0x00 背景
刚看到年初时挖的洞分配了CVE,也有师傅已经做了一些分析并给出了poc证明图,因此我在这里将我当时的一些笔记发出来。在先知上有人对CVE-2021-26086以及CVE-2021-26085都分别进行了分析,这两个CVE分别对应Jira Software Server和Confluence,Confluence分析的较为完整,Jira的分析稍显单薄,由于本质原因基本一样,因此这篇文章就主要说一下Jira。
0x01 影响版本
Jira Software Server 8.0.0 - 8.14.1(2021年1月29日最新版)
0x02 Jira的正常访问/WEB-INF/受限
Jira在部署时,其实质是作为Tomcat下的一个webapp目录进行存放,在访问各页面时,会通过定义在web.xml中的映射关系以及文件本身的路由进行响应。
但是WEB-INF目录作为敏感目录,在直接通过url访问http://0.0.0.0:8080/WEB-INF/web.xml时,会直接返回错误页面,有关于这一部分的限制在于org.apache.catalina.core.StandardContextValve:
public final void invoke(Request request, Response response) throws IOException, ServletException {
MessageBytes requestPathMB = request.getRequestPathMB();
if (!requestPathMB.startsWithIgnoreCase("/META-INF/", 0) && !requestPathMB.equalsIgnoreCase("/META-INF") && !requestPathMB.startsWithIgnoreCase("/WEB-INF/", 0) && !requestPathMB.equalsIgnoreCase("/WEB-INF")) {
Wrapper wrapper = request.getWrapper();
if (wrapper != null && !wrapper.isUnavailable()) {
try {
response.sendAcknowledgement();
} catch (IOException var6) {
this.container.getLogger().error(sm.getString("standardContextValve.acknowledgeException"), var6);
request.setAttribute("javax.servlet.error.exception", var6);
response.sendError(500);
return;
}
if (request.isAsyncSupported()) {
request.setAsyncSupported(wrapper.getPipeline().isAsyncSupported());
}
wrapper.getPipeline().getFirst().invoke(request, response);
} else {
response.sendError(404);
}
} else {
response.sendError(404);
}
}
简单来说,就是访问的路由不能以/META-INF、/WEB-INF开头,并且也不能包含/META-INF、/WEB-INF,因此,当我们访问/WEB-INF/web.xml时就会进入response.sendError(404);分支,得到404。
0x03 访问限制的突破
对于受限目录访问的突破主要依赖于两个函数:org.apache.catalina.core.ApplicationContext.stripPathParams()、org.apache.tomcat.util.http.RequestUtil.normalize()。
在stripPathParams中,主要起作用的是:
while(pos < limit) {
int nextSemiColon = input.indexOf(59, pos);
if (nextSemiColon < 0) {
nextSemiColon = limit;
}
sb.append(input.substring(pos, nextSemiColon));
int followingSlash = input.indexOf(47, nextSemiColon);
if (followingSlash < 0) {
pos = limit;
} else {
pos = followingSlash;
}
}
简单来说,会将访问路径中的;进行忽略处理,比如对于路径/x/..;/WEB-INF/web.xml将会首先取;前的/x/..,再取;后的/WEB-INF/web.xml,最后将两者进行拼接得到:/x/../WEB-INF/web.xml。
随后这个路径会交由normalize进行处理,在normalize中所做的处理简单来说,就是相对路径的抵消,关键代码如下:
while(true) {
int index = normalized.indexOf("//");
if (index < 0) {
while(true) {
index = normalized.indexOf("/./");
if (index < 0) {
while(true) {
index = normalized.indexOf("/../");
if (index < 0) {
if (normalized.length() > 1 && addedTrailingSlash) {
normalized = normalized.substring(0, normalized.length() - 1);
}
return normalized;
}
if (index == 0) {
return null;
}
int index2 = normalized.lastIndexOf(47, index - 1);
normalized = normalized.substring(0, index2) + normalized.substring(index + 3);
}
}
normalized = normalized.substring(0, index) + normalized.substring(index + 2);
}
}
normalized = normalized.substring(0, index) + normalized.substring(index + 1);
}
从上面不难看出,对于传入的路径/x/../WEB-INF/web.xml会进行相对路径的转换,得到/WEB-INF/web.xml,因此也就可以访问该文件,并且由于对WEB-INF以及META_INF路径的限制是在stripPathParams以及normalize的处理之前,因此也不会受到限制了。
0x04 绕过登陆限制
在未登录时,如果直接以ip:8080/x/..;/WEB-INF/web.xml访问,则依旧会重定向至登录页面,因此需要绕过这个登录限制。在上面这个重定向至登录页面的过程中,ApplicationFilterChain中起作用的主要是JiraLoginFilter,受到它的限制才会重定向至登录页面进而要求登录:
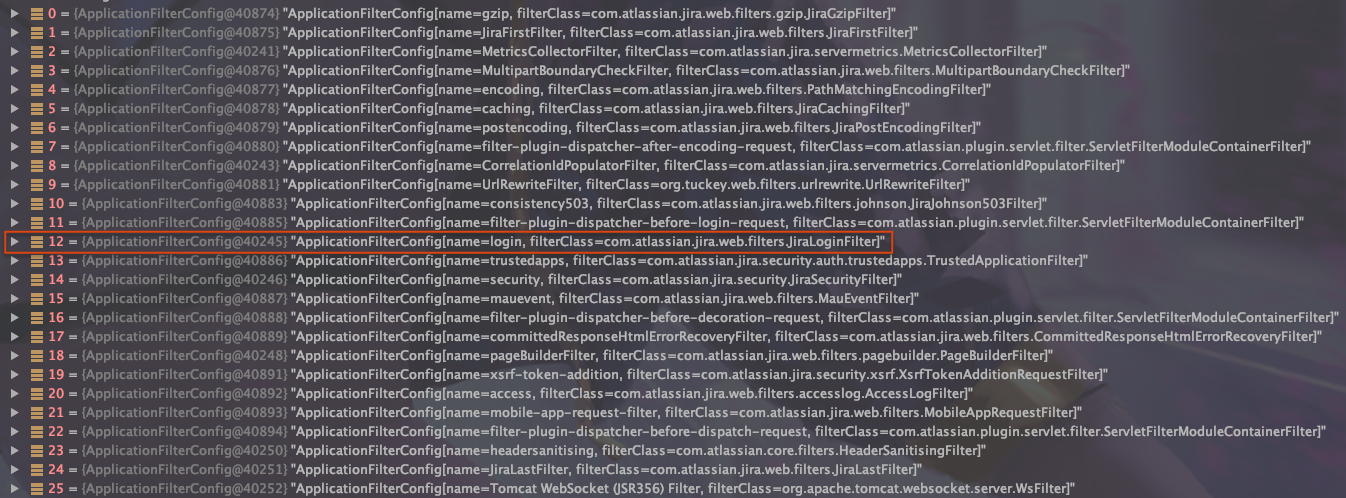
因此绕过登录实际上是找到ApplicationFilterChain不存在JiraLoginFilter这个Filter的加载方式。在Jira中,静态资源的加载并不是直接通过在ip后的路径访问,而是通过如下形式:
http://0.0.0.0:8080/s/x/x/x/x/x/_/download/contextbatch/js/atl.dashboard,jira.global,atl.general,jira.dashboard,-_super/batch.js?agile_global_admin_condition=true&jag=true&locale=zh-CN
整个链接以_分为两部分,前半部分可以直接在首页获取到,其具体内容并不影响文件读取,后半部分则是文件路径。当我们访问这个形式的链接时,会访问到全限定名如下的类:
com.atlassian.jira.plugin.webresource.CachingResourceDownloadRewriteRule
这个类中就会对url进行重组,然后访问重组后的资源,主要实现函数为:
public RewriteMatch matches(HttpServletRequest request, HttpServletResponse response) {
String normalisedRequestUriPath;
try {
normalisedRequestUriPath = this.getNormalisedPathFrom(request);
} catch (URISyntaxException var7) {
return null;
}
final Matcher nonWebInfResourcesPatternMatcher = createMatcher(normalisedRequestUriPath);
if (!nonWebInfResourcesPatternMatcher.matches()) {
return null;
} else {
final String rewrittenUriPath = "/" + nonWebInfResourcesPatternMatcher.group(2);
final String rewrittenUrl = request.getContextPath() + rewrittenUriPath;
return new RewriteMatch() {
public String getMatchingUrl() {
return rewrittenUrl;
}
public boolean execute(HttpServletRequest request, HttpServletResponse response) throws ServletException, IOException {
ResourceDownloadUtils.addPublicCachingHeaders(request, response);
request.setAttribute("cachingHeadersApplied", true);
request.setAttribute("_statichash", nonWebInfResourcesPatternMatcher.group(1));
request.getRequestDispatcher(rewrittenUriPath).forward(request, response);
return true;
}
};
}
}
...
其中,url的重组主要发生在:
final String rewrittenUriPath = "/" + nonWebInfResourcesPatternMatcher.group(2);
final String rewrittenUrl = request.getContextPath() + rewrittenUriPath;
经过处理后的url便成为了:/x/..;/WEB-INF/web.xml,随后这个url会传入normalize这些函数进行处理。
而此时,由于是通过静态资源的加载路径,在其ApplicationFilterChain中就不存在JiraLoginFilter,因此也就绕过了登录限制。以下为示意图,poc就不完整放出了:
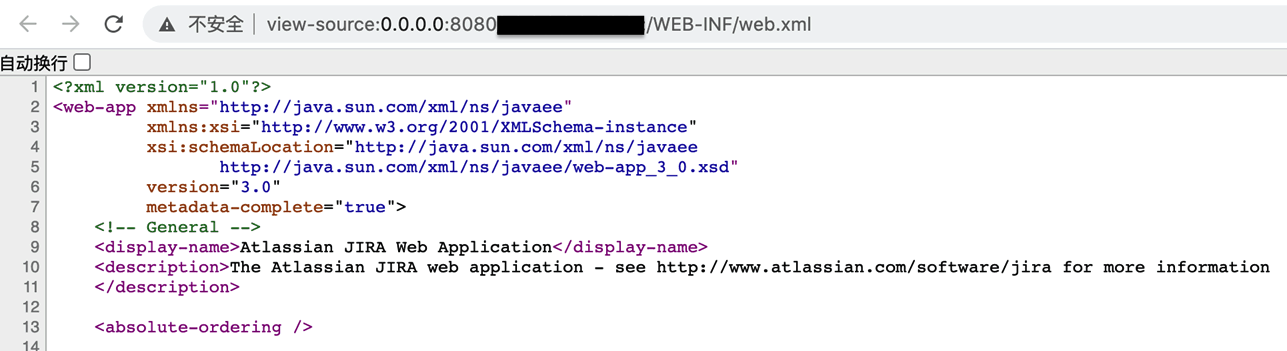
0x05 漏洞局限性
由于normalize对于相对路径的抵消,是直接通过对字符串截取完成,因此对于上级目录-相对路径一一对应的情况是毫无影响的,但是当这两者不完全对应时,比如/x/..;/..;/cc,normalize在第一次抵消后会得到/..;/cc,当再次进行抵消时,由于字符串无法再向前截断,就会报错得到NullPointerException,因此只能在jira的应用目录下读取文件。






