0x00 大纲
本文将回答下面几个问题:
- CodeQL能否找到log4shell这个漏洞
- 如何基于log4j-api-2.14.1.jar和log4j-core-2.14.1.jar创建CodeQL database
- 如何基于CodeQL进行调用图分析
- CodeQL如何解析虚拟函数调用
- 如何对CodeQL的污点分析进行debug
0x01 前言
传言log4shell这个漏洞是通过CodeQL发现的,而且是在lgtm.com发现的。我想动手试一下CodeQL能不能发现log4shell这个漏洞。
我先尝试去lgtm.com找被修复前的版本,我记得之前lgtm可以看历史commit的分析结果的。然而我现在再去lgtm上找发现不能切换commit了,只能在history那个页面看commit的记录,但是那个页面只能看到新增代码对应的漏洞,在浏览的时候发现了个:
https://lgtm.com/projects/g/apache/logging-log4j2/rev/14e307ac825f9c169f8c14203c680564d1943ac2
这个对应的时间是2021.12.25是漏洞发现后的提交记录,但是我猜测原本应该是和这个差不多的提示。因为都是用官方的检测规则检测的,对应的检测jndi注入的规则是:
https://github.com/github/codeql/blob/main/java/ql/src/Security/CWE/CWE-074/JndiInjection.ql
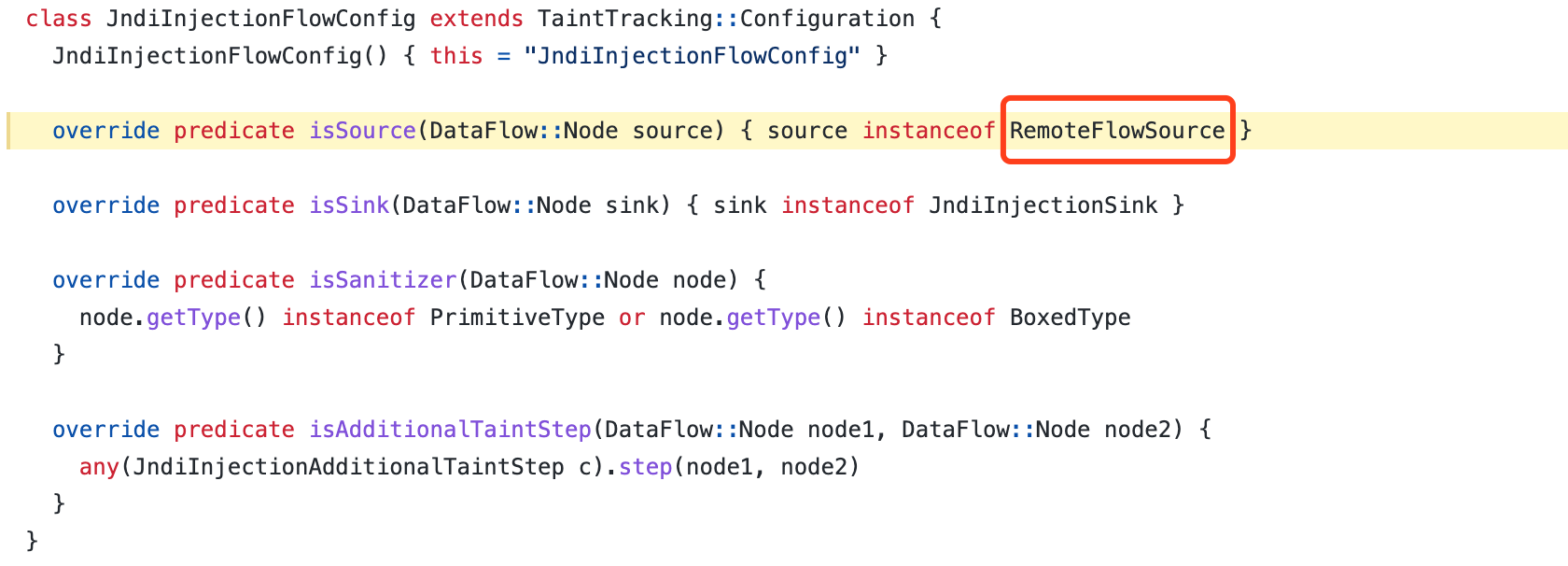
从图中可以看到source是RemoteFlowSource,所以不可能查出从log#error参数到Context#lookup参数的路径。
如果再往后翻翻,如果能找到提交JndiManager.java提交的记录应该就行了?然而现实很骨感
创建那个JndiManager.java文件的提交commit是 c017d3e87f7704a247245a4f7ddf879a77563ea4
然后访问 https://lgtm.com/projects/g/apache/logging-log4j2/rev/c017d3e87f7704a247245a4f7ddf879a77563ea4 显示404
又访问另一个commit https://lgtm.com/projects/g/apache/logging-log4j2/rev/19c92876f957a8439fa9c21ea6b9c13aced0c006 显示build失败
0x02 创建log4j2 database
只剩自己创建database进行分析这一条路了。
lgtm支持输入github地址创建project,然后我就clone了log4j2的repo到本地,然后回滚到修复前的版本,然后传到了https://github.com/BytecodeDL/log4j2 创建了https://lgtm.com/projects/g/BytecodeDL/log4j2/ 这个project,创建的时候并没有那么顺利,刚开始直接build的时候还是失败,然后加了一些配置也不行,后来rebuild了一下好像就好了,也有可能是因为我修复了pom文件才rebuild成功。具体原因不详,复现的话可以reset到这个231596956e23a1dd1aadf48c5e0f9ad0089a9940,然后查看alert好像也并没有出现jndi alert 也不知道哪里出了问题。然后又把这个文章 中的规则,复制上去,执行发现,可以查出结果但是和文章中的不太一样。
原本以为线上创建的数据库有问题,想本地再build一次,但是本地死活build不起来,因为没有JDK9,安装一个又觉得费劲。开始研究能不能像ByteCodeDL那样直接从bytecode创建CodeQL的database。经过一周的研究发现理论上是可行的,但是由于本人编译原理相关知识相对薄弱,暂时没有完成这项工作。在研究的时候发现CodeQL在创建java database时实际不需要编译,仅有源码即可创建database,研究产出见项目extractor-java。关于CodeQL java extractor分析,有空再补一篇文章。先尝试直接用clone下来的源码创建,但是遇到了未知bug,在排除test文件后可以创建database。最终通过反编译log4j-api-2.14.1.jar 和log4j-core-2.14.1.jar ,然后再利用extractor-java成功创建log4j2的database。没错又回到了反编译这条路,extractor-java和codeql_compile有什么区别呢?区别在于extractor-java反编译之后不需要再进行build。CodeQL创建database大致过程为,先利用CodeQL魔改的javacc读取java文件,将源码解析成AST,然后遍历AST节点生成Trap文件,最会将Trap文件转换成database。
0x03 调用图分析
通过调试,测试代码为
public class logshell {
public static void main(String[] args) {
Logger logger = LogManager.getLogger();
logger.error("ffff${jndi://127.0.0.1:8787}");
}
}
得到运行时的调用栈
lookup:417, InitialContext (javax.naming)
lookup:172, JndiManager (org.apache.logging.log4j.core.net)
lookup:56, JndiLookup (org.apache.logging.log4j.core.lookup)
lookup:221, Interpolator (org.apache.logging.log4j.core.lookup)
resolveVariable:1110, StrSubstitutor (org.apache.logging.log4j.core.lookup)
substitute:1033, StrSubstitutor (org.apache.logging.log4j.core.lookup)
substitute:912, StrSubstitutor (org.apache.logging.log4j.core.lookup)
replace:467, StrSubstitutor (org.apache.logging.log4j.core.lookup)
format:132, MessagePatternConverter (org.apache.logging.log4j.core.pattern)
format:38, PatternFormatter (org.apache.logging.log4j.core.pattern)
toSerializable:344, PatternLayout$PatternSerializer (org.apache.logging.log4j.core.layout)
toText:244, PatternLayout (org.apache.logging.log4j.core.layout)
encode:229, PatternLayout (org.apache.logging.log4j.core.layout)
encode:59, PatternLayout (org.apache.logging.log4j.core.layout)
directEncodeEvent:197, AbstractOutputStreamAppender (org.apache.logging.log4j.core.appender)
tryAppend:190, AbstractOutputStreamAppender (org.apache.logging.log4j.core.appender)
append:181, AbstractOutputStreamAppender (org.apache.logging.log4j.core.appender)
tryCallAppender:156, AppenderControl (org.apache.logging.log4j.core.config)
callAppender0:129, AppenderControl (org.apache.logging.log4j.core.config)
callAppenderPreventRecursion:120, AppenderControl (org.apache.logging.log4j.core.config)
callAppender:84, AppenderControl (org.apache.logging.log4j.core.config)
callAppenders:540, LoggerConfig (org.apache.logging.log4j.core.config)
processLogEvent:498, LoggerConfig (org.apache.logging.log4j.core.config)
log:481, LoggerConfig (org.apache.logging.log4j.core.config)
log:456, LoggerConfig (org.apache.logging.log4j.core.config)
log:63, DefaultReliabilityStrategy (org.apache.logging.log4j.core.config)
log:161, Logger (org.apache.logging.log4j.core)
tryLogMessage:2205, AbstractLogger (org.apache.logging.log4j.spi)
logMessageTrackRecursion:2159, AbstractLogger (org.apache.logging.log4j.spi)
logMessageSafely:2142, AbstractLogger (org.apache.logging.log4j.spi)
logMessage:2017, AbstractLogger (org.apache.logging.log4j.spi)
logIfEnabled:1983, AbstractLogger (org.apache.logging.log4j.spi)
error:740, AbstractLogger (org.apache.logging.log4j.spi)
main:9, logshell (com.yxxx)
logger#error一路调用到InitialContext#lookup。先不考虑污点分析,先考虑调用图,看CodeQL能不能找到AbstractLogger#error到InitialContext#lookup的调用路径。
根据文档CodeQL中表达调用关系的有这么三种谓语
-
calls
-
Holds if this callable calls
target. -
callImpls
-
Holds if c is a viable implementation of a callable called by this callable, taking virtual dispatch resolution into account.
-
polyCalls
-
Holds if this callable may call the specified callable, taking virtual dispatch into account.
大概意思就是polyCalls和callImpls会进行虚拟调用解析,而calls直接将编译期间确定函数作为被调函数,即使他是个interface接口。为了搞清楚CodeQL是如何解析虚拟函数调用的,我进行了一次黑盒测试,(由于实力不足还不能从代码层面硬刚),得出的结论是,CodeQL解析虚拟函数调用时,基本和CHA差不多。
测试过程如下,选取了 https://github.com/BytecodeDL/Benchmark/tree/main/src/main/java/com/bytecodedl/benchmark/demo 中的VirtualCalldemo1,VirtualCalldemo2,VirtualCalldemo3 作为测试。
package com.bytecodedl.benchmark.demo;
public class VirtualCallDemo1 implements VirtualCallInterface1 {
public VirtualCallInterface1 parent;
public static void main(String[] args) {
VirtualCallInterface1 vcall2 = new VirtualCallDemo2();
VirtualCallDemo1 vcall1 = new VirtualCallDemo1(vcall2);
VirtualCallInterface1 varParent = vcall1.getParent();
String source = vcall1.source();
varParent.foo(source);
}
public VirtualCallDemo1(VirtualCallInterface1 argParent){
this.parent = argParent;
}
public VirtualCallInterface1 getParent() {
return parent;
}
public void foo(String fooArg) {
VirtualCallDemo1.target(fooArg);
}
public static void target(String targetArg){
}
public String source(){
return "source";
}
}
关键是考察CodeQL对varParent.foo(); ,人为可以判断出varParent.foo() 应该被解析成VirtualCallDemo2#foo
污点分析的结果最终会以path的形式展示在vscode侧栏,对用户非常友好,CallGraph的结果能不能也写成path呢?经过搜索后发现确实可以,参考文档或者这个Issue 或者下面的代码
/**
* @kind path-problem
*/
import java
class FooMethod extends Method {
FooMethod() {
getName() = "foo"
}
}
class TargetMethod extends Method {
TargetMethod() {
getName() = "target"
}
}
class MyMainMethod extends Method {
MyMainMethod() {
getName() = "main" and
this.getDeclaringType().hasQualifiedName("com.bytecodedl.benchmark.demo", "VirtualCallDemo1")
}
}
query predicate edges(Method a, Method b) { a.polyCalls(b) }
from TargetMethod end, MyMainMethod entryPoint
where edges+(entryPoint, end)
select end, entryPoint, end, "Found a path from start to target."
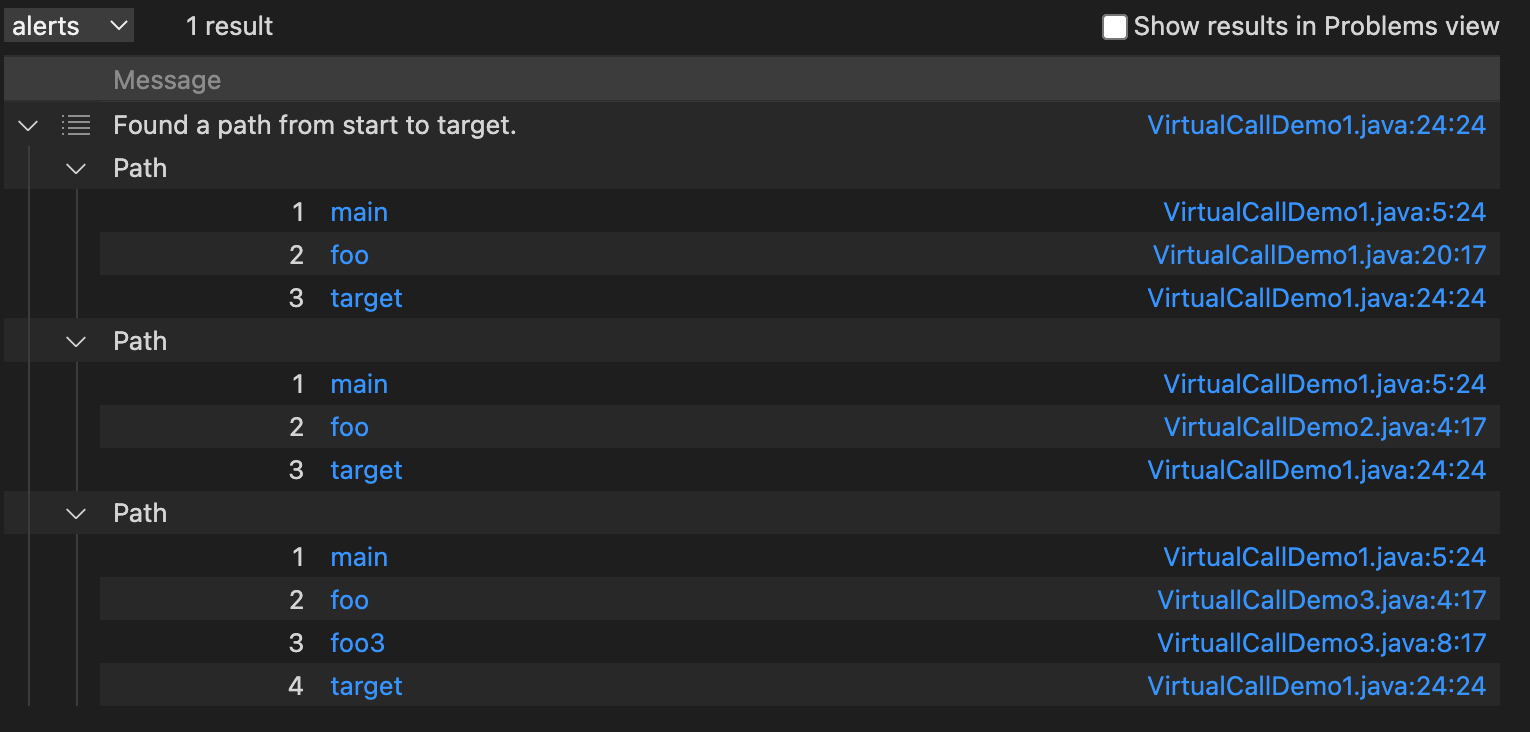
从分析结果可以看出CodeQL将varParent.foo() 解析成了VirtuallCall1#foo、VirtuallCall2#foo 、 VirtuallCall2#foo,既不符合指针分析的结果,也不符合RTA分析的结果,非常吻合CHA分析的结果。得出这个结果后,感觉CodeQL也不是想象中的那么强大,因为过程间的分析非常依赖虚拟函数解析的准确性,然而CHA算法解析不太准确,会带来很多误报,同时也导致分析速度变慢,但是印象中CodeQL分析速度一直都挺快的,CodeQL是有啥黑魔法吗?确实有黑魔法,CodeQL牺牲了精度换来了速度,这个后面再进行进一步介绍。
言归正传,开始利用CodeQL分析从error到lookup,注意这个要想成功显示path,最后的sink需要时出现在源码中的,要不然显示不出来path,所以这里将Context#lookup的caller也就是JndiManager#lookup作为最终的sink,而不是Context#lookup
/**
* @kind path-problem
*/
import java
class LookupMethod extends Method {
LookupMethod() {
getName() = "lookup" and
this.getDeclaringType().getASupertype*().hasQualifiedName("javax.naming", "Context")
}
}
class JndiMangerMethod extends Method {
JndiMangerMethod() {
getName() = "lookup" and
this.getDeclaringType().hasQualifiedName("org.apache.logging.log4j.core.net", "JndiManager")
}
}
class ErrorMethod extends Method {
ErrorMethod() {
getParameterType(0).hasName("String") and
getNumberOfParameters() = 1 and
getName() = "error" and
this.getDeclaringType().hasQualifiedName("org.apache.logging.log4j.spi", "AbstractLogger")
}
}
class StrategyLogMethod extends Method{
StrategyLogMethod(){
getName() = "log" and
this.getDeclaringType().getASupertype*().hasQualifiedName("org.apache.logging.log4j.core.config", "DefaultReliabilityStrategy")
}
}
query predicate edges(Method a, Method b) { a.polyCalls(b) }
from JndiMangerMethod end, ErrorMethod entryPoint
where edges+(entryPoint, end)
select end, entryPoint, end, "Found a path from start to target."
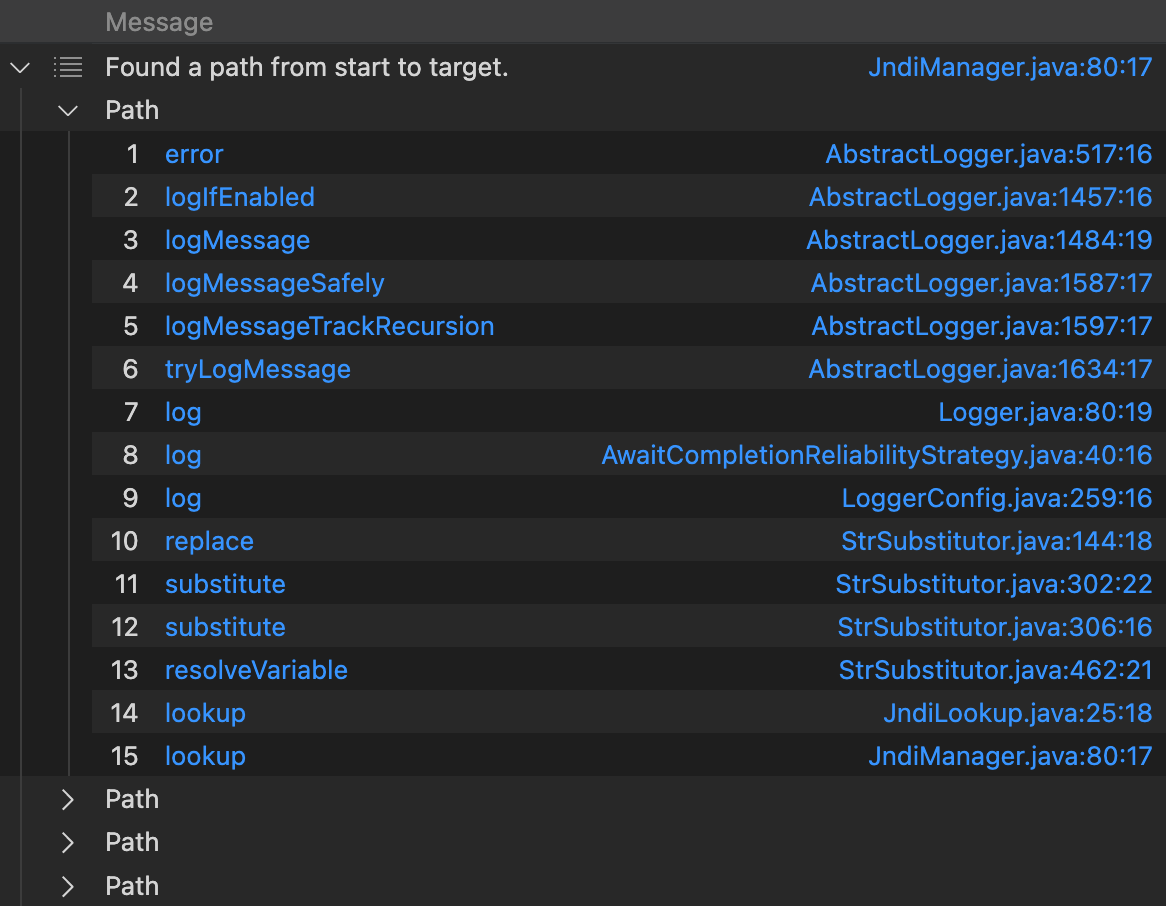
和真实调用栈比较后发现,到第8行就不一样了,strategy.log( 解析成了AwaitCompletionReliabilityStrategy#log 而不是实际的DefaultReliabilityStrategy#log
这是什么原因呢?是创建的database的有问题吗?
下面开始进行debug,先看error能不能到DefaultReliabilityStrategy#log
将上述代码中的end的类型改成 StrategyLogMethod即可,得出的结果如下:
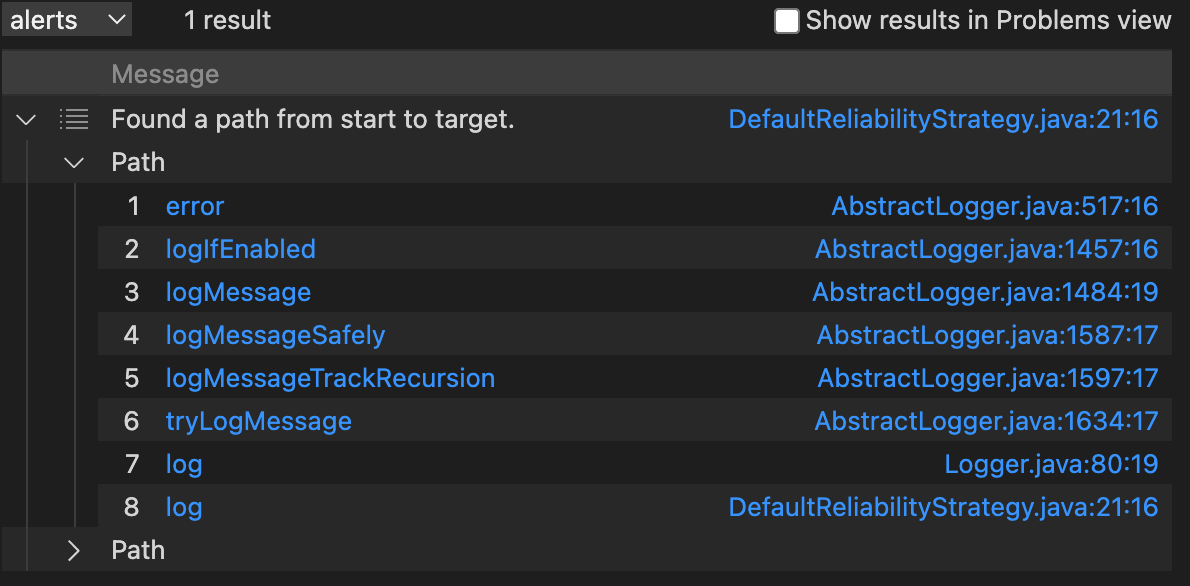
从AbstractLogger#error能够调用到DefaultReliabilityStrategy#log ,那么从DefaultReliabilityStrategy#log 能不能调用到JndiManager#lookup呢,答案也是可以的
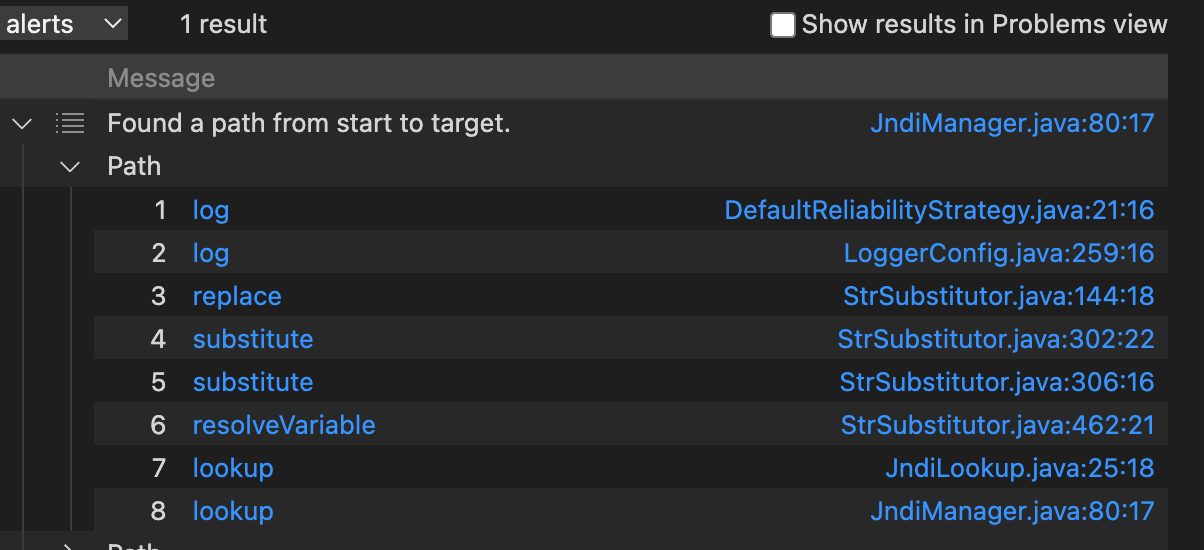
哪为啥直接查AbstractLogger#error到JndiManager#lookup没有相应的路径呢?我觉得可能和CodeQL的优化策略有关,导致我们查到的并不是全部的结果,而是CodeQL帮我们选取的部分结果,这种情况在分析大型项目我觉得是无法避免的,如果仅靠CHA解析虚拟函数调用,调用图就会变的比较大,然后找两个点之间的全部路径又是np hard问题,所以CodeQL这样处理也情有可原。
还有个问题,上面的路径虽然和真实的不一样,有没有可能也是真实的呢?看了一下,走不到那个分支,还没来得及研究走进那个分支需要什么条件。
做个小结:CodeQL能找到error到lookup的路径,但是找不到和真实调用栈一摸一样的调用路径。
0x04 污点分析
污点分析,势必要涉及到过程间的数据流分析,过程间的数据流分析又依赖调用图,那CodeQL在进行污点分析时是如何解析虚拟函数调用的呢?接着用VirtualCallDemo1进行黑盒测试
/**
* @kind path-problem
*/
import java
import semmle.code.java.dataflow.FlowSources
import DataFlow::PathGraph
class SourceMethod extends Method {
SourceMethod() {
getName() = "source" and
this.getDeclaringType().hasQualifiedName("com.bytecodedl.benchmark.demo", "VirtualCallDemo1")
}
}
class TargetMethod extends Method {
TargetMethod() {
getName() = "target"
}
}
class Tainttrack extends TaintTracking::Configuration {
Tainttrack() {
this = "Tainttrack"
}
override predicate isSource(DataFlow::Node source) {
exists(SourceMethod sourceMethod, Call call |
call.getCallee() = sourceMethod and
source.asExpr() = call)
}
override predicate isSink(DataFlow::Node sink) {
exists(Call call, TargetMethod method |
call.getCallee() = method and
sink.asExpr() = call.getAnArgument()
)
}
}
from Tainttrack config , DataFlow::PathNode source, DataFlow::PathNode sink
where
config.hasFlowPath(source, sink)
select sink.getNode(), source, sink, "unsafe lookup", source.getNode(), "this is user input"
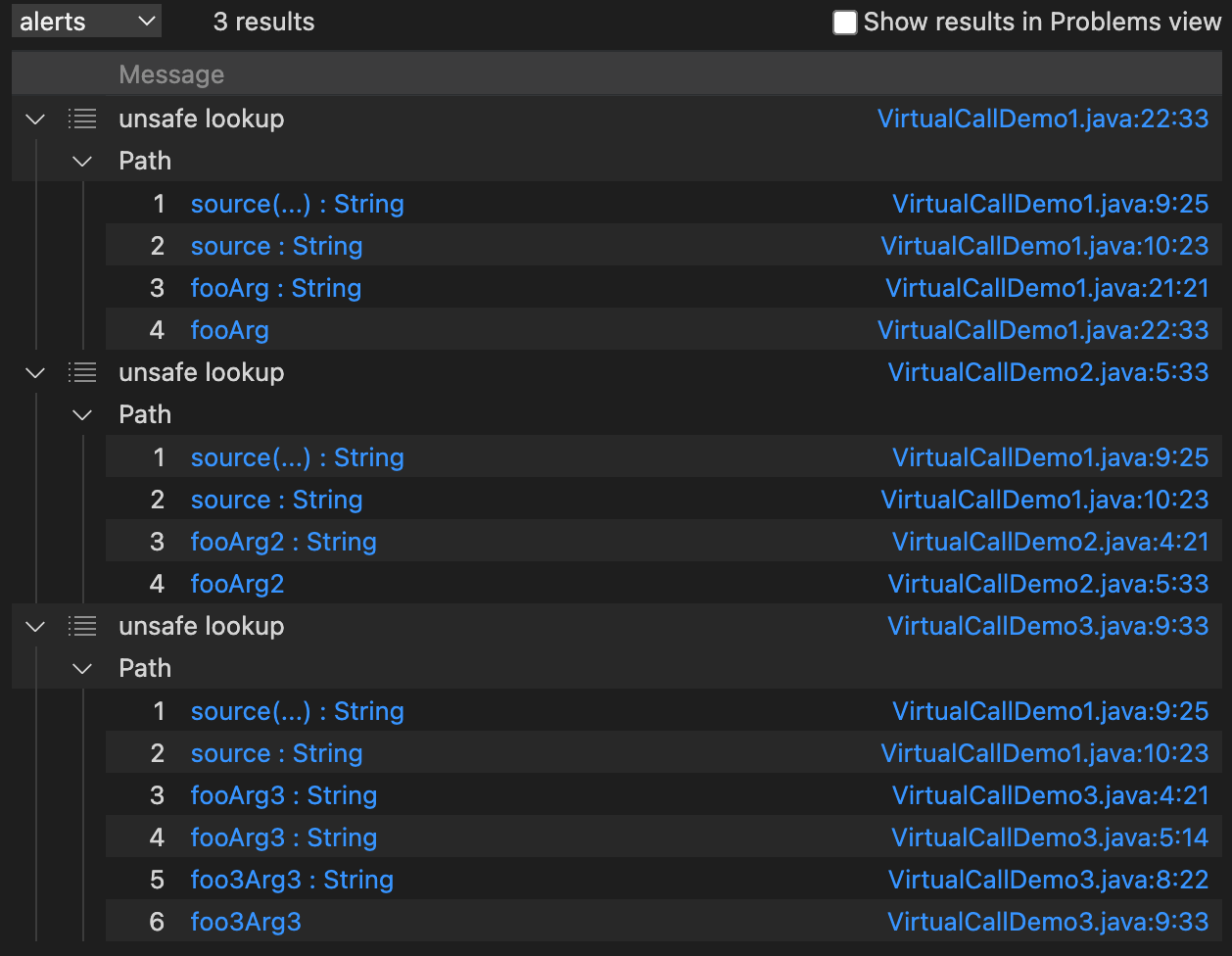
依旧存在两条误报,应该还是用polyCalls解析的虚拟函数调用,由于调用图不准确带来的污点传播不准确。
我首先尝试了这篇文章中的规则,没有结果查出结果(原因是生成代码的对应的commit不一样),在在线的数据库上可以查到结果,但是结果和作者查到的并不太一样,没有作者展示的113个节点的path。

然后就开始自己写一版
/**
*@name Tainttrack Context lookup
*@kind path-problem
*/
import java
import semmle.code.java.dataflow.TaintTracking
import DataFlow::PathGraph
class ErrorMethod extends Method {
ErrorMethod() {
getParameterType(0).hasName("String") and
getNumberOfParameters() = 1 and
getName() = "error" and
this.getDeclaringType().hasQualifiedName("org.apache.logging.log4j.spi", "AbstractLogger")
}
}
class LookupMethod extends Method {
LookupMethod() {
getName() = "lookup" and
this.getDeclaringType().getASupertype*().hasQualifiedName("javax.naming", "Context")
}
}
class TainttrackLookup extends TaintTracking::Configuration {
TainttrackLookup() {
this = "TainttrackLookup"
}
override predicate isSource(DataFlow::Node source) {
exists(ErrorMethod method |
source.asParameter() = method.getParameter(0))
}
override predicate isSink(DataFlow::Node sink) {
exists(Call call, LookupMethod method |
call.getCallee() = method
and
sink.asExpr() = call.getAnArgument()
)
}
}
from TainttrackLookup config , DataFlow::PathNode source, DataFlow::PathNode sink
where
config.hasFlowPath(source, sink)
select sink.getNode(), source, sink, "unsafe lookup", source.getNode(), "this is user input"
查不出结果
下面进行debug
首先看看isSource和isSink定义的准不准确,可以通过vscode的CodeQL插件的quick evulation功能查看
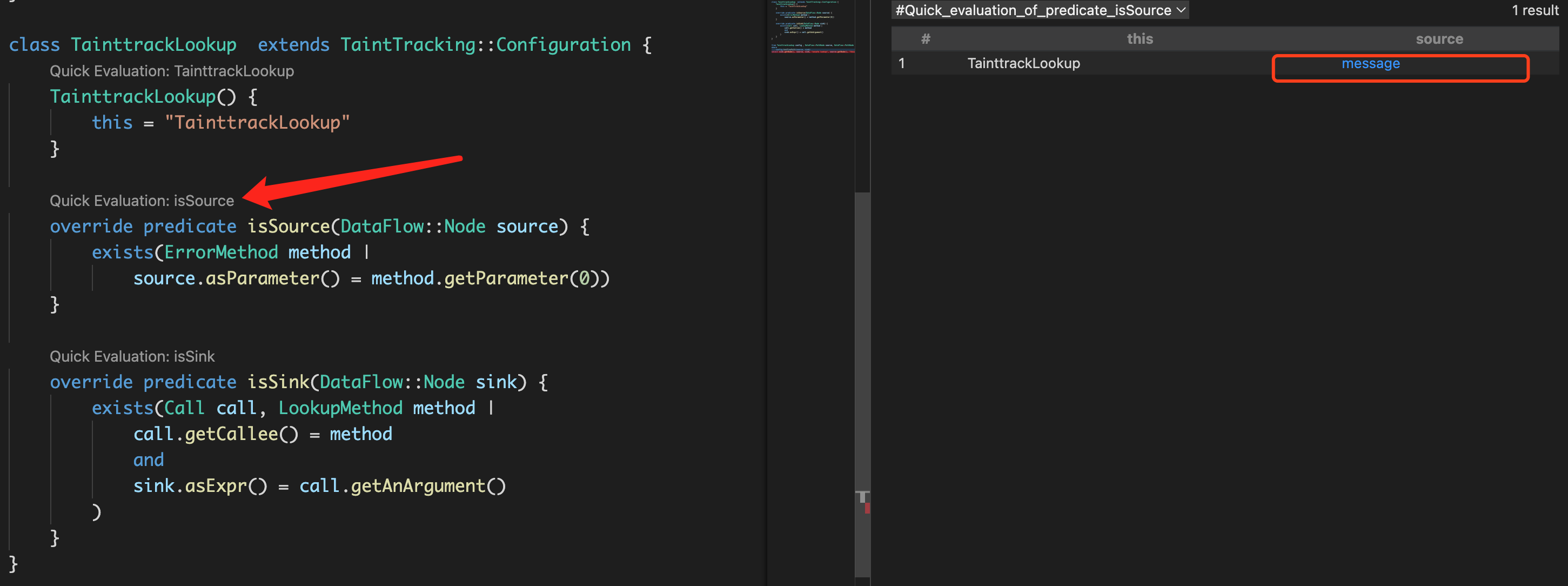
isSource和isSink定义都是准确的,不是这里的问题
然后猜测是污点传播中断的问题,如何判断断在哪里了?一种比较糙的方法就是把isSink设置为永远返回true,看source能够流到哪些node,
将isSink改成
override predicate isSink(DataFlow::Node sink) {
1 = 1
}
一共有88个result,一个个的查看也不是很好查看。这样也看不出来啥东西,反正我们是马后炮分析,根据调用栈进行二分法排查错误,看到底断在了哪步。
/**
*@name Tainttrack Context lookup
*@kind path-problem
*/
import java
import semmle.code.java.dataflow.TaintTracking
import DataFlow::PathGraph
class ErrorMethod extends Method {
ErrorMethod() {
getParameterType(0).hasName("String") and
getNumberOfParameters() = 1 and
getName() = "error" and
this.getDeclaringType().hasQualifiedName("org.apache.logging.log4j.spi", "AbstractLogger")
}
}
class LookupMethod extends Method {
LookupMethod() {
getName() = "lookup" and
this.getDeclaringType().getASupertype*().hasQualifiedName("javax.naming", "Context")
}
}
class LogMessageSafely extends Method {
LogMessageSafely() {
getName() = "logMessageSafely" and
this.getDeclaringType().hasQualifiedName("org.apache.logging.log4j.spi", "AbstractLogger")
}
}
class TainttrackLookup extends TaintTracking::Configuration {
TainttrackLookup() {
this = "TainttrackLookup"
}
override predicate isSource(DataFlow::Node source) {
exists(ErrorMethod method |
source.asParameter() = method.getParameter(0))
}
override predicate isSink(DataFlow::Node sink) {
exists(Call call, LogMessageSafely method |
call.getCallee() = method
and
sink.asExpr() = call.getAnArgument()
)
}
// override predicate isSink(DataFlow::Node sink) {
// 1 = 1
// }
}
from TainttrackLookup config , DataFlow::PathNode source, DataFlow::PathNode sink
where
config.hasFlowPath(source, sink)
select sink.getNode(), source, sink, "unsafe lookup", source.getNode(), "this is user input"
最终排查出可以到AbstractLogger#logMessage 但是到不了AbstractLogger#logMessageSafely
protected void logMessage(final String fqcn, final Level level, final Marker marker, final String message, final Throwable throwable) {
this.logMessageSafely(fqcn, level, marker, this.messageFactory.newMessage(message), throwable);
}
也就是说message被污染了,但是this.messageFactory.newMessage(message) 的返回值没有被污染,这不就是典型的参数是污点,返回值不是污点吗,加个isAdditionalTaintStep应该就行了,改善后的
/**
*@name Tainttrack Context lookup
*@kind path-problem
*/
import java
import semmle.code.java.dataflow.TaintTracking
import DataFlow::PathGraph
class ErrorMethod extends Method {
ErrorMethod() {
getParameterType(0).hasName("String") and
getNumberOfParameters() = 1 and
getName() = "error" and
this.getDeclaringType().hasQualifiedName("org.apache.logging.log4j.spi", "AbstractLogger")
}
}
class LookupMethod extends Method {
LookupMethod() {
getName() = "lookup" and
this.getDeclaringType().getASupertype*().hasQualifiedName("javax.naming", "Context")
}
}
class LogMessageSafely extends Method {
LogMessageSafely() {
getName() = "logMessageSafely" and
this.getDeclaringType().hasQualifiedName("org.apache.logging.log4j.spi", "AbstractLogger")
}
}
class TainttrackLookup extends TaintTracking::Configuration {
TainttrackLookup() {
this = "TainttrackLookup"
}
override predicate isSource(DataFlow::Node source) {
exists(ErrorMethod method |
source.asParameter() = method.getParameter(0))
}
override predicate isSink(DataFlow::Node sink) {
exists(Call call, LookupMethod method |
call.getCallee() = method
and
sink.asExpr() = call.getAnArgument()
)
}
override predicate isAdditionalTaintStep(DataFlow::Node fromNode, DataFlow::Node toNode) {
exists(Call call |
call.getAnArgument() = fromNode.asExpr() and
toNode.asExpr() = call
)
}
}
from TainttrackLookup config , DataFlow::PathNode source, DataFlow::PathNode sink
where
config.hasFlowPath(source, sink)
select sink.getNode(), source, sink, "unsafe lookup", source.getNode(), "this is user input"
可以查到还是没有和真实的调用堆栈并不一样。

为什么会出现这种情况呢?带着这个疑问去找了官方文档,发现了debugging-data-flow-queries-using-partial-flow 有官方的debug教程
里面的建议是
- 检查source和sink是否正确
- 将
fieldFlowBranchLimit的值设置大一点,这个值会影响性能 - partial flow
针对1已经检查过了没有问题,fieldFlowBranchLimit这个值到底是影响啥的?
Gets the virtual dispatch branching limit when calculating field flow. This can be overridden to a smaller value to improve performance (a value of 0 disables field flow), or a larger value to get more results.
不是很清楚field flow是个啥玩意,通过测试设置为5000,6000,8000,18000执行的结果都一样,速度也几乎一样
那么只剩partial flow了,根据上面的教程,可以改成
/**
*@name Tainttrack Context lookup
*@kind path-problem
*/
import java
import semmle.code.java.dataflow.TaintTracking
// import DataFlow::PathGraph
import DataFlow::PartialPathGraph
class ErrorMethod extends Method {
ErrorMethod() {
getParameterType(0).hasName("String") and
getNumberOfParameters() = 1 and
getName() = "error" and
this.getDeclaringType().hasQualifiedName("org.apache.logging.log4j.spi", "AbstractLogger")
}
}
class LookupMethod extends Method {
LookupMethod() {
getName() = "lookup" and
this.getDeclaringType().getASupertype*().hasQualifiedName("javax.naming", "Context")
}
}
class LogMessageSafely extends Method {
LogMessageSafely() {
getName() = "logMessageSafely" and
this.getDeclaringType().hasQualifiedName("org.apache.logging.log4j.spi", "AbstractLogger")
}
}
class TainttrackLookup extends TaintTracking::Configuration {
TainttrackLookup() {
this = "TainttrackLookup"
}
override predicate isSource(DataFlow::Node source) {
exists(ErrorMethod method |
source.asParameter() = method.getParameter(0))
}
override predicate isSink(DataFlow::Node sink) {
exists(Call call, LookupMethod method |
call.getCallee() = method
and
sink.asExpr() = call.getAnArgument()
)
}
override int explorationLimit() { result = 2 }
// override predicate isAdditionalTaintStep(DataFlow::Node fromNode, DataFlow::Node toNode) {
// exists(Call call |
// call.getAnArgument() = fromNode.asExpr() and
// toNode.asExpr() = call
// )
// }
// override int fieldFlowBranchLimit() { result = 18000 }
}
// from TainttrackLookup config , DataFlow::PathNode source, DataFlow::PathNode sink
// where
// config.hasFlowPath(source, sink)
// select sink.getNode(), source, sink, "unsafe lookup", source.getNode(), "this is user input"
from TainttrackLookup config , DataFlow::PartialPathNode source, DataFlow::PartialPathNode sink
where
config.hasPartialFlow(source, sink, _)
select sink, source, sink, "Partial flow from unsanitized user data"
explorationLimit参数的含义为
Gets the exploration limit for
hasPartialFlowandhasPartialFlowRevmeasured in approximate number of interprocedural steps.
还是看不懂,这个参数是通过影响啥,改变了性能及结果,这个参数只在partial flow中有用,在正常的污点分析中没有用。
explorationLimit限制了从source节点所在函数开始最多在往下调用函数的数量,和ByteCodeDL限制调用步数时一个道理。
当explorationLimit为0时,只能在source所在的函数内传播,也就是error方法中传播

当explorationLimit为1时,可以传播到logIfEnabled

当explorationLimit设置为2时有13个result,可以传播到isEnabled和logMessage中

设置为3时有34个result,设置为4时1819个result,设置为5时就跑不出结果来了
当设置为4时,我们发现了
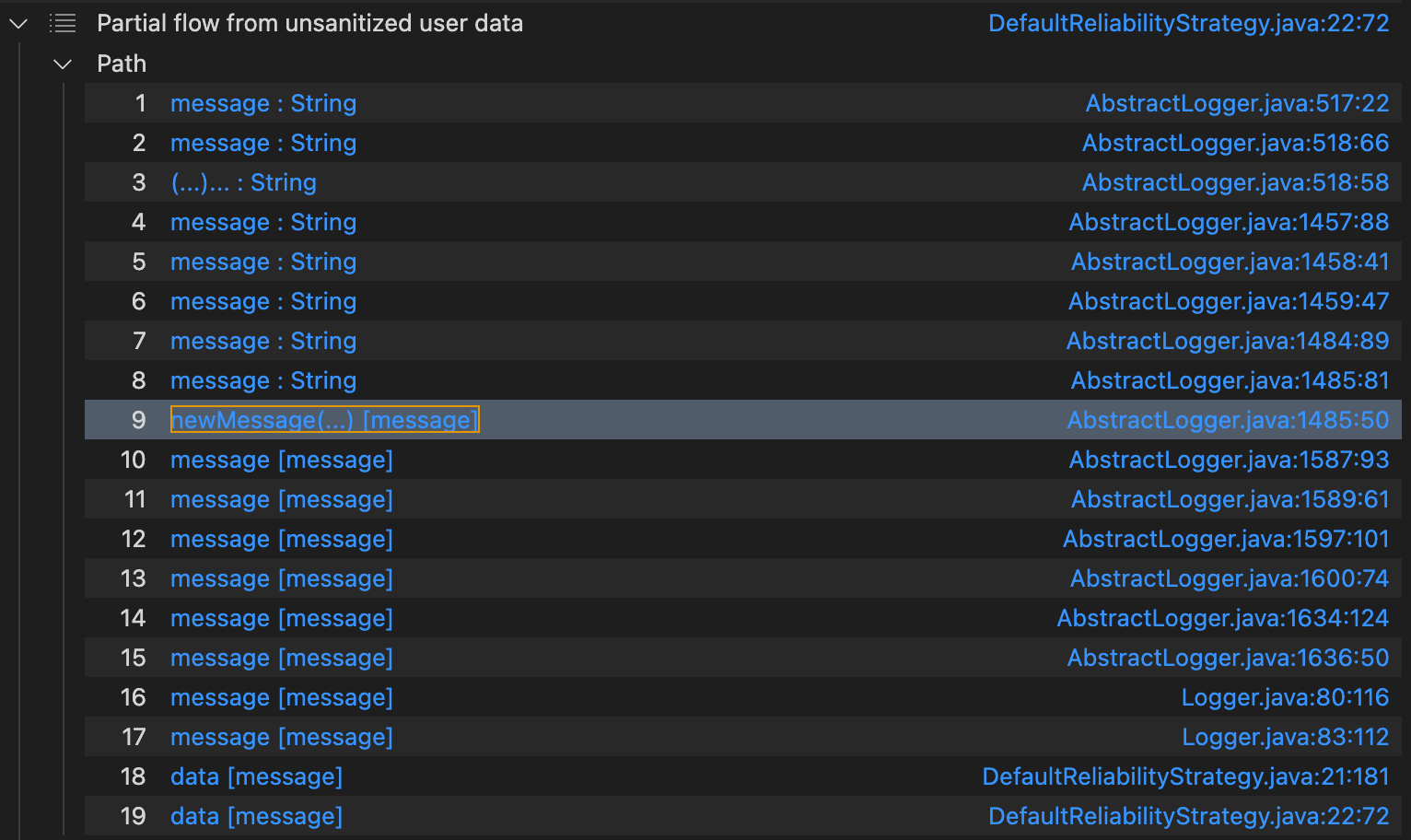
是可以从error的参数传播到logMessageSafely参数,甚至可以传播到DefaultReliabilityStrategy#log,那为啥污点分析不行呢?迷惑!
0x05 总结
-
CodeQL默认的规则应该检测不出log4shell漏洞,通过自定义CodeQL规则不能完全准确的检测出log4shell实际的污点传播路径。
-
通过extractor-java可以在反编译jar包之后,无需再次编译即可创建CodeQL database,也就是说CodeQL对于java也可以像脚本语言那样有源码就可以数据库,不需要编译。
-
基于这两篇文章creating-path-queries和Issue ,可以在vscode的侧边栏显示调用路径,注意最后的sink需要存在源码
-
从黑盒的表现来看,CodeQL使用了CHA算法解析虚拟函数调用
-
基于这篇debugging-data-flow-queries-using-partial-flow 可以通过partial flow进行数据流debug
CodeQL虽然很强大,但是分析log4j2这样的大型项目时,还是存在很多漏报和误报,即便如此CodeQL的分析结果可以给我们一些参考的信息,或者灵感来辅助我们挖洞。
0x06 参考
- https://github.com/waderwu/extractor-java
- https://codeql.github.com/docs/writing-codeql-queries/debugging-data-flow-queries-using-partial-flow/
- https://codeql.github.com/docs/writing-codeql-queries/creating-path-queries/
- https://github.com/github/codeql/discussions/5353
- https://xz.aliyun.com/t/10707


