浅谈pyd相关逆向
.pyd 文件本质上是一个包含 Python 代码的库文件,可以被其他 Python 应用程序调用和使用。 通过使用Cython编译器,可以快速得把python文件打包为一个动态链接库,这个动态链接库也就是pyd。pyd相较于python源码本身可读性大大下降,很多人处于类似混淆得目的,也会使用这种形式对python代码进行保护
再过去的比赛中,其实经常会遇到pyd相关的题目,但是之前做起来的时候基本上要么不需要逆向,要么最后使用测信道的方式得到了flag。而国赛期间出了一个需要切切实实逆向pyd的题目,于是借助这个题目,对pyd得整体进行一个快速学习,同时记录一些pyd对应得逆。
pyd基本介绍
环境准备
首先我们编写一个脚本test_for_pyd.py:
def test_hello(a):
test = 2
result = test + 2
t = 4
print(a)
print(test, result, t)
def int(string):
table = "8ed4bc0123a567f9"
v7 = 0
index = 0
num = 0
string = reversed(string)
for each in string:
num *= 16
index = table.find(each)
num += index
return num
if __name__ == "__main__":
test_hello("hello")
print(int("123"))
脚本中用了尽可能多的元素,这样一会儿可以更好的介绍。
之后编写编译脚本setup.py
from setuptools import setup
from Cython.Build import cythonize
setup(
name="test_for_pyd",
ext_modules=cythonize('test_for_pyd.py')
)
两者放在同级目录下之后,输入
python .\setup.py build_ext --inplace
即可生成相关源码test_for_pyd.c,以及对应的test_for_pyd.cp36-win_amd64.pyd
变量分析
整个pyd文件非常长,但是其实都是为了python这种动态运行语言进行的准备。其中我们有几个需要注意的点:
首先是变量区,变量去分为变量名区和变量定义区。变量名区域如下
/* Implementation of 'test_for_pyd' */
static PyObject *__pyx_builtin_reversed;
static const char __pyx_k_a[] = "a";
static const char __pyx_k_t[] = "t";
static const char __pyx_k_v7[] = "v7";
static const char __pyx_k_123[] = "123";
static const char __pyx_k_end[] = "end";
static const char __pyx_k_int[] = "int";
static const char __pyx_k_num[] = "num";
static const char __pyx_k_each[] = "each";
static const char __pyx_k_file[] = "file";
static const char __pyx_k_find[] = "find";
static const char __pyx_k_main[] = "__main__";
static const char __pyx_k_name[] = "__name__";
static const char __pyx_k_test[] = "test";
static const char __pyx_k_hello[] = "hello";
static const char __pyx_k_index[] = "index";
static const char __pyx_k_print[] = "print";
static const char __pyx_k_table[] = "table";
static const char __pyx_k_result[] = "result";
static const char __pyx_k_string[] = "string";
static const char __pyx_k_test_2[] = "__test__";
static const char __pyx_k_reversed[] = "reversed";
static const char __pyx_k_test_hello[] = "test_hello";
static const char __pyx_k_test_for_pyd[] = "test_for_pyd";
static const char __pyx_k_test_for_pyd_py[] = "test_for_pyd.py";
static const char __pyx_k_8ed4bc0123a567f9[] = "8ed4bc0123a567f9";
static const char __pyx_k_cline_in_traceback[] = "cline_in_traceback";
可以看到,开始的__pyx_k_即为我们在代码中使用的所有变量,甚至于包含某些可能只作为传参or中间变量的值。毕竟Python是解释性语言,所以回尽可能的保留多的运行过程中的信息。其中
static const char __pyx_k_test_hello[] = "test_hello";
static const char __pyx_k_test_for_pyd[] = "test_for_pyd";
static const char __pyx_k_test_for_pyd_py[] = "test_for_pyd.py";
static const char __pyx_k_cline_in_traceback[] = "cline_in_traceback";
这几个为描述当前模块以及相关的调试信息符号。再这之后就是实际的变量定义区域
static PyObject *__pyx_kp_s_123;
static PyObject *__pyx_kp_s_8ed4bc0123a567f9;
static PyObject *__pyx_n_s_a;
static PyObject *__pyx_n_s_cline_in_traceback;
static PyObject *__pyx_n_s_each;
static PyObject *__pyx_n_s_end;
static PyObject *__pyx_n_s_file;
static PyObject *__pyx_n_s_find;
static PyObject *__pyx_n_s_hello;
static PyObject *__pyx_n_s_index;
static PyObject *__pyx_n_s_int;
static PyObject *__pyx_n_s_main;
static PyObject *__pyx_n_s_name;
static PyObject *__pyx_n_s_num;
static PyObject *__pyx_n_s_print;
static PyObject *__pyx_n_s_result;
static PyObject *__pyx_n_s_reversed;
static PyObject *__pyx_n_s_string;
static PyObject *__pyx_n_s_t;
static PyObject *__pyx_n_s_table;
static PyObject *__pyx_n_s_test;
static PyObject *__pyx_n_s_test_2;
static PyObject *__pyx_n_s_test_for_pyd;
static PyObject *__pyx_kp_s_test_for_pyd_py;
static PyObject *__pyx_n_s_test_hello;
static PyObject *__pyx_n_s_v7;
static PyObject *__pyx_pf_12test_for_pyd_test_hello(CYTHON_UNUSED PyObject *__pyx_self, PyObject *__pyx_v_a); /* proto */
static PyObject *__pyx_pf_12test_for_pyd_2int(CYTHON_UNUSED PyObject *__pyx_self, PyObject *__pyx_v_string); /* proto */
static PyObject *__pyx_int_0;
static PyObject *__pyx_int_2;
static PyObject *__pyx_int_16;
static PyObject *__pyx_tuple_;
static PyObject *__pyx_tuple__3;
static PyObject *__pyx_tuple__5;
static PyObject *__pyx_tuple__6;
static PyObject *__pyx_codeobj__2;
static PyObject *__pyx_codeobj__4;
可以看到,除了字符串描述之外,Python还会使用一个PyObject*来描述一个与他名字相同的全局变量。这个变量定义在Python目录下的object.h中
/* Define pointers to support a doubly-linked list of all live heap objects. */
#define _PyObject_HEAD_EXTRA \
struct _object *_ob_next; \
struct _object *_ob_prev;
/* Nothing is actually declared to be a PyObject, but every pointer to
* a Python object can be cast to a PyObject*. This is inheritance built
* by hand. Similarly every pointer to a variable-size Python object can,
* in addition, be cast to PyVarObject*.
*/
typedef struct _object {
_PyObject_HEAD_EXTRA
Py_ssize_t ob_refcnt;
struct _typeobject *ob_type;
} PyObject;
可以看到,其描述非常类似于Python文档中给出的对Python对象的定义:
- 每一个对象都有引用计数
ob_refcnt,当引用计数归0后销毁对象 - 使用链表将多个对象进行关联
- 有一个描述对象的具体类型的
struct _typeobject
这里进行一个简单的Python知识科普:在Python中,即使是数字也是一个对象。这也就意味着,如果在我们的代码中显式的写了某个数字,并且这个数字不仅仅用于赋值,那这个数字就会被作为一个对象存储。
例如我们Python代码中,函数中写到了
def test_hello(a):
test = 2
result = test + 2
t = 4
# pass some code
def int(string):
num = 0
# pass some code
for each in string:
# pass some code
num *= 16
return num
可以看到,上述总共出现了0,2,4,16三个数字,其中2,16分别在表达式中出现,0赋值的num对象也被用于了表达式,于是在我们生成的pyd文件中,就有了如下的定义:
static PyObject *__pyx_int_0;
static PyObject *__pyx_int_2;
static PyObject *__pyx_int_16;
而4这个数字仅仅作为了赋值语句,所以没有生成数字对象。这些对象最终会在一个全局表中进行关联:
static __Pyx_StringTabEntry __pyx_string_tab[] = {
{&__pyx_kp_s_123, __pyx_k_123, sizeof(__pyx_k_123), 0, 0, 1, 0},
{&__pyx_kp_s_8ed4bc0123a567f9, __pyx_k_8ed4bc0123a567f9, sizeof(__pyx_k_8ed4bc0123a567f9), 0, 0, 1, 0},
{&__pyx_n_s_TestObject, __pyx_k_TestObject, sizeof(__pyx_k_TestObject), 0, 0, 1, 1},
{&__pyx_n_s_TestObject_Testprint, __pyx_k_TestObject_Testprint, sizeof(__pyx_k_TestObject_Testprint), 0, 0, 1, 1},
{&__pyx_n_s_TestObject___init, __pyx_k_TestObject___init, sizeof(__pyx_k_TestObject___init), 0, 0, 1, 1},
{&__pyx_n_s_Testprint, __pyx_k_Testprint, sizeof(__pyx_k_Testprint), 0, 0, 1, 1},
{&__pyx_n_s_a, __pyx_k_a, sizeof(__pyx_k_a), 0, 0, 1, 1},
{&__pyx_n_s_cline_in_traceback, __pyx_k_cline_in_traceback, sizeof(__pyx_k_cline_in_traceback), 0, 0, 1, 1},
{&__pyx_n_s_doc, __pyx_k_doc, sizeof(__pyx_k_doc), 0, 0, 1, 1},
{&__pyx_n_s_each, __pyx_k_each, sizeof(__pyx_k_each), 0, 0, 1, 1},
{&__pyx_n_s_end, __pyx_k_end, sizeof(__pyx_k_end), 0, 0, 1, 1},
{&__pyx_n_s_file, __pyx_k_file, sizeof(__pyx_k_file), 0, 0, 1, 1},
{&__pyx_n_s_find, __pyx_k_find, sizeof(__pyx_k_find), 0, 0, 1, 1},
{&__pyx_n_s_hello, __pyx_k_hello, sizeof(__pyx_k_hello), 0, 0, 1, 1},
{&__pyx_n_s_index, __pyx_k_index, sizeof(__pyx_k_index), 0, 0, 1, 1},
{&__pyx_n_s_init, __pyx_k_init, sizeof(__pyx_k_init), 0, 0, 1, 1},
{&__pyx_n_s_int, __pyx_k_int, sizeof(__pyx_k_int), 0, 0, 1, 1},
{&__pyx_n_s_main, __pyx_k_main, sizeof(__pyx_k_main), 0, 0, 1, 1},
{&__pyx_n_s_metaclass, __pyx_k_metaclass, sizeof(__pyx_k_metaclass), 0, 0, 1, 1},
{&__pyx_n_s_module, __pyx_k_module, sizeof(__pyx_k_module), 0, 0, 1, 1},
{&__pyx_n_s_name, __pyx_k_name, sizeof(__pyx_k_name), 0, 0, 1, 1},
{&__pyx_n_s_num, __pyx_k_num, sizeof(__pyx_k_num), 0, 0, 1, 1},
{&__pyx_n_s_object, __pyx_k_object, sizeof(__pyx_k_object), 0, 0, 1, 1},
{&__pyx_n_s_prepare, __pyx_k_prepare, sizeof(__pyx_k_prepare), 0, 0, 1, 1},
{&__pyx_n_s_print, __pyx_k_print, sizeof(__pyx_k_print), 0, 0, 1, 1},
{&__pyx_n_s_qualname, __pyx_k_qualname, sizeof(__pyx_k_qualname), 0, 0, 1, 1},
{&__pyx_n_s_result, __pyx_k_result, sizeof(__pyx_k_result), 0, 0, 1, 1},
{&__pyx_n_s_reversed, __pyx_k_reversed, sizeof(__pyx_k_reversed), 0, 0, 1, 1},
{&__pyx_n_s_self, __pyx_k_self, sizeof(__pyx_k_self), 0, 0, 1, 1},
{&__pyx_n_s_string, __pyx_k_string, sizeof(__pyx_k_string), 0, 0, 1, 1},
{&__pyx_n_s_t, __pyx_k_t, sizeof(__pyx_k_t), 0, 0, 1, 1},
{&__pyx_n_s_table, __pyx_k_table, sizeof(__pyx_k_table), 0, 0, 1, 1},
{&__pyx_n_s_test, __pyx_k_test, sizeof(__pyx_k_test), 0, 0, 1, 1},
{&__pyx_n_s_test_2, __pyx_k_test_2, sizeof(__pyx_k_test_2), 0, 0, 1, 1},
{&__pyx_n_s_test_for_pyd, __pyx_k_test_for_pyd, sizeof(__pyx_k_test_for_pyd), 0, 0, 1, 1},
{&__pyx_kp_s_test_for_pyd_py, __pyx_k_test_for_pyd_py, sizeof(__pyx_k_test_for_pyd_py), 0, 0, 1, 0},
{&__pyx_n_s_test_hello, __pyx_k_test_hello, sizeof(__pyx_k_test_hello), 0, 0, 1, 1},
{&__pyx_n_s_v7, __pyx_k_v7, sizeof(__pyx_k_v7), 0, 0, 1, 1},
{0, 0, 0, 0, 0, 0, 0}
};
在进行实际的逆向工作的时候,找到这个表的位置就非常重要。通过表格我们能够还原出大部分的符号信息。而前文讨论过的数字,则会在某个全局函数中被初始化
static CYTHON_SMALL_CODE int __Pyx_InitGlobals(void) {
if (__Pyx_InitStrings(__pyx_string_tab) < 0) __PYX_ERR(0, 1, __pyx_L1_error);
__pyx_int_0 = PyInt_FromLong(0); if (unlikely(!__pyx_int_0)) __PYX_ERR(0, 1, __pyx_L1_error)
__pyx_int_2 = PyInt_FromLong(2); if (unlikely(!__pyx_int_2)) __PYX_ERR(0, 1, __pyx_L1_error)
__pyx_int_16 = PyInt_FromLong(16); if (unlikely(!__pyx_int_16)) __PYX_ERR(0, 1, __pyx_L1_error)
return 0;
__pyx_L1_error:;
return -1;
}
此函数也能帮助对存在文件中的整数对象的结果进行分析。
函数分析
在pyd中,不同类型的函数有不同的实现形式。这边为了更好的区分函数,新增一个类,观察不同的函数类型的不同:
class TestObject(object):
def __init__(self):
self.a = 0
def Testprint(self):
print(self.a)
翻译后,在变量区也能看到这几个函数
static const char __pyx_k_TestObject[] = "TestObject";
static const char __pyx_k_TestObject___init[] = "TestObject.__init__";
static const char __pyx_k_TestObject_Testprint[] = "TestObject.Testprint";
static PyObject *__pyx_n_s_TestObject;
static PyObject *__pyx_n_s_TestObject_Testprint;
static PyObject *__pyx_n_s_TestObject___init;
然后在变量区之后,就能看到函数区域
static PyObject *__pyx_pf_12test_for_pyd_10TestObject___init__(CYTHON_UNUSED PyObject *__pyx_self, PyObject *__pyx_v_self); /* proto */
static PyObject *__pyx_pf_12test_for_pyd_10TestObject_2Testprint(CYTHON_UNUSED PyObject *__pyx_self, PyObject *__pyx_v_self); /* proto */
static PyObject *__pyx_pf_12test_for_pyd_test_hello(CYTHON_UNUSED PyObject *__pyx_self, PyObject *__pyx_v_a); /* proto */
static PyObject *__pyx_pf_12test_for_pyd_2int(CYTHON_UNUSED PyObject *__pyx_self, PyObject *__pyx_v_string); /* proto */
可以看到,所有以__pyx_pf开头的变量本质上都是Python中函数的定义。我们以最基本的test_hello为例进行分析:
def test_hello(a, b):
test = 2
result = test + 2
t = 4
print(a,b)
print(test, result, t)
首先这个函数会在Python中被声明成如下的函数:
/* "test_for_pyd.py":9
* print(self.a)
*
* def test_hello(a): # <<<<<<<<<<<<<<
* test = 2
* result = test + 2
*/
/* Python wrapper */
static PyObject *__pyx_pw_12test_for_pyd_1test_hello(PyObject *__pyx_self, PyObject *__pyx_v_a); /*proto*/
static PyMethodDef __pyx_mdef_12test_for_pyd_1test_hello = {"test_hello", (PyCFunction)__pyx_pw_12test_for_pyd_1test_hello, METH_O, 0};
static PyObject *__pyx_pw_12test_for_pyd_1test_hello(PyObject *__pyx_self, PyObject *__pyx_v_a) {
PyObject *__pyx_r = 0;
__Pyx_RefNannyDeclarations
__Pyx_RefNannySetupContext("test_hello (wrapper)", 0);
__pyx_r = __pyx_pf_12test_for_pyd_test_hello(__pyx_self, ((PyObject *)__pyx_v_a));
/* function exit code */
__Pyx_RefNannyFinishContext();
return __pyx_r;
}
test_hello函数并不会被直接调用,而是会先定义一个proto(原型):
static PyObject *__pyx_pw_12test_for_pyd_1test_hello(PyObject *__pyx_self, PyObject *__pyx_v_a); /*proto*/
这个函数声明了函数的调用模式,其中第一个参数是__pyx_self,其实就是描述python这个运行的对象(相当于C++中的self指针)。然后第二个参数表述了当先引用的参数。如果参数超过一个的时候,例如
def test_hello(a, b):
test = 2
result = test + 2
t = 4
print(a,b)
print(test, result, t)
此时的C语言形式会变成如下
static PyObject *__pyx_pw_12test_for_pyd_1test_hello(PyObject *__pyx_self, PyObject *__pyx_args, PyObject *__pyx_kwds); /*proto*/
这种参数就是Python中一种比较常见的def func(*args, **kwds),表示传进来的参数可以同时支持list和dict两种形式。然后他会进行如下的定义
static PyMethodDef __pyx_mdef_12test_for_pyd_1test_hello =
{
"test_hello",
(PyCFunction)__pyx_pw_12test_for_pyd_1test_hello,
METH_O,
0
};
这个地方会定义这个函数与python中的字符串,以及函数对应属性。这个结构体的相关的定义如下:
struct PyMethodDef {
const char *ml_name; /* The name of the built-in function/method */
PyCFunction ml_meth; /* The C function that implements it */
int ml_flags; /* Combination of METH_xxx flags, which mostly
describe the args expected by the C func */
const char *ml_doc; /* The __doc__ attribute, or NULL */
};
里面会描述函数的名字以及对应的C实现。再逆向过程中,可以通过这个表找到当前代码中实现的相关函数。然后会是这个wrapper函数的实现:
static PyObject *__pyx_pw_12test_for_pyd_1test_hello(PyObject *__pyx_self, PyObject *__pyx_args, PyObject *__pyx_kwds) {
PyObject *__pyx_v_a = 0;
PyObject *__pyx_v_b = 0;
int __pyx_lineno = 0;
const char *__pyx_filename = NULL;
int __pyx_clineno = 0;
PyObject *__pyx_r = 0;
__Pyx_RefNannyDeclarations
__Pyx_RefNannySetupContext("test_hello (wrapper)", 0);
{
static PyObject **__pyx_pyargnames[] = {&__pyx_n_s_a,&__pyx_n_s_b,0};
PyObject* values[2] = {0,0};
if (unlikely(__pyx_kwds)) {
Py_ssize_t kw_args;
const Py_ssize_t pos_args = PyTuple_GET_SIZE(__pyx_args);
switch (pos_args) {
case 2: values[1] = PyTuple_GET_ITEM(__pyx_args, 1);
CYTHON_FALLTHROUGH;
case 1: values[0] = PyTuple_GET_ITEM(__pyx_args, 0);
CYTHON_FALLTHROUGH;
case 0: break;
default: goto __pyx_L5_argtuple_error;
}
kw_args = PyDict_Size(__pyx_kwds);
switch (pos_args) {
case 0:
if (likely((values[0] = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_a)) != 0)) kw_args--;
else goto __pyx_L5_argtuple_error;
CYTHON_FALLTHROUGH;
case 1:
if (likely((values[1] = __Pyx_PyDict_GetItemStr(__pyx_kwds, __pyx_n_s_b)) != 0)) kw_args--;
else {
__Pyx_RaiseArgtupleInvalid("test_hello", 1, 2, 2, 1); __PYX_ERR(0, 9, __pyx_L3_error)
}
}
if (unlikely(kw_args > 0)) {
if (unlikely(__Pyx_ParseOptionalKeywords(__pyx_kwds, __pyx_pyargnames, 0, values, pos_args, "test_hello") < 0)) __PYX_ERR(0, 9, __pyx_L3_error)
}
} else if (PyTuple_GET_SIZE(__pyx_args) != 2) {
goto __pyx_L5_argtuple_error;
} else {
values[0] = PyTuple_GET_ITEM(__pyx_args, 0);
values[1] = PyTuple_GET_ITEM(__pyx_args, 1);
}
__pyx_v_a = values[0];
__pyx_v_b = values[1];
}
goto __pyx_L4_argument_unpacking_done;
__pyx_L5_argtuple_error:;
__Pyx_RaiseArgtupleInvalid("test_hello", 1, 2, 2, PyTuple_GET_SIZE(__pyx_args)); __PYX_ERR(0, 9, __pyx_L3_error)
__pyx_L3_error:;
__Pyx_AddTraceback("test_for_pyd.test_hello", __pyx_clineno, __pyx_lineno, __pyx_filename);
__Pyx_RefNannyFinishContext();
return NULL;
__pyx_L4_argument_unpacking_done:;
__pyx_r = __pyx_pf_12test_for_pyd_test_hello(__pyx_self, __pyx_v_a, __pyx_v_b);
/* function exit code */
__Pyx_RefNannyFinishContext();
return __pyx_r;
}
函数很长,但是仔细看下来的话会发现其实就是在处理传参和函数的一些准备工作,基本上只是再做如下的几个事情:
- 定义了真正调用时候传入的参数
__pyx_n_s_a和__pyx_n_s_b,也就是真正的test_hello(a,b)中的两个参数 - 如果存在
__pyx_kwds,此时尝试优先去__pyx_args取出两个变量,赋值给__pyx_n_s_a和__pyx_n_s_b,否则使用dict的形式,赋值给对应的__pyx_n_s_a和__pyx_n_s_b变量中。 - 如果不存在
__pyx_kwds,尝试从__pyx_args中从取出前两个变量,赋值给__pyx_n_s_a和__pyx_n_s_b - 最后调用真正的主要函数
完成传参数之后,进入主要函数。为了方便,我们这边逐Python语句的进行翻译:
static PyObject *__pyx_pf_12test_for_pyd_test_hello(CYTHON_UNUSED PyObject *__pyx_self, PyObject *__pyx_v_a, PyObject *__pyx_v_b) {
/* "test_for_pyd.py":10
*
* def test_hello(a, b):
* test = 2 # <<<<<<<<<<<<<<
* result = test + 2
* t = 4
*/
__Pyx_INCREF(__pyx_int_2);
__pyx_v_test = __pyx_int_2;
首先我们增加__pyx_int_2对象的引用计数,表示此处用了这个数字。,然后将这个对象赋值给__pyx_v_test,也就是python中定义的test对象。
/* "test_for_pyd.py":11
* def test_hello(a, b):
* test = 2
* result = test + 2 # <<<<<<<<<<<<<<
* t = 4
* print(a,b)
*/
__pyx_t_1 = __Pyx_PyInt_AddObjC(__pyx_v_test, __pyx_int_2, 2, 0, 0); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 11, __pyx_L1_error)
__Pyx_GOTREF(__pyx_t_1);
__pyx_v_result = __pyx_t_1;
__pyx_t_1 = 0;
然后我们通过使用方法__Pyx_PyInt_AddObjC进行整数对象的相加。整数对象再内存中的存储形式为
typedef struct{
PyObject_HEAD
long ob_ival;
}PyIntObject
可以得知,这个对象中会描述当前存放的整数的值,以及相关的一些对象数据。整数的初始化过程可以参考这个文章。这里只要记得,Python运算中被明确使用的数字,都会被显示的存放在一个对象中即可。完成加法后,其增加了一个临时的引用对象__pyx_t_1的引用计数,然后将答案赋值给了__pyx_v_result,之后将这个值重新值为了0,相当于完成了result = test + 2这个流程。
/* "test_for_pyd.py":12
* test = 2
* result = test + 2
* t = 4 # <<<<<<<<<<<<<<
* print(a,b)
* print(test, result, t)
*/
__pyx_v_t = 4;
之后对__pyx_v_t变量进行赋值。可以看到由于t变量再我们的Python代码中不存在任何运算过程,于是他是直接被赋值了一个数字,而并非是一个整数对象。
/* "test_for_pyd.py":13
* result = test + 2
* t = 4
* print(a,b) # <<<<<<<<<<<<<<
* print(test, result, t)
*
*/
__pyx_t_1 = PyTuple_New(2); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 13, __pyx_L1_error)
__Pyx_GOTREF(__pyx_t_1);
__Pyx_INCREF(__pyx_v_a);
__Pyx_GIVEREF(__pyx_v_a);
PyTuple_SET_ITEM(__pyx_t_1, 0, __pyx_v_a);
__Pyx_INCREF(__pyx_v_b);
__Pyx_GIVEREF(__pyx_v_b);
PyTuple_SET_ITEM(__pyx_t_1, 1, __pyx_v_b);
if (__Pyx_PrintOne(0, __pyx_t_1) < 0) __PYX_ERR(0, 13, __pyx_L1_error)
__Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
再调用print之前,Python会先临时的创建一个tuple,我们要传入的参数设置在tuple之中。其流程为
- 首先增加变量
__pyx_v_的引用计数 - 表示对齐进行引用
- 调用
PyTuple_SET_ITEM设置其在tuple对象中的下标
完成设置之后,通过将tuple对象作为整体,传入__Pyx_PrintOne这个函数中,实现调用。
稍微复杂的函数处理流程
看完了上述的简单调用,我们来看一下稍微复杂的函数调用:
def int(string):
table = "8ed4bc0123a567f9"
v7 = 0
index = 0
num = 0
string = reversed(string)
for each in string:
num *= 16
index = table.find(each)
num += index
return num
本质上程序也没有太多新增的内容,不过在这个函数中存在一些内置的函数(reserverd)以及常见的迭代对象的使用。我们直接观察新增内容:
/* "test_for_pyd.py":21
* index = 0
* num = 0
* string = reversed(string) # <<<<<<<<<<<<<<
* for each in string:
* num *= 16
*/
__pyx_t_1 = __Pyx_PyObject_CallOneArg(__pyx_builtin_reversed, __pyx_v_string); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 21, __pyx_L1_error)
__Pyx_GOTREF(__pyx_t_1);
__Pyx_DECREF_SET(__pyx_v_string, __pyx_t_1);
__pyx_t_1 = 0;
这里有一个调用内置函数的过程。内置函数__pyx_builtin_reversed对应的符号其实在上文也有过定义:
{&__pyx_n_s_reversed, __pyx_k_reversed, sizeof(__pyx_k_reversed), 0, 0, 1, 1},
static CYTHON_SMALL_CODE int __Pyx_InitCachedBuiltins(void) {
__pyx_builtin_object = __Pyx_GetBuiltinName(__pyx_n_s_object); if (!__pyx_builtin_object) __PYX_ERR(0, 1, __pyx_L1_error)
__pyx_builtin_reversed = __Pyx_GetBuiltinName(__pyx_n_s_reversed); if (!__pyx_builtin_reversed) __PYX_ERR(0, 21, __pyx_L1_error)
return 0;
__pyx_L1_error:;
return -1;
}
再全局初始化函数__Pyx_InitCachedBuiltins后,这个变量正式被赋值。这种函数通过__Pyx_PyObject_Call*系列函数进行封装后调用。其特征为第一个参数为函数全局对象,后方的内容为参数。在这之后会增加对于返回值的引用计数。注意这边虽然我们对变量起名叫做string,但是这个对象没有进行全局赋值,因为这个变量是一个临时变量,其被赋值为了一个贯穿了整个Python调用过程的临时对象__pyx_t_1中。
/* "test_for_pyd.py":22
* num = 0
* string = reversed(string)
* for each in string: # <<<<<<<<<<<<<<
* num *= 16
* index = table.find(each)
*/
if (likely(PyList_CheckExact(__pyx_v_string)) || PyTuple_CheckExact(__pyx_v_string)) {
__pyx_t_1 = __pyx_v_string; __Pyx_INCREF(__pyx_t_1); __pyx_t_2 = 0;
__pyx_t_3 = NULL;
} else {
__pyx_t_2 = -1; __pyx_t_1 = PyObject_GetIter(__pyx_v_string); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 22, __pyx_L1_error)
__Pyx_GOTREF(__pyx_t_1);
__pyx_t_3 = Py_TYPE(__pyx_t_1)->tp_iternext; if (unlikely(!__pyx_t_3)) __PYX_ERR(0, 22, __pyx_L1_error)
}
for (;;) {
if (likely(!__pyx_t_3)) {
if (likely(PyList_CheckExact(__pyx_t_1))) {
if (__pyx_t_2 >= PyList_GET_SIZE(__pyx_t_1)) break;
#if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
__pyx_t_4 = PyList_GET_ITEM(__pyx_t_1, __pyx_t_2); __Pyx_INCREF(__pyx_t_4); __pyx_t_2++; if (unlikely(0 < 0)) __PYX_ERR(0, 22, __pyx_L1_error)
#else
__pyx_t_4 = PySequence_ITEM(__pyx_t_1, __pyx_t_2); __pyx_t_2++; if (unlikely(!__pyx_t_4)) __PYX_ERR(0, 22, __pyx_L1_error)
__Pyx_GOTREF(__pyx_t_4);
#endif
} else {
if (__pyx_t_2 >= PyTuple_GET_SIZE(__pyx_t_1)) break;
#if CYTHON_ASSUME_SAFE_MACROS && !CYTHON_AVOID_BORROWED_REFS
__pyx_t_4 = PyTuple_GET_ITEM(__pyx_t_1, __pyx_t_2); __Pyx_INCREF(__pyx_t_4); __pyx_t_2++; if (unlikely(0 < 0)) __PYX_ERR(0, 22, __pyx_L1_error)
#else
__pyx_t_4 = PySequence_ITEM(__pyx_t_1, __pyx_t_2); __pyx_t_2++; if (unlikely(!__pyx_t_4)) __PYX_ERR(0, 22, __pyx_L1_error)
__Pyx_GOTREF(__pyx_t_4);
#endif
}
} else {
__pyx_t_4 = __pyx_t_3(__pyx_t_1);
if (unlikely(!__pyx_t_4)) {
PyObject* exc_type = PyErr_Occurred();
if (exc_type) {
if (likely(__Pyx_PyErr_GivenExceptionMatches(exc_type, PyExc_StopIteration))) PyErr_Clear();
else __PYX_ERR(0, 22, __pyx_L1_error)
}
break;
}
__Pyx_GOTREF(__pyx_t_4);
}
__Pyx_XDECREF_SET(__pyx_v_each, __pyx_t_4);
__pyx_t_4 = 0;
// 后面有后续
然后进入一个非常长的逻辑。这个逻辑流程是这样的:
- 首先检查了一个字符串是否为
List或者Tuple。如果是的话,直接将其赋值给__pyx_t_1,之后会以迭代器的方式调用,并且用__pyx_t_2标记此时的循环下标;否则,调用PyObject_GetIter,获取当前对象的可迭代对象,赋值给__pyx_t_1,此时__pyx_t_3会记录当前的带对象的下一个迭代对象。并且__pyx_t_2会被赋值为-1作为标记 - 然后回进入一个循环,每次循环的时候首先检查
__pyx_t_3是否为空,如果不为空的话进行迭代逻辑处理,并且将迭代对象交给__pyx_t_4,否则进行迭代对象的尝试获取 - 假设为空,此时确认
__pyx_t_1是否为List或者Tuple,若满足其中一项,则通过PyList_GET_SIZE取出其大小,并且如果大小大于__pyx_t_2,则条数循环。显然,我们这个时候的__pyx_t_2作为下标,小于我们的size,于是调用Py*_GET_ITEM(或者PySequence_ITEM)将其中元素赋值给__pyx_t_4,同时自增作为下标的__pyx_t_2
完成变量的取出之后,就会进入普通的运算逻辑
/* "test_for_pyd.py":23
* string = reversed(string)
* for each in string:
* num *= 16 # <<<<<<<<<<<<<<
* index = table.find(each)
* num += index
*/
__pyx_t_4 = PyNumber_InPlaceMultiply(__pyx_v_num, __pyx_int_16); if (unlikely(!__pyx_t_4)) __PYX_ERR(0, 23, __pyx_L1_error)
__Pyx_GOTREF(__pyx_t_4);
__Pyx_DECREF_SET(__pyx_v_num, __pyx_t_4);
__pyx_t_4 = 0;
/* "test_for_pyd.py":24
* for each in string:
* num *= 16
* index = table.find(each) # <<<<<<<<<<<<<<
* num += index
*
*/
__pyx_t_5 = __Pyx_PyObject_GetAttrStr(__pyx_v_table, __pyx_n_s_find); if (unlikely(!__pyx_t_5)) __PYX_ERR(0, 24, __pyx_L1_error)
__Pyx_GOTREF(__pyx_t_5);
__pyx_t_6 = NULL;
if (CYTHON_UNPACK_METHODS && likely(PyMethod_Check(__pyx_t_5))) {
__pyx_t_6 = PyMethod_GET_SELF(__pyx_t_5);
if (likely(__pyx_t_6)) {
PyObject* function = PyMethod_GET_FUNCTION(__pyx_t_5);
__Pyx_INCREF(__pyx_t_6);
__Pyx_INCREF(function);
__Pyx_DECREF_SET(__pyx_t_5, function);
}
}
__pyx_t_4 = (__pyx_t_6) ? __Pyx_PyObject_Call2Args(__pyx_t_5, __pyx_t_6, __pyx_v_each) : __Pyx_PyObject_CallOneArg(__pyx_t_5, __pyx_v_each);
__Pyx_XDECREF(__pyx_t_6); __pyx_t_6 = 0;
if (unlikely(!__pyx_t_4)) __PYX_ERR(0, 24, __pyx_L1_error)
__Pyx_GOTREF(__pyx_t_4);
__Pyx_DECREF(__pyx_t_5); __pyx_t_5 = 0;
__Pyx_DECREF_SET(__pyx_v_index, __pyx_t_4);
__pyx_t_4 = 0;
上述首先进行了简单的数字处理,然后尝试调用了一个内置函数find。可以看到其首先通过函数__Pyx_PyObject_GetAttrStr,指定需要在__pyx_v_table找到__pyx_n_s_find,并且这个值会临时存放在__pyx_t_5。完成函数方法检测之后,其通过__Pyx_PyObject_Call2Args对函数进行了调用。注意,第一个参数是通过调用__Pyx_PyObject_GetAttrStr找到了方法,然后第二个参数为上一段,找到被迭代对象后,通过__Pyx_XDECREF_SET(__pyx_v_each, __pyx_t_4);赋值得到的,真正的迭代对象的值。最后将运算结果得到的值赋值给__pyx_v_index
/* "test_for_pyd.py":25
* num *= 16
* index = table.find(each)
* num += index # <<<<<<<<<<<<<<
*
*
*/
__pyx_t_4 = PyNumber_InPlaceAdd(__pyx_v_num, __pyx_v_index); if (unlikely(!__pyx_t_4)) __PYX_ERR(0, 25, __pyx_L1_error)
__Pyx_GOTREF(__pyx_t_4);
__Pyx_DECREF_SET(__pyx_v_num, __pyx_t_4);
__pyx_t_4 = 0;
/* "test_for_pyd.py":22
* num = 0
* string = reversed(string)
* for each in string: # <<<<<<<<<<<<<<
* num *= 16
* index = table.find(each)
*/
} // 之前for(;;)的循环结尾
__Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
__Pyx_XDECREF(__pyx_r);
__Pyx_INCREF(__pyx_v_num);
__pyx_r = __pyx_v_num;
goto __pyx_L0;
/* "test_for_pyd.py":16
* print(test, result, t)
*
* def int(string): # <<<<<<<<<<<<<<
* table = "8ed4bc0123a567f9"
* v7 = 0
*/
/* function exit code */
__pyx_L1_error:;
// 一些退出函数
__pyx_L0:;
// 一些退出函数
return __pyx_r;
程序最后将__pyx_v_index与前文的__pyx_v_num进行相加,完成最后的运算,并且将最终运算结果__pyx_v_num作为返回值。
最后还要提一点,函数的名字会在这个位置为放置到一个全局的dict对象中,从而保证能够从module中取出这个对应的对象:
/* "test_for_pyd.py":9
* print(self.a)
*
* def test_hello(a, b): # <<<<<<<<<<<<<<
* test = 2
* result = test + 2
*/
__pyx_t_1 = __Pyx_CyFunction_New(&__pyx_mdef_12test_for_pyd_1test_hello, 0, __pyx_n_s_test_hello, NULL, __pyx_n_s_test_for_pyd, __pyx_d, ((PyObject *)__pyx_codeobj__7)); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 9, __pyx_L1_error)
__Pyx_GOTREF(__pyx_t_1);
if (PyDict_SetItem(__pyx_d, __pyx_n_s_test_hello, __pyx_t_1) < 0) __PYX_ERR(0, 9, __pyx_L1_error)
__Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
/* "test_for_pyd.py":16
* print(test, result, t)
*
* def int(string): # <<<<<<<<<<<<<<
* table = "8ed4bc0123a567f9"
* v7 = 0
*/
__pyx_t_1 = __Pyx_CyFunction_New(&__pyx_mdef_12test_for_pyd_3int, 0, __pyx_n_s_int, NULL, __pyx_n_s_test_for_pyd, __pyx_d, ((PyObject *)__pyx_codeobj__9)); if (unlikely(!__pyx_t_1)) __PYX_ERR(0, 16, __pyx_L1_error)
__Pyx_GOTREF(__pyx_t_1);
if (PyDict_SetItem(__pyx_d, __pyx_n_s_int, __pyx_t_1) < 0) __PYX_ERR(0, 16, __pyx_L1_error)
__Pyx_DECREF(__pyx_t_1); __pyx_t_1 = 0;
逆向技巧总结
通过上述分析,我们知道有几个重要的数据结构需要关注
- 用于初始化Python符号表的
__pyx_string_tab - 用于初始化各类函数的
__Pyx_InitCachedBuiltins,如果一个看似内置函数(例如int)没有在这边被初始化, 则说明此时这个函数很可能被覆盖了。函数的特征可以通过__Pyx_GetBuiltinName函数,或者__pyx_n_s_打头的函数全局变量进行交叉引用 - 用于初始化数字的
__Pyx_InitGlobals,再Python中,很多重要的数字都会以对象的形式存在,所以不能直接依赖看先有的数字。这个函数可以通过密集的Py*_FromLong之类的函数,或者通过__pyx_int_等数字全局变量进行定位。
逆向分析的时候,牢记python万物皆对象的原则。也就是说,大部分运算,赋值过程中,操作的通常是一个对象,而不是他实际代表的值。比如数字,字符串,这些都会以对象的形式存在。
在逆向range这种迭代对象的时候,也有几个特征:
- 由于传入的数值可能是
List\Tuple或者是其他可接受的迭代对象(包括string),所以不同的函数进入range相关逻辑处理过程可能不同,但是无论如何,都会有一个全局对象__pyx_t_4接受取出的对象 - 可以通过函数指针返回的对象同时会在其他分支中被赋值的特点找到迭代对象
除去以上逻辑外,逆向函数还有一些技巧
- 如果存在内置的函数调用,通常
__Pyx_PyObject_GetAttrStr被取出的函数对象__pyx_t_5可能会面临一个判断语句,不过最终这种判断语句中的内容会把结果重新交给最初赋值的变量__pyx_t_5身上
实战分析:CISCN-crystal
以往CTF的pyd大多是通过侧信道,或者通过猜测字符串的形式慢慢磨出flag,这次的题目好像都不好使了,只能试着直接逆向了。
首先题目本身肯定是一个exe,他的图标也是熟悉的一个python附在磁盘上。所以直接运行,然后去C盘指定的位置就能把对应的pyd抠出来。
首先根据上文,我们首先找到最重要的__pyx_string_tab所在的位置。可以尝试运行程序,然后发现其会打印wrong这个字符串,通过交叉引用能够找到其被引用的位置:
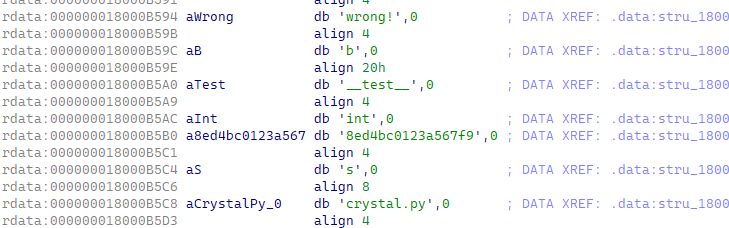
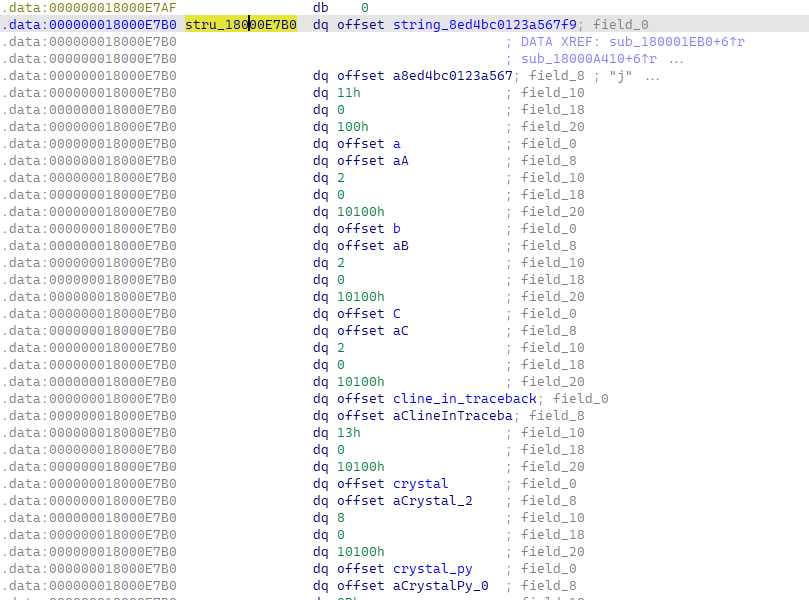
根据其内存布局,大致能还原出结构体如下:
00000000 PyStruct struc ; (sizeof=0x28, mappedto_34)
00000000 ; XREF: .data:stru_18000E7B0/r
00000000 field_0 dq ? ; XREF: sub_180001EB0+6/r
00000000 ; sub_18000A410+6/r ; offset
00000008 field_8 dq ? ; XREF: sub_180001EB0+14/o
00000008 ; sub_18000A410+14/o ; offset
00000010 field_10 dq ?
00000018 field_18 dq ?
00000020 field_20 dq ?
00000028 PyStruct ends
还原之后,就能得到大部分的变量的内容了:
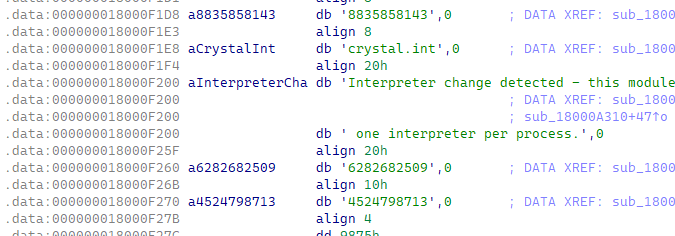
其次,我们需要关注一下数字的部分。我们通过PyLong_FromLong,发现一处其被频繁调用的位置:

这个位置也可在字符串区域中,发现奇怪的数字后引用找过来:
找齐了这些变量之后,就能够开始分析主逻辑了!
首先利用这些信息,定位到00x180005240的主要函数,其首先对很多变量进行了初始化(这个地方埋了个坑,后面会提到)其中着重关注这里
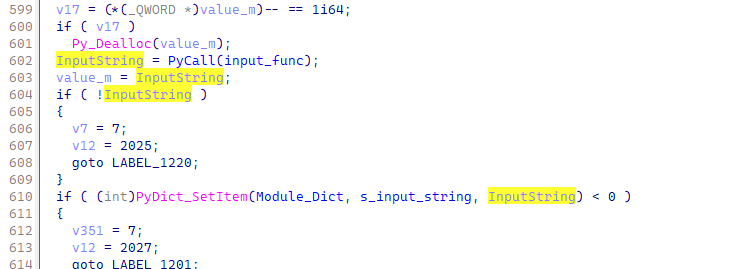
可以看到这边调用了input函数读入了数据。我们就紧随其后观察其数据走向。他首先被检查了长度
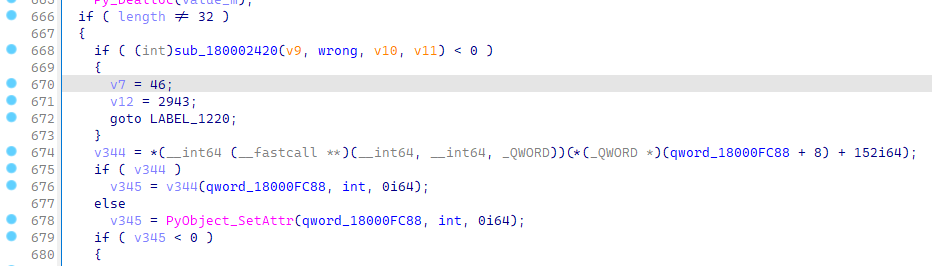
可以看到,变量会一种被各种引用来引用去。整个pyd逆向都是这个流程,因为从python的角度来看,它在尽可能动态的地维护一个对象的生命周期,所以需要紧紧的盯着看这个变量最终的赋值点
一直跟随,可来到这边
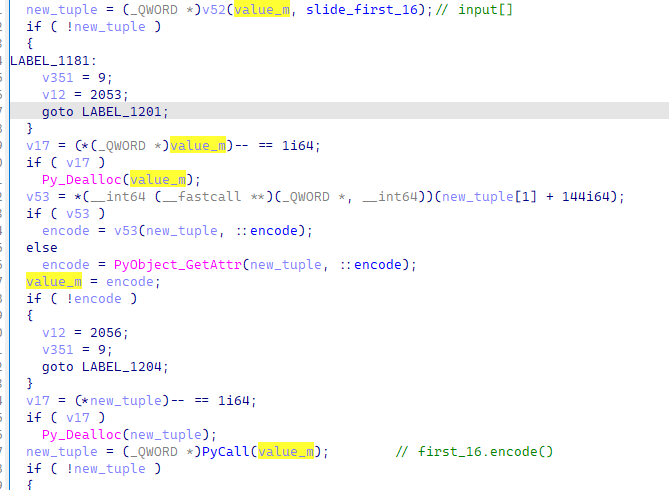
其中slide_first_16根据交叉引用,能够直到它是一个切片对象
if ( !qword_18000FBD0
|| (v350 = 3, (qword_18000FC28 = PyCode_New(1i64, 0i64, 3i64)) == 0)
|| (slide_first_16 = PySlice_New(Py_NoneStruct, dowrd_16, Py_NoneStruct)) == 0
|| (slide_last_16 = PySlice_New(dowrd_16, Py_NoneStruct, Py_NoneStruct)) == 0 )
{
v12 = 1994;
goto LABEL_1220;
}
于是此时根据逻辑,不难猜出,其python代码大致如下
input_string[:16].encode()
结合后文,我们能够直到这个切片对象被赋值给了b对象。然后会有一个简单的加密逻辑:
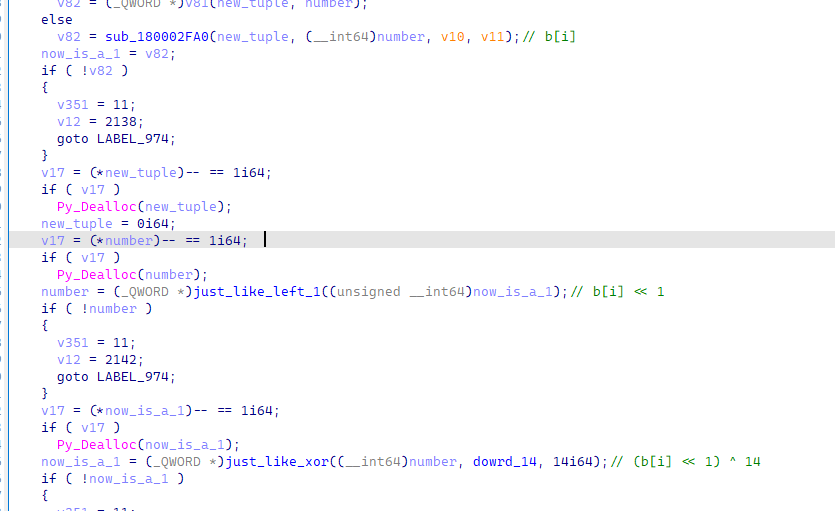
总结就能得出如下的代码:
b = test[:16]
slide_last_16 = test[16:]
b = bytearray(b.encode())
for i in range(len(b)):
b[i] = ((b[i] << 1) ^ 14) >> 1
紧接着,其将decode之后的值,通过int函数处理,交给了一个全局对象m
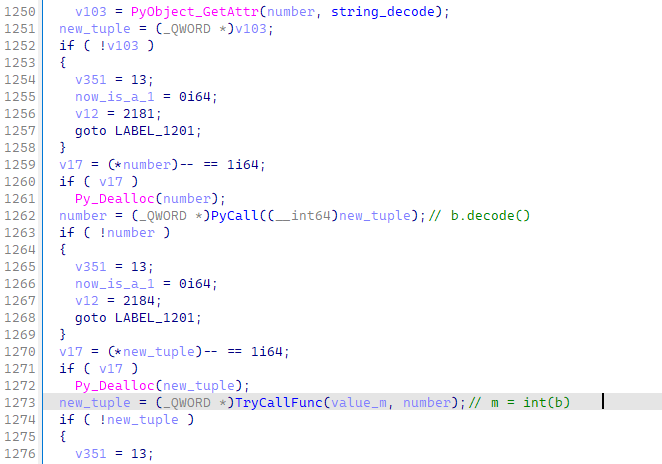
对应python代码如下:
m = int(b.decode())
之后会进行一系列的赋值操作。其中有一个值没有被交给全局对象,说明该值不会与对象进行数字运算:
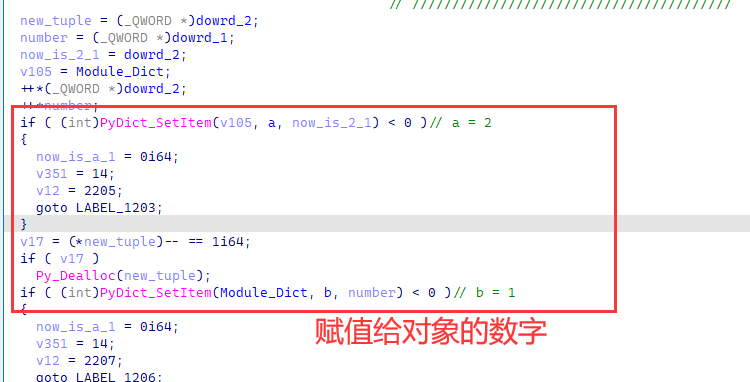
首先检查下标,会发现它相当于一个循环的边界,检查整个运算有没有越界

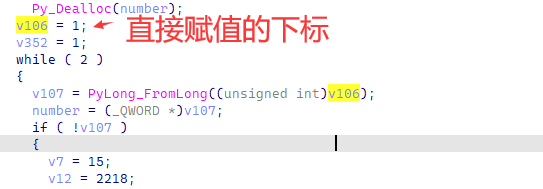
然后我们跟进到里面,由于其逻辑有点破碎,跳转众多,这边直接按照逆向结果分析。首先这边会用i对象进行一个range循环的设置。
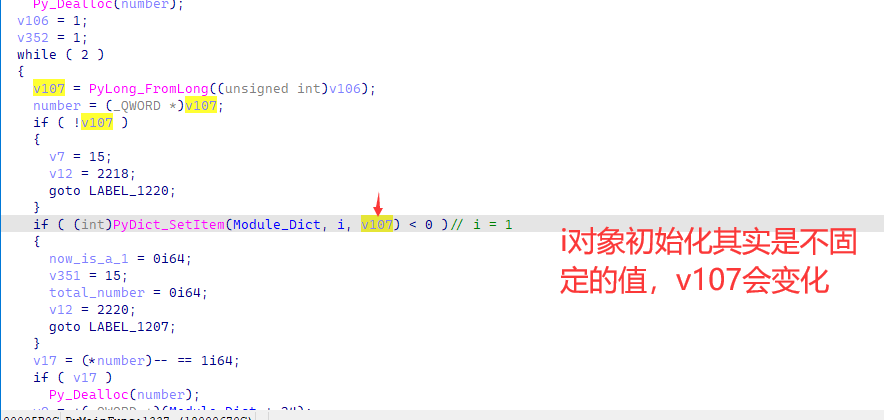
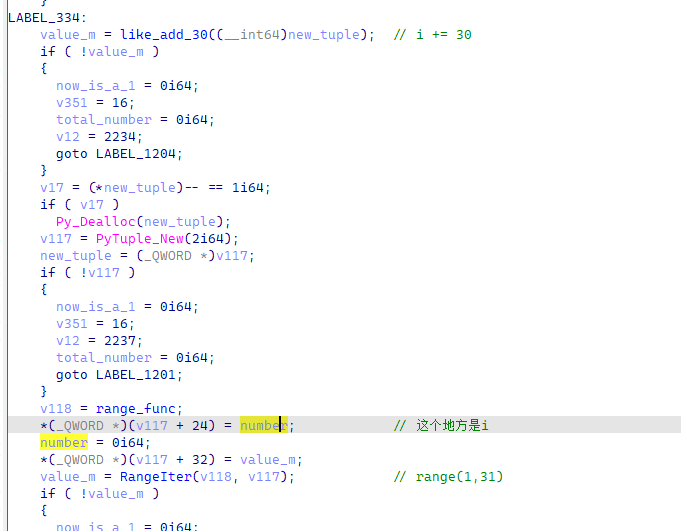
之后会利用这个i进行数字运算

完成运算之后,会将其与之前赋值的m做差
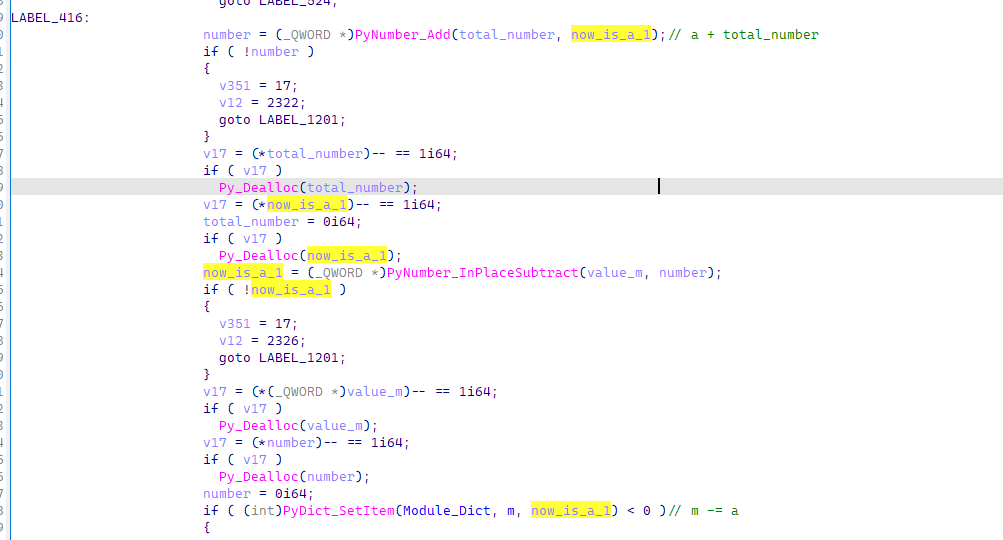
并且最后,还有一个检查m是否为空的比较,如果为空,则跳出循环
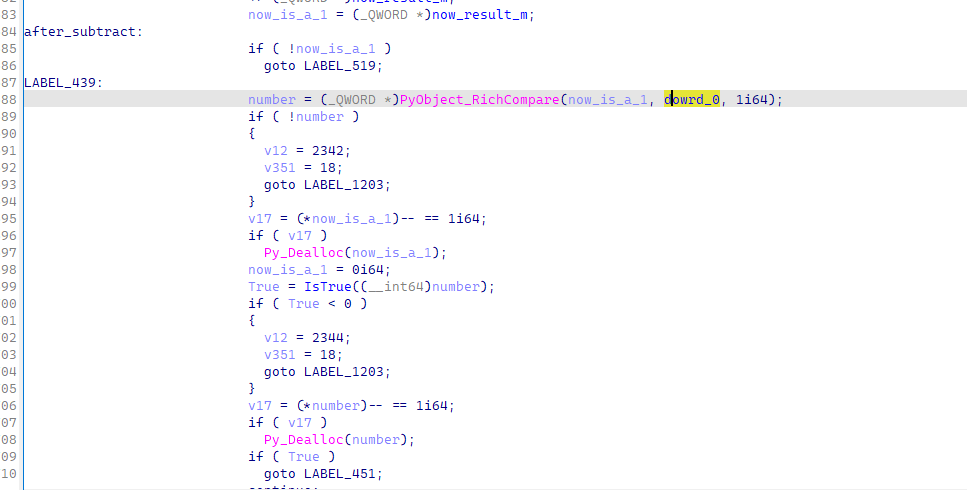
所以结合上下文,这一段的逻辑大致可以翻译为
a = 2
b = 1
i = 1
tmp = 1
while tmp < 10000:
i = tmp
for i in range(i,i+30):
# i**2
a = 8835858143 + ((i ** 2) * 6282682509 + i * 4524798713)
m -= a
if m == 0:
break
for循环结束之后,a和b的值会进行更新:
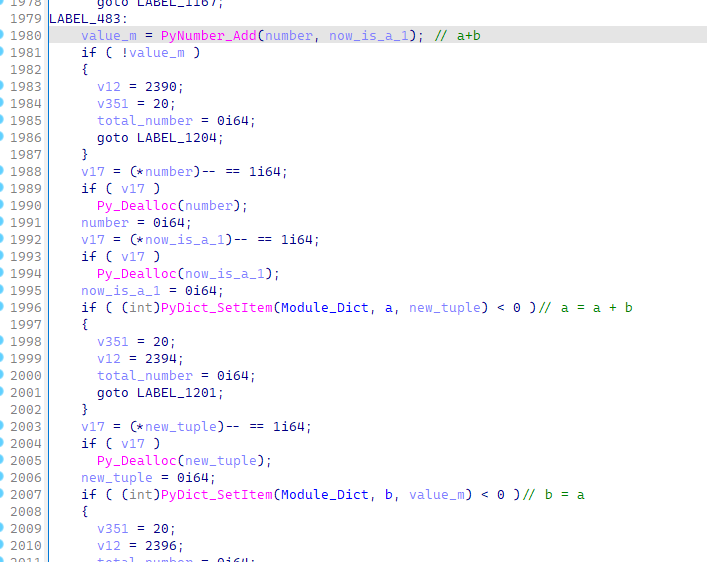
于是整个循环可以完善为
a = 2
b = 1
i = 1
tmp = 1
while tmp < 10000:
i = tmp
for i in range(i,i+30):
# i**2
a = 8835858143 + ((i ** 2) * 6282682509 + i * 4524798713)
m -= a
if m == 0:
break
a,b = b,a+b
tmp += 30
到这里加密逻辑基本上分析完了。剩下的另一部分逻辑显然也是根据这个逻辑进行分析即可。区别在于加密的手法略有不同,并且下标使用的为一个叫做j的变量
最后我们来到逻辑检查部分:
首先会检查i的值是否为1000
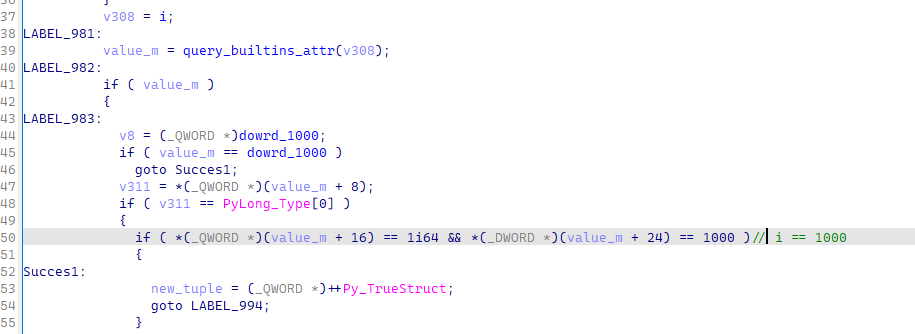
同理检查了j的值是否为2000,完成下标的见检查之后,会检查之前运算中m和n的值是否为0
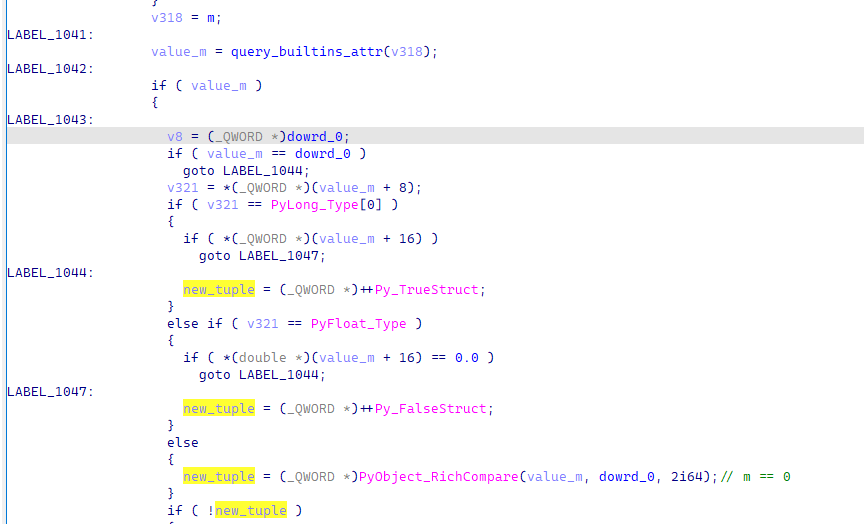
所有检查通过后,输出right。
至此,我们所有的逻辑已经分析完成,大概可以写出如下的脚本
if __name__ == "__main__":
test = input()
if len(test) != 32:
print("wrong!")
exit(0)
b = test[:16]
slide_last_16 = test[16:]
b = bytearray(b.encode())
for i in range(len(b)):
b[i] = ((b[i] << 1) ^ 14) >> 1
m = int(b.decode())
a = 2;b = 1;i = 1;tmp = 1
while tmp < 10000:
i = tmp
for i in range(i,i+30):
# i**2
a = 8835858143 + ((i ** 2) * 6282682509 + i * 4524798713)
m -= a
if m == 0:
break
a,b = b,a+b
tmp += 30
b = test[16:]
b = bytearray(b.encode())
for i in range(len(b)):
b[i] = ((b[i] << 1) ^ 2) >> 1
n = int(b.decode())
a = 2;b = 1;j = 1;tmp = 1
while tmp < 20000:
j = tmp
for j in range(j,30+j):
# i**2
a = 8835858143 + ((j ** 2) * 6282682509 + j * 4524798713)
n -= a
if n == 0:
break
a,b = b,a+b
if m == 0:
break
tmp += 30
if i == 1000 and j == 2000 and m == 0 and n == 0:
print("right!")
else:
print("wrong")
不过如果这样做的话,会发现一个奇怪的现象:答案算出来有很多的乱码,而且int函数就会报错,提示这不是一个10进制的数字。于是考虑到,这个int是不是被重载了
关于int的坑
在最初初始化的时候,我们跳过了一个地方
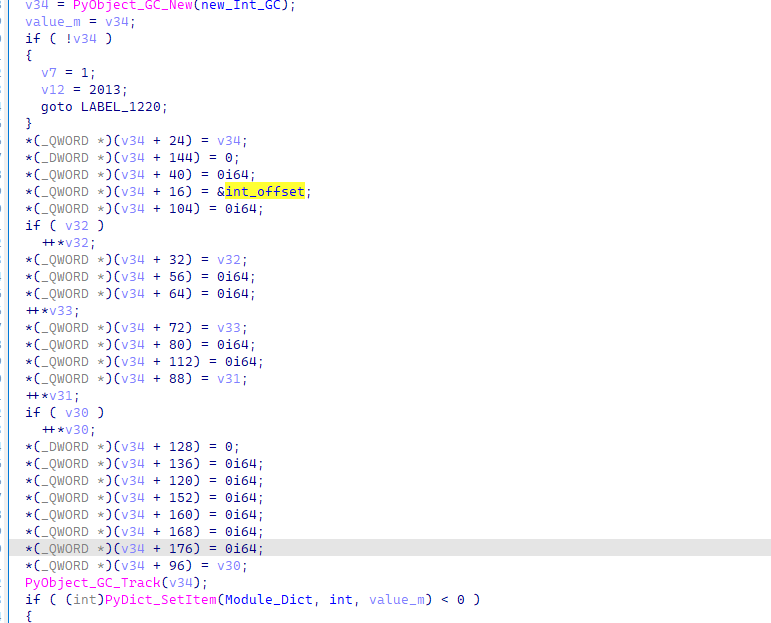
这边的int被特殊的初始化过,如果跟随进去会发现,这个地方是一个函数结构体

整体分析逻辑与前文相似,大致就是这个int能够帮我们将16进制的数字映射到另一串字母,然后进行十进制转换。其最终整理的逻辑如下
def self_int(string):
table = "8ed4bc0123a567f9"
v7 = 0
index = 0
num = 0
string = reversed(string)
for each in string:
num *= 16
index = table.find(each)
num += index
于是,最后我们能够得到一个解题脚本:
def self_int(string):
table = "8ed4bc0123a567f9"
v7 = 0
index = 0
num = 0
string = reversed(string)
for each in string:
num *= 16
index = table.find(each)
num += index
return num
def back_int(string):
table = "8ed4bc0123a567f9"
v7 = 0
index = 0
num = 0
string = reversed(string)
for each in string:
# print(each)
num *= 16
index = int(table[int(each,16)],16)
num += index
return num
def decode1(string):
# t = [int(string[i:i+2],16) for i in range(0,len(string),2) ]
t = bytearray(string.encode())
# print(t)
ans = []
for i in range(len(t)):
t[i] = ((t[i] << 1)^14)>>1
# print(ans)
return t
def decode2(string):
# t = [int(string[i:i+2],16) for i in range(0,len(string),2) ]
t = string.encode()
# print(t)
ans = []
for each in t:
ans.append(((each << 1) ^ 2) >> 1)
# print(ans)
return ''.join([chr(c) for c in ans])
# 0x5a2
def get_answer(bind):
a = 2
b = 1
i = 1
tmp = 1
m = 0
while tmp < 10000:
i = tmp
for i_tmp in range(i,30+i):
# i**2
m += 8835858143 + ((i_tmp ** 2) * 6282682509 + i_tmp * 4524798713) + a
# m -= a
# if m == 0:
# break
if i_tmp == bind:
# print(m)
tmp = hex(m)[2:]
# print("the number is:"+tmp)
t = back_int(tmp)
# print("back is :"+hex(t)[2:])
if bind == 1000:
print(decode1(hex(t)[2:]).decode())
elif bind == 2000:
print(decode2(hex(t)[2:]))
return
a,b = b,a+b
# if m == 0:
# break
tmp += 30
# print(decode1("0000000000000001"))
# print(hex(back_int(hex(self_int("3c8a95c996893a7d5"))[2:])))
get_answer(str(1000))
get_answer(2000)
得到最终答案为1b0151a145a73c0b9d92440ccb03663g
参考链接
https://blog.csdn.net/zhangyifei216/article/details/50667192


