户最终是为整个生态系统付费和提供动力,然而,除了反馈渠道外,他们对软件没有控制权,并可能受到上游安全问题的影响。
II-B 注册表滥用概述(An Overview of Registry Abuse)
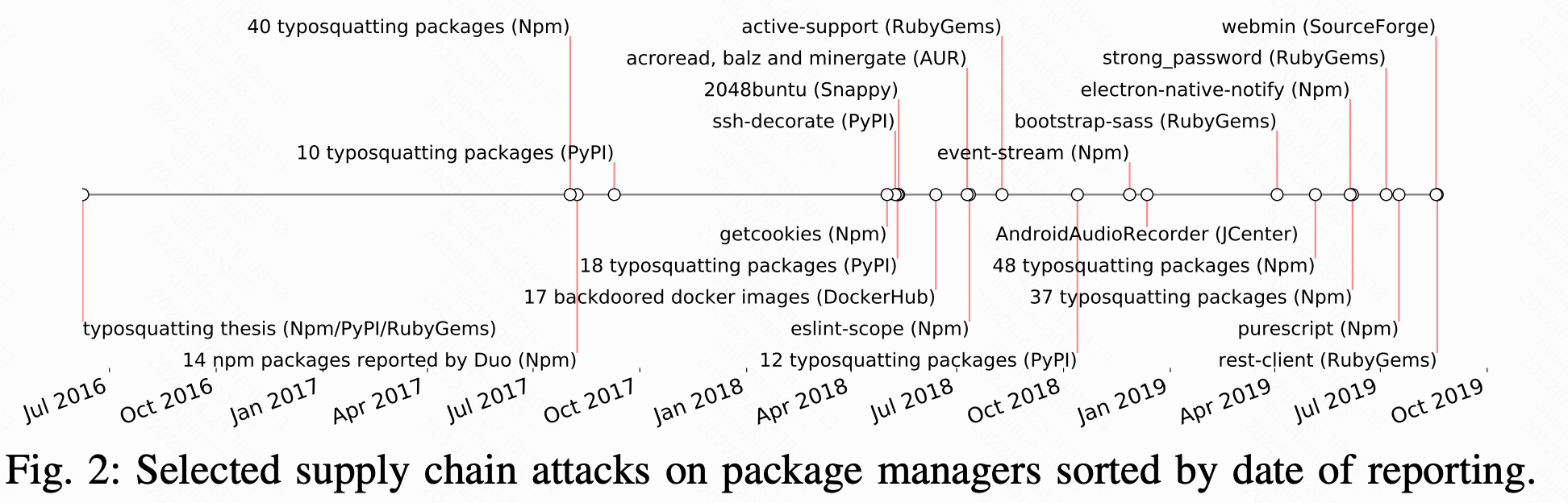
在Fig 2中展示了部分针对供应链的攻击,不同的注册中心都有存在(例如,解释语言,系统范围)。2016年,Tschacher演示了一种针对包管理器的概念验证攻击,该攻击使用了typosquatting技术,就是错误拼写流行包名称,它等待安装包的用户输入错误的名称,从而导致恶意包安装。截止2019年8月,在不同注册表(Pypi、Npm和RubyGems等)中,有超过300个恶意包被报告和删除。
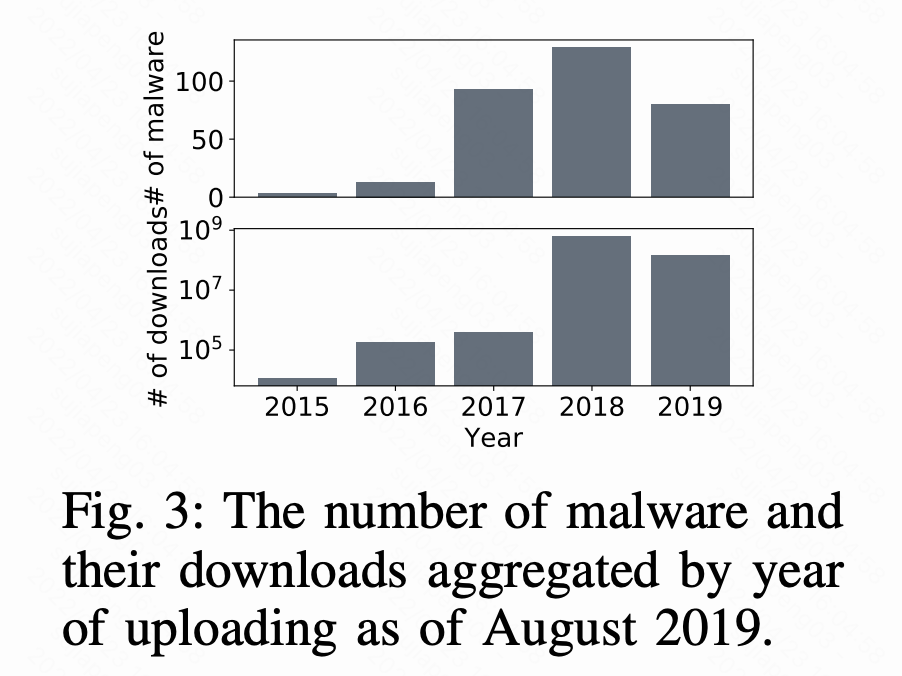
在Fig 3中,我们展示了上传到注册中心的恶意包数量,以及对应年份的下载次数。这些数据是记录/检测到的攻击,是所有攻击(已知和未知的)的子集,仅2018年一年就有100多个恶意包,累计下载量超过6亿次。
Typosquatting只是攻击类型的一种,漏洞平台Snyk最新的一份报告将攻击分为三种类型,即Typosquatting、账户劫持和社会工程。账户劫持是通过窃取认证信息进行账户破坏,而社会工程学是欺骗包存储库所有权转移的欺骗策略。该报告强调,Typosquatting是最常见的攻击策略,因为绝大多数注册中心不执行任何安全策略,如Loden所示。账户劫持是由于攻击者猜到弱口令,而社会工程攻击利用了开源项目的协作性,在许多攻击中都可以看到。不幸的是,社区的焦点一直是通过Synode、NodeCure和ReDos等平台查找包代码中的bug。BreakApp可以实现不可信包的运行时隔离,但由于需要开发人员的使用,实际效果不佳,而且无法应对加密劫持(挖矿)等攻击。注册表维护人员意识到了这些问题,并主动增加了一些安全功能,例如包签名和双因素身份认证(2FA)。虽然增加了一些安全措施,但是包注册中心中的恶意包数量还在上升。
II-C 保护注册表的挑战(Challenges in Securing Registries)
为了防御针对包维护人员(PMs)的供应链攻击,需要对生态系统进行深入分析,以了解那些部分被滥用,谁对此负责,如何才能更好的防范此类攻击,以及可以采取那些措施进行补救。虽然为每个威胁提出修复措施可能很简单,例如账户的2FA,但是系统地理解脆弱环节并提出对策仍然是一个挑战。为了实现这一点,我们在 III-A 中提供了一个框架来定性的分析Pypi、Npm和RubyGems注册表。我们为什么选择这几个解释型语言的包管理器,因为它们在开发人员中很流行,并且遇到了最多的供应链攻击。该框架通过系统地分析注册表的功能、安全性和补救功能,以及已知攻击的攻击载体和恶意行为,来展现存在的问题。
从定性分析中得到一个重要结论,注册管理机构目前几乎没有发布包的审查过程。因此,我们的直觉告诉我们,应该还有很多未知的恶意软件存在。为了验证这一点,我们使用大家所熟知的程序分析技术,如元数据、静态和动态分析来研究注册表滥用。然而,现有的工具存在准确性和覆盖不全的问题。首先,由于这些包有可能有大量的依赖关系,直接对它们进行静态分析,会有大量的时间和空间开销,而且在重复分析常用包时还会浪费计算资源。例如,eslint和electron都在Npm上重用了超过100个包,包括间接依赖。受StubDroid的启发,我们实现了模块化的静态分析,将依赖整理成特定格式,以便进一步重用。其次,这些包是用动态类型的语言编写的,可以很灵活的执行,存在静态分析不准确和运行时动态分析很复杂的问题。在这项研究中,我们采取了尽最大努力的方法来分析包的行为,并利用我们对现有供应链攻击的分析来标记可疑攻击。然后,我们以迭代的方式分析检测结果,来识别和报告恶意包。值得注意的是,我们并不是要找到程序分析方面最先进的技术,而是将现有的工具编译成社区可以在其基础上进行构建的流水线。令人惊讶的是,我们在 III-B 中发现的339个恶意程序中,其中3个下载量超过10万次。
III 方法(METHODOLOGY)
III-A 定性分析(Qualitative Analysis)
自2018年以来,我们一直在跟踪对注册表的供应链攻击,重点关注Pypi、Npm和RubyGems,它们受到的攻击最多。通过对这三个注册表进行镜像,我们获取了312例报告的攻击样本。为了分析这些攻击,我们提出了一个框架,可以对注册表进行比较分析,以确定根本原因和安全漏洞。这个框架的灵感来自于对包管理生态中的管理和开发过程建模。我们论述了现有生态系统中的风险,并展示了如何将其应用到我们的框架中。
III-A1 注册表功能(Registry Features)
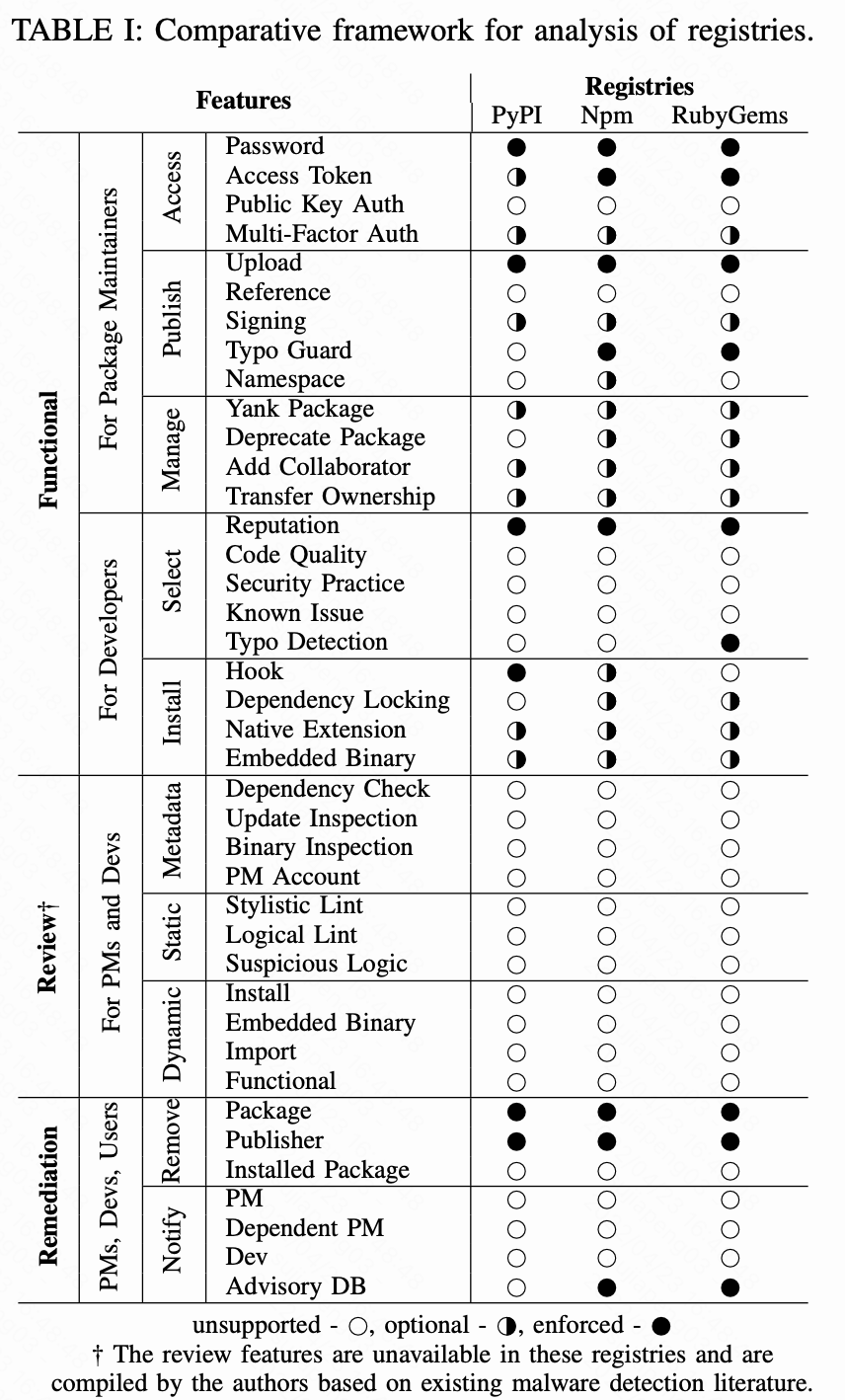
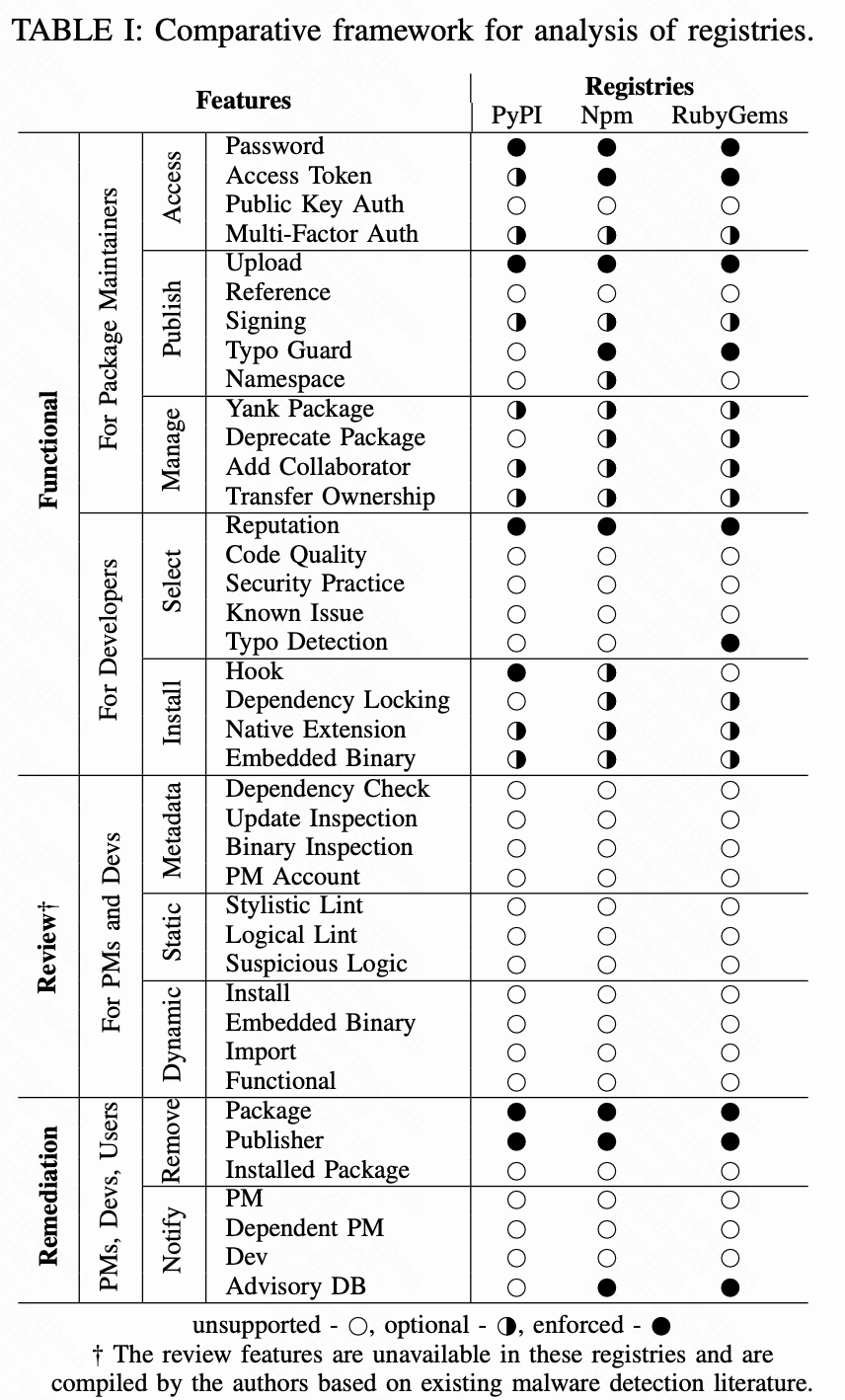
注册表是包管理器生态系统的核心组件,提供包托管和账户保护等功能。我们在 Table1中列出了PyPi、Npm和RubyGems的特性,分为三类,即功能、复查和补救。
功能特性(Functional Features)
如Fig 1所示,作为供应商的包维护者(PMs)登陆账户,并在注册中心发布和管理他们的包,而作为消费者的开发者(Devs)从注册中心选择和安装包。每个注册表有不同的安装方式和不同的发布方式。
Access :指注册中心如何对包维护者(PMs)进行身份验证以发布包。我们将研究与账户安全相关的特性,如公钥身份验证和多因素身份认证(MFA)。
Publish :指的是如何打包并将其发布到注册中心。我们将研究发布的方法,例如由包维护者(PMs)上传和包开发存储引用。我们还研究了一些打包特性,如签名和命名规则,比如防拼写错误规则。
Manage:指如何管理包以及允许对包进行那些控制,包含按版本删除包、弃用包或添加授权的协作者。
Select:指评级或信誉评分,可以帮助开发者选择正确的包,并添加为依赖,我们关注与存储库和作者评级、声誉相关的标准。
Install:指的是开发者安装包的方式,我们关注一些特性,比如可以运行时执行代码的安装钩子,可以指定安全依赖关系的依赖锁定,以及包是否可以包含专有代码。
审查功能(Review Features)
我们定义了注册中心可以实现的审查功能,以主动保护用户访问,并检测脆弱性和恶意包,目前都是不支持。
Metadata:指的是是包的元数据分析,它包括依赖关系分析、作者信息、更新历史和其他打包组件。
Static:指的是只对代码风格和逻辑进行检测,这可能包括发现易受攻击或者恶意代码,此外,还包括使用杀毒软件扫描里面的二进制文件。
Dynamic:指的是是通过动态包来分析包的行为,监控可疑行为,如网络连接、可疑文件访问等。
补救措施(Remediation Features)
一旦注册中心维护人员(RMs)发现需要进一步调查的情况,安全团队就会进行深入调查,并移除对应的包和进行通告。
Remove:指的是在注册中心维护人员(RMs)基于分析报告删除包的主动性,基本操作包括删除受影响的软件包和禁用发布者账户,而主动操作包括删除已安装的包。
Notify:指的是注册中心维护人员(RMs)将相关信息通知给公众的机制,这包括如何通知,例如注册中心维护人员(RMs)可以在git repo上创建一个issue来通知包维护者(PMs),或者通过电子邮件来联系包维护者(PMs),这也包括通知谁。例如,注册中心维护人员(RMs)可以通知受害者(把这个恶意包作为依赖的开发人员)使用恶意依赖。更主动的会试图通知开发人员,发布通告并提出修复建议。
我们手动评估了Table I中部分功能的特性。对于审查和补救特性,我们直接联系了注册表维护人员,来报告我们在流水线中识别出的恶意包。基于我们交流的信息,我们关注相关问题的答复,比如他们有什么可以检测或标记可疑包的方法,并将其记录在下表中的审查和补救部分。此外,我们从他们的博客中收集了信息,这些信息展示了注册中心的安全实践。
III-A2 威胁模型(Threat Model)
Fig 1中高亮显示的部分,我们认为供应链攻击的目的是利用包管理器生态中的上游涉众(即注册中心维护人员和包维护人员),来扩大他们对下游涉众(即开发人员和用户)的影响,我们分析现有的供应链攻击报告,并详细阐述起攻击的载体和恶意行为。
攻击方式(Attack Vectors)
一些威胁覆盖了包管理供应链生态系统。我们对他们进行如下定义,并在Fig 1中用编号对其进行标注。
Registry Exploitation(4)指的是利用注册表服务中的漏洞,这个漏洞可以影响所有包,并修改或插入恶意代码。
Typosquatting(3)指的是名称拼写错误的包,模仿流行包,希望开发者指定错误的包,而不是预期的包,这还包括跨注册表和平台占用的流行包名称(也称为包屏蔽),希望开发者错误地认为它们存在于特定的注册表上。
Publish(3)指的是直接发布包,而不期望出现拼写错误,这可以用于机器人跟踪或者恶意软件托管。
Accout Compromise(3)通过注册表用户的账户泄露,攻击者可以使用恶意包替换该包,或者发布恶意版本。
Infrastructure Compromise(2)指注册表维护人员的开发、集成和部署基础设施的威胁,允许攻击者将恶意代码注入到包中。
Disgruntled Inside(1)指授权的注册表管理者,他们插入恶意代码或者试图破坏开发包。
Malicious Contributor (1)指的是一个正常包,它接收bug修复或者改进的正常包,其中包括引入存在漏洞代码或者恶意代码。
Ownership Transfer(1)(3)指包废弃回收或原所有者将权限转给新的所有者,用于未来的开发,这种转移可以在代码托管网站或者注册表中进行。
恶意的行为(Malicious Behaviors)
在供应链攻击中,我们将受害者视为下游利益相关者,Fig 1中的开发者和用户。开发者可以直接窃取他们证书或破坏他们的基础设施,也可以间接地通过他们的应用程序或者服务接触用户的渠道。用户可能被窃取证书或者损害他们的设备。我们参考公告和博客对现有恶意软件的行为进行总结
- Stealing:指的是获取敏感信息并发送给攻击者,各种类型的信息可能会被收集或者窃取,例如不太敏感的信息,机器标识符或者敏感信息,包括令牌、加密货币、密码甚至信用卡,这些信息泄露直接会造成损失。
- Backdoor:指在受害者机器上留下一个执行代码的后门,后门可以通过多种方式实现。它可以特定的代码或者执行任意命令的反弹shell。
- Sabotage:指的是破坏系统或资源,由于隔离机制这些问题在浏览器中不严重,但对开发人员的基础设施和最终用户的设备至关重要。这可能是为了利益或者恶作剧,删除或者加密文件来破坏系统,并要求支付解密费用(勒索软件)
- Cryptojacking:指通过受害者机器进行挖矿,这是一个正在快速发展的恶意软件家族,也可以在浏览器和其他平台上看到。
- Virus:指利用一个人同时可以是开发者(Devs)和包管理者(PMs),来传播恶意软件,从而感染由他维护的包。
- Malvertising:指的是通过感染者访问受攻击的网站或使感染者访问攻击者创建的广告连接,来赚取收入
- Proof-of-concept:指的是没有实际危害的包,而是为了证明可以进行恶意操作的验证行为。
III-A3 安全漏洞和失信(Security Gaps and Broken Trust)
我们进一步分析Fig 1中列举的供应链模型下的威胁。Registry Exploitation是由注册表维护者(RMs)的实现错误引起的,但这很难出现,也很少发现。Typosquatting是由利用注册表维护人员(RMs)对包维护者(PMs)的信任引发的。Accout Compromise是因为包维护者(PMs)的原因缺少MFA和账户异常检测导致的。Infrastructure Compromise、Disgruntled Inside和Malicious Contributo是由于注册表的安全机制不足,以及利用注册表维护人员(RMs)对包维护者(PMs)的信任引发的,以确保他们的代码和基础设施的安全。Ownership Transfer是由包维护者(PMs)和注册表管理人员(RMs)对新开发者的善意信任引起的。
安全漏洞需要加强生态系统,并且很容易修复。如Table 1所示,注册表维护人员(RMs)可以支持或者强制使用2FA来访问账户,引用代码发布平台的代码来保持代码在托管服务和注册中心之间的一致性,以及在客户端进行Typosquatting检测。此外包维护者(PMs)和注册表维护者(RMs)可以限制能够管理包发布的人员,特别是对于常用包的发布,来最小化风险。
为了更好的理解破损的任性关系,我们在Table 2中列出了利益相关者的信任模型的变化RMs是生态系统中的权威,所有PMs和Devs都必须信任他们。但恰恰相反,尽管RMs可以信任大多数PMs和Devs,但是不应该信任所有人,因为存在潜在的攻击者。由于潜在的恶意贡献者和不满的内部人员的存在。PMs与贡献者和其他PMs互动,也应该减少对他们多数人的信任或者基于声誉的信任。Devs和Users,作为生态系统中的下游用户,不得不相信上游利益相关者,尽管他们可能会添加一些安全机制。另一方面,Devs与Users通过互联网进行互动,但并不信任他们。
III-B 证明(Empirical Measurement)
我们的定性分析表明,三个注册中心目前没有发布审查的过程,现有的发现供应链攻击的方式主要是通过社区报告,并没有自动化检测能力。直觉告诉我们,还会存在更多未知的攻击存在。因此,我们通过程序分析技术,例如元数据、静态和动态分析,来发现新的恶意软件包。值得注意的是,我们并不是在发明一个新的程序分析技术,而是通过分析已经发生过的攻击,来创建一个具有审查功能的流水线,用于分析包和发现潜在的攻击。
我们在Fig 4中展示了检测流水线MALOSS的工作流和内部组件,它由四个组件组成:元数据分析、静态分析、动态分析和真实性验证。来自注册中心的包由三个分析组件处理,来生成揭示可疑活动的中间报告。
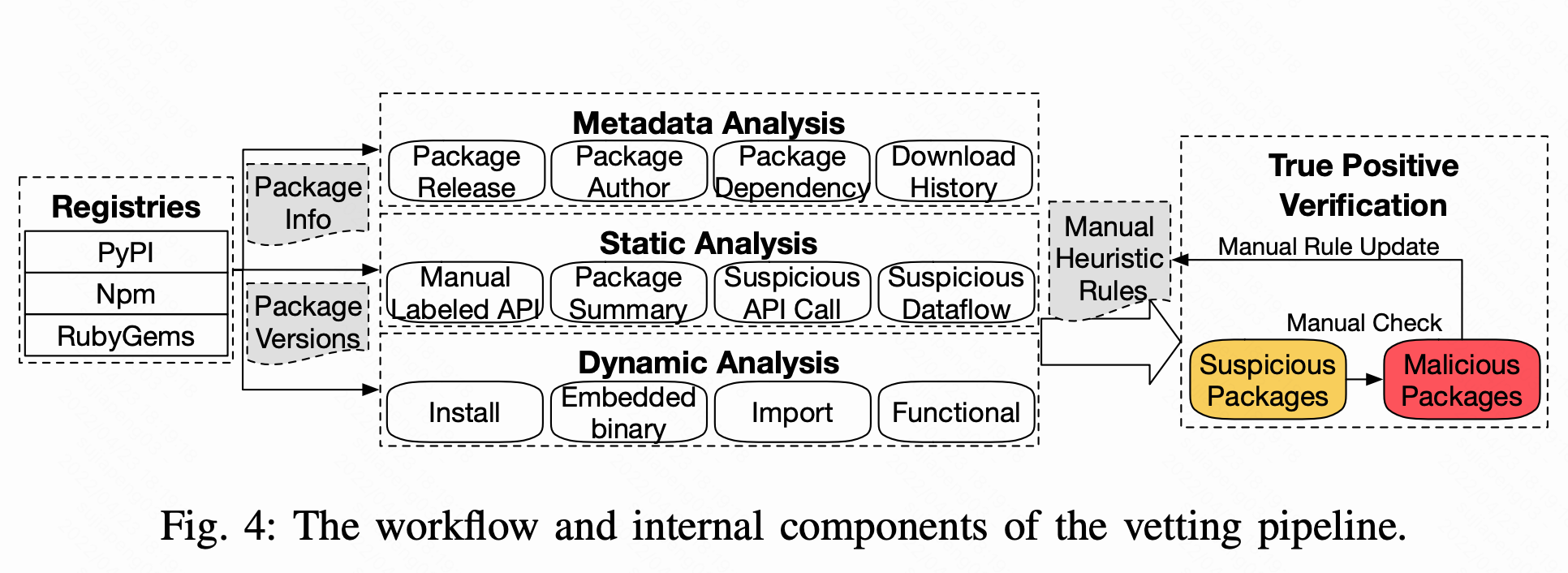
III-B1 元数据分析(Metadata Analysis)
元数据分析集中收集包的辅助信息(例如包名、作者、版本、下载量和依赖关系),并根据不同的标准聚合它们,所有信息都直接从注册表API获取,元数据分析可以标记可疑包,以及识别与已知恶意软件类似的包。例如:包名的编辑距离可以帮助它们的名称对包进行分组,允许精确定位流行包的伪造包;作者信息可以对包进行分组,允许识别来自已恶意包作者的包。元数据分析还包括包中附带的文件类型,以确定是否存在二进制文件或本地扩展。
III-B2 静态分析(Static Analysis)
静态分析侧重于分析每个包管理器对应的解释语言的源文件,跳过嵌入的二进制文件和本地扩展。分析包括三部分:API手工标注、API使用分析和数据流分析。为了在存在大量依赖的情况下实现高效处理,我们使用包摘要执行模块化分析
API手工标注(Manual API Labeling)
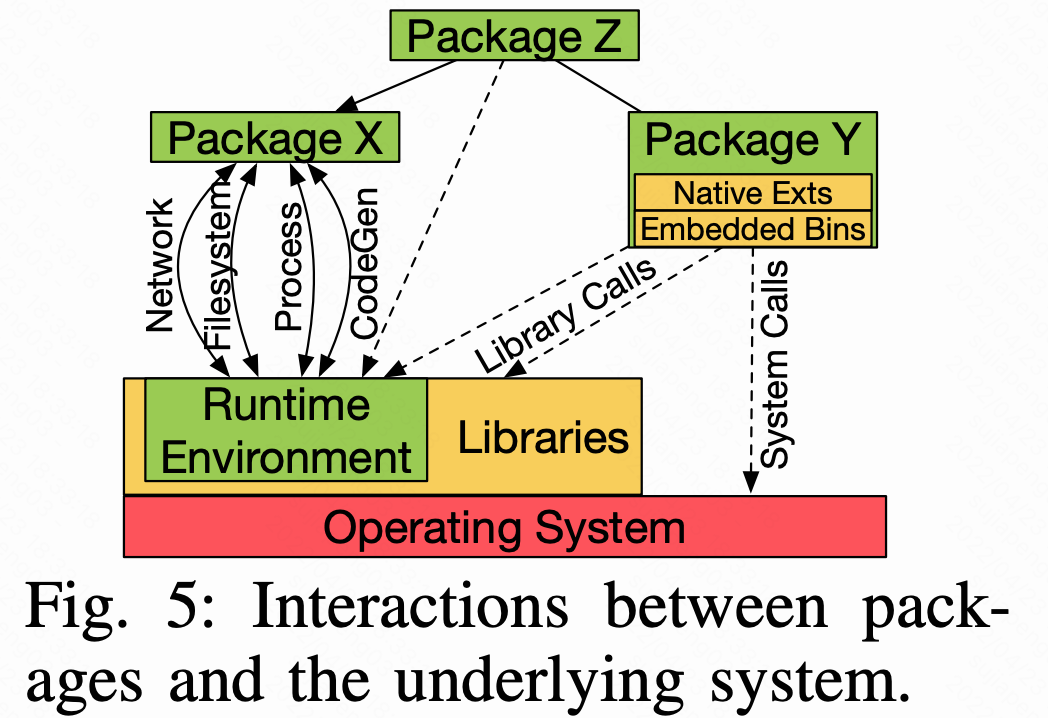
如Fig 5所示,我们在静态分析中关注四种类型的API,即网络、文件系统、进程和代码生成。网络API允许通过各种协议进行通信,如套接字、HTTP、FTP等,它们被用于泄露敏感信息,获取恶意代码等等。文件系统API允许文件操作,如读、写、chmod等,它们被用来泄露ssh私钥,感染其他包等等。进程API允许操作进程,如创建、终止和权限更改等,它们被用来创建恶意进程。代码生成API,允许运行时执行时代码的生成和加载,例如eval和nodejs中的vm.runlnContext,它们被用作加载恶意payload。
我们手动检查每个注册表运行时的的API框架,并检查它们是否属于上述类别。进行数据流分析时,如果它们返回敏感或者可疑数据,我们进一步将它们标记为数据源,如果它们能对输入进行可疑操作,我们将它们标记为数据接收器。值得注意的是一个API可以是源也可以是接收器,例如在nodejs中的https.post即可以接受数据,又可以发送敏感信息。此外,一些接收器API不必与源一起来执行恶意行为。例如nodsjs中的fs.rmdir是一个接收器,如果它的参数来自用户输入,会引发一个告警。但及时没有消息来源,fs.mkdir能通过硬编码路径到根目录,来破坏用户机器。因此我们需要识别可疑的API以及流。附录中的Table V有更详细的标签。
API使用分析(API Usage Analysis)
我们使用相关技术把包的源文件解析为抽象语法树(AST),并在AST中搜索手动标记API的用法。对于全局命名空间中的API(例如Python的eval),我们使用它们的名称将它们与函数调用进行匹配。对于类的静态方法或者模块的导出函数API(例如Nodejs的vm.runlnContext),我们通过跟踪类或模块的别名并匹配他们的全名来识别它们的使用情况。对于作为类实例方法的API,由于在动态类型语言中标示它们是一个开放问题,我们做了一个权衡,以两种方式标识它们的使用:只使用方法名和方法名称为默认实例名称。虽然前者可能会高估,而后者可能会有误报和漏报,但我们认为它们在评估API使用方面任然有用。例如,通过处理Listing 1中eslint-scope的恶意代码片段,我们可以识别静态方法https.get下载恶意代码和全局函数eval执行。

此外,包存在依赖关系,可以通过依赖关系导出函数间接调用的可疑API,例如 Listing 2里面的discord.js-user通过依赖项窃取discord令牌。处理间接API使用的一种直观的解决方案是分析每个包和对应的依赖关系,但这可能会导致对常见包的重复分析,如果依赖关系太多,可能会导致资源耗尽。因此,为了提高效率和减少故障,我们执行模块化的API使用分析,对每个包只分析一次。首先我们构建一个所有包的依赖树,并分析那些没有依赖的包的API使用情况。然后,我们沿着依赖树往上走,并结合包及其依赖的API,Pk 表示包k的api,i表示k的依赖包,我们计算k的组合api为UiPiUPk

数据流分析(Dataflow Analysis)
为了进行数据流分析,我们调查和测试了每种解释型语言的开源工具,并选择Python的PyT、JavaScript的JSPrime和Ruby的Brakeman,我们使用这些工具来分析配置了自定义源和接收器的包,并识别任何发送端到接收端之间的数据流。通过使用这些工具,流水线继承了他们在准确性和可伸缩性方面的局限性。我们认为,如果有更好的替代方案,这些局限性可以得到改善。通过数据流分析,流水线可以支持更有表现力的启发式标记规则。
与API使用分析类似,数据流分析需要处理依赖项流出和流入的关系。受StubDroid的启发,通过总结Java包的依赖关系,来加速后续的数据流分析,我们对包进行数据流分析,检查它们导出的函数是否为从已知源返回间接源的值,或者参数传递到间接接收器,或者传播节点返回派生的值。当我们沿着所有包的依赖关系树分析时,我们输出已识别的流,以及间接源、间接接收端和传播节点,它们被合并到定制的配置中,用于后续分析。例如,我们可以首先总结请求,发现其导出的函数请求调用了https.post,然后分析Listing 2中的代码,发现了通过网络泄漏令牌的恶意流。
III-B3 动态分析(Dynamic Analysis)
动态分析集中分析执行包时的系统调用。与静态分析相比,动态分析考虑源文件、二进制文件和本地扩展,但它对运行时的环境没有可见性(例如不能跟踪eval)。分析由两部分组成,使用Docker容器作为沙箱执行包,使用sysdig进行动态跟踪,来提高效率和可用性。
包执行(Package Execution)
包有不同的执行方式,例如独立的工具或者库,这些应该在动态分析中考虑。因此,我们以四种方式执行包,即安装、嵌入二进制、导入和功能。对于安装,我们运行安装命令(例如npm install <name>)来安装包,这将触发定制的安装脚本(如果有的话),并允许攻击者根据用户的权限进行操作。对于嵌入的二进制文件,我们执行在包中携带的二进制文件,因为攻击者可以包含已经构建好的二进制文件或者混淆代码,来进行对抗。对于导入,我们将包作为库导入,以触发初始化逻辑,来检测是否有攻击行为。对于功能,我们对导出的函数和类库进行模糊测试,来测试他们的行为。当前例子调用定义的函数,用空参数初始化类,递归调用模块和对象的可调用用属性。在执行包时,我们使用Docker作为沙箱,来保护真实系统避免遭受恶意软件的攻击(Listing 3所示)。
动态跟踪(Dynamic Tracing)
为了捕获进程与底层系统的交互,在Linux系统中有三种流行的工具,即Strace,Dtrace和Sysdig。经过对比,我们选择了Sysdig作为跟踪系统调用的工具,因为它效率高,可用性好。为了充分利用计算资源,我们并行分析多个包,每个包在一个独立的Docker容器中,其名称包含包的信息,如名字、版本等。Sysdig捕获系统调用,并将它们与用户空间信息(docker名称)关联起来,从而允许我们区分不同容器里包的行为。在进行原型设计时,我们跟踪ip、dns查询、文件和进程相关的系统调用,并将它们存储到文件中进行下一步处理。
III-B4 真阳性验证(True Positive Verification)
验证步骤是半自动化的,包括基于启发式规则标记可疑包的自动化过程、检查恶意和更新规则。更新后的规则用于迭代过滤和缩小可疑包的范围。通过学习现有的供应链攻击和其他恶意软件的研究,我们定制了一组启发式规则,完整的规则见TABLE III

元数据分析规则(Metadata Analysis Rules)
为了发现typosquatting攻击,我们使用编辑距离来表示与注册表内或跨注册表的流行包名称相似但作者不同的包。为了通过找出可疑包,我们标记依赖于已知恶意软件或具有相似的作者和发布模式的软件包。我们会对携带了提前建好的二进制文件的包进行标记,例如同时携带的多个二进制文件(windows PE和linux ELF文件)。
静态分析规则(Static Analysis Rules)
首先,恶意软件通常在安装过程中执行恶意代码,我们通过安装逻辑来标记可疑包,其次,因为账户泄露而发布的最新版恶意软件,会使用以前没有出现的网络、进程或者代码生成API,我们会标记这些包。第三,根据植入恶意软件之后的行为,窃取行为和后门行为通常会有网络请求,我们用特定类型的流标记包,例如从文件系统源到网络接收器的流,以及从网络源到代码生成接收器的流。
动态分析规则(Dynamic Analysis Rules)
首先,收到窃取信息和后门需要网络通信行为的启发,我们标记与非白名单IP或域名的网络请求,其中白名单IP或域名来自官方域名(例如pypi.org)和代码托管服务(例如github.com)。其次,受到恶意行为的启发,通常涉及对敏感文件的访问,如果它们对这些文件(例如/etc/sudoers,/etc/shadow)进行读写,我们会标记这些包。第三点,受加密劫持通常会产生一个用于挖矿的进程,我们用非白名单之外的进程标记包,其中白名单进程像安装命令(例如pip)
然而,为注册中心维护者(RMs)或包维护人员(PMs)提供了信息,但是必须手动筛查可疑包,以最终确认是否为恶意包,或将它们标记为假阳性,来帮助更新启发式规则。为了避免规则更新时的重新计算,将分析的中间结果缓存起来。我们反复执行基于规则的过滤过程和手动标记过程,来检测恶意软件。
IV FINDINGS(发现)
基于III-B4的启发性规则,我们反复标记可疑包,更新规则,最终发现339个新的恶意软件, 其中PyPI中存在7个,Npm中存在41个,RubyGems中有291个。我们报告的这339个新的恶意软件,被注册中心维护者(RMs)确认和删除了278个,占比82%,其中PyPI中的7个恶意包均被删除,Npm中的41个均被删除,RubyGems中的291个被删除252个。在被删除的软件包中,有3个(即paranoid2, simple_captcha2 and datagrid)下载量均超过10万,这表明存在大量的受害者。因此,我们申请了CVE(CVE2019-13589, CVE-2019-14282, CVE-2019-14281),希望潜在的受害者能够收到通知并及时补救。此外,我们再附录中列出了61个已经报告旦未删除的包。
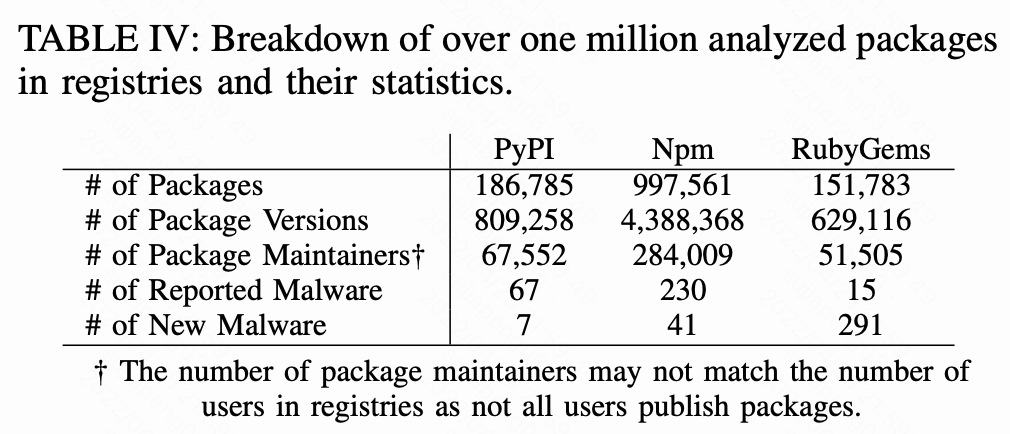
在本节中,我们将339个新的恶意软件与312个社区报告的恶意软件结合起来,见Table IV,并使用III-A中提出的框架和术语分析这些供应链攻击,以理解其攻击方式和影响等方面。此外,我们列举了正常包中的反分析技术和看似恶意的行为,来提高研究社区的意识,并避免调入陷阱。
- 注册中心的包通过一些直接依赖紧关联到很多间接依赖,这意味着包维护者(PMs)要确保直接重用包的质量,注册中心维护人员(RMs)需要检查间接依赖是否恶意。
- Typosquatting和账户被攻击是最容易被利用的对象,这表明攻击者倾向于使用最低的成本进行攻击,这表明注册中心维护人员(RMs)缺乏安全意识,包维护者(PMs)缺乏对账户的保护意识。
- 窃取和后门是最常见的恶意行为,这表明所有下游利益相关者都是目标,包括最终用户、开发人员甚至是企业。
- 其中20%的恶意软件再包管理器中上传超过400天,下载量超过1千,这意味着缺乏应对措施和潜在的巨大风险,把它们作为依赖的包的影响范围将进一步扩大。
- Passive-DNS数据显示了供应链攻击的有效性,并验证了我们的直觉,即大型用户群可以帮助并及时纠正安全风险。
- 攻击者会使用代码混淆、多级有效payload和逻辑炸弹等技术来逃避检测
- 注册系统缺乏相关规定和对应的策略,导致了诸如信息窃取和用户跟踪之间的没有明确的界限等问题。
IV-A 实验(Experiment Setup)
实验环境
我们使用20个本地工作站,运行Ubuntu 16.04操作系统,硬件配置为64G内存和8个3.60GHZ的Intel Xeon cpu,从PyPI、Npm和RubyGems下载并分析所有包及其版本。我们使用NSA用60TB的硬盘来存储。我们使用NAS服务器来镜像来自注册中心的包,以及元数据,并存储分析结果。注册表镜像允许我们能获得恶意软件的副本,即使它们被删除。
工具和数据集
对于元数据分析,我们从官方注册表API收集包以及版本的辅助信息。对于静态分析,我们使用AST解析和数据流分析的开源项目。为了进行模块化分析,我们构建依赖树,并使用Airflow为来进行分析,它可以使用有向无环图(DAGs)来调度任务。对于动态分析,我们使用Docker作为沙箱,使用sysdig进行系统调用跟踪。我们使用Celery来进行任务调度。为了了解供应链攻击的受害者,我们与一家主要的互联网服务商(ISP)合作,根据其passive DNS数据来进行相关查询。
IV-B 数据统计(package Statistics)
我们使用流水线检查超过了一百万个包,如Table IV所示,其中PyPI处理的包为186K,Npm处理的包为997K,RubyGems处理的包为151K。下文我们会进行详细讲解。
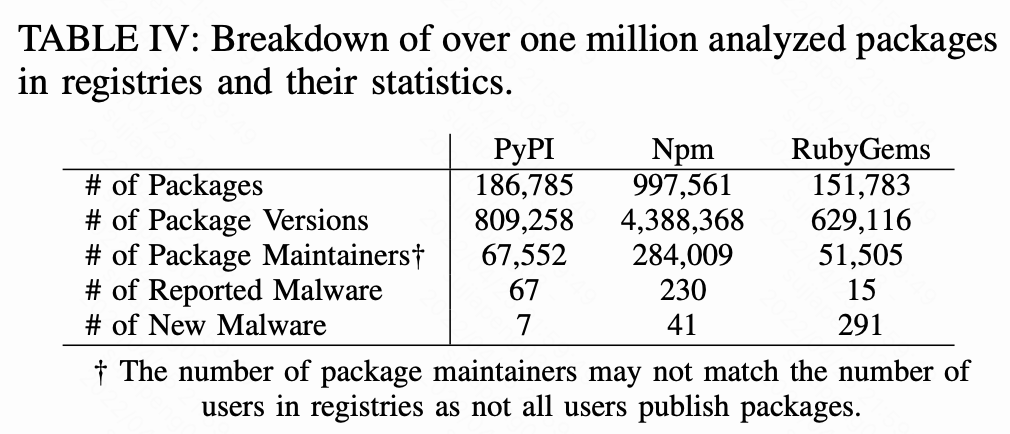
元数据分析
对于注册中心中的所有包,我们再Fig 6a中展示了每个包版本数量和下载数量的分布。版本数量的分布表明80%的包少于7到9个版本,不同的注册中心有相似的分布,这意味着跨注册中心有相似的发布模式。相比之下,下载数量的分布在不同的注册表中是不同的,20%的RubyGems和PyPi包下载次数分别超过了13835次和678次,说明在RubyGems上发布的包被下载和重用的频率更高。
我们还展示了Fig 6b中下载量排名前10k包的依赖项计数分布,包括直接依赖和间接依赖。其中80%的包由2个或更多的直接依赖项,这将增加到20个或更少的间接依赖项,这意味着包维护者(PMs)需要确保重用的OSS质量,以及注册中心管理人员(RMs)需要来检查这些包是否恶意。在Fig 6b中,间接依赖项的最大数量超过1K,这意味着当经常使用的包被破坏时,影响会更大。这表明PyPI和RubyGems面临着类似于之前强调的Npm风险,比如单点故障和未维护包的威胁。
静态分析
我们在Fig 7a中展示了使用可疑API下载量前10K包的百分比。与直觉想法,代码生成API,例如eval是危险的,但是很少使用。Fig 7a显示7%的PyPI包和10%的RubyGems包使用代码生成api。此类代码生成的API不仅常用于供应链攻击,而且如果它们的输入没有得到校验,也可能存在代码注入漏洞。

动态分析
我们动态分析注册表中的所有包,方法是将它们放在Docker容器中,并使用Sysdig跟踪它们的行为。Fig 7b显示了根据III-B4中的检测模式,每个注册表中存在意外动态行为的包的数量。从图中可以看出,Npm和PyPI比RubyGems拥有更多带有意外网络活动(IP访问和DNS解析)的包。需要注意的是,安装期间的意外行为会被依赖包放大,导致Fig 7b中出现大量标记的包,随后通过检查依赖树来消除这种误报。
IV-C 供应链攻击细节(Supply Chain Attack Details)
我们按照III-A 中提出的框架和术语,系统的分析了651个恶意软件,在演示时,我们使用Overall来表示总体报告的恶意软件,Community表示由社区报告的恶意软件,Authors表示由作者报告的恶意软件。
攻击向量
我们根据恶意软件的攻击向量在Fig 8a中进行了分类,其中typosquatting是最容易被利用的攻击向量,其次是账户泄露和包发布。由于攻击者倾向于使用低成本的方法,所以typosquatting和publich将占主导地位,这是很直观的。然而,账户泄露意味着注册中心维护人员(RMs)没有开发相关的安全性功能,并且包维护者(PMs)缺乏保护账户的意识。其他攻击向量虽然不显著,例如恶意贡献者和所有权转移也会被利用,表明包管理器的生态系统中每个利益相关者都应该提高安全意识和参与到这场战斗中来。

恶意行为
我们根据恶意软件的恶意行为在Fig 8b中进行了分类,其中获取信息是最常见的行为,其次是后门、概念证明和加密劫持(挖矿)。我们进一步分析了信息窃取的行为,发现大约有四分之三的人收集不太敏感的信息,例如用户名、ip等,对开发者和最终用户造成的危害较小。其余的收集各种敏感信息,如密码、私钥、信用卡信息等等。至于后门和加密劫持,这种行为的流行表明,攻击者不仅针对最终用户,还针对开发人员和企业的基础设施,这意味着需要开发人员和企业立刻采取行动。
持久性
我们在Fig 9中展示了每个恶意软件的存在天数和下载量分布,其中20%的恶意软件在包管理器中注册超过400天,下载量超过1K。截止2019年8月,这三个注册中心都没有宣布采取分析软件或者手动审查流程来检测恶意软件,而是依靠社区报告恶意软件,从而导致恶意软件长期存在。为了更好的理解恶意软件在持久性和流行度方面的分布,我们在Fig 10中展示了发布天数和下载量关系。散点图显示。流行的软件包可能持续的天数更少,这可能因为它们的用户基数更大。如Fig 10所示,识别出18个下载超过10万次的恶意包。我们报告了18个包中的4个。我们报告的三个恶意包,即paranoid2、simple_captcha2和datagrid,已被注册表维护人员确认并删除,分别被分配为CVE-2019-13589、CVE-2019-14282和CVE-201914281。不幸的是,第四个被识别的恶意软件包rsa-compat仍然在线。 它收集关于包、Node.js运行时和操作系统的信息,由于缺乏定义用户跟踪和窃取的策略,它正在被Npm维护者调查。
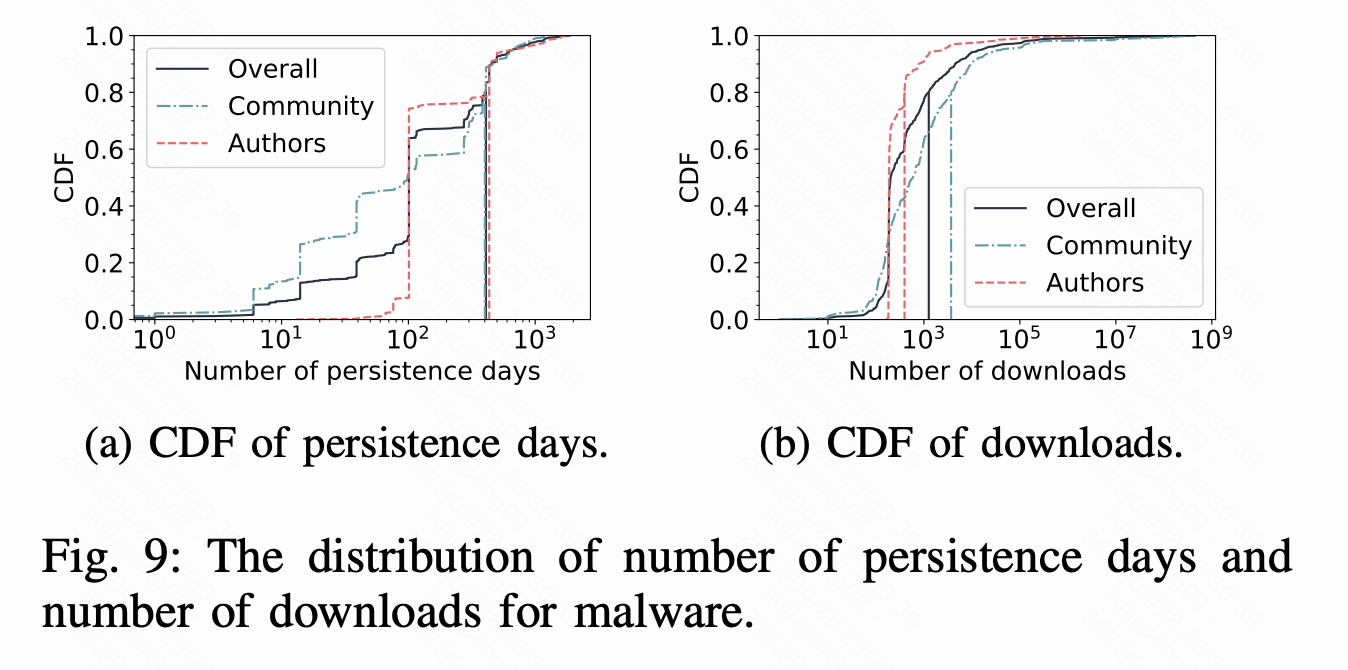
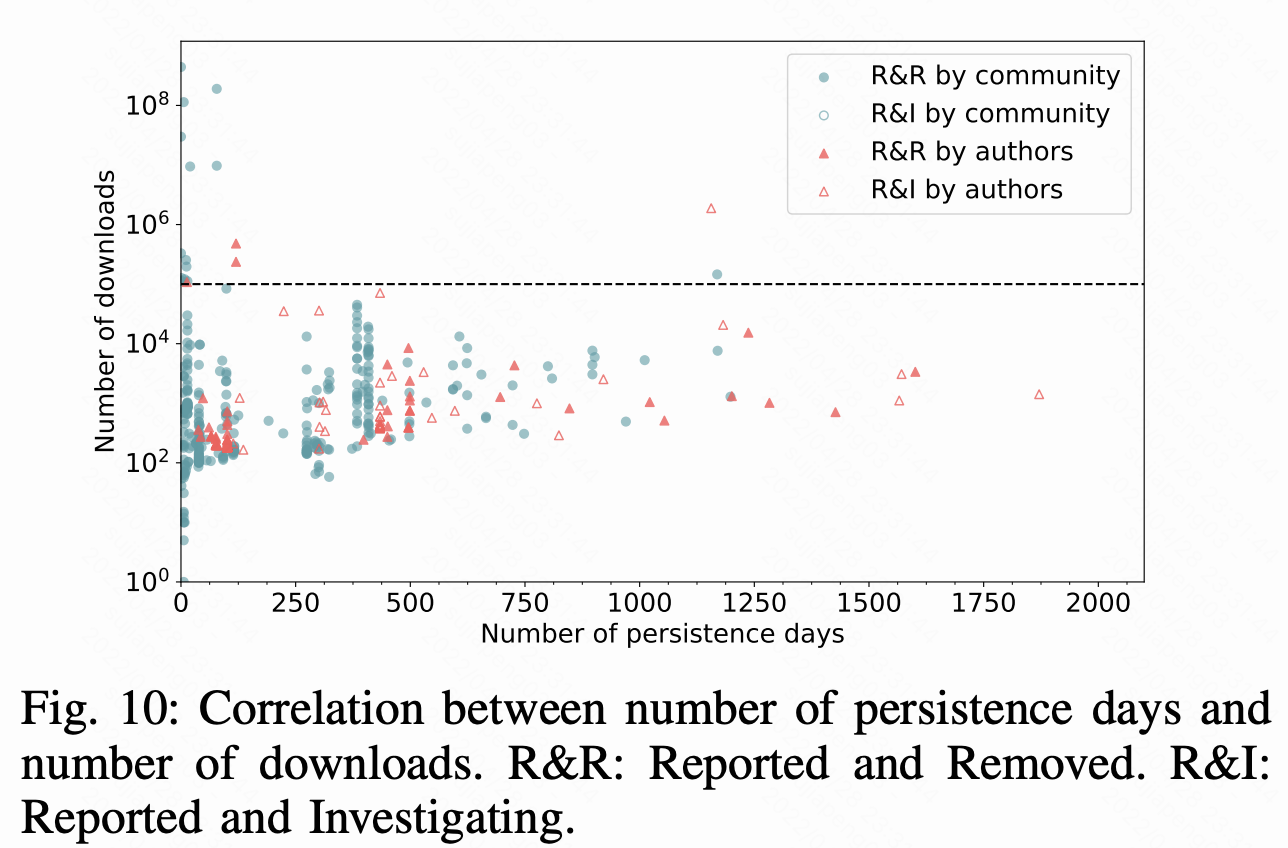
影响
除了恶意软件的特征,我们还衡量其潜在影响,特别是通过检查下载的数量来衡量受影响的开发者和最终用户的规模。从Fig 9b中,我们选在下载量超过1000万的恶意软件。包括正常包和恶意版本在内,最流行的恶意程序包(event-stream 1.9亿下载,eslint-scope 4.42亿下载量, bootstrap-sass 3000万下载量,rest-client 1.14亿下载量)总共下载量为7.76亿。除了直接下载带来的威胁之外,我们还强调,与面向用户的移动应用商店不同,注册表中的软件包还是面向开发者的,从而放大了它们的影响。此外,在Fig 6b的依赖树中,我们发现event-stream有3905个依赖,eslint-scope有15356个依赖,bootstrap-sass有546个依赖,rest-client有4722个依赖。通过衡量它们的依赖下载量,这些软件包的下载量被显著放大,即event-stream 5.39亿次, eslint-scope 25.9亿次,bootstrap-sass 4600万次,rest-client 2.89亿次,总计34,64亿次下载,从而将影响放大了4.5倍
值得注意的是,下载量可能应为CI/CD流水线被放大,并不能真实反映受影响的开发人员和最终用户的准确数量。然而,由于注册中心不提供这信息,甚至可能没有这些信息,我们依靠下载量来评估影响。
感染
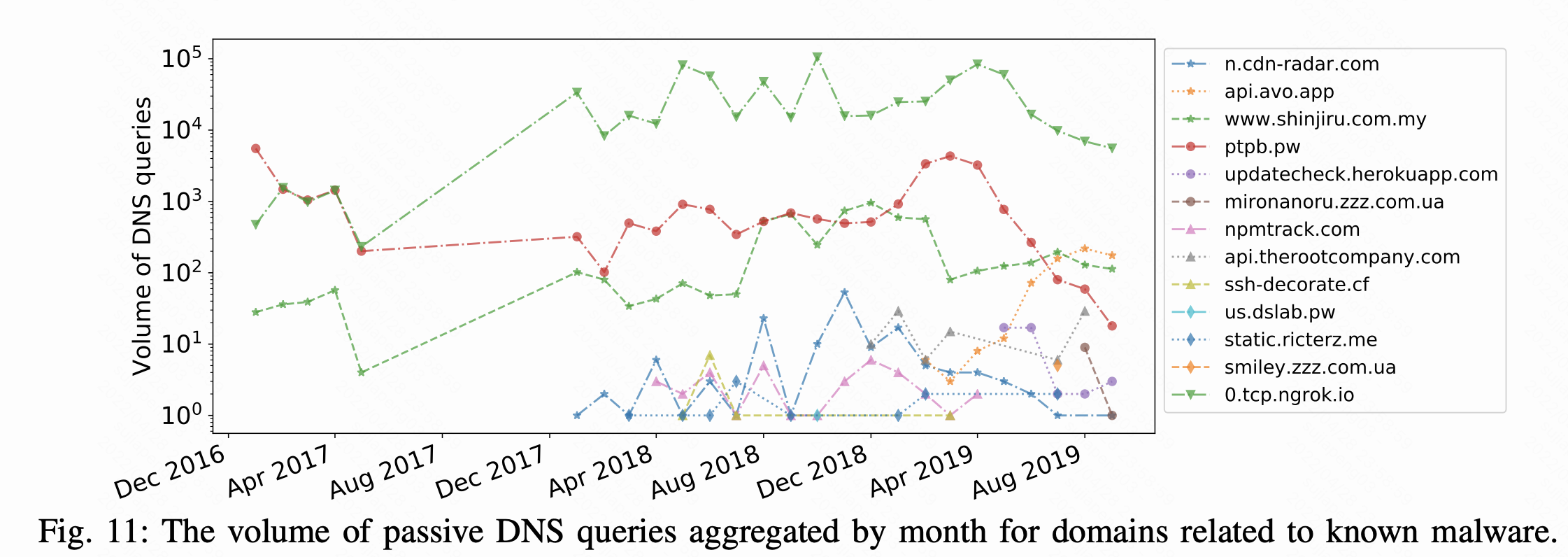
虽然下载量和反向依赖可以间接衡量恶意软件的流行程度,但它仍然是反映不出影响了多少开发者和用户的。受到许多恶意软件的恶意逻辑和网络行为的分析的启发,我们与一个主要的ISP合作,分析和恶意软件相关的DNS查询。我们从手动检查恶意负载和获取域名解析开始。然后是排除常用域名如pastebin.com和google-analytics.com。我们根据ISP共享的passive DNS数据查询相关数据,并在Fig 11中显示它们按月聚合的数据。数据包含2017年1月到2019年9月的查询,但是在2017年6月到2017年12月数据丢失。如Fig 11所示,rest-client使用的域名mironanoru.zzz.com.ua在2019年8月有10次解析,但是在2019年9月几乎为零。这与rest-client在2019年8月被上传和删除的事实相吻合,这表明供应链攻击的有效性,验证了我们的直觉,即庞大的用户群体有助于及时弥补安全风险。ncdn-radar.com是一个用于AndroidAudioRecorder的域名,直到2019年9月都在使用,即使在2018年12月被删除后任然有人感染。近一步的调查显示,没有针对这一事件的报告,受害者可能根本不知道这个问题的存在,这意味着需要建立通报机制。此外ptpb.pw是acroread使用的域名,由于被滥用在2019年3月被永久关闭了,这意味恶意软件会滥用dns查询以及在线服务必须有抗滥用性。
重要的是要注意,感染量是按照经验统计出来的,并且假设少量与恶意软件相关的DNS查询可能受到了污染。然而,如果不能直接接触到最终感染者,我们就不能证明它们被感染。此外,Passive DNS数据可能与DNS查询量存在偏差,作者无法控制或者查看这些数据。
IV-D 反分析技术(Anti-analysis Techniques)
在人工分析恶意代码时,我们注意到恶意软件一直在进化,并利用各种技术来进行对抗。通过分析历史上的恶意软件,我们分类列举了这些技术在软件供应链攻击中的使用情况,来引起社区的注意和帮助它们进一步分析。
良信服务滥用(Benign Service Abuse)
攻击者通过良信服务来隐藏自己,绕过保护机制。例如,在Listing 4中显示rest-client滥用pastebin.com服务来加载它们第二级的代码,使得基于DNS查询的检测技术无法有效检测。类似的AndroidAudioRecorder通过DNS隧道回传信息,IDS通常允许DNS服务。从Fig 11中的DNS查询角度来说,pyconau-funtimes成功地将攻击者隐藏在0.tcp.ngrok.io中,建立了一个安全的隧道。

多级利用代码(Multi-stage Payload)
大多数杀毒软件的检测基于签名,恶意软件倾向于把恶意逻辑分割为多个阶段,并包括使用最少的代码片段来隐藏它们的逻辑和指纹。例如,Listing 4只包含有效负载获取、代码生成和错误处理,并隐藏它的恶意逻辑,如通过pastebin.com加载的获取环境变量的恶意代码。
代码混淆(Code Obfuscation)
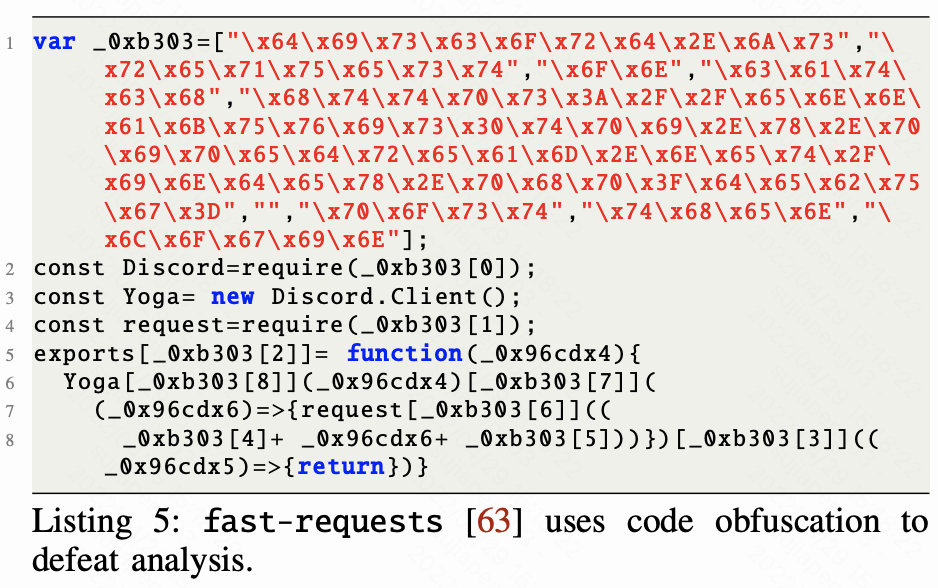
通过已有研究,恶意软件的混淆技术可分为随机混淆、编码混淆、逻辑结构混淆等类别,并指出恶意软件可以对代码进行混淆,从而隐藏恶意逻辑,不受人工检查和自动检测的影响。我们发现供应链攻击也不例外。例如getcookies和purescript都使用了代码混淆。类似的,在Listing 5中fasg-requests使用随机混淆和编码混淆来提高分析难度。
逻辑炸弹(Logic Bomb)
TriggerScope将逻辑炸弹定义为仅在特定(通常较窄)环境下执行或者触发的恶意代码。逻辑炸弹可以用来对抗静态和动态分析方法。例如,如果不是在生产环境中执行,rest-client的动态分析永远不会执行恶意代码(Listing 4的第八行)
旧版本(Older Version)
通过账户泄露发布的个别恶意软件,利用独特的攻击技术来对抗检测。攻击者不是将恶意代码发布到软件包的最新版里面(即最大化受害者的数量,从而增加被捕获的可能性),而是将这些恶意代码,发布到软件包的旧版本,以针对较少的受害者。我们可以想象攻击者的攻击场景是使用旧版本的开发员对安全性不够谨慎,因此将攻击持久性最大化,将检测概率最小化。
IV-E 安全分析的难点(Security Analysis Hurdles)
在真正的验证过程中,我们遇到了几个看似可疑的行为,但是进行分析后是正常包。我们列举这些行为,是为了提高社区的研究意识,避免踩坑,同时希望注册中心维护人员(RMs)可以指定明确相关定义和规范,来规避这些行为。
安装钩子(Installation Hook)
在安装过程中,一些包从在线服务获取数据,并在本地评估或者在敏感位置写入数据。例如stannp使用c.docverter.com将README转换为RST格式,而meshblu-mailgun则试图跳过构建过程,通过在cdn.octoblu.com上下载提前构建好的二进制文件,这种行为类似恶意活动,会污染自动检测的数据。
代码动态加载(Dynamic Code Loading)
应用商店认为在运行时加载代码是可疑行为,会把未知的代码注入到应用程序中。然而,一些正常包在本地也会加载来自远程的代码。例如Listing 6中的net_http_detector会从github.com加载代码。

用户跟踪(User Tracking)
包维护者(PMs)可能想要跟踪用户来改善用户体验或增加业务,但是如果没有明确的界限,信息窃取和用户跟踪之间的界限是模糊的。例如rsa-compat就是因为用户跟踪策略被分析的包质疑(Fig 10),它收集Node.js运行时和操作系统指标,并将数据回传到https://therootcompany.com。
V 缓解(MITIGATION)
V-A 缓解策略(Mitigation Strategies)
我们研究的目的不仅是让人们注意到这个被忽视的问题,而且还为包管理器生态中的利益相关者提供指导,以检测和减轻供应链攻击。我们在III-A3章节强调了注册中心维护人员(RMs)的重要性。然而,从长期来看,随着攻击者的发展,每个涉众都要提高意识并帮助改善安全状况。
注册中心维护人员(Registry Maintainers)
注册中心维护人员(RMs)是整个生态系统的中央,我们根据Table I中的三类特征,即职能、审查和补救,来阐述它们的缓解策略。
功能特点(Functional Feature)
注册中心维护人员(RMs)可以通过提供MFA和代码签名,防止弱口令或密码泄露,检测异常登陆,可以大大提高对账户的保护能力。它们还可以通过在注册表客户端检测输入错误和防止发布流行包的输入错误包。此外,注册中心维护人员(RMs)可以修改策略来保护所有权转移,来规范包的行为,比如在rsa-compat中不通知就跟踪用户,并排除不需要的包。比如restcli,它声称自己是一个防止输入错误的gem包,但是没有证明它是无害的。
审查机制(Review Feature)
注册中心维护人员(RMs)可以扩展审查流水线,来识别包名和现有流行包名类似的包或者使用元数据分析和现有攻击相关的包,使用静态分析可疑的API使用和数据流。使用动态分析分析存在异常行为的包。真正积极的验证过程是可以通过众包的手工评审来实现的。由于包管理器生态系统是一个有项目涉众(如项目经理和开发人员)的开源社区,他们可以参与进来确保生态系统的安全。特别是,当注册中心维护人员(RMs)检测到一个恶意包是,它们可以将该信息广播给相应的开发人员,或者发布”公众投票“的分析结果.
补救功能(Remediation Feature)
由于注册中心维护人员(RMs)拥有最高权限,它们不仅可以从服务器上删除恶意包和发布者,还可以通过比较黑名单从客户端删除包。此外,注册中心维护人员(RMs)还可以通过各种渠道,例如邮件、安全建议和客户端检测,来通知大众相关安全事件。通知包括受影响的包以及依赖的开发人员和包维护者(PMs)。例如,Fig 11所示,AndroidAudioRecorder被删除后的感染量展现了收到通知之后的进行处理的重要性。
包维护者(Package Maintainers)
针对包维护者(PMs)的攻击包括账户泄露、基础设施攻击、恶意内部人员、恶意贡献者和所有权转移。包维护者(PMs)可以通过采用MFA、代码签名和强密码等技术来保护他们的账户。包维护者(PMs)可以通过防火墙、及时安装补丁和IDS保护相关基础设施。包维护者(PMs)需要谨慎对待新的贡献者和不满的内部人员,手动检查小的包,或者为大的包使用代码审查系统。除了增强功能之外,包维护者(PMs)还可以通过向咨询机构报告安全问题、更新依赖关系来避免已知的安全问题、加入”社会投票“和不使用阻碍安全分析的技术来进行开发,来帮助改善整个生态系统。
开发者(Developers)
尽管开发人员不能控制上游包,但是他们可以遵循最佳实践来纠正安全问题。开发人员可以使用已知的安全包版本来托管私有注册表,来避免来自上游涉众的供应链攻击。开发者可以定期查看安全建议,并及时更新,避免已知漏洞。对于不受信任的包,开发人员可以手动检查,部署一个审查管道来检查代码,并在运行时隔离他们,以避免潜在的危险。此外,开发者可以加入“社会投票”来提高安全性分析。
最终用户(End-users)
尽管最终用户不控制任何提供的服务和软件,用户可以利用反病毒工具来保护他们的设备和保护自己。此外,用户可以提高自己的安全意识,只访问官方和信誉良好的网站。
V-B 检测的局限性(Measurement Limitations)
我们检测目的是通过分析已知的供应链攻击,来识别在野的新的攻击方式。我们的目标是展示问题的严重性和普遍性,而不是在程序分析中实现高覆盖率和健壮性。目前的审查的流水线方式存在静态分析不准确、动态分析覆盖范围低、容易逃避检测的问题。我们是为了推动程序分析技术的发展,帮助保护包管理器生态系统。
分析的范围(Scope of Analysis)
当流水线进行原型设计时,我们只考虑在静态分析中为每个注册表使用相应的语言编写的文件,没有包括本地拓展、嵌入的二进制文件和使用其他语言编写的文件。在动态分析中,我们只考虑Linux平台,特别是Ubuntu 16.04。不包括其他Linux发行版、Windows和MacOS。我们只考虑运行时依赖,忽略了开发时依赖。
不准确的静态分析(Inaccurate Static Analysis)
流水线依赖于静态分析中使用的AST解析和数据流分析工具,由于动态类型的原因,这些工具可能不准确。此外,诸如反射和运行时代码生成之类的编程实践也会增加问题,并导致不准确的结果。然而,我们认为可以开发更精确的工具和算法,并在可用时集成到流水线中。
动态代码覆盖率(Dynamic Code Coverage)
尽管在Ubuntu 16.04上面进行四种类型的动态检测,但代码覆盖范围可能有限。还有需要改进的项目例如执行环境多样化(如Windows、浏览器)、强制执行、符号执行等等。
反分析技术(Anti-analysis Techniques)
如IV-D所述,攻击者使用了反分析技术。我们预计未来会出现更复杂的技术,如故意存在漏洞的代码和更高级的混淆。在未来,我们号召研究人员来不断的和攻击者进行对抗。
威胁的有效性(Threats to Validity)
有两个人工步骤依赖实施者的经验。首先,III-B2中的手动标记API检查语言细节和运行时API。不正确的标签可以导致假阳性和假阴性的可疑包。假阳性被真阳性验证第一步排除,而假阴性被会被忽略,会依旧存在在注册表中。第二,III-B4中初始启发式规则和真实实验验证是基于已知攻击者和作者已知知识领域。这个步骤可能会引入错误否定和遗漏恶意软件。
VI 相关工作(RELATED WORK)
软件供应链攻击(Software Supply Chain Attacks)
最早的软件供应链攻击是1983年Thompson实施的,他在编译器中留下了一个后门,即使它的源代码是无害的,也可能影响程序的正常运行。随后,类似的攻击逐步被曝光,目标是各种供应链组件,如基础设施、操作系统、更新渠道、编译器和密码算法。近年来,针对包管理器的供应链攻击逐步上升,这些包管理器依托发布的包,来获得代码共享等好处。最新,Zimermann等人提出一项关于Npm生态系统的研究,解释了社区面临的风险,如单点故障和未维护包的威胁。相反,我们的主要研究室针对三种的包管理器的供应链攻击,来确定根本原因,扫描新的威胁并提出改进意见。作为额外分析,我们对IV-B中的三个包管理器进行依赖分析,发现他们面临着与Npm研究中强调的类似的风险(即单点故障和未维护包的威胁)。由于我们的工作重点是展示供应链攻击特征,因此我们不会进一步量化风险 ,同时在不同注册中心之间进行比较。
包管理安全(Package Management Security)
之前的研究工作包括包管理器的设计和实现,提出了攻击方式和防御建议。这些工作的重点是设计一个更安全的包管理器,它具有诸如折中性和供应链完整性等属性。此外,由于Npm生态系统中漏洞和恶意软件的数量不断增加,各种意见被提出来用来发现新的漏洞,隔离不可信的包,评估风险和修复问题。我们的工作不同于之前的工作,我们研究的是一个针对包管理人员真实供应链攻击的语料库,并提出了可行的改进建议。
安全工具(Security Tools)
我们提出的检查流水线原型是可扩展的,这样就可以将跟多的工具添加到流水线中来识别出更多的问题。例如,针对各种语言的静态分析工具和二进制分析,可以产生更准确和全面的结果。动态分析工具可以增加动态代码的覆盖率,并提供更加多样的平台和环境。此外,现有的威胁情报服务,如VirusTotal和安全博客,可以提供分析工具识别的指标(如文件hash、URL、IP)等信息,从而自动化验证攻击的是否已经被实施。
VII 结论(CONCLUSION)
为了系统性的研究包管理器生态系统中最近发生的供应链攻击,我们提出了一个比较框架,揭示了利益相关者之间的关系。我们找出其根本原因,并总结其攻击载体和恶意行为。基于我们现有知识体系,我们将大众所知的程序分析,如元数据分析、静态分析和动态分析,编译成一个大规模的分析流水线,来展示包的各个方面,并帮助检测恶意包。通过反复验证,我们在PyPI中识别并报告了7个恶意软件,在Npm中识别了41个恶意软件,在RubyGems中识别了291个恶意软件,其中278(82%)个恶意软件已经被删除,3个恶意软件分配了CVE编号。
我们将开源分析流水线,并根据要求提供收集到的恶意软件样本,用于研究目的,来帮助提高包管理器安全性和防御供应链攻击的研究。我们还邀请社区改进它,并邀请注册中心维护人员(RMs)部署它们,来确保实现最低的安全标准。

