0x00 背景
之前在先知社区写过相关的文章。
文章过于粗糙,一些基础原理和细节问题没有谈明白
所以再写一篇文章做更完善的分析
0x01 数据流分析
静态分析理论中的数据流分析,通过算法得到Basic Block进而建立Control Flow Graph后,根据传递函数迭代生成每个Basic Block的in/out集直到不再变化后得到一个保守的分析结果
不同于标准的数据流分析,笔者这里是一种简单的方式
先带大家从一个简单的SQL注入例子的字节码来分析JVM Stack Frame中Operand Stack和Local Variables的变化
状态分析
给出一个最简单的SQL注入例子
public List<User> selectUser(String name) {
String sql = "select * from t_user where name=\"" + name + "\"";
List<User> users = jdbcTemplate.query(sql, new BeanPropertyRowMapper(User.class));
return users;
}
简单分析上面的代码可以得出结论:name参数存在了字符串拼接操作,并且拼接后的字符串被设置为jdbcTemplate.query方法的第一个参数执行了该方法
如果name参数是可控的用户输入变量,那么就可以成功触发SQL注入漏洞
假设现在我们确认了name是可控输入(如何将在后文中详细解释)应该如何分析呢
首先来看String sql = ...这句话的字节码
NEW java/lang/StringBuilder
DUP
INVOKESPECIAL java/lang/StringBuilder.<init> ()V
LDC "select * from t_user where name=\""
INVOKEVIRTUAL java/lang/StringBuilder.append (Ljava/lang/String;)Ljava/lang/StringBuilder;
ALOAD 1
INVOKEVIRTUAL java/lang/StringBuilder.append (Ljava/lang/String;)Ljava/lang/StringBuilder;
LDC "\""
INVOKEVIRTUAL java/lang/StringBuilder.append (Ljava/lang/String;)Ljava/lang/StringBuilder;
INVOKEVIRTUAL java/lang/StringBuilder.toString ()Ljava/lang/String;
ASTORE 2
注意到代码中没有StringBuilder为什么字节码中有
因为在JVM中字符串相加其实会被转为StringBuilder.append操作
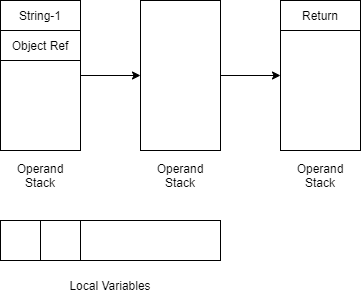
第一行NEW java/lang/StringBuilder实际在JVM中的过程如下,压栈Object Ref对象引用
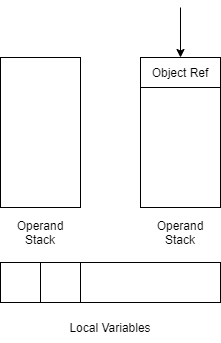
第二句DUP会将Operand Stack栈顶元素复制一份,变成下图这样(为什么要复制见下文)
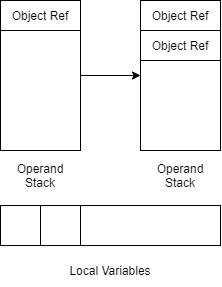
下一句INVOKESPECIAL java/lang/StringBuilder.<init> ()V真正地实例化对象
虽然并没有传参数,但非STATIC方法的调用第0个参数实际上是this对象,也就是这里的Object Ref
在JVM中方法调用的过程如图:从Local Varaibles中取值放入OperandStack作为方法参数,调用方法时弹出。调用方法结束后,如果方法有返回值会讲返回值压入OperandStack
回到刚才的实例化StringBuilder字节码,这里会弹出栈顶的一个Object Ref,由于初始化方法没有返回值,所以并没有压入的返回值。但是此时栈顶存在的另一个Object Ref指向被实例化的对象,所以不再是空指针,当然这里不是我们需要关注的地方
所以这一步调用结束后,状态应该和第一步NEW相同
再看下一句LDC "select * from t_user where name=\""
这句的效果是直接将字符串常量压栈,如下图
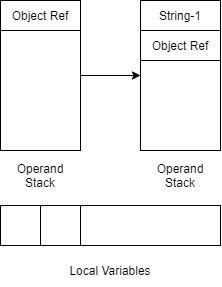
其实这一句LDC的作用是为了下一句的append方法调用
INVOKEVIRTUAL java/lang/StringBuilder.append (Ljava/lang/String;)Ljava/lang/StringBuilder;
注意到方法非STATIC且有一个参数,所以会弹出栈顶两个元素
append方法执行完后会有一个返回值,压栈
上一步压栈的返回值其实还是StringBuilder对象,如果要下一次append那么就需要再找一个字符串
看到下一步是ALOAD 1操作,这条指令的作用是取Local Variables第2个元素压栈
注意到上面一些列图中的Local Variables一直都有两个元素(为了防止干扰所以没有标明是什么)
非STATIC方法的Local Variables的第1个元素一定是this对象,而传入的参数依次往后排
所以ALOAD 1在JVM中执行的过程应该如下
后续三步的过程同上
第一个INVOKEVIRTUAL作用是append了可控变量name,返回值压栈
LDC是SQL语句的结尾,再次append完返回值压栈
INVOKEVIRTUAL java/lang/StringBuilder.append (Ljava/lang/String;)Ljava/lang/StringBuilder;
LDC "\""
INVOKEVIRTUAL java/lang/StringBuilder.append (Ljava/lang/String;)Ljava/lang/StringBuilder;
执行完这两步后状态如下(注意Local Variables中的变量被ALOAD完不变)
结尾的两步其实也简单,注意到toString方法没有参数,返回一个String
所以会弹栈再压栈,下一步的ASTORE 2作用是保存到局部变量表第3位
INVOKEVIRTUAL java/lang/StringBuilder.toString ()Ljava/lang/String;
ASTORE 2
以上过程图示
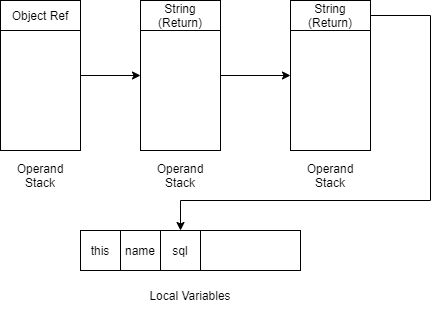
注意以上的过程只是第一句String sql = ...的字节码分析
第二步List<User> users = jdbcTemplate.query(...);的字节码如下
ALOAD 0
GETFIELD org/sec/cidemo/dao/impl/SQLIDaoImpl.jdbcTemplate : Lorg/springframework/jdbc/core/JdbcTemplate;
ALOAD 2
NEW org/springframework/jdbc/core/BeanPropertyRowMapper
DUP
LDC Lorg/sec/cidemo/model/User;.class
INVOKESPECIAL org/springframework/jdbc/core/BeanPropertyRowMapper.<init> (Ljava/lang/Class;)V
INVOKEVIRTUAL org/springframework/jdbc/core/JdbcTemplate.query (Ljava/lang/String;Lorg/springframework/jdbc/core/RowMapper;)Ljava/util/List;
ASTORE 3
首先来看前两步,局部变量表第1位的this压栈,然后GETFIELD
这个指令的作用是取栈顶对象中的某个属性,然后压栈
再取局部变量表第3位的sql压栈
之后NEW BeanPropertyRowMapper不仔细分析了,读者可以自行分析
直到关键方法INVOKEVIRTUAL JdbcTemplate.query之前的过程图示如下
(其中BPW是BeanPropertyRowMapper对象)
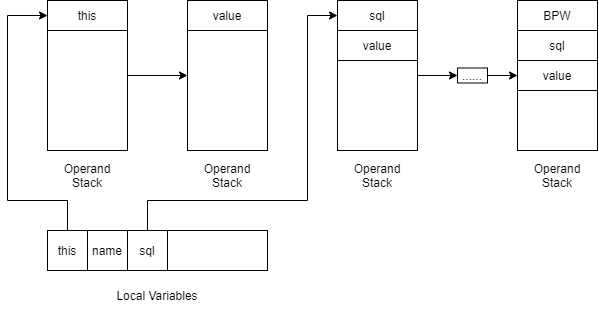
上图最右侧的OperandStack状态正是调用关键方法之前的状态
INVOKEVIRTUAL org/springframework/jdbc/core/JdbcTemplate.query (Ljava/lang/String;Lorg/springframework/jdbc/core/RowMapper;)Ljava/util/List;
该方法需要两个参数,由于非STATIC需要加上方法本身的this参数,也就是总共需要三个参数
入参的顺序是从右到左,依次弹出栈中的三个元素作为参数,然后执行该方法
没有必要做后续的分析了,这一步已经可以确认SQL注入漏洞了
分析思路
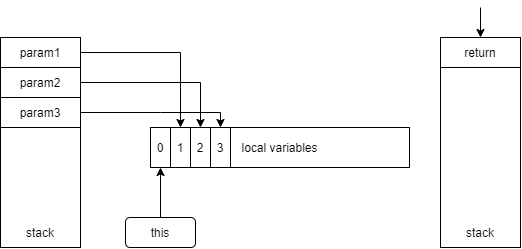
借用上文一张图
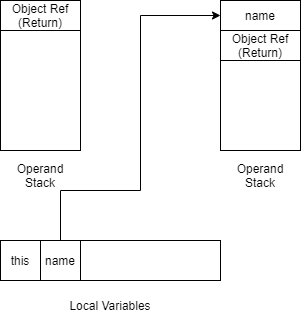
JVM在进入该方法时候,会在局部变量表里面初始化参数,第1位this,方法参数依次往后排
由于我们假设了name参数是可控的参数,可以给它一个颜色表明它存在问题
所以上文拼接字符串的部分可以表示如下
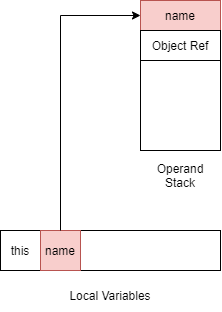
字符串被拼接后保存到局部变量表
后续的jdbcTemplate.query调用又会取出来,作为参数传入
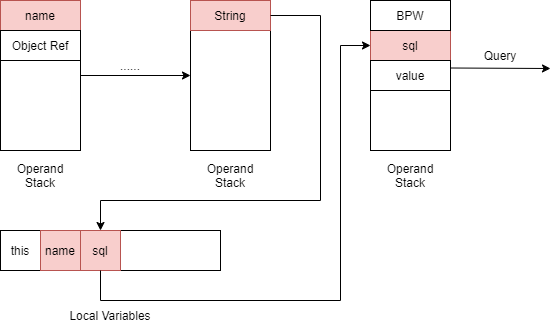
所以如果一开始的name是红色且最后数据库操作的参数中包含了红色,说明存在漏洞
代码实现
那么如何实现呢?
造个Operand Stack和Local Variables
其中的泛型T可以理解为上文的红色
public class OperandStack<T> {
private final LinkedList<Set<T>> stack;
// pop push methods
}
public class LocalVariables<T> {
private final ArrayList<Set<T>> array;
// set get method
}
在进入方法的时候初始化这两个数据结构
public void visitCode() {
super.visitCode();
localVariables.clear();
operandStack.clear();
if ((this.access & Opcodes.ACC_STATIC) == 0) {
localVariables.add(new HashSet<>());
}
for (Type argType : Type.getArgumentTypes(desc)) {
for (int i = 0; i < argType.getSize(); i++) {
localVariables.add(new HashSet<>());
}
}
}
模拟JVM的操作
以下是节选自CoreMethodAdapter的部分代码,其中visitInsn方法是遇到无操作数的指令情况
实际上这个模拟很复杂,需要处理各种指令的情况,比如GOTO等指令需要复制状态,处理起来很麻烦
@Override
public void visitInsn(int opcode) {
switch (opcode) {
case Opcodes.NOP:
break;
case Opcodes.LCONST_0:
case Opcodes.LCONST_1:
case Opcodes.DCONST_0:
case Opcodes.DCONST_1:
operandStack.push();
operandStack.push();
break;
case Opcodes.IALOAD:
case Opcodes.FALOAD:
case Opcodes.AALOAD:
case Opcodes.BALOAD:
case Opcodes.CALOAD:
case Opcodes.SALOAD:
operandStack.pop();
operandStack.pop();
operandStack.push();
break;
case Opcodes.LALOAD:
case Opcodes.DALOAD:
operandStack.pop();
operandStack.pop();
operandStack.push();
operandStack.push();
break;
....
}
}
关于该类完整代码参考:
当我们给两大数据结构中的元素设置内容时,其实就相当于上文的红色
遇到JVM指令后,模拟做出相同的动作,一般情况下这个红色就会传递下去
如果出现类似RETURN的操作,红色不会传递下去,那么我们判断下是否符合指定的条件,然后手动传递下去即可
实际上这一步实现起来不是那么简单,会遇到很多意外的情况
0x02 方法调用图
回到一开始的地方,当时说我们认为name参数是可控参数
为什么能这么认为,如何判断是否真正可控
还是从实际的例子入手,一个最简单的SpringMVC入口,经过Service层到达Dao层完成数据库操作
@RequestMapping("/select")
@ResponseBody
public List<User> select(@RequestParam("name") String name){
return sqliService.selectUser(name);
}
@Override
public List<User> selectUser(String name) {
return sqliDao.selectUser(name);
}
@Override
public List<User> selectUser(String name) {
String sql = "select * from t_user where name=\"" + name + "\"";
List<User> users = jdbcTemplate.query(sql, new BeanPropertyRowMapper(User.class));
return users;
}
可以使用ASM技术分析所有的字节码
这里的所有指的是目标jar包中源代码,依赖库以及JDK中的字节码
然后visit所有的method(可以理解为遍历所有class文件的方法)
分析即可得到当前整个运行环境中,存在的每个方法中有那些方法调用
直接这样说也许显得空白,下面用一个简单的例子解释:每个方法中有那些方法调用是什么意思
public class Demo{
int demo(int a){
int b = A.test1(a);
int c = new A().test2(a);
}
}
那么它存在这样的调用(数字表示参数索引)
Demo.demo(1)->A.test1(0)
Demo.demo(1)->A.test2(1)
由于test1方法是静态方法,而demo和test2方法不是。需要考虑到正常情况下方法参数索引0为this
而caller参数a的索引为1,target参数索引在静态情况下为0,正常情况下为1
这是一处简单的方法,经过测试运行环境实际上会有几万到几百万个方法,需要做的事情是分析所有方法
思路有了,接下来写代码
遍历到的每个方法在进入方法时设置上当前的参数索引(visitCode是ASM定义观察方法过程中的第一步)
@Override
public void visitCode() {
super.visitCode();
int localIndex = 0;
int argIndex = 0;
if ((this.access & Opcodes.ACC_STATIC) == 0) {
localVariables.set(localIndex, "arg" + argIndex);
localIndex += 1;
argIndex += 1;
}
for (Type argType : Type.getArgumentTypes(desc)) {
localVariables.set(localIndex, "arg" + argIndex);
localIndex += argType.getSize();
argIndex += 1;
}
}
在当前方法内遇到方法调用时,会执行visitMethodInsn方法
@Override
public void visitMethodInsn(int opcode, String owner, String name, String desc, boolean itf) {
Type[] argTypes = Type.getArgumentTypes(desc);
// 这里主要目的是判断是否STATIC决定第0位参数是否为this
if (opcode != Opcodes.INVOKESTATIC) {
Type[] extendedArgTypes = new Type[argTypes.length + 1];
System.arraycopy(argTypes, 0, extendedArgTypes, 1, argTypes.length);
extendedArgTypes[0] = Type.getObjectType(owner);
argTypes = extendedArgTypes;
}
switch (opcode) {
case Opcodes.INVOKESTATIC:
case Opcodes.INVOKEVIRTUAL:
case Opcodes.INVOKESPECIAL:
case Opcodes.INVOKEINTERFACE:
int stackIndex = 0;
// 遍历调用方法的所有参数
for (int i = 0; i < argTypes.length; i++) {
// 这个argIndex是目标方法的参数索引
int argIndex = argTypes.length - 1 - i;
Type type = argTypes[argIndex];
// 从Operand Stack中取出当前参数对应的值
Set<String> taint = operandStack.get(stackIndex);
if (taint.size() > 0) {
for (String argSrc : taint) {
// 由于这个值是visitCode时初始化的
// 所以会是arg1这样的格式需要切割
srcArgIndex = Integer.parseInt(argSrc.substring(3));
// 构造当前的CallGraph并保存结果
discoveredCalls.add(new CallGraph(
new MethodReference.Handle(
new ClassReference.Handle(this.owner), this.name, this.desc),
new MethodReference.Handle(
new ClassReference.Handle(owner), name, desc),
srcArgIndex,
argIndex));
}
}
stackIndex += type.getSize();
}
break;
default:
throw new IllegalStateException("unsupported opcode: " + opcode);
}
super.visitMethodInsn(opcode, owner, name, desc, itf);
}
通过以上的代码,可以得到下面的结果
caller:Controller.select(1)
target:Service.selectUser(1)
caller:Service.selectUser(1)
target:Dao.selectUser(1)
这时候如果将第一步的name变成红色,通过模拟JVM两大数据结构之间的交互,让这个红色在方法调用间逐渐传递
从Controller层传递到最后Dao层调用数据库操作的地方,这里就贯通了整个流程
为了方便理解,再画一张图表示
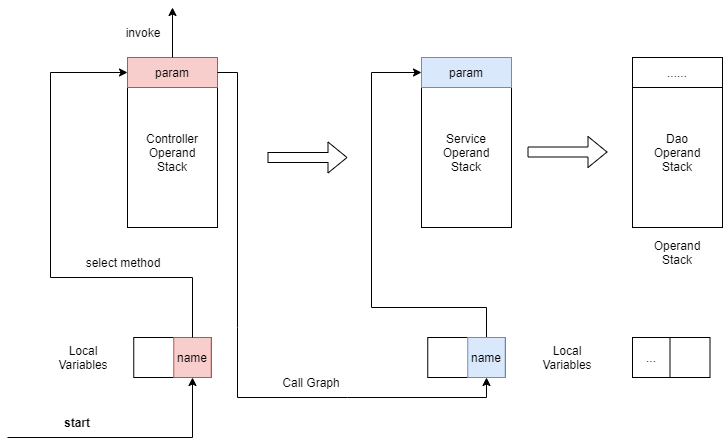
其中start是前端传入的可控参数,在Local Variables中将它染红,select(name)方法调用前压栈,调用后弹出
这时候红色消失了,如何确保传递呢?
通过上文分析得到的CallGraph结果,查到Controller.select(1)->Service.selectUser(1)发现name参数传入了selectUser方法中,也就是上图最左边栈顶的红色
于是手动给Service Local Variables中对应的参数索引位置设置颜色,为了区分选择了蓝色
Service层两大数据结构模拟过程同上,到达Dao层。通过CallGraph查到了这样的结果:Service.selectUser(1)->Dao.selectUser(1)认为第1个参数name可以继续传递
而Dao层的操作相比前两层来看复杂了很多,这里正是本文一开始分析的数据流分析
一开始假设Dao.selectUser(name)的name参数是可控输入,直接染红。假设在这里就可以去掉了
最终到达jdbcTemplate.query(sql,...)处
经过上文数据流分析,发现了拼接sql语句并执行的操作,也就是SQL注入漏洞
0x03 返回值分析
对漏洞而言,仅仅确定漏洞可以触发其实是不足的,更需要想办法做到回显
类似普通的漏洞分析,可以看到上文已经做到了漏洞触发的分析,如果遇到反射XSS这种需要判断回显的怎么办
给出一个简单的反射XSS例子
Controller
@RequestMapping("/reflection")
@ResponseBody
public String reflection(@RequestParam("data") String message) {
return xssService.reflection(message);
}
Service
@Override
public String reflection(String message) {
if (!message.equals("test")) {
return message;
}
return "error";
}
简单地分析可以发现如果message参数不是test那么就会原样输出给前端,造成反射XSS
上文的红色原理可以用在这里
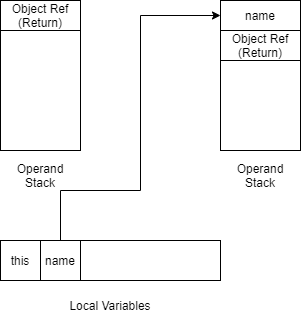
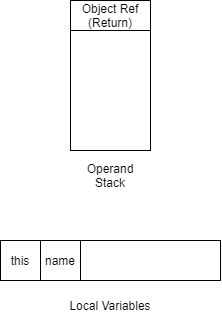
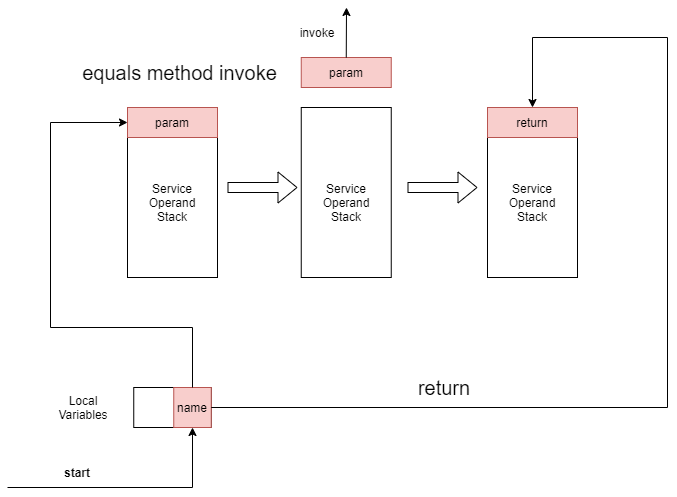
单独分析Service层方法,如果入参染成红色,返回时ALOAD 1会把入参压栈,因此返回值也变成了红色
ALOAD 1
LDC "test"
INVOKEVIRTUAL java/lang/String.equals (Ljava/lang/Object;)Z
...
ALOAD 1
ARETURN
图片表示过程如下:
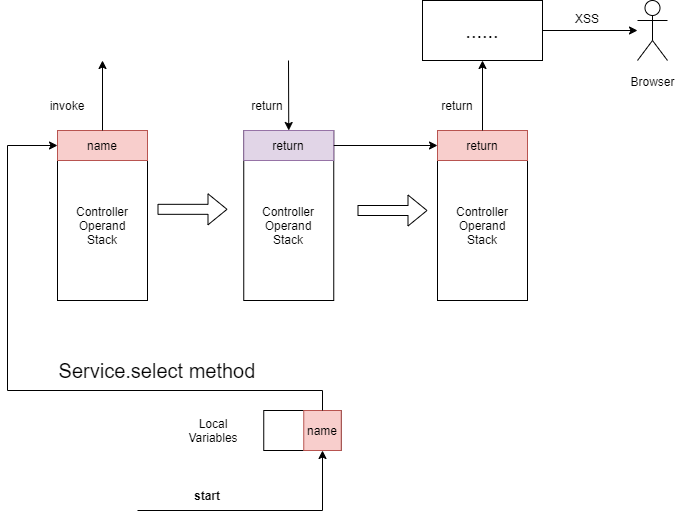
再分析Controller层,由于我们已知Service层的方法返回值有可能和入参一致,所以调用Service.select方法得到返回值可以设为红色,进而可以初步推断出反射XSS
(这里为了简化分析,所以暂不考虑其他的操作,比如字符串是否被实体化编码等)
逆拓扑排序
涉及到另外一个问题,应该从哪个方法优先分析?
答案:显然应该从最底层的调用(调用链最末端)开始分析
假如有如下的调用链:A.B.C.D.E单一的线性调用,可以直接从E开始
如果不是线性的,是复杂的图结构,应该如何处理呢?
参考GadgetInspector中的逆拓扑排序
private static void dfsTsort(Map<MethodReference.Handle, Set<MethodReference.Handle>> outgoingReferences,
List<MethodReference.Handle> sortedMethods, Set<MethodReference.Handle> visitedNodes,Set<MethodReference.Handle> stack, MethodReference.Handle node) {
if (stack.contains(node)) {
return;
}
if (visitedNodes.contains(node)) {
return;
}
// 根据起始方法,取出被调用的方法集
Set<MethodReference.Handle> outgoingRefs = outgoingReferences.get(node);
if (outgoingRefs == null) {
return;
}
// 入栈,以便于递归不造成类似循环引用的死循环整合
stack.add(node);
for (MethodReference.Handle child : outgoingRefs) {
// 递归
dfsTsort(outgoingReferences, sortedMethods, visitedNodes, stack, child);
}
stack.remove(node);
// 记录已被探索过的方法,用于在上层调用遇到重复方法时可以跳过
visitedNodes.add(node);
// 递归完成的探索,会添加进来
sortedMethods.add(node);
}
关于逆拓扑排序,参考Longofo师傅的文章,对图片做了一些优化和精简
这是一个方法调用关系:
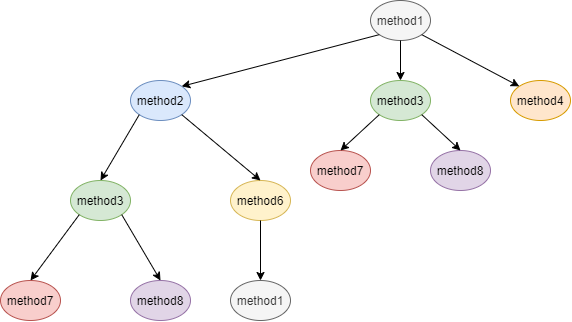
在排序中的stack和visited和sorted过程如下:
只要有子方法,就一个个地入栈
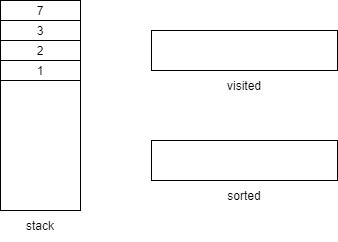
到达method7发现没有子方法,那么弹出并加入visited和sorted
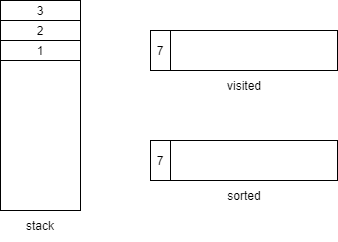
回溯上一层,method3还有一个method8子方法,压栈
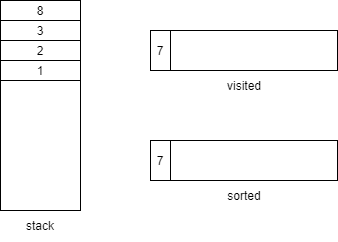
method8没有子方法,回溯上一层method3也没有,都弹出并进入右侧
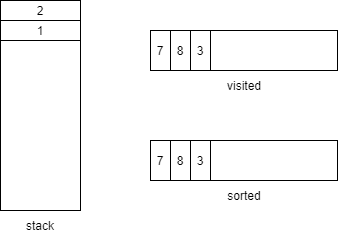
到达method6,有子方法,压栈,找到method6下的method1,压栈,注意这里是Set结构不重复,所以压了等于没压
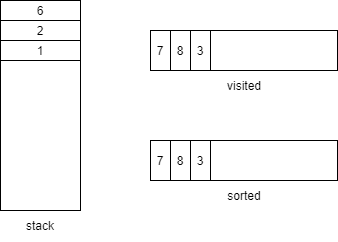
回溯后method6和method2都没有子方法了,弹出并进入右边
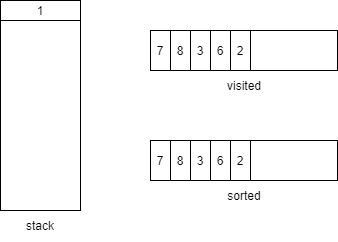
往后执行遇到method1的两个子方法method3和method4,由于method3已在visited,直接return,把method4压栈。然后method4没有子方法弹栈,最后剩下的method1也没有子方法,弹栈
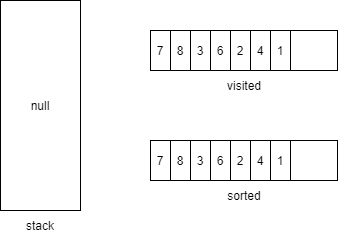
最终得到的排序结果就是7836241,达到了最末端在最开始的效果
当排序完成后,遍历分析这些方法的返回值与入参的关系,即可串通返回值分析这一条路



