0x01 需求背景
公司要弄自动化的扫描工具,目前市面上的工具都无法针对业务进行检测,所以只能自己开发。辣么,就有个问题,爬虫需要自己去写。。。
之前自己也写过相关的爬虫,但是要么是半成品,要么就是垃圾代码…很多都无法直接引用,所以,在强大的KPI考核下,强迫自己代码重构。用Python写起。
0x02 遇到问题
本身在爬虫上轻车熟路,很轻易就写出了一个根据多线程的爬虫,完成整站扫描,但是问题来了,效率如何提高。仔细观察下扫描的链接就发现,它爬取了很多链接,都是一些重复性比较高的链接,例如以下:
[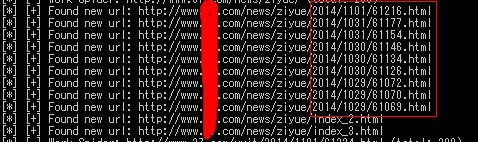
这些链接都是静态的页面,也就是一些新闻之类的,页面架构的都差不多,这个情况我们自己知道,但是爬虫是不了解的。它只是按照我们指定的规则去做,所以导致爬虫效率降低。
在我预想的情况下,一些静态的页面,我们是可以减少抓取的,通过减少抓取我们可以提高整体的效率。例如:
http://www.xxx.com/news/ziyue/2014/1029/61069.html
http://www.xxx.com/news/ziyue/2014/1029/61070.html
http://www.xxx.com/news/ziyue/2014/1029/61071.html
这三个URL中,我们只需要抓取一条作为典型,完全就能达到我们的需求,不需要将所有的抓下来。因为大家都知道,这是伪静态生成的。那么问题来了,该怎样去做这个规则?小伙伴可能有想法说:“你怎么知道这种静态页面就一定架构一样呢?” 好吧,我不确定,但是我有办法去确定。现在就以上面的URL做个拆分了解下:
http://www.xxx.com/ 这个是host
/news/ziyue/2014/1029/ 这个是具体的目录,或者说是具体的文章归类。
61069.html 这个是具体的页面。
上面分析后,小伙伴又有新的问题:“莫装逼,你怎么知道人家的URL一定按照这个标准来?” 好吧,对此我整理了下我所发现的URL组合规则,目前很多URL都是以以下几种方式组成的。
1)静态页面型:
http://[host]/xxx/xxx/xxx/[int|string].html
2)rewrite型:
http://[host]/xxx/xxx/xxx/[string|int]
3)目录型:
http://[host]/xxx/xxx/xxx/Catalog/
4)不固定型:
http://[host]/xxx/xxx/xxx/file.[asp|php|aspx|do|jsp]?[string|int]=[string|int]
0x03 奇葩的实验
找到了这些规律后,应该考虑怎样去把爬虫的质量提升起来,降低重复率,然后就有了以下奇葩的实验:
1)先建立规则:
[
2) 然后针对这些规则进行引用、测试。
[
运行结果诸如:
[
确实达到了我期望的结果…. 本文只是抛砖引玉,可能代码略挫。各位大侠轻拍,射射。
【实验前】
[
【实验后】
[


