跟着afl-training学习afl
0x00 安装
个人习惯问题,不大喜欢用docker,所以自己在ubuntu18里面搭建环境。
安装依赖环境:
sudo apt-get install git build-essential curl libssl-dev sudo libtool libtool-bin libglib2.0-dev bison flex automake python3 python3-dev python3-setuptools libpixman-1-dev gcc-9-plugin-dev cgroup-tools \
clang-11 clang-tools-11 libc++1-11 libc++-11-dev libc++abi1-11 libc++abi-11-dev libclang1-11 libclang-11-dev libclang-common-11-dev libclang-cpp11 libclang-cpp11-dev liblld-11 liblld-11-dev liblldb-11 liblldb-11-dev libllvm11 libomp-11-dev libomp5-11 lld-11 lldb-11 python3-lldb-11 llvm-11 llvm-11-dev llvm-11-runtime llvm-11-tools libstdc++-10-dev
可能会报错:
Reading package lists... Done
Building dependency tree
Reading state information... Done
E: Unable to locate package gcc-9-plugin-dev
E: Unable to locate package clang-11
E: Unable to locate package clang-tools-11
E: Unable to locate package libc++1-11
E: Couldn't find any package by regex 'libc++1-11'
E: Unable to locate package libc++-11-dev
E: Couldn't find any package by regex 'libc++-11-dev'
E: Unable to locate package libc++abi1-11
E: Couldn't find any package by regex 'libc++abi1-11'
E: Unable to locate package libc++abi-11-dev
E: Couldn't find any package by regex 'libc++abi-11-dev'
E: Unable to locate package libclang1-11
E: Unable to locate package libclang-11-dev
E: Unable to locate package libclang-common-11-dev
E: Unable to locate package libclang-cpp11
E: Unable to locate package libclang-cpp11-dev
E: Unable to locate package liblld-11
E: Unable to locate package liblld-11-dev
E: Unable to locate package liblldb-11
E: Unable to locate package liblldb-11-dev
E: Unable to locate package libllvm11
E: Unable to locate package libomp-11-dev
E: Unable to locate package libomp5-11
E: Unable to locate package lld-11
E: Unable to locate package lldb-11
E: Unable to locate package python3-lldb-11
E: Unable to locate package llvm-11
E: Unable to locate package llvm-11-dev
E: Unable to locate package llvm-11-runtime
E: Unable to locate package llvm-11-tools
Unable to locate package gcc-9-plugin-dev是因为没有最新的gcc源,下面是因为没有llvm11相关的源。
E: Unable to locate package gcc-9-plugin-dev的解决方案:
sudo add-apt-repository ppa:ubuntu-toolchain-r/test
sudo apt-get update
根据llvm官网的说明来安装llvm的依赖:
bash -c "$(wget -O - https://apt.llvm.org/llvm.sh)"
然后切换clang等编译器:
sudo update-alternatives --install /usr/bin/clang clang `which clang-11` 1
sudo update-alternatives --install /usr/bin/clang++ clang++ `which clang++-11` 1
sudo update-alternatives --install /usr/bin/llvm-config llvm-config `which llvm-config-11` 1
sudo update-alternatives --install /usr/bin/llvm-symbolizer llvm-symbolizer `which llvm-symbolizer-11` 1
依赖环境都好了,下载afl++并编译:
$ git clone https://github.com/AFLplusplus/AFLplusplus
$ cd AFLplusplus
$ git checkout 2.68c # if you want a specific version, otherwise skip this step
$ make distrib
$ sudo make install
$ sudo /path/AFLplusplus/afl-system-config
0x01 quickstart
quickstart通过fuzz一个简单的demo来体验afl的使用过程。
编译demo的方法是:
cd quickstart
CC=afl-clang-fast AFL_HARDEN=1 make
可以看到将编译器替换成了afl-clang-fast并加入了AFL_HARDEN=1的环境变量,最终make。
查看该目录下的makefile:
# Enable debugging and suppress pesky warnings
CFLAGS ?= -g -w
all: vulnerable
clean:
rm -f vulnerable
vulnerable: vulnerable.c
${CC} ${CFLAGS} vulnerable.c -o vulnerable
make默认会编译all,all编译的是vulnerable,所以最终会形成afl-clang-fast -g -w vulnerable.c -o vulnerable。
vulnerable.c代码如下所示:
$ cat vulnerable.c
#include <string.h>
#include <stdio.h>
#include <unistd.h>
#include <stdlib.h>
#define INPUTSIZE 100
int process(char *input)
{
char *out;
char *rest;
int len;
if (strncmp(input, "u ", 2) == 0)
{ // upper case command
char *rest;
len = strtol(input + 2, &rest, 10); // how many characters of the string to upper-case
rest += 1; // skip the first char (should be a space)
out = malloc(len + strlen(input)); // could be shorter, but play it safe
if (len > (int)strlen(input))
{
printf("Specified length %d was larger than the input!\n", len);
return 1;
}
else if (out == NULL)
{
printf("Failed to allocate memory\n");
return 1;
}
for (int i = 0; i != len; i++)
{
out[i] = rest[i] - 32; // only handles ASCII
}
out[len] = 0;
strcat(out, rest + len); // append the remaining text
printf("%s", out);
free(out);
}
else if (strncmp(input, "head ", 5) == 0)
{ // head command
if (strlen(input) > 6)
{
len = strtol(input + 4, &rest, 10);
rest += 1; // skip the first char (should be a space)
rest[len] = '\0'; // truncate string at specified offset
printf("%s\n", rest);
}
else
{
fprintf(stderr, "head input was too small\n");
}
}
else if (strcmp(input, "surprise!\n") == 0)
{
// easter egg!
*(char *)1 = 2;
}
else
{
return 1;
}
return 0;
}
int main(int argc, char *argv[])
{
char *usage = "Usage: %s\n"
"Text utility - accepts commands and data on stdin and prints results to stdout.\n"
"\tInput | Output\n"
"\t------------------+-----------------------\n"
"\tu <N> <string> | Uppercased version of the first <N> bytes of <string>.\n"
"\thead <N> <string> | The first <N> bytes of <string>.\n";
char input[INPUTSIZE] = {0};
// Slurp input
if (read(STDIN_FILENO, input, INPUTSIZE) < 0)
{
fprintf(stderr, "Couldn't read stdin.\n");
}
int ret = process(input);
if (ret)
{
fprintf(stderr, usage, argv[0]);
};
return ret;
}
看起来程序获取来输入后调用process函数进行处理,根据输入的不同进行不同的处理:
u <N> <string>:对字符串的前n个字节变成大写字符串;head <N> <string>:截取字符串的前n个字符;surprise!:隐藏功能,直接触发崩溃。
运行afl-fuzz对程序进行测试:
afl-fuzz -i inputs -o out ./vulnerable
inputs目录是输入的种子目录,由用户提供,应该是精心准备的样本以有效提高fuzz效率,可以看到系统提供的inputs目录中包含触发u和head的样例:
$ ls inputs
head u
$ cat inputs/u
u 4 capsme
$ cat inputs/head
head 20 This string is going to be truncated at the 20th position.
很快就fuzz出了结果:
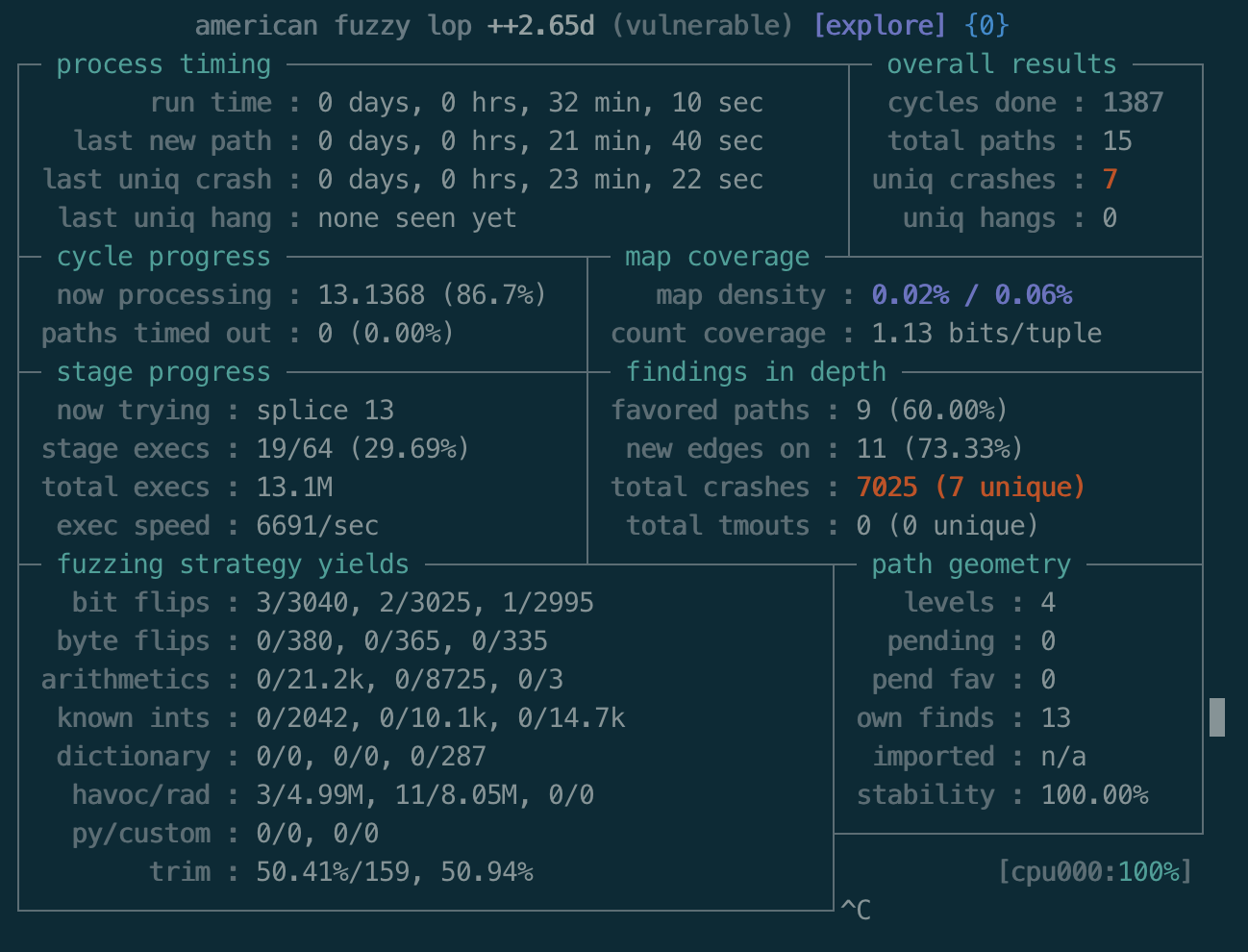
out有相应的产出,其中crashes目录存储的是崩溃样本;queue目录存储的是成果触发新路径的样本即有趣的样本。
$ ls out
cmdline crashes fuzz_bitmap fuzzer_stats hangs plot_data queue
$ ls out/crashes
id:000000,sig:11,src:000006,time:1554,op:havoc,rep:2
id:000001,sig:11,src:000003+000006,time:5379,op:splice,rep:16
id:000002,sig:06,src:000010+000012,time:34485,op:splice,rep:32
id:000003,sig:06,src:000006+000010,time:47997,op:splice,rep:16
id:000004,sig:06,src:000007+000010,time:186126,op:splice,rep:32
id:000005,sig:06,src:000013,time:215280,op:havoc,rep:64
id:000006,sig:06,src:000008+000012,time:528074,op:splice,rep:16
README.txt
$ ls out/queue
id:000000,time:0,orig:head
id:000001,time:0,orig:u
id:000002,src:000000,time:3,op:flip1,pos:0,+cov
id:000003,src:000000,time:25,op:flip2,pos:6,+cov
id:000004,src:000001,time:293,op:flip1,pos:2,+cov
id:000005,src:000001,time:295,op:flip1,pos:2,+cov
id:000006,src:000001,time:301,op:flip2,pos:2,+cov
id:000007,src:000001,time:306,op:flip4,pos:2
最后示例也生成了一个比较低效的样本my seed作为种子文件,再次进行fuzz,二者比对后可以发现前者效率会高很多,所以种子的有效性还是比较关键的。
$ mkdir in
$ echo "my seed" > in/a
$ afl-fuzz -i in -o out ./vulnerable
通过这个小的demo来体验afl fuzz的过程,对afl有了初步的了解。
0x02 harness
harness的作用是通过demo来体验如何针对具体的库代码来编写测试框架。
有了quickstart的经验,先来总结下afl-fuzz的主要组成及工作流程,如下图所示:
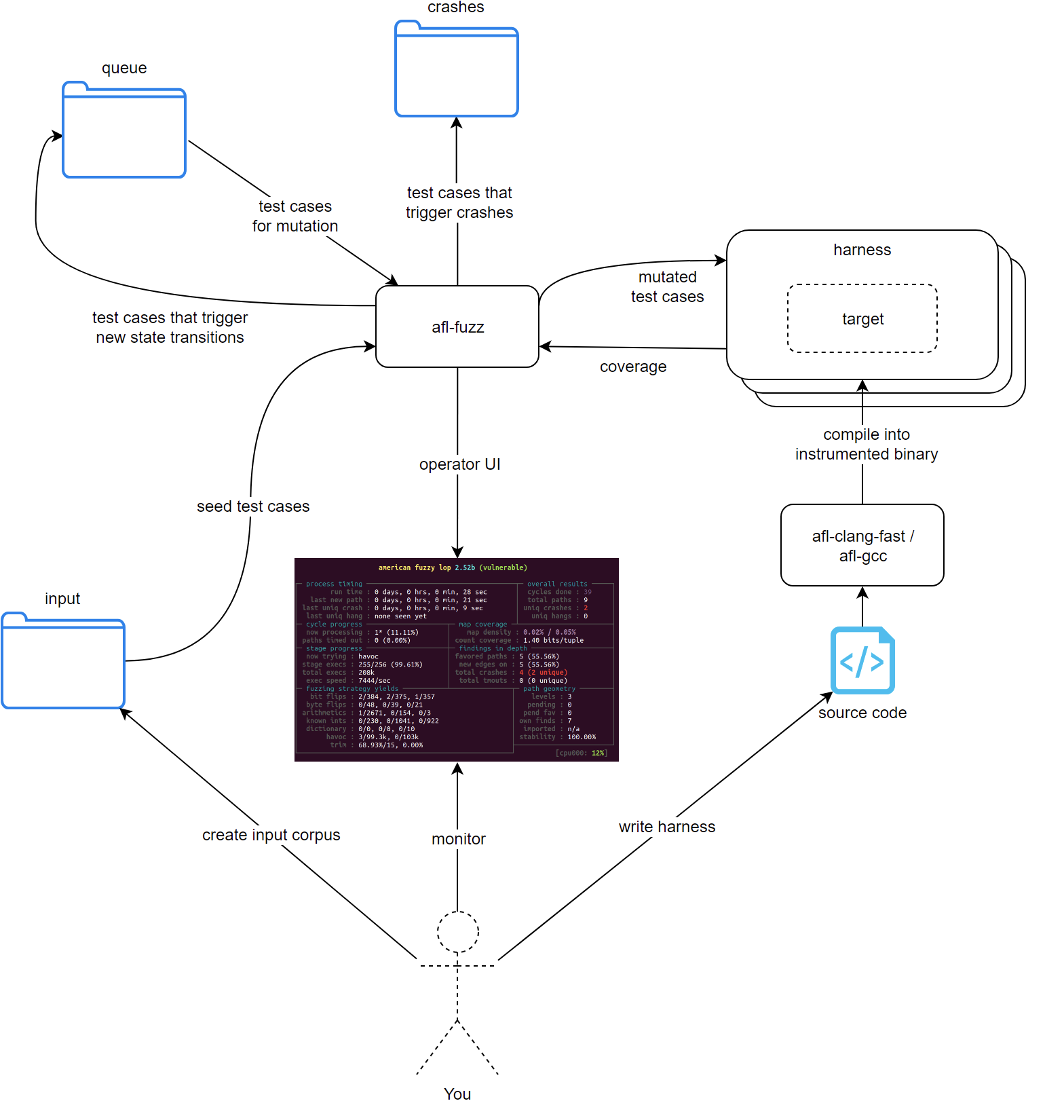
研究测试人员创建输入目录并提供变异的语料库(input corpus);针对测试代码编写测试框架(write harness),经过afl-clang-fast/afl-gcc插桩编译后产生支持反馈模糊测试的二进制程序;afl-fuzz从队列(queue)中挑选种子进行变异;变异后的样本扔给测试框架(harness)运行并监控运行结果;如果崩溃,则存储到崩溃目录中(crashes);如果样本成功触发了新路径,则将它添加到队列(queue)当中。
此次的实验则是通过编写针对library库的测试代码来理解如何编写harness。
library库中存在两个库函数,相应的定义在library.h中,如下所示;具体的实现在library.c中。我们的目标是编写出一个程序框架使得可以通过afl来对这两个库函数进行fuzz。
#include <unistd.h>
// an 'nprintf' implementation - print the first len bytes of data
void lib_echo(char *data, ssize_t len);
// optimised multiply - returns x*y
int lib_mul(int x, int y);
两个函数的功能是:
lib_echo:输出参数data中的前len个字符串;lib_mul:输出参数x乘以y的值。
我们的目标是对编写一个框架实现对这两个函数的模糊测试。
为了实现目的,该框架必须有以下功能:
- 编译出来的程序必须是可执行的,即需要一个
main函数,从而被编译成可执行的二进制程序; - 具备反馈信息的能力以使
afl更高效的fuzz,即编写出来的代码需要使用afl-clang-fast或afl-clang或afl-gcc进行插桩编译; - 提供数据接口以供
afl进行变异;即两个函数使用的参数数据应来自于标准输入或文件,使得afl可以很方便的变异。
最终编写出来的代码如下所示:
#include <unistd.h>
#include <string.h>
#include <stdio.h>
#include "library.h"
// fixed size buffer based on assumptions about the maximum size that is likely necessary to exercise all aspects of the target function
#define SIZE 100
int main(int argc, char* argv[]) {
if((argc == 2) && strcmp(argv[1], "echo") == 0) {
// make sure buffer is initialized to eliminate variable behaviour that isn't dependent on the input.
char input[SIZE] = {0};
ssize_t length;
length = read(STDIN_FILENO, input, SIZE);
lib_echo(input, length);
} else if ((argc == 2) && strcmp(argv[1], "mul") == 0) {
int a,b = 0;
read(STDIN_FILENO, &a, 4);
read(STDIN_FILENO, &b, 4);
printf("%d\n", lib_mul(a,b));
} else {
printf("Usage: %s mul|echo\n", argv[0]);
}
}
可以看到main函数中由命令行参数决定是对lib_echo函数进行模糊测试还是对lib_mul进行模糊测试(满足第一个要求);接着是由标准输入读取数据作为参数来对函数进行调用(满足第二个要求);最后使用afl-clang-fast对程序进行编译实现框架的生成(满足第二个要求)。
编译的命令是:
AFL_HARDEN=1 afl-clang-fast harness.c library.c -o harness
接下来对lib_echo库函数进行模糊测试:
mkdir echo_in
echo aaaaaa > echo_in/seed
afl-fuzz -i echo_in -o out ./harness echo
创建echo_in文件夹用于存储种子文件,创建内容为aaaaaa的seed文件作为种子文件,启动afl-fuzz对lib_echo进行模糊测试。
不一会就可以fuzz出crash,内容是:
$ cat out/default/crashes/id:000000,sig:06,src:000004,time:63255,op:havoc,rep:4
pop!)!!!!%![1m
对lib_mul函数进行模糊测试:
mkdir mul_in
echo "1 3 " > mul_in/seed
afl-fuzz -i mul_in -o out ./harness mul
创建echo_mul文件夹用于存储种子文件,创建内容为1 3的seed文件作为种子文件,启动afl-fuzz对lib_mul进行模糊测试。
当然也可以考虑不是在命令行中指定mul或echo参数来对特定的功能进行fuzz,可以同时对这两部分功能都进行测试。
通过这个demo可以理解在对特定的目标进行模糊测试时,如何基于afl编写优化框架来对代码进行模糊测试。
0x03 challenges
challenges是一系列的带有漏洞的真实目标,通过使用afl来对这些目标进行模糊测试,成功挖掘出相应的漏洞以进一步掌握afl的使用以及原理。
libxml2
根据RUNOOB XML 教程,知道xml是指指可扩展标记语言(eXtensible Markup Language,它被设计用来传输和存储数据。
XML 文档形成了一种树结构,它从"根部"开始,然后扩展到"枝叶"。XML 文档必须包含根元素。该元素是所有其他元素的父元素。
XML 文档中的元素形成了一棵文档树。这棵树从根部开始,并扩展到树的最底端。
所有的元素都可以有子元素:
<root>
<child>
<subchild>.....</subchild>
</child>
</root>
父、子以及同胞等术语用于描述元素之间的关系。父元素拥有子元素。相同层级上的子元素成为同胞(兄弟或姐妹)。
libxml2的库是解析XML文档的函数库。它用 C 语言写成,并且能被多种语言所调用。我们的目标就是利用afl++来对libxml2库进行模糊测试,看是否挖掘它解析xml文件格式时的漏洞。
根据afl-training先下载对应版本的libxml2:
git clone https://github.com/GNOME/libxml2.git
cd libxml2
git submodule init
git submodule update
git checkout v2.9.2
然后编译:
CC=afl-clang-fast ./autogen.sh
AFL_USE_ASAN=1 make -j 4
环境变量的作用可以在官方手册--env_variables.txt里看,AFL_USE_ASAN的作用是启动ASAN特性来更好的检测崩溃。
- Setting AFL_USE_ASAN automatically enables ASAN, provided that your
compiler supports that. Note that fuzzing with ASAN is mildly challenging
- see notes_for_asan.txt.
然后编写harness来对函数进行检测,libxml2提供的接口有很多,可以通过官方手册来进一步了解。
我们的目的并不是深度挖掘该软件漏洞,而是通过对该软件漏洞的挖掘进一步掌握afl的使用方法,因此只需要看官方给的Libxml2 set of examples就可以了,挑选了parse1.c: Parse an XML file to a tree and free it来进行修改,最终得到的harness.c代码如下所示:
#include "libxml/parser.h"
#include "libxml/tree.h"
int main(int argc, char **argv) {
if (argc != 2)
return -1;
xmlDocPtr doc; /* the resulting document tree */
doc = xmlReadFile(argv[1], NULL, 0);
if (doc == NULL) {
return -1;
}
xmlFreeDoc(doc);
xmlCleanupParser();
return 0;
}
可以看到最主要fuzz的api是xmlReadFile、xmlFreeDoc以及xmlCleanupParser函数,通过命令行传入xml文件名称,接着对应的函数对文件数据进行解析。而afl主要是对xml文件进行变异以实现对libxml2的模糊测试。
编译harness,命令如下所示。-I指定头文件所在的路径,接上libxml2的静态链接库以实现将所需模糊测试的函数链接到harness中,-lm 使用math库,-lz 使用zlib库。
AFL_USE_ASAN=1 afl-clang-fast ./harness.c -I ~/work/fuzz/libxml2/include ~/work/fuzz/libxml2/.libs/libxml2.a -lz -lm -o fuzzer
创建模糊测试种子文件:
mkdir in
vim in/seed.xml
seed.xml文件内容如下所示:
<?xml version="1.0" encoding="UTF-8"?>
<note>
<to>Tove</to>
<from>Jani</from>
<heading>Reminder</heading>
<body>Don't forget me this weekend!</body>
</note>
启动fuzzer:
afl-fuzz -i in -o out ./fuzzer @@
此时可能会由于内存限制导致报错:
[-] Whoops, the target binary crashed suddenly, before receiving any input
from the fuzzer! Since it seems to be built with ASAN and you have a
restrictive memory limit configured, this is expected; please read
/usr/local/share/doc/afl/notes_for_asan.md for help.
[-] PROGRAM ABORT : Fork server crashed with signal 6
Location : afl_fsrv_start(), src/afl-forkserver.c:76
解决方案,加入-m none取消内存的限制:
afl-fuzz -m none -i in -o out ./fuzzer @@
不一会就会跑出crash,重现分析崩溃现场如下:
==21614==ERROR: AddressSanitizer: heap-buffer-overflow on address 0x621000002500 at pc 0x00000057da50 bp 0x7fffffffe070 sp 0x7fffffffe068
READ of size 1 at 0x621000002500 thread T0
#0 0x57da4f in xmlParseXMLDecl /home/f0cus7/fuzz/libxml2/parser.c:10666:2
#1 0x57eed9 in xmlParseDocument /home/f0cus7/fuzz/libxml2/parser.c:10771:2
#2 0x5bfbbf in xmlDoRead /home/f0cus7/fuzz/libxml2/parser.c:15298:5
#3 0x5bfbbf in xmlReadFile /home/f0cus7/fuzz/libxml2/parser.c:15360:13
#4 0x4c6080 in main /home/f0cus7/fuzz/afl-training/challenges/libxml2/./harness.c:20:11
#5 0x7ffff6c07b96 in __libc_start_main /build/glibc-2ORdQG/glibc-2.27/csu/../csu/libc-start.c:310
#6 0x41c369 in _start (/home/f0cus7/fuzz/afl-training/challenges/libxml2/fuzzer+0x41c369)
0x621000002500 is located 0 bytes to the right of 4096-byte region [0x621000001500,0x621000002500)
allocated by thread T0 here:
查看源码:
// parser.c:10666
MOVETO_ENDTAG(CUR_PTR);
NEXT;
}
// include/libxml/parseInternals.h: 297
#define MOVETO_ENDTAG(p) \
while ((*p) && (*(p) != '>')) (p)++
可以看到应该是由于*p访问字符串末尾越界导致的,实质上它不算是漏洞,而是正常的行为。
将它进行patch,将该函数添加到asan的白名单之中
void __attribute__((no_sanitize_address)) MOVETO_ENDTAG_PATCH(xmlChar *p)
{
while ((*p) && (*(p) != '>')) (p)++;
}
编译libxml2以及harness,重新再跑,就没有那么容易跑出crash了。
思考
在patch以后,就很难跑出crash了,思考下怎样可以更高效的进行模糊测试,主要方法包括:
- 提供更有效的
xml样本,同时对样本进行进一步的精简; - 对更多的
libxml2接口进行模糊测试,编写的harness进一步复杂; - 改进
harness.c,使其效率更高。
第一个可以通过在互联网上寻找更有效的xml文件,如fuzzdata中的xml数据,并使用afl-cmin以及afl-tmin工具来对样本进行精简。
第二个则是阅读官方手册,使得harness覆盖更多的数据接口,进行更为复杂的操作。
第三个是改进harness.c,根据AFL-FUZZ 启用 llvm,当启用llvm,使用afl-clang-fast对harness进行编译的时候可以在代码中加入__AFL_LOOP,使用AFL persistent mode减少frok以进一步提高效率。
使用方法如下所示,加入__AFL_LOOP后,afl会在启动一次进程后,根据后面指定的数字(1000)生成1000次样本并运行1000次后,再重新启动下一次进程运行,减少fork的次数以提升效率。同时没有使用afl进行模糊测试,而是单独运行程序时,循环不会起作用,达到在复现分析崩溃现场也可以使用同一个程序的效果。
while (__AFL_LOOP(1000))
{
XXXXXX
}
因此上面的harness可以修改如下所示,编译后再次模糊测试可以看到效率提高了很多(从每秒1000提升到了6000次)。
#include "libxml/parser.h"
#include "libxml/tree.h"
int main(int argc, char **argv) {
if (argc != 2)
return -1;
xmlDocPtr doc; /* the resulting document tree */
while (__AFL_LOOP(1000)) {
doc = xmlReadFile(argv[1], NULL, 0);
if (doc != NULL) {
xmlFreeDoc(doc);
}
}
xmlCleanupParser();
return 0;
}

heartbleed
heartbleed漏洞很经典,当然这次漏洞分析不是这次的本文的主要目的,此次实验的目的是如何使用afl挖掘出该漏洞崩溃点。
心脏滴血漏洞是CVE-2014-0160,在OpenSSL1.0.1版本中存在严重漏洞,该漏洞会导致内存越界,攻击者可以远程读取存OpenSSL服务器内存中64K的数据。影响版本:OpenSSL1.0.1、1.0.1a、1.0.1b、1.0.1c、1.0.1d、1.0.1e、1.0.1f、Beta 1 of OpenSSL 1.0.2等版本。
tls数据传输的过程如下所示,openssl很友好的支持了tls/ssl传输协议。
Client Server
------ ------
(1)
ClientHello --------> |
ServerHello |
Certificate* |
ServerKeyExchange* |
CertificateRequest* |
(2) |
<-------- ServerHelloDone |
Certificate* |
ClientKeyExchange |--- HANDSHAKE
CertificateVerify* |
[ChangeCipherSpec] |
(3) |
Finished --------> |
[ChangeCipherSpec] |
(4) |
<-------- Finished |
Application Data <-------> Application Data
BIO是openssl在实现tls/ssl协议流程过程中一个比较重要的概念,它是对数据的进一步封装。具体可参考的文章包括:
- Using OpenSSL with memory BIOs
- OpenSSL BIO_s_mem example
- Directly Read/Write Handshake data with Memory BIO
OpenSSL uses the a concept of BIOs which is an input/output abstraction allowing us to e.g. use data from a file, memory or network in a similar way.
下面来开始模糊测试相关部分的操作。
根据手册,先编译openssl 1.0.1f :
git clone https://github.com/openssl/openssl.git
git checkout OpenSSL_1_0_1f
CC=afl-clang-fast CXX=afl-clang-fast++ ./config -d
AFL_USE_ASAN=1 make
编译完成后,下一步需要编写harness,看handshake.cc关键代码。可以看到它开启了一个Memory BIO的server,并调用BIO_write函数往BIO队列中写入了data数据,但是这个data却是没有定义的。为了完善这个harness,最主要是定义data。
int main() {
static SSL_CTX *sctx = Init();
SSL *server = SSL_new(sctx);
BIO *sinbio = BIO_new(BIO_s_mem());
BIO *soutbio = BIO_new(BIO_s_mem());
SSL_set_bio(server, sinbio, soutbio);
SSL_set_accept_state(server);
/* TODO: To spoof one end of the handshake, we need to write data to sinbio
* here */
BIO_write(sinbio, data, size);
SSL_do_handshake(server);
SSL_free(server);
return 0;
}
我们可定义data为缓冲区,并从标准输入中获取该数据以为afl提供变异的数据,最终main函数如下所示:
int main() {
static SSL_CTX *sctx = Init();
SSL *server = SSL_new(sctx);
BIO *sinbio = BIO_new(BIO_s_mem());
BIO *soutbio = BIO_new(BIO_s_mem());
SSL_set_bio(server, sinbio, soutbio);
SSL_set_accept_state(server);
/* TODO: To spoof one end of the handshake, we need to write data to sinbio
* here */
char data [0x100];
size_t size = read(STDIN_FILENO, data, 0x100);
if(size == -1) {
return -1;
}
BIO_write(sinbio, data, size);
SSL_do_handshake(server);
SSL_free(server);
return 0;
}
编译harness,命令如下所示。-ldl指示连接器连接一个库。这个库里包含了dlopen及dlsym等函数即支持在运行时显示加载使用动态连接库的函数库。
AFL_USE_ASAN=1 afl-clang-fast++ -g handshake.cc ~/Desktop/openssl/libcrypto.a ~/Desktop/openssl/libssl.a ~/Desktop/openssl/libcrypto.a ~/Desktop/openssl/libssl.a -o handshake -I ~/Desktop/openssl/include -ldl
创建种子文件为变异提供输入:
mkdir in
echo 11111 > in/seed
最终进行fuzz:
afl-fuzz -m none -i in -o out ./handshake
跑了一段时间以后,成功跑出crash:

在看了ANSWERS.md以及HINTS.md以后,提示说因开启了ASAN特性,因此最好去读读docs/notes_for_asan.txt。在读完文档后知道启用ASAN特性进行fuzz的时候最好是对32位程序,因为它们消耗的内存大致在600-800m左右;而当程序是64位的时候,所消耗的内存会达到17.5 TB-20TB左右,所以直接跑64位程序可能会出错。
如果一定要跑的话,可以使用root权限来调用asan_cgroups/limit_memory.sh脚本运行(sudo ~/AFLplusplus/examples/asan_cgroups/limit_memory.sh -u fuzzer afl-fuzz -i in -o out -m none ./handshake);也可以像上面一样直接传参-m none来运行,当然这可能会出现程序耗内存过多被系统给杀掉的情况。
sendmail/1301
基础知识-parallel fuzzing
根据描述在多核的系统中运行时,为了最大化fuzz的效率,最好启动多个afl-fuzz或者在多系统中运行afl-fuzz,称为parallel fuzzing。
并行fuzz要看的手册是docs/parallel_fuzzing.txt,在把该文档浏览一遍以后,简要记录些基础知识。
每个afl-fuzz会独占一个cpu内核,因此在多核(n核)的系统中,最多会允许启动n个afl-fuzz实例,只启动一个实例也确实是有些浪费系统资源。
在一个系统中启动并行fuzz的方式也比较简单,要创建一个用于输出的同步目录sync_dir,同时在启动时对各个系统做好命名即可。
第一个实例启动命令如下所示,需要指定它为master(-M):
$ ./afl-fuzz -i testcase_dir -o sync_dir -M fuzzer01 [...other stuff...]
其余的实例也以同样的方式启动,指定它们为client(sencondary -S):
$ ./afl-fuzz -i testcase_dir -o sync_dir -S fuzzer02 [...other stuff...]
$ ./afl-fuzz -i testcase_dir -o sync_dir -S fuzzer03 [...other stuff...]
启动后所有的实例都会将它的状态保存到单独的目录中,如:
/path/to/sync_dir/fuzzer01/
每个实例会间隔一段时间后扫描同步文件夹,并将所有的interesting样本同步到自己的样本库中。
-M和-S的区别是,master实例会执行deterministic checks;而secondary实例则是会随机的调整(random tweaks)。这个deterministic checks以及random tweaks没太明白意思,感觉是master需要针对所有的实例做一些决策,其余的都不用。可以所有的实例都以-S启动,特别在目标是比较复杂的情况下,多个实例以-M的方式启动是没有必要的,有点浪费资源。
在多个系统中启动并行fuzz比单系统稍微复杂点,最主要的区别是要编写一个脚本来在系统之间进行同步:
- 使用
ssh证书登陆到各个系统中并将fuzz数据(/path/to/sync_dir/<fuzzer_id>/queue/)保存下来,样例如下所示:
bash
for s in {1..10}; do
ssh user@host${s} "tar -czf - sync/host${s}_fuzzid*/[qf]*" >host${s}.tgz
done
- 将上面保存的数据文件同步到其它的机器路径当中,样例如下所示:
bash
for s in {1..10}; do
for d in {1..10}; do
test "$s" = "$d" && continue
ssh user@host${d} 'tar -kxzf -' <host${s}.tgz
done
done
在experimental/distributed_fuzzing/路径下有对应的示例,可以参考。
值得一提的是crash是不会在各个实例之间进行同步的,需要用户自己主动去查看。
fuzz sendmail
sendmail是一个SMTP服务源码,提取出来的代码的主体功能是在7-bit MIME和8-bit MIME格式进行转换。
harness如下面的main所示,从文件中获取数据并调用mime7to8进行转换。
#include "my-sendmail.h"
#include <assert.h>
int main(int argc, char **argv){
HDR *header;
register ENVELOPE *e;
FILE *temp;
assert (argc == 2);
temp = fopen (argv[1], "r");
assert (temp != NULL);
header = (HDR *) malloc(sizeof(struct header));
header->h_field = (char *) malloc(sizeof(char) * 100);
header->h_field = "Content-Transfer-Encoding";
header->h_value = (char *) malloc(sizeof(char) * 100);
header->h_value = "quoted-printable";
e = (ENVELOPE *) malloc(sizeof(struct envelope));
e->e_id = (char *) malloc(sizeof(char) * 50);
e->e_id = "First Entry";
e->e_dfp = temp;
mime7to8(header, e);
fclose(temp);
return 0;
}
makefile如下所示,最终编译出来的程序是m1-bad。
CFLAGS ?= -g
all: m1-bad
clean:
rm -f *-bad *-ok
m1-bad: mime1-bad.c main.c
${CC} ${CFLAGS} -o m1-bad mime1-bad.c main.c -I .
编译命令如下:
CC=afl-clang-fast AFL_HARDEN=1 make
对功能进行测试:
$ echo hi > input
$ ./m1-bad input
buf-obuf=4294967232
obp-obuf=0
canary-obuf=4294967222
canary = GOOD
obuf = hi
canary should be GOOD
canary = GOO
创建种子文件:
$ mkdir in
$ echo hi > in/seed
因为我的系统cpu是8核的,最多可以开启8个实例,这里我决定开启4个实例。
afl-fuzz -i in -o out -M fuzzer01 ./m1-bad @@
afl-fuzz -i in -o out -S fuzzer02 ./m1-bad @@
afl-fuzz -i in -o out -S fuzzer03 ./m1-bad @@
afl-fuzz -i in -o out -S fuzzer04 ./m1-bad @@
对应的out目录下也有相应的路径产生:
$ ls out
fuzzer01 fuzzer02 fuzzer03 fuzzer04
不一会就跑出了crash。
date
date命令是关于时间的命令,它可以用来查看、更改系统时间,它是coreutils组件中的一个程序。
可以通过man手册来查看相应的用法:
DATE(1) User Commands DATE(1)
NAME
date - print or set the system date and time
SYNOPSIS
date [OPTION]... [+FORMAT]
date [-u|--utc|--universal] [MMDDhhmm[[CC]YY][.ss]]
DESCRIPTION
Display the current time in the given FORMAT, or set the system date.
Mandatory arguments to long options are mandatory for short options too.
-d, --date=STRING
display time described by STRING, not 'now'
--debug
annotate the parsed date, and warn about questionable usage to stderr
-f, --file=DATEFILE
like --date; once for each line of DATEFILE
-I[FMT], --iso-8601[=FMT]
output date/time in ISO 8601 format. FMT='date' for date only (the default), 'hours', 'minutes', 'seconds', or 'ns' for date and time to the indicated precision. Example:
2006-08-14T02:34:56-06:00
我们可以通过设置不同的TZ环境变量来显示不同的时间:
$ date
Thu 03 Dec 2020 12:08:47 PM EST
$ TZ='Asia/Tokyo' date
Fri 04 Dec 2020 02:08:56 AM JST
$ TZ='America/Los_Angeles' date
Thu 03 Dec 2020 08:47:45 AM PST
$ TZ='Europe/London' date
Thu 03 Dec 2020 04:48:25 PM GM
此次实验的目的是通过对环境变量TZ的模糊测试来了解在不是从标准输入以及文件进行输入的情况下(环境变量),如何使用afl进行fuzz。
先编译漏洞版本的date程序:
git clone https://github.com/coreutils/coreutils
cd coreutils
git submodule init && git submodule update
sudo apt install autopoint bison gperf autoconf texinfo # already installed in the container environment
git checkout f4570a9
./bootstrap # may finish with some errors to do with 'po' files, which can be ignored
#this old version doesn't work with modern compilers, we need to apply a patch
pushd gnulib && wget https://src.fedoraproject.org/rpms/coreutils/raw/f28/f/coreutils-8.29-gnulib-fflush.patch && patch -p1 < coreutils-8.29-gnulib-fflush.patch && popd
# configure
CC=afl-clang-fast CXX=afl-clang-fast++ ./configure
# make
AFL_USE_ASAN=1 make -j src/date # only compile the date binary - saves a lot of time
./src/date
Mon Jul 3 08:11:23 PDT 2017
在编译的过程可能会报错:
cc1: error: '-Wabi' won't warn about anything [-Werror=abi]
好像是因为我用的afl版本太新了,于是我决定降到afl-training中用的版本2.68c:
cd ~/path/to/AFLplusplus
git checkout 2.68c
make distrib
sudo make install
目标存在的已知漏洞是CVE-2017-7476,主要是TZ环境变量处理不当形成的漏洞,接下来思考如何让afl可以对环境变量进行fuzz。
因为目前afl对从标准输入以及文件中读取的数据的fuzz支持的比较友好,对于环境变量的fuzz要进行一定的转换,主要途径有以下三种:
- 从源码中找到相应的获取
TZ环境变量(getenv)的地方,把代码修改成从标准输入获取数据; - 编写
harness,在程序的开头设置TZ环境变量,然后继续运行; - 编写自定义的
getenv函数并使用LD_PRELOAD来对函数进行hook,实现每次调用getenv函数时都从stdin中获取数据。
三种方式的优劣如下:
- 第一种可行,但是需要在代码中找全对
TZ变量引用的地方并进行修改,有点费劲; - 第二种可行,在函数的开头加入从标准输入中获取数据并设置环境变量的代码,如examples/bash_shellshock一样,简单便捷;
- 第三种可行,且这种方式对于其它类似的情况也适用,但需要编写额外的
so,有点麻烦。
第二种方式最简单,只需要在src/date.c的main函数开头加入从标准输入中获取数据并设置TZ环境变量的代码,diff代码如下所示。
$ diff src/date.c date_back.c
361,364d360
< char env_data[0x400];
< read(0, env_data, 0x400);
< setenv("TZ", env_data, 1);
<
修改完成以后,重新编译date程序,此时对于环境变量的模糊测试已经转换成了对标准输入中的数据的模糊测试,满足afl fuzz的条件。
创建种子文件:
$ mkdir in
$ echo 1>in/seed #或 echo -n "Europe/London" > in/london 效率更高
因为我编译的时候开启了ASAN特性,所以运行的时候最好用asan_cgroups/limit_memory.sh以限制内存:
sudo ~/AFLplusplus/examples/asan_cgroups/limit_memory.sh -u fuzzer ~/AFLplusplus/afl-fuzz -m none -i in -o out ~/Desktop/coreutils/src/date --date "2017-03-14T15:00-UTC"
不过我比较简单粗暴,直接加进去-m none就没管了:
afl-fuzz -m none -i in -o out ~/Desktop/coreutils/src/date --date "2017-03-14 15:00 UTC"
在程序后面加入--date "2017-03-14 15:00 UTC"的原因是让date程序的输出都一致,免得程序因为时间的不同导致输出不同从而去模糊测试一些不相干的代码,提高效率。
过了一会,也就跑出了crash:
使用afl在对不是从标准输入或者文件中获取数据的目标进行模糊测试的时候,如何进行合理的转换是需要好好思考的问题。
ntpq
ntpq 指令使用NTP模式6数据包与NTP服务器通信,能够在允许的网络上查询的兼容的服务器。它以交互模式运行,或者通过命令行参数运行。
此次模糊测试的ntpq版本是4.2.2,下载链接是https://www.eecis.udel.edu/~ntp/ntp_spool/ntp4/ntp-4.2/ntp-4.2.2.tar.gz,先下载代码:
curl https://www.eecis.udel.edu/~ntp/ntp_spool/ntp4/ntp-4.2/ntp-4.2.2.tar.gz -o ntp-4.2.2.tar.gz
tar -xf ntp-4.2.2.tar.gz
模糊测试的漏洞目标是CVE-2009-0159: NTP Remote Stack Overflow,是在cookedprint函数中出的问题。
先编译ntpq:
CC=afl-clang-fast ./configure
AFL_HARDEN=1 make -C ntpq
接下来思考如何实现利用afl-fuzz对网络收发包程序ntpq的模糊测试,一个可行的方法是对目标函数cookedprint进行针对性的fuzz,而不是花心思去用afl来构造ntpd数据包。
cookedprint函数原型如下所示,因此只需从标准输入中获取datatype、length、data以及status,并将fp重定向给stdout,并对函数进行调用就可以了。
// ntpq.c: 3000
/*
* cookedprint - output variables in cooked mode
*/
static void
cookedprint(
int datatype,
int length,
char *data,
int status,
FILE *fp
)
{
最终形成的调用代码如下所示:
#ifdef __AFL_HAVE_MANUAL_CONTROL
__AFL_INIT();
#endif
int datatype=0;
int status=0;
char data[1024*16] = {0};
int length=0;
#ifdef __AFL_HAVE_MANUAL_CONTROL
while (__AFL_LOOP(1000)) {
#endif
datatype=0;
status=0;
memset(data,0,1024*16);
read(0, &datatype, 1);
read(0, &status, 1);
length = read(0, data, 1024 * 16);
cookedprint(datatype, length, data, status, stdout);
#ifdef __AFL_HAVE_MANUAL_CONTROL
}
#endif
return 0;
将上述代码写入到ntpq的main函数当中,形成的patch代码如下所示:
$ diff ntpq/ntpq_back.c ntpq/ntpq.c
491c491,512
< return ntpqmain(argc, argv);
---
> /* return ntpqmain(argc, argv); */
> #ifdef __AFL_HAVE_MANUAL_CONTROL
> __AFL_INIT();
> #endif
> int datatype=0;
> int status=0;
> char data[1024*16] = {0};
> int length=0;
> #ifdef __AFL_HAVE_MANUAL_CONTROL
> while (__AFL_LOOP(1000)) {
> #endif
> datatype=0;
> status=0;
> memset(data,0,1024*16);
> read(0, &datatype, 1);
> read(0, &status, 1);
> length = read(0, data, 1024 * 16);
> cookedprint(datatype, length, data, status, stdout);
> #ifdef __AFL_HAVE_MANUAL_CONTROL
> }
> #endif
> return 0
重新编译,生成对应的harness。
创建种子文件:
$ mkdir in
$ echo 1>in/seed
启动fuzz(当然也可以使用并行fuzz进一步提高效率,我这里没有用):
afl-fuzz -i in -o out ~/Desktop/ntp-4.2.2/ntpq/ntpq
不一会跑出crash:

跑了一段时间以后,会想知道跑了这么久跑了多少的覆盖率(针对cookedprint函数),可以使用llvm中对gcov的支持来查看覆盖率,具体可以去看gcov與LLVM中的實現。
简单来说gcov是一个测试代码覆盖率的工具。与GCC(llvm也支持)一起使用来分析程序,以帮助创建更高效、更快的运行代码,并发现程序的未测试部分。是一个命令行方式的控制台程序,需要结合lcov,gcovr等前端图形工具才能实现统计数据图形化。
知道了这个概念具体来操作,先跑make distclean清除之前的痕迹,然后编译支持gcov的ntpq:
CC=clang CFLAGS="--coverage -g -O0" ./configure && make -C ntpq
然后调用ntpq运行out/queue目录下所有的文件,该目录下存储的是会触发新路径的文件,运行一次即可记录所有覆盖的路径:
$ for F in out/queue/id* ; do ./ntp-4.2.2/ntpq/ntpq < $F > /dev/null ; done
生成gcov报告:
cd ~/Desktop/ntp-4.2.2/ntpq
llvm-cov-11 gcov ntpq.c
生成的报告名称是ntpq.c.gcov,打开该文件进行查看。特别关注的是cookedprint函数,示例代码如下所示。其中前面是-的表示是没有对应生成代码的区域;前面是数字的表示执行了的次数;前面是#####的表示是没有执行到的代码,可以通过观察覆盖率然后调整种子提升模糊测试效率。
3029 -: 3024:static void
3030 365: 3025:cookedprint(
3031 -: 3026: int datatype,
3032 -: 3027: int length,
3033 -: 3028: char *data,
3034 -: 3029: int status,
3035 -: 3030: FILE *fp
3036 -: 3031: )
3037 -: 3032:{
3038 -: 3033: register int varid;
3039 -: 3034: char *name;
3040 -: 3035: char *value;
3041 -: 3036: char output_raw;
3042 -: 3037: int fmt;
3043 -: 3038: struct ctl_var *varlist;
3044 -: 3039: l_fp lfp;
3045 -: 3040: long ival;
3046 -: 3041: struct sockaddr_storage hval;
3047 -: 3042: u_long uval;
3048 -: 3043: l_fp lfparr[8];
3049 -: 3044: int narr;
3050 -: 3045:
3051 365: 3046: switch (datatype) {
3052 -: 3047: case TYPE_PEER:
3053 194: 3048: varlist = peer_var;
3054 194: 3049: break;
3055 -: 3050: case TYPE_SYS:
3056 51: 3051: varlist = sys_var;
3057 51: 3052: break;
3058 -: 3053: case TYPE_CLOCK:
3059 119: 3054: varlist = clock_var;
...
3079 #####: 3074: if (!decodets(value, &lfp))
3080 #####: 3075: output_raw = '?';
3081 -: 3076: else
3082 #####: 3077: output(fp, name, prettydate(&lfp));
3083 #####: 3078: break;
字典模式 fuzz
afl的一个局限性是它的变异是语法无效的(syntax-blind),对于SQL以及HTTP这种格式较明确的处理效率不高,如很难变异生成*Set-Cookie: FOO=BAR* to *Content-Length: -1*这样的语句。为了处理这种情况,afl引入了字典模式以提高,基于字典语法来进行变异可较大提高性能,具体详情可以参考afl-fuzz: making up grammar with a dictionary in hand以及Finding bugs in SQLite, the easy way。
在命令行参数中加入-x [name.dict]即指定相应的字典,对于上面的ntpq,afl-training也构建了ntpq.dict字典来提升fuzz,该字典内容如下:
"leap"
"reach"
"refid"
"reftime"
"clock"
"org"
"rec"
"xmt"
"flash"
"srcadr"
"peeradr"
"dstadr"
"filtdelay"
"filtoffset"
"filtdisp"
"filterror"
"pkt_dup"
"pkt_bogus"
"pkt_unsync"
"pkt_denied"
"pkt_auth"
"pkt_stratum"
"pkt_header"
"pkt_autokey"
"pkt_crypto"
"peer_stratum"
"peer_dist"
"peer_loop"
"peer_unreach"
启动fuzz的命令是:
afl-fuzz -i in -o out -x ntpq.dict ~/Desktop/ntp-4.2.2/ntpq/ntpq
cyber-grand-challenge/CROMU_00007
cgc比赛的一样例题,有两个洞一个比较难,一个比较容易。容易的洞比较轻松可以fuzz出来,难的洞作者说可能fuzz不出来。感觉对于afl的理解没啥帮助,就没啥做的必要和价值,跳过。
sendmail/1305
persistent mode
在libxml2的fuzz过程中对afl的persistent mode进行了初步的介绍,现在来进一步对它进行介绍。
之前的样例中afl运行一次样例就要执行一次fork或execve,这样会大量的消耗资源以及使得模糊测试的时间消耗在创建新的进程上。为了尽可能的使资源以及时间花在真正的fuzz上,afl设计实现了persistent mode,在每次运行关联性不强的目标以及内存状态可以容易的恢复到初始状态的目标上,我们可以使用persistent mode,调用相关的api即可实现一次创建进程运行多次样例的目标。具体详情可以查看New in AFL: persistent mode以及Fuzzing capstone using AFL persistent mode。
在harness中加入while (__AFL_LOOP(1000)) {将模糊测试的目标代码给圈起来就算开启了persistent mode,还要提一句的是应该是要在llvm mode中才能使用(使用afl-clang-fast编译的时候)。
int main(int argc, char** argv) {
while (__AFL_LOOP(1000)) {
/* Reset state. */
memset(buf, 0, 100);
/* Read input data. */
read(0, buf, 100);
/* Parse it in some vulnerable way. You'd normally call a library here. */
if (buf[0] != 'p') puts("error 1"); else
if (buf[1] != 'w') puts("error 2"); else
if (buf[2] != 'n') puts("error 3"); else
abort();
}
}
fuzz sendmail
sendmail 1305的目标是模糊测试sendmail中的prescan函数,它是预处理用户提供的邮箱以验证它的合法性。
prescan-overflow-bad-start.c的内容如下所示,根据内容示意,主要对addr内容进行模糊测试。
int main(){
char *addr;
int delim;
static char **delimptr;
char special_char = '\377'; /* same char as 0xff. this char will get interpreted as NOCHAR */
int i = 0;
addr = (char *) malloc(sizeof(char) * 500);
strcpy(addr, "Misha Zitser <misha@mit.edu>");
delim = '\0';
delimptr = NULL;
OperatorChars = NULL;
ConfigLevel = 5;
CurEnv = (ENVELOPE *) malloc(sizeof(struct envelope));
CurEnv->e_to = (char *) malloc(strlen(addr) * sizeof(char) + 1);
strcpy(CurEnv->e_to, addr);
parseaddr(addr, delim, delimptr);
return 0;
}
修改代码形成harness,开启persistent mode以及从标准输入中获取addr:
int main(){
char *addr;
int delim;
const int MAX_MESSAGE_SIZE = 1000;
int size;
static char **delimptr;
/* This address is valid */
/* "Misha Zitser <misha@mit.edu>" */
delim = '\0';
delimptr = NULL;
OperatorChars = NULL;
ConfigLevel = 5;
CurEnv = (ENVELOPE *) malloc(sizeof(struct envelope));
CurEnv->e_to = (char *) malloc(MAX_MESSAGE_SIZE + 1);
// Read from stdin
addr = (char *) calloc(1,MAX_MESSAGE_SIZE+1);
#ifdef __AFL_HAVE_MANUAL_CONTROL
__AFL_INIT();
while (__AFL_LOOP(1000)) {
#endif
size = read(STDIN_FILENO, addr, MAX_MESSAGE_SIZE);
if (size == -1) {
printf("Failed to read from stdin\n");
return(-1);
}
memcpy(CurEnv->e_to, addr, size);
CurEnv->e_to[size] = '\0'; // the api requires a C string
parseaddr(addr, delim, delimptr);
#ifdef __AFL_HAVE_MANUAL_CONTROL
}
#endif
return 0;
}
编译harness:
cp prescan-overflow-bad-fuzz.c prescan-overflow-bad.c
CC=afl-clang-fast AFL_USE_ASAN=1 make
创建种子文件:
$ mkdir in
$ echo -n "test@test.com" > in/seed
运行fuzz:
$ afl-fuzz -m none -i in -o out ./prescan-bad
0x04 总结
通过对afl-training的学习,知道了afl的基本使用方法,fuzzer主要对从标准输入以及文件获取数据的模糊测试支持比较友好;对于网络协议或其它形式获取输入的目标,我们可以修改代码编写适合afl fuzz的harness来进行模糊测试;合适的情况下可以开启persistent mode以及使用并行fuzz来提高效率,也可以用字典模式来提高效率;定期可以查看目标的覆盖率,修改种子文件来提高覆盖率。
万物皆可fuzz。




