0x00 背景
随着学习的深入,接触的设备已经慢慢的从一些简单的路由器向其他的智能设备开始扩散,就会碰到更多看起来比较复杂的固件,就比如RTOS的固件,当用常规的方法----binwalk对它进行解包的时候,并不能直接看见文件系统里面的内容,笔者一开始接触这类系统十分的困惑,在研究完修改的过程之后,记录一下学习的过程。
0x01 RTOS介绍
RTOS的全称为Real-time operating system,翻译过来就是实时操作系统的意思,这里的实时指的是某个程序的响应时间严格限制在某段时间内完成,简单来说,就是设置了一个坎,在时间结束之前必须跨过这个坎,建立这么一个基本的概念就算到位了,其实在现代的操作系统当中,除了某种特点的情况才需要用到RTOS,因为在硬件能力慢慢提升的情况下,这种差距就显得没有那么大,除非在AI,自动化,航空等领域,否则其他的情况,人们很难去感受到它们的差距在哪,更多详细的内容参考下面的链接:
总的来说,没有说实时操作系统和非实时操作系统的速度,吞吐量和规模一定谁比谁快,谁比谁精巧,只是在某种应用场景下,那种系统更加的符合应用场景就使用那种系统罢了
0x02 开始修复固件
此处用的是TP-LINK TL-WDR7660来练手,毕竟网上还是有点资料,出现问题也能参考参考,链接:
固件分析
先通过binwalk识别一下,识别到是uImage和一堆LZMA压缩过的数据,前者是U-boot,后者可能里面存在文件系统,其中比较大的很有可能就是文件系统,就比如0x10400这个,还有这是arm架构的
➜ binwalk wdr7660gv1-cn-up_2019-08-30_10.37.02.bin
DECIMAL HEXADECIMAL DESCRIPTION
--------------------------------------------------------------------------------
512 0x200 uImage header, header size: 64 bytes, header CRC: 0xDEFB3DA, created: 2018-09-05 07:32:57, image size: 48928 bytes, Data Address: 0x41C00000, Entry Point: 0x41C00000, data CRC: 0x2A36A3AD, OS: Firmware, CPU: ARM, image type: Standalone Program, compression type: lzma, image name: "U-Boot 2014.04-rc1-gdbb6e75-dirt]"
576 0x240 LZMA compressed data, properties: 0x5D, dictionary size: 67108864 bytes, uncompressed size: -1 bytes
66560 0x10400 LZMA compressed data, properties: 0x6E, dictionary size: 8388608 bytes, uncompressed size: 3869672 bytes
1422400 0x15B440 LZMA compressed data, properties: 0x5A, dictionary size: 8388608 bytes, uncompressed size: 7170 bytes
1423926 0x15BA36 LZMA compressed data, properties: 0x5A, dictionary size: 8388608 bytes, uncompressed size: 200 bytes
...
提取文件系统
用dd命令提取,下面是它的命令解析:
bs=字节数 一次读写的比特数(默认:512);
count=块数 只将复制指定数量的输入块
ibs=字节数 一次读取的字节数(默认:512)
if=文件 从指定文件而非标准输入来进行读取
obs=字节数 一次写入指定字节数(默认:512)
of=文件 写入到指定文件而非标准输出
skip=块数 在输入开始处跳过指定的 ibs 大小的块数
这里提一下count的计算:1422400-66560=1355840
➜ dd if=wdr7660gv1-cn-up_2019-08-30_10.37.02.bin of=ac7660.lzma bs=1 skip=66560 count=1355840
记录了1355840+0 的读入
记录了1355840+0 的写出
1355840字节(1.4 MB,1.3 MiB)已复制,3.98426 s,340 kB/s
但是解压有点问题
➜ firware lzma -d ac76601.lzma
lzma: ac76601.lzma: 压缩数据已损坏
用010打开之后,发现后面有一段空数据,怀疑是空数据影响到了,重新计算长度,0x15a477-0x10400=0x14a077(1351799),重新提取
➜ dd if=wdr7660gv1-cn-up_2019-08-30_10.37.02.bin of=ac7660.lzma bs=1 skip=66560 count=1351799
记录了1351799+0 的读入
记录了1351799+0 的写出
1351799字节(1.4 MB,1.3 MiB)已复制,7.3005 s,185 kB/s
➜ lzma -d ac7660.lzma
再次binwalk获得信息,得知这是小端,所以确定这是ARM little的架构,或者直接采用binwalk -A来进行识别CPU的架构
➜ binwalk ac7660 | grep "endian"
3728344 0x38E3D8 SHA256 hash constants, little endian
3784928 0x39C0E0 SHA256 hash constants, little endian
3847576 0x3AB598 CRC32 polynomial table, little endian
➜ binwalk -A ac7660
DECIMAL HEXADECIMAL DESCRIPTION
--------------------------------------------------------------------------------
84 0x54 ARM instructions, function prologue
...
打开IDA进行分析,设置Processor type为ARM Little-endian
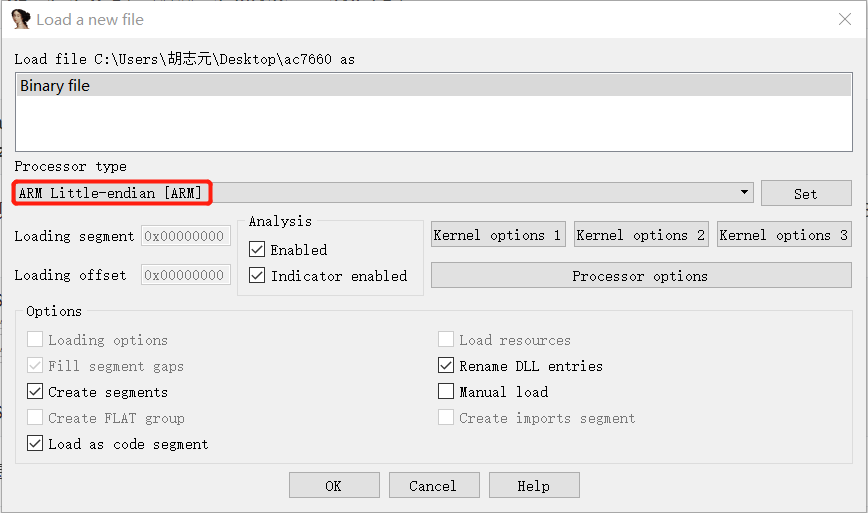
之后就来到关键的第一步:定位程序入口点
如何定位程序入口点
由于此文件是外部链接符号,导致只能用下面这种方法来确认程序的入口点,如果确定文件是内部链接符号,可以参考下面的链接进行定位:
上图确认之后,IDA会弹窗要选择入口地址,在不知道之前先填入0:
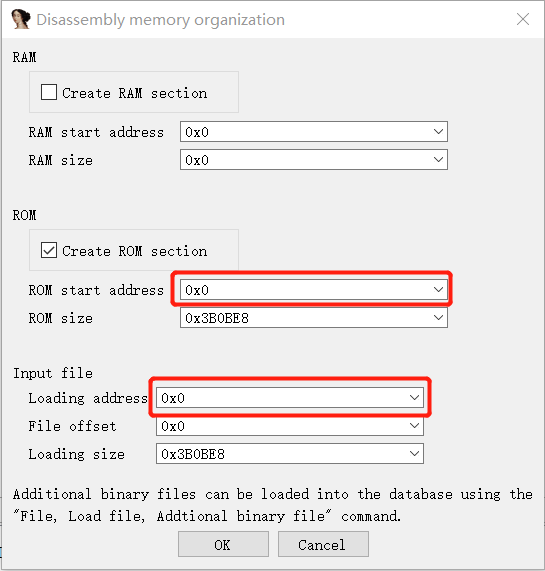
进来看到IDA开头,也就是ROM中地址0的位置,在此处全部转换成代码(按键c)
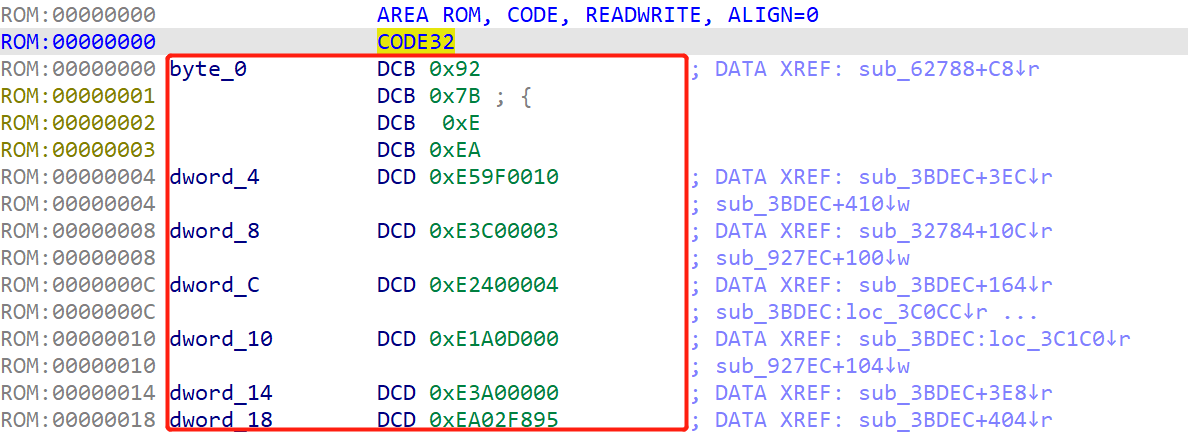
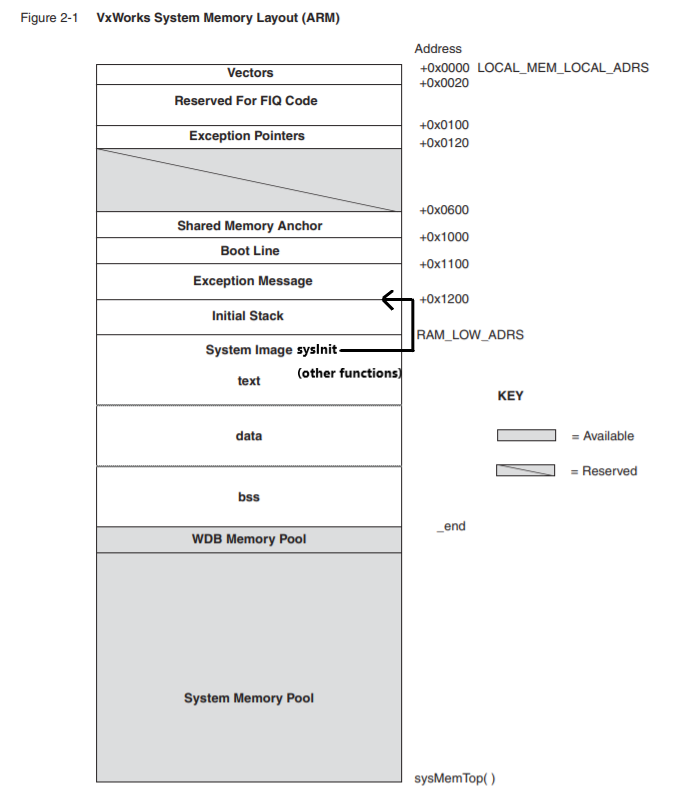
完成之后的结果如下,可以看到用红色框框住的数值就是VxWorks的程序入口点,为什么这么说呢?来看一下VxWorks的启动流程就明白了!
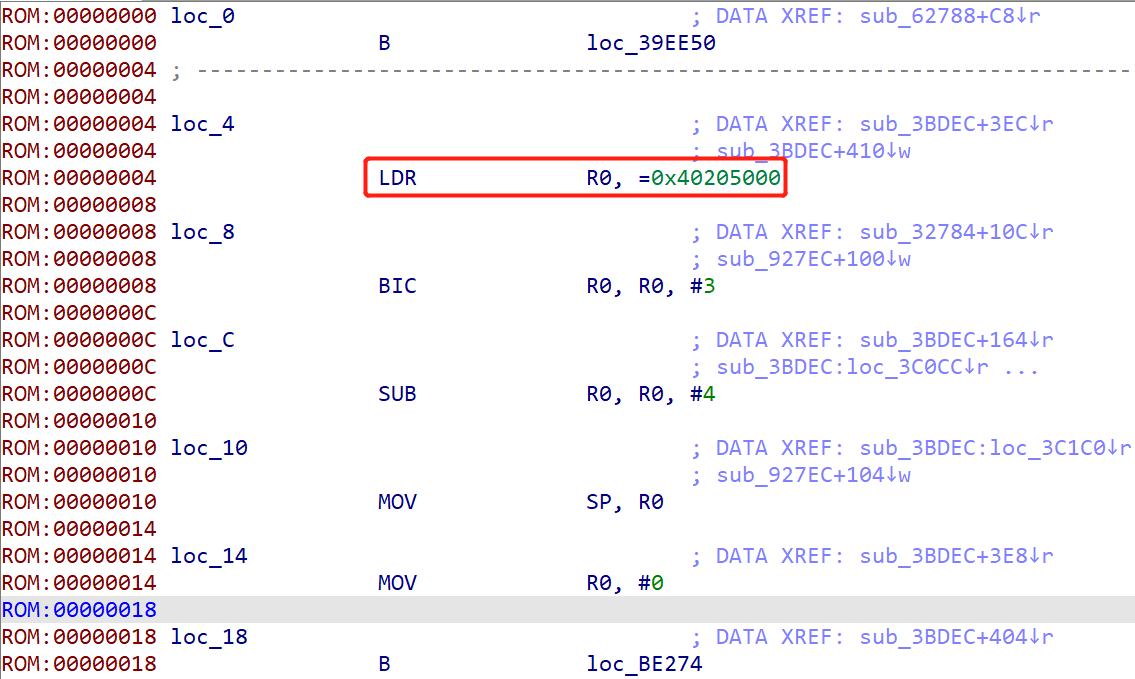
通过查阅资料得知,sysInit() 是VxWorks系统执行的第一段代码,它的主要工作是:关中断、设置usrInit()的栈、调用usrInit(),可以看到这个函数有几个关键的点:设置栈以及调用,所以必然会有两个很明显的操作,对栈进行操作,以及一次跳转(不保存返回地址的),根据这个特征,可以看到此处确实存在这么一个现象,同时在VxWorks当中,程序一开始的入口地址和栈指针是指向同一个地方的,为什么等下再说,所以压栈的那个数值就是一直在找的程序入口地址,为下图的R0中的值:

回过头看看这个问题:为什么程序一开始的入口地址和栈指针是指向同一个地方?
根据官方的文档(16页),initial stack是给usrInit()以及usrRoot()分配的栈空间,所以sysInit()中对栈的操作是给usrInit()做准备的,而usrInit()是程序的入口函数:

所以初始化栈的地址同时也是固件的内存加载地址:
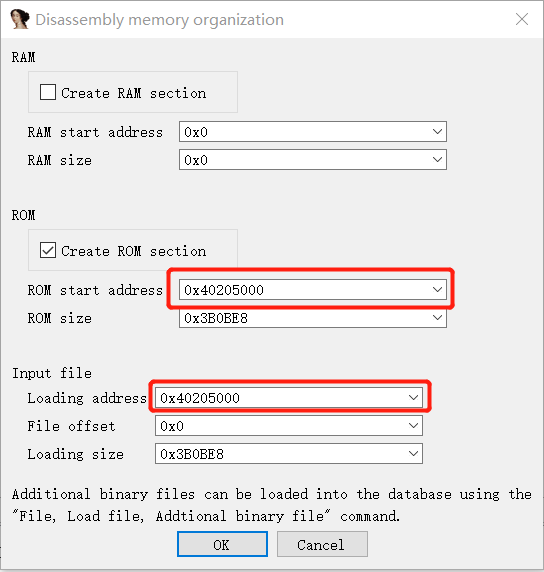
得到入口地址之后就可以重新打开IDA,在选择入口地址处填入刚刚得到的入口地址即可:
0x03 修复程序函数名
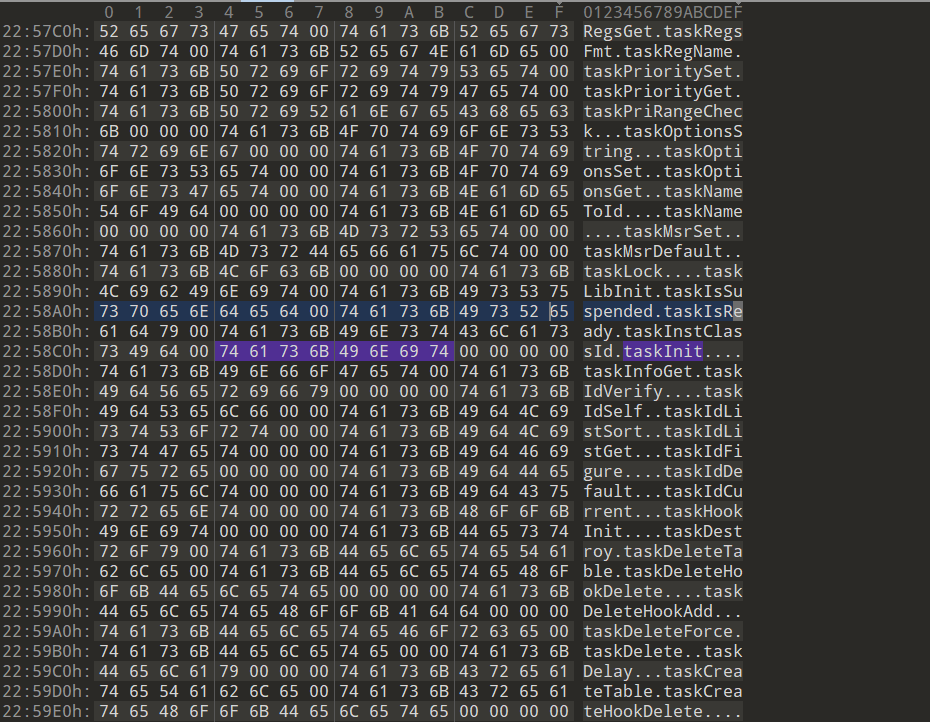
修复之前得找到符号表,有两种符号表的形式,一种是直接包括在整个文件当中,笔者称为内部符号表,还有一种是外部符号表,它可能散落在解包之后的某个文件当中,可以通过某个VxWorks特定的函数来定位符号表的位置,就比如在VxWorks中处理任务调度库函数的taskInit:
下面分别是内部符号表和外部符号表的示例,内部符号表是NOE77101工控设备的固件中binwalk解压出来名为385的文件,外部还是本文最开始采用的固件
内部符号表
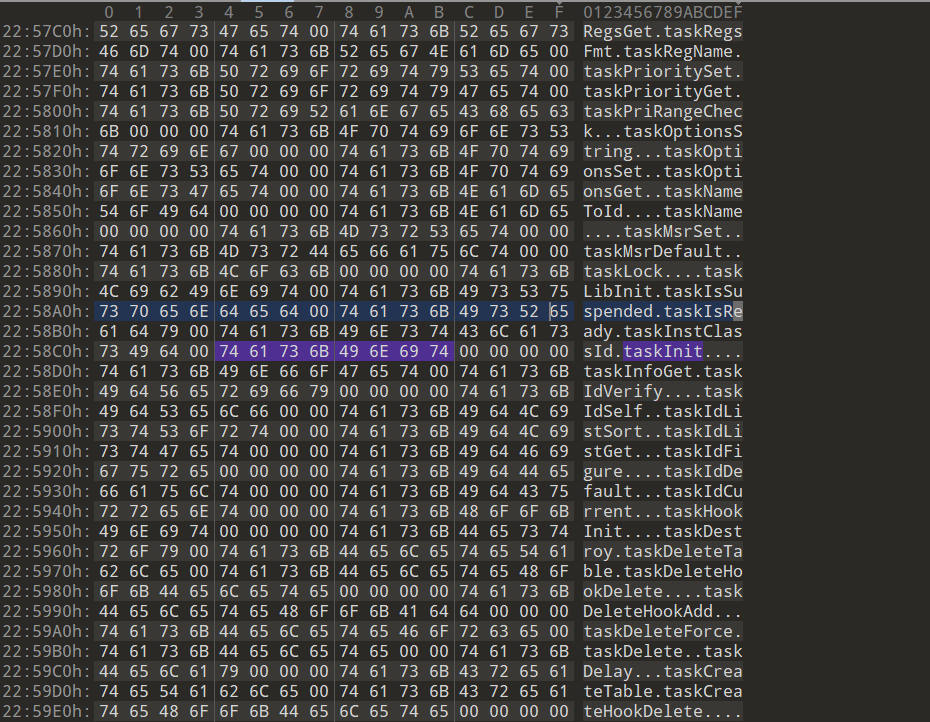
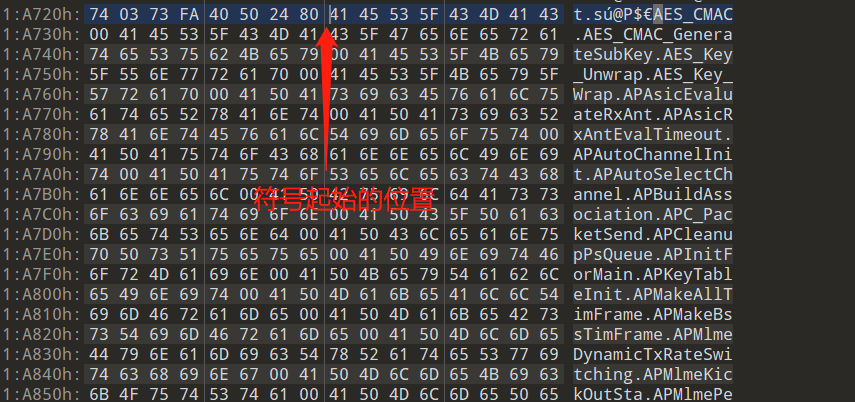
外部符号表
当在分析的文件当中找不到符号表的时候,就可以考虑是不是在另一个文件当中,通过grep来寻找符号表文件:
➜ grep -r "taskInit"
匹配到二进制文件 _wdr7660gv1-cn-up_2019-08-30_10.37.02.bin.extracted/15CBBA
匹配到二进制文件 _NOE77101.bin.extracted/385
修复程序的函数名,没有固定的脚本,可能每个架构的结构不同会导致脚本有些变化,具体还是看符号表的结构来修复,回到一开始的固件进行分析,先看看开头8个比特,0x00051B29为文件的大小,0x000034E4为符号表中符号的数量,剩下的符号表都是以8个比特来进行排列的
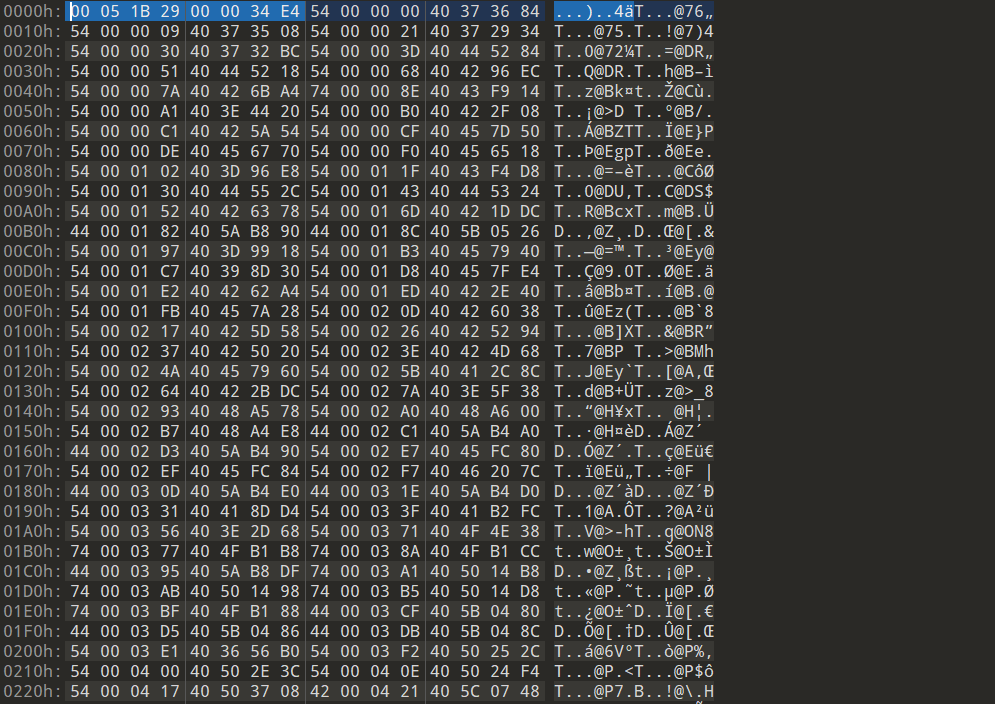
可以验证一下,0x00051B29为文件的大小:
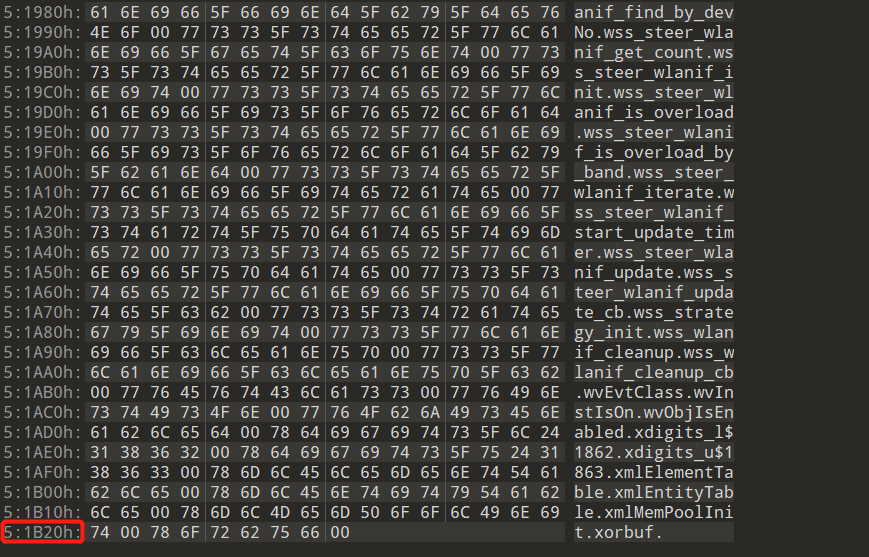
计算的方法:8(开头的8个bit)+ 8(每个符号的大小)* 13540(0x34E4)= 108328(0x1a728)
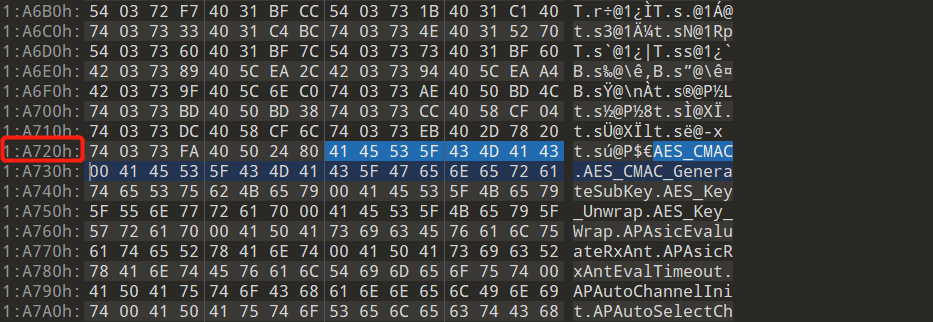
再回过头来看看符号的每个bit的作用:

符号类型
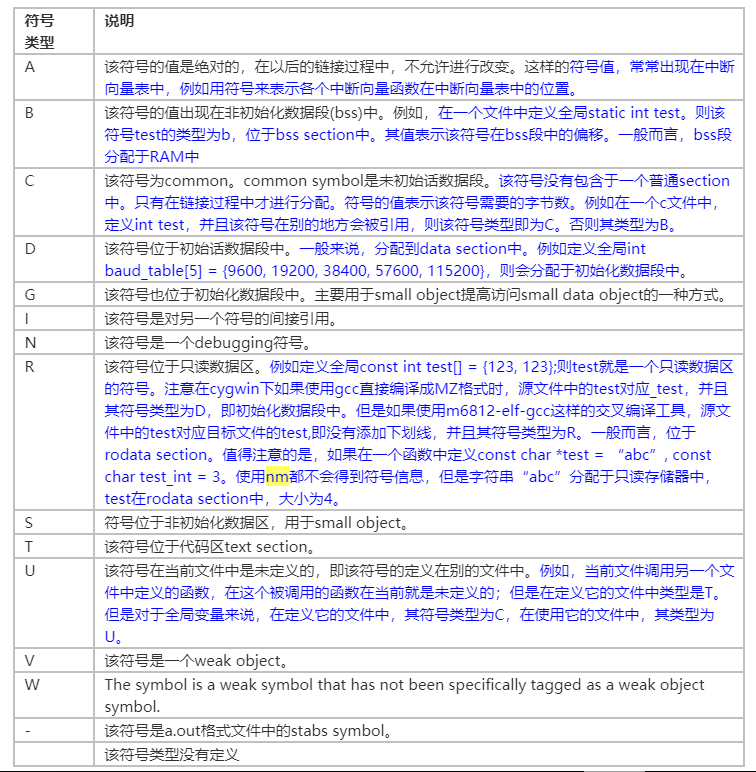
具体可以看看下面的链接:
符号的偏移
符号开始的偏移为0,它将根据下一个符号的其实位置来寻找此符号到那里结束:
知道了这些信息其实就可以写脚本了,大致的功能为将字符串从符号偏移中取出来,然后根据符号在内存中的位置来修改段的名字以及转换成伪代码,最后创建函数,脚本如下(在python2+IDA7.0版本下运行,python3+IDA7.5一直有点问题):
import idautils
import idc
import idaapi
symfile_path = ''
symbols_table_start = 8
strings_table_start = 0x1a728
with open(symfile_path, 'rb') as f:
symfile_contents = f.read()
symbols_table = symfile_contents[symbols_table_start:strings_table_start]
strings_table = symfile_contents[strings_table_start:]
def get_string_by_offset(offset):
index = 0
while True:
if strings_table[offset+index] != '\x00':
index += 1
else:
break
return strings_table[offset:offset+index]
def get_symbols_metadata():
symbols = []
for offset in xrange(0, len(symbols_table),8):
symbol_item = symbols_table[offset:offset+8]
flag = symbol_item[0]
string_offset = int(symbol_item[1:4].encode('hex'), 16)
string_name = get_string_by_offset(string_offset)
target_address = int(symbol_item[-4:].encode('hex'), 16)
symbols.append((flag, string_name, target_address))
return symbols
def add_symbols(symbols_meta_data):
for flag, string_name, target_address in symbols_meta_data:
idc.MakeName(target_address, string_name)
if flag == '\x54':
idc.MakeCode(target_address)
idc.MakeFunction(target_address)
if __name__ == "__main__":
symbols_metadata = get_symbols_metadata()
add_symbols(symbols_metadata)
最后修复的结果,之后就能进行漏洞的挖掘了:
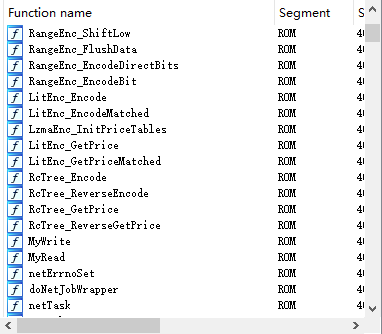
0x04 总结
修复VxWorks的流程大致如下,还有一些小的问题需要注意一下:

- 要在确定好架构的大小端再进行分析,否则反汇编出来的指令看不出程序的入口点
- 可能每个架构的符号表的格式不太一样,并不是每个都能直接跑脚本就能出来的,还是得知其然知其所以然


