1.introduction
影响或阻碍 IDA、BinaryNinja、Ghidra 和 Radare2 等反汇编工具的 ELF 或 Mach-O 修改。
不会修改汇编代码或二进制数据。重点是修改可执行文件格式的一些结构,比如节区和符号。
所有修改均基于LIEF,一个用于解析和修改可执行文件格式的库。
2.__unwind_info & .eh_frame
ELF .eh_frame 节区和 Mach-O __unwind_info 节区包含可用于获取二进制文件中存在的函数地址列表的信息。
该节区可以被LIEF支持和解析,并获取到函数地址列表。
import lief
target = lief.parse("/bin/ls")
for function in target.functions:
print(function.address)
反汇编程序也使用这些部分来获取可以开始反汇编的函数的初始工作列表。
因此,我们可以通过打乱它们的内容来防止反汇编程序使用这些部分的内容。这是ELF部分的示例:
for name in [".eh_frame", ".eh_frame_hdr"]:
section = target.get_section(name)
section_content = list(section.content)
random.shuffle(section_content)
section.content = section_content
IDA、BinaryNinja 和 Radare2 似乎不受此修改的影响,但Ghidra在尝试分析二进制文件时会引发异常。

3.Exported Symbols
我们可以对可执行格式进行的第一个简单、高效和通用的修改是创建fake exports。感谢ELF .eh_frame节区和 Mach-O __unwind_info节区,我们可以或多或少地获得函数起始地址的准确列表,从而创建相关的导出。
3.1 Creating Fake Exports Names
我们可以通过创建随机命名的导出名称来开始“混淆”二进制文件。可以使用LIEF的add_exported_function函数创建导出(此函数仅适用于 ELF 和 Mach-O 格式,不适用于 PE 格式),随机符号的名称可以通过 Python random 模块生成。
import lief
import random
import string
target = lief.parse("mbedtls_self_test.arm64.macho")
for function in target.functions:
name = "".join(random.choice(string.ascii_letters) for i in range(20)) # 获取长度为20的随机函数名
target.add_exported_function(function.address, name)
target.write("01-mbedtls_self_test.arm64.macho")
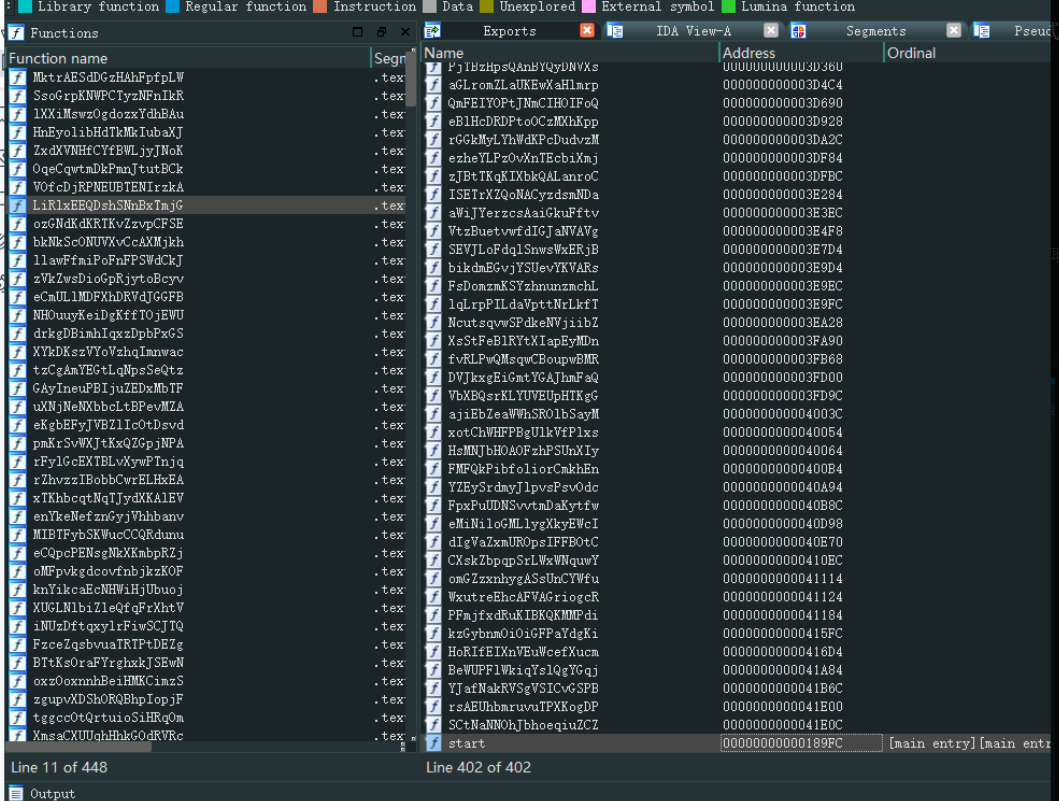
3.2 Confusing the Exports Names
创建随机导出名称令人困惑,但逆向工程师可以立即识别出二进制文件已被修改或旨在受到保护。此外,与常规的功能剥离相比,它并没有带来更多的保护。
实际上,我们仍然可以利用导出表来添加新条目,但我们可以从原始 Mbed TLS 二进制文件中选择真实且一致的函数名称,而不是使用随机字符串。
target = lief.parse("mbedtls_self_test.arm64.elf")
nostripped = lief.parse("mbedtls_self_test.nostrip.arm64.elf")
SYMBOLS = [s.name for s in non_striped.symbols \
if s.name.startswith("mbedtls_")]
for function in target.functions:
name = random.choice(SYMBOLS)
SYMBOLS.remove(name)
target.add_exported_function(function.address, name)
为了继续使用有意义的名称,我们还可以从像 libc.so 这样的标准库中获取名称。
与 mbedtls_* 名称相比,libc 的符号通常被反汇编程序识别,反汇编程序为此类函数提供类型库。还可以通过从 LLVM 库(例如)中获取C++修饰过的符号达到更好的混淆。
但是让我们继续使用 libc 的符号。对于Android,我们可以从NDK中收集 libc 的符号,并且我们还需要避免使用目标已经导入的 libc的导出符号:
libc = lief.parse("[FF.]toolchains/llvm/prebuilt/linux-x86_64" "/sysroot/usr/lib/aarch64-linux-android/23/libc.so")
libc_symbols = {s.name for s in libc.exported_symbols}
libc_symbols -= {s.name for s in target.imported_symbols}
libc_symbols = list(libc_symbols)
for function in target.functions:
sym = random.choice(libc_symbols)
libc_symbols.remove(sym)
target.add_exported_function(function.address, sym)
我们还需要让loader不使用我们新创建的libc导出符号被实际解析成其他库或库本身导入的libc函数,可以通过调整符号的可见性和符号绑定来实现:
export = target.add_exported_function(function.address, sym)
export.binding = lief.ELF.SYMBOL_BINDINGS.GNU_UNIQUE
export.visibility = lief.ELF.SYMBOL_VISIBILITY.INTERNAL
如果二进制文件以 Linux 为目标,则绑定必须设置为
lief.ELF.SYMBOL_BINDINGS.WEAK 而不是 lief.ELF.SYMBOL_BINDINGS.GNU_UNIQUE
3.3 Exports Addresses
进行静态分析时的挑战之一是识别二进制文件中存在的函数。
二进制入口点显然是反汇编代码的良好开端,但反汇编程序依赖于来自可执行文件格式的其他信息,例如导出表。事实证明,反汇编程序强烈信任导出表,而我们实际上可以创建具有任意符号和任意地址的条目。
前面的内容仅涉及导出名称。由于导出总是与地址相关联,我们也可以欺骗这个值。这些技巧之一是在函数开头创建具有 delta 值的导出:
for function in target.functions:
address = function.address
address += random.randint(16, 32)
为了避免出现未对齐的指令,我们需要确保增量在四个字节上对齐:
for function in target.functions:
address = function.address
address += random.randint(16, 32)
address -= address % 4
通过这样的修改,所有工具:IDA、BinaryNinja、Radare2、Ghidra 都会错误地反汇编代码并生成不完整的控制流图。
4.Sections Transformations
基于导出表的修改对反汇编程序的效率和准确性有重要影响。为了增强我们的混淆器,我们还可以对 ELF 和 Mach-O 二进制文件的节区应用修改。虽然这两种格式都有节区和段,但加载器使用它们的方式不同。然而,我们可以利用反汇编程序在段和节区之间造成的混淆来误导反汇编程序的输出。
4.1 ELF
解析 ELF 二进制文件时的挑战之一是节和段之间的对称性,编译器/链接器使用sections,而加载器使用segments来运行可执行文件。这意味着不应使用节来获取二进制文件的可执行视图。
segments在数据上具有粗略的粒度,而sections对数据的位置和含义提供了更好的精度。
例如,根据segments识别GOT的位置就不那么简单了,然而在使用sections时,GOT 通常由.got节区映射。
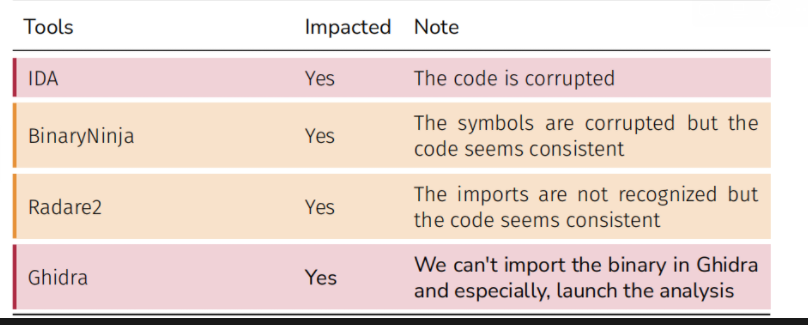
我们可以通过删除 ELF section table来完全去除这些部分,但是像 IDA 这样的反汇编器学会了处理这种情况。(gdb 无法调试无节的二进制文件)
因此,与其完全删除sections table或随意破坏section属性,我们的想法是交换一些section,这样我们在保持一定程度的一致性的同时会破坏整体布局。
这种交换配置对不同的反汇编工具非常有效,Radare2 和 BinaryNinja 在导入符号时遇到了困难,但汇编代码似乎与原始代码一致。另一方面,Ghidra 甚至在启动分析之前也无法导入二进制文件。最后,IDA 能够加载二进制文件,但它破坏了汇编代码。
SWAP_LIST = [ (".rela.dyn", ".data.rel.ro"),
(".got", ".got.plt"),
(".plt", ".text"),
(".dynsym", ".gnu.version"),
]
target = lief.parse("mbedtls_self_test.arm64.elf")
for (lhs_name, rhs_name) in SWAP_LIST:
print(lhs_name, rhs_name)
lhs = target.get_section(lhs_name).as_frame()
rhs = target.get_section(rhs_name).as_frame()
tmp = lhs.offset, lhs.size, lhs.name, lhs.type, lhs.virtual_address
lhs.offset = rhs.offset
lhs.size = rhs.size
lhs.name = rhs.name
lhs.type = rhs.type
lhs.virtual_address = rhs.virtual_address
rhs.offset = tmp[0]
rhs.size = tmp[1]
rhs.name = tmp[2]
rhs.type = tmp[3]
rhs.virtual_address = tmp[4]
target.write("swapped_alt_mbedtls_self_test.arm64.elf")
4.2 Mach-O
与 ELF 格式相比,Mach-O 格式及其加载器 dyld 强制执行更严格的布局,例如在不中断二进制执行的情况下无法交换节。 dyld 对部分布局执行的一些检查在 dyld/dyld3/MachOAnalyze.cpp 中定义。
在这些检查中,它验证:
- 节的大小不是负数(或溢出)
- 节的虚拟地址和虚拟大小在段的虚拟地址/虚拟大小之内
- 它强制对特殊部分(如 MOD_INIT_FUNC_POINTERS)进行部分大小对齐
所以基本上,与 ELF 格式相比,节与段的绑定更强。然而,在 __TEXT 段中,我们可以进行一个小的修改,包括将 __stub section的起始位置虚拟地移动到 __text section上去。

首先,这两个部分在同一个 __TEXT 段中。
其次,保证所有sections的大小之和不变。
__stubs section与用于记录导入解析的 ELF .plt 部分非常相似。
__stubs section包含汇编代码(trampoline stub),因此它与 __text section共享相同类型的内容。
以编程方式,我们可以使用以下代码执行这个修改:
SHIFT = 0x100
__text = target.get_section("__text")
__stubs = target.get_section("__stubs")
# Reduce the size of the __text section
__text.size -= SHIFT
__stubs.offset -= SHIFT
__stubs.virtual_address -= SHIFT
__stubs.size += SHIFT
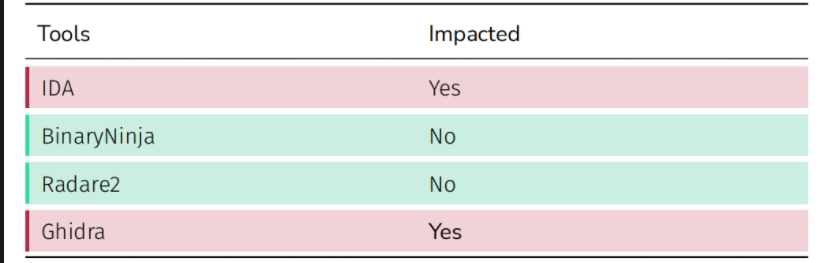
Radare2 和 BinaryNinja 似乎没有受到这种转变的影响,而 Ghidra 和 IDA 受到了很大的影响。
Ghidra 只是拒绝导入二进制文件。导入操作先于分析操作,因此此修改阻止 Ghidra 将二进制文件添加到项目中。另一方面,IDA 能够加载二进制文件,但其输出令人困惑。特别是,main函数被破坏,我们可以在下图中观察到:
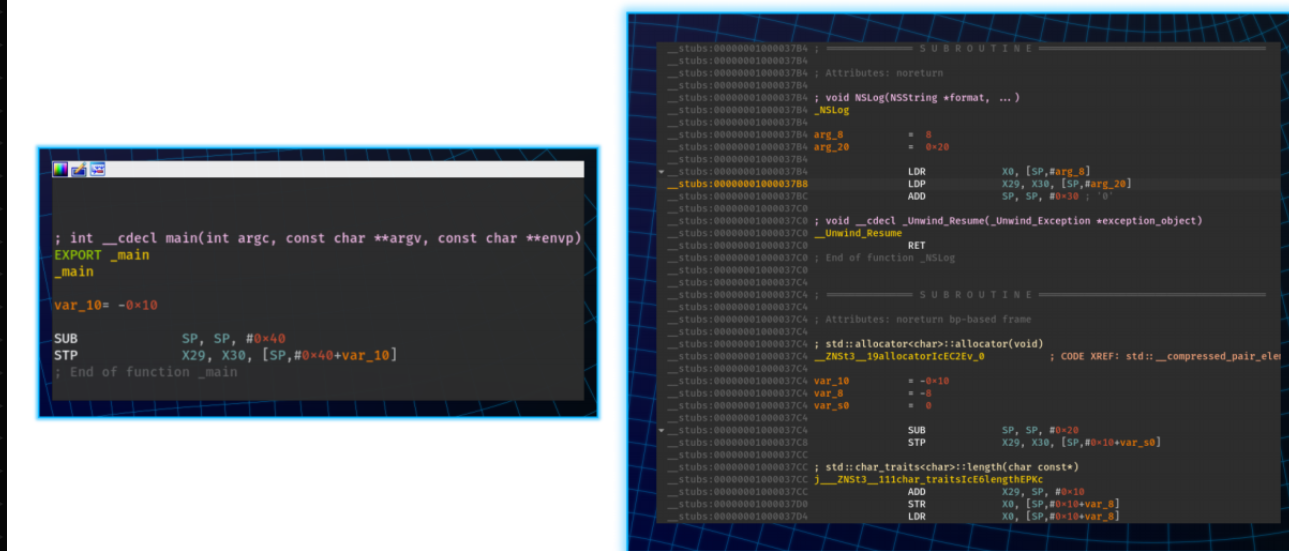
5.Specific Transformations
在前面的内容中,我们详细介绍了基于两种格式共享的结构的修改:
- 导出
- 节区
下面详细介绍了特定用于 Mach-O 或 ELF 格式的其他修改。
5.1 LC_FUNCTIONS_STARTS
LC_FUNCTIONS_STARTS 命令是一种调试命令,它引用二进制文件中存在的函数列表。该命令在加载二进制文件时对 dyld 没有影响,因此完全破坏其内容或修改函数的地址是可能的。
与导出表类似,反汇编工具使用此命令获取可信赖的函数列表以开始反汇编。
这个命令中列出的函数只是一个相对于默认基地址(由__TEXT段虚拟地址给出)的地址列表。使用LIEF,我们可以应用Exports Addresses中描述的类似技术,在两个地址之间建立重叠。
functions = [f for f in LC_FUNCTION_STARTS.functions]
for idx, f in enumerate(functions):
# Overlap 7 instructions
if idx % 2 == 0:
functions[idx] += 4 * 7
else:
functions[idx] -= 4 * 7
LC_FUNCTION_STARTS.functions = functions
这种重叠会影响除 Ghidra 之外的所有反汇编工具。
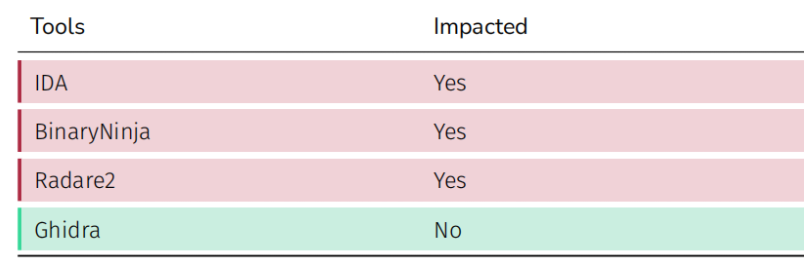
5.2 .dynsym section
正如前面段落中已经提到的:ELF 格式非常棘手。除了节和段之间的对称性之外,计算.dynsym 节中引用的导入或导出符号的数量并非易事。
与导入和导出相关的符号表的开头由位于 PT_DYNAMIC 段中的 DT_SYMTAB 条目定义,引用表的 DT_ 条目通常与另一个保存表大小的 DT_SZ 条目配对。事实证明,DT_SYMTAB 条目有一个例外,该条目未绑定到引用其大小的另一个条目。
另一方面,动态符号表由具有大小的 .dynsym section映射。因此,使用该section来计算表中的条目数很有吸引力。正如我们在节区修改内容中提到的,ELF sections不能被信任。
我们可以利用 ELF 格式的这一特性来人为地减小 .dynsym 部分的大小:
dynsym = target.get_section(".dynsym").as_frame()
sizeof = dynsym.entry_size
osize = dynsym.size
nsyms = osize / sizeof
dynsym.size = sizeof * 3
此代码人为地将 .dynsym section的大小限制为 3 个符号
6. Conclusion
文件格式修改对于防止逆向工程工具正常工作非常有效,由于原始汇编代码保持不变,因此文件格式修改的弹性不如经典混淆。另一方面,与常规混淆相比,这是一个较少探索的主题。
code:
# _*_ coding:utf-8 _*_
import lief
import random
import string
# Mach-O __unwind_info modify
def mach_o_unwind_info_modify(target):
section = target.get_section("__unwind_info")
content = list(section.content)
random.shuffle(content)
section.content = content
return target
# ELF .eh_frame modify
def elf_eh_frame_modify(target):
for sname in [".eh_frame", ".eh_frame_hdr"]:
section = target.get_section(sname)
if section is None:
continue
content = list(section.content)
random.shuffle(content)
section.content = content
return target
# 修改导出表,用程序函数地址添加随机函数名的导出函数
def elf_exports_name_random(target):
for idx, function in enumerate(target.functions):
name = "".join(random.choice(string.ascii_letters) for i in range(20))
target.add_exported_function(function.address, name)
return target
# 从target0中提取函数名修改到target1导出表中(可执行文件之间)
def elf_exports_from_target0_to_target1(target0, target1):
SYMBOLS = [s.name for s in target0.symbols]
for idx, function in enumerate(target.functions):
if len(SYMBOLS) == 0:
break
sym = random.choice(SYMBOLS)
SYMBOLS.remove(sym)
target1.add_exported_function(function.address, sym)
return target1
# 从libc中提取函数名修改到target导出表
# libc = lief.parse("<ANDROID_HOME>/sdk/ndk/24.0.8215888/toolchains/llvm/prebuilt/linux-x86_64/sysroot/usr/lib/aarch64-linux-android/23/libc.so")
def elf_exports_from_libc_to_target(libc, target):
libc_symbols = {s.name for s in libc.exported_symbols}
libc_symbols -= {s.name for s in target.imported_symbols}
libc_symbols = list(libc_symbols)
for idx, function in enumerate(target.functions):
if len(libc_symbols) == 0:
break
sym = random.choice(libc_symbols)
libc_symbols.remove(sym)
export = target.add_exported_function(function.address, sym)
export.binding = lief.ELF.SYMBOL_BINDINGS.GNU_UNIQUE
export.visibility = lief.ELF.SYMBOL_VISIBILITY.INTERNAL
return target
# 从libc中提取函数名, 并且让原先获取的地址被修改后添加到target导出表
def elf_exports_from_libc_to_target_addresschange(libc, target):
libc_symbols = {s.name for s in libc.exported_symbols}
libc_symbols -= {s.name for s in target.imported_symbols}
libc_symbols = list(libc_symbols)
for idx, function in enumerate(target.functions):
if len(libc_symbols) == 0:
break
sym = random.choice(libc_symbols)
libc_symbols.remove(sym)
address = function.address
address += random.randint(16, 32)
address -= address % 4
export = target.add_exported_function(address, sym)
export.binding = lief.ELF.SYMBOL_BINDINGS.GNU_UNIQUE
export.visibility = lief.ELF.SYMBOL_VISIBILITY.INTERNAL
return target
# Mach-O sections modify
def mach_o_sections_modify(target):
__text = target.get_section("__text")
__stubs = target.get_section("__stubs")
SHIFT = 0x100
__text.size -= SHIFT
__stubs.offset -= SHIFT
__stubs.virtual_address -= SHIFT
__stubs.size += SHIFT
return target
# elf sections swap
def elf_sections_swap(target):
SWAP_LIST = [
(".rela.dyn", ".data.rel.ro"),
(".got", ".got.plt"),
# (".got", ".data"),
(".plt", ".text"),
(".dynsym", ".gnu.version"),
# (".preinit_array", ".bss"),
]
for (lhs_name, rhs_name) in SWAP_LIST:
print(lhs_name, rhs_name)
lhs = target.get_section(lhs_name).as_frame()
rhs = target.get_section(rhs_name).as_frame()
tmp = lhs.offset, lhs.size, lhs.name, lhs.type, lhs.virtual_address
lhs.offset = rhs.offset
lhs.size = rhs.size
lhs.name = rhs.name
lhs.type = rhs.type
lhs.virtual_address = rhs.virtual_address
rhs.offset = tmp[0]
rhs.size = tmp[1]
rhs.name = tmp[2]
rhs.type = tmp[3]
rhs.virtual_address = tmp[4]
return target
# elf dynsym modify
def elf_dynsym_modify(target):
dynsym = target.get_section(".dynsym")
sizeof = dynsym.entry_size
osize = dynsym.size
nsyms = osize / sizeof
dynsym.size = sizeof * min(3, nsyms)
return target
# Mach-O LC_FUNCTIONS_STARTS address overlap
def mach_o_LC_FUNCTIONS_STARTS_modify(target):
LC_FUNCTION_STARTS = target[lief.MachO.LOAD_COMMAND_TYPES.FUNCTION_STARTS]
functions = [f for f in LC_FUNCTION_STARTS.functions]
for idx, f in enumerate(functions):
if idx % 2 == 0:
functions[idx] += 4 * 7
else:
functions[idx] -= 4 * 7
return target
if __name__ == '__main__':
target = lief.parse('fuck')
# elf_exports_name_random(elf_dynsym_modify(target)).write('fuck1')
记录下学习国外这篇文章的笔记:https://www.romainthomas.fr/publication/22-pst-the-poor-mans-obfuscator/




