前言
这次的分析接着上次的来讲,也是分析了两个中间件的通信模型,分别是非主流中间件被厂商魔改后的中间件➕CGI和OpenWrt中间模块uhttpd/lighttpd➕CGI/Lua,话不多说,直接开始...
非主流中间件被厂商魔改后的中间件➕CGI
Boa源码分析:通信模型
src/Boa.c中的main中包含大量初始化,关键的循环是server_s
...
parse_commandline(argc, argv); //解析输入的命令
fixup_server_root(); // 确认服务器根目录
read_config_files(); // 读取配置文件
create_common_env(); // 创建环境变量
open_logs(); // 打开日志
server_s = create_server_socket(); // 创建套接字
init_signals(); //初始化信号
build_needs_escape(); // 创建转义字符串
...
loop(server_s); // 循环检查信号
在src/poll.c中loop(server_s)进行信号的初始化之后进入process_requests(server_s)处理请求
void loop(int server_s)
{
while (1) {
time(¤t_time);
if (sighup_flag)
sighup_run();
if (sigchld_flag)
sigchld_run();
if (sigalrm_flag)
sigalrm_run();
if (sigterm_flag) {
if (sigterm_flag == 1) {
sigterm_stage1_run();
close(server_s);
server_s = -1;
{
for(i = 0, j = 0;i < pfd_len;++i) {
if (i == (unsigned) server_pfd)
continue;
pfd1[other][j].fd = pfd1[which][j].fd;
pfd1[other][j].events = pfd1[which][j].events;
++j;
}
pfd_len = j;
pfds = pfd1[other];
temp = other;
other = which;
which = temp;
}
watch_server = 0;
}
if (sigterm_flag == 2 && !request_ready && !request_block) {
sigterm_stage2_run();
}
} else {
if (total_connections < max_connections) {
server_pfd = pfd_len++;
pfds[server_pfd].fd = server_s;
pfds[server_pfd].events = BOA_READ;
watch_server = 1;
} else {
watch_server = 0;
}
pending_requests = 0;
if (pfd_len) {
timeout = (request_ready ? 0 :
(request_block ? default_timeout : -1));
if (poll(pfds, pfd_len, timeout) == -1) {
if (errno == EINTR)
continue;
}
if (!sigterm_flag && watch_server) {
if (pfds[server_pfd].revents &
(POLLNVAL|POLLERR)) {
log_error("server pfd revent contains "
"POLLNVAL or POLLERR! Exiting.");
exit(EXIT_FAILURE);
} else if (pfds[server_pfd].revents & BOA_READ) {
pending_requests = 1;
}
}
time(¤t_time);
}
pfd_len = 0;
if (request_block) {
update_blocked(pfd1[other]);
}
pfds = pfd1[other];
temp = other;
other = which;
which = temp;
process_requests(server_s);
}
}
先来关注一下request这个待处理的请求结构体,里面包含了请求当中的各种参数:
struct request {
// 请求头基本信息
enum REQ_STATUS status; // 状态码
enum KA_STATUS keepalive; // 连接状态
enum HTTP_VERSION http_version; // http版本
enum HTTP_METHOD method; // 请求方法
enum RESPONSE_CODE response_status; // 响应码
// cgi的请求信息
enum CGI_TYPE cgi_type; // cgi的请求类型和状态
enum CGI_STATUS cgi_status; // cgi的请求状态
...
char *pathname; // 请求路径
...
int data_fd; // 文件fd
unsigned long filesize; // 文件大小
unsigned long filepos; // 文件指针位置
unsigned long bytes_written; // 写入大小
char *data_mem; // 数据内存位置
...
char *header_line; // 请求头的开始
char *header_end; // 请求头的尾部
int parse_pos; // 解析数量
int buffer_start; // 缓冲区开始
int buffer_end; // 缓冲区结尾
...
// cgi参数
int cgi_env_index;
...
char buffer[BUFFER_SIZE + 1]; // I/O的缓冲区
char request_uri[MAX_HEADER_LENGTH + 1]; // 请求的uri
char client_stream[CLIENT_STREAM_SIZE]; // 客户端的流
char *cgi_env[CGI_ENV_MAX + 4]; // cgi环境变量
...
};
在src/request.c中的process_requests首先判断是否存在待处理的请求中的数据包,如果存在调用get_request(server_sock)进行结构化,然后赋值给current,完成后根据current->status来判断处理请求的函数,最后再判断是否存在待处理的请求,再进行处理,笔者这里关注的是处理请求的流程,所以read_header(current)是重点关注的函数:
void process_requests(int server_sock)
{
// 若存在待处理的请求,就获取请求的内容
if (pending_requests) {
get_request(server_sock);
#ifdef ORIGINAL_BEHAVIOR
pending_requests = 0;
#endif
}
current = request_ready;
while (current) {
...
// 判断请求的状态是否有效
retval = 1;
if (current->buffer_end &&
current->status < TIMED_OUT) {
retval = req_flush(current);
if (retval == -2) {
current->status = DEAD;
retval = 0;
} else if (retval >= 0) {
retval = 1;
}
}
// 进入对应状态的处理函数
if (retval == 1) {
switch (current->status) {
case READ_HEADER:
case ONE_CR:
case ONE_LF:
case TWO_CR:
retval = read_header(current);
break;
case BODY_READ:
retval = read_body(current);
break;
case BODY_WRITE:
retval = write_body(current);
break;
case WRITE:
retval = process_get(current);
break;
case PIPE_READ:
retval = read_from_pipe(current);
break;
case PIPE_WRITE:
retval = write_from_pipe(current);
break;
case IOSHUFFLE:
...
if (sigterm_flag)
SQUASH_KA(current);
// 获取下一个请求的数据包
if (pending_requests)
get_request(server_sock);
switch (retval) {
case -1:
trailer = current;
current = current->next;
block_request(trailer);
break;
case 0:
current->time_last = current_time;
trailer = current;
current = current->next;
free_request(trailer);
break;
case 1:
current->time_last = current_time;
current = current->next;
break;
default:
...
current->status = DEAD;
// 处理下一个请求
current = current->next;
break;
}
}
}
在src\read.c中的read_header中进行一些判断数据包是否正常,然后就调用process_header_end进行处理
int read_header(request * req)
{
// 初始化处理请求的位置
check = req->client_stream + req->parse_pos;
buffer = req->client_stream;
bytes = req->client_stream_pos;
...
while (check < (buffer + bytes)) {
uc = *check;
// 判断请求是否为可见字符
if (uc != '\r' && uc != '\n' && uc != '\t' &&
(uc < 32 || uc > 127)) {
...
send_r_bad_request(req);
return 0;
}
switch (req->status) {
case READ_HEADER:
if (uc == '\r') {
req->status = ONE_CR;
req->header_end = check;
} else if (uc == '\n') {
req->status = ONE_LF;
req->header_end = check;
}
break;
case ONE_CR:
if (uc == '\n')
req->status = ONE_LF;
else if (uc != '\r')
req->status = READ_HEADER;
break;
case ONE_LF:
if (uc == '\r')
req->status = TWO_CR;
else if (uc == '\n')
req->status = BODY_READ;
else
req->status = READ_HEADER;
break;
case TWO_CR:
if (uc == '\n')
req->status = BODY_READ;
else if (uc != '\r')
req->status = READ_HEADER;
break;
default:
break;
}
...
req->parse_pos++;
check++;
if (req->status == ONE_LF) {
*req->header_end = '\0';
if (req->header_end - req->header_line >= MAX_HEADER_LENGTH) {
...
send_r_bad_request(req);
return 0;
}
if (req->logline) {
if (process_option_line(req) == 0) {
return 0;
}
} else {
if (process_logline(req) == 0)
return 0;
if (req->http_version == HTTP09)
return process_header_end(req);
}
req->header_line = check;
} else if (req->status == BODY_READ) {
#ifdef VERY_FASCIST_LOGGING
...
retval = process_header_end(req);
#else
int retval = process_header_end(req);
#endif
if (retval && req->method == M_POST) {
req->header_line = check;
req->header_end =
req->client_stream + req->client_stream_pos;
req->status = BODY_WRITE;
if (req->content_length) {
content_length = boa_atoi(req->content_length);
if (content_length < 0) {
...
send_r_bad_request(req);
return 0;
}
if (single_post_limit
&& content_length > single_post_limit) {
...
send_r_bad_request(req);
return 0;
}
req->filesize = content_length;
req->filepos = 0;
if ((unsigned) (req->header_end - req->header_line) > req->filesize) {
req->header_end = req->header_line + req->filesize;
}
} else {
...
send_r_bad_request(req);
return 0;
}
}
return retval;
}
}
...
if (req->status < BODY_READ) {
buf_bytes_left = CLIENT_STREAM_SIZE - req->client_stream_pos;
if (buf_bytes_left < 1 || buf_bytes_left > CLIENT_STREAM_SIZE) {
...
req->response_status = 400;
req->status = DEAD;
return 0;
}
bytes =
read(req->fd, buffer + req->client_stream_pos, buf_bytes_left);
if (bytes < 0) {
if (errno == EINTR)
return 1;
else if (errno == EAGAIN || errno == EWOULDBLOCK)
return -1;
log_error_doc(req);
perror("header read");
req->response_status = 400;
return 0;
} else if (bytes == 0) {
if (req->kacount < ka_max &&
!req->logline &&
req->client_stream_pos == 0) {
;
} else {
...
}
req->response_status = 400;
return 0;
}
...
}
return 1;
}
return 1;
}
在src/request.c中的process_header_end是真正的处理函数,它对请求的uri进行简单的判断后调用translate_uri解析对应uri的虚拟路径,translate_uri中的init_script_alias会将虚拟路径转换成设备上真实的路径,比如请求的url是http://ip:port/cgi-bin/*.cgi,它将/cgi/bin/*.cgi拿出来然后加上etc/boa/WWW
int process_header_end(request * req)
{
if (!req->logline) {
...
send_r_error(req);
return 0;
}
if (unescape_uri(req->request_uri, &(req->query_string)) == 0) {
...
send_r_bad_request(req);
return 0;
}
clean_pathname(req->request_uri);
if (req->request_uri[0] != '/') {
...
return 0;
}
if (vhost_root) {
if (!req->header_host) {
req->host = strdup(default_vhost);
} else {
req->host = strdup(req->header_host);
}
if (!req->host) {
...
send_r_error(req);
return 0;
}
strlower(req->host);
c = strchr(req->host, ':');
if (c)
*c = '\0';
if (check_host(req->host) < 1) {
...
send_r_bad_request(req);
return 0;
}
}
// 解析uri虚拟路径
if (translate_uri(req) == 0) {
SQUASH_KA(req);
return 0;
}
if (req->method == M_POST) {
req->post_data_fd = create_temporary_file(1, NULL, 0);
if (req->post_data_fd == 0) {
send_r_error(req);
return 0;
}
if (fcntl(req->post_data_fd, F_SETFD, 1) == -1) {
...
req->post_data_fd = 0;
return 0;
}
return 1;
}
// 判断cgi类型后进行初始化
if (req->cgi_type) {
return init_cgi(req);
}
req->status = WRITE;
return init_get(req);
}
在src/cgi.c中的init_cgi就是根据上述translate_uri函数解析出来的uri路径进行执行
int init_cgi(request * req)
{
...
if (req->cgi_type) {
//添加环境变量
if (complete_env(req) == 0) {
return 0;
}
}
...
if (req->cgi_type == CGI ||
(!req->cgi_type &&
(req->pathname[strlen(req->pathname) - 1] == '/'))) {
use_pipes = 1;
if (pipe(pipes) == -1) {
...
return 0;
}
if (set_nonblock_fd(pipes[0]) == -1) {
...
close(pipes[0]);
close(pipes[1]);
return 0;
}
}
// fork子进程
child_pid = fork();
switch (child_pid) {
case -1:
boa_perror(req, "fork failed");
if (use_pipes) {
close(pipes[0]);
close(pipes[1]);
}
return 0;
break;
case 0:
reset_signals();
if (req->cgi_type == CGI || req->cgi_type == NPH) {
c = strrchr(req->pathname, '/');
if (!c) {
...
if (use_pipes)
close(pipes[1]);
_exit(EXIT_FAILURE);
}
*c = '\0';
if (chdir(req->pathname) != 0) {
...
if (use_pipes)
close(pipes[1]);
_exit(EXIT_FAILURE);
}
oldpath = req->pathname;
req->pathname = ++c;
l = strlen(req->pathname) + 3;
newpath = malloc(sizeof (char) * l);
if (!newpath) {
...
if (use_pipes)
close(pipes[1]);
_exit(EXIT_FAILURE);
}
newpath[0] = '.';
newpath[1] = '/';
memcpy(&newpath[2], req->pathname, l - 2);
free(oldpath);
req->pathname = newpath;
}
if (use_pipes) {
close(pipes[0]);
if (dup2(pipes[1], STDOUT_FILENO) == -1) {
...
_exit(EXIT_FAILURE);
}
close(pipes[1]);
} else {
if (dup2(req->fd, STDOUT_FILENO) == -1) {
...
_exit(EXIT_FAILURE);
}
close(req->fd);
}
if (set_block_fd(STDOUT_FILENO) == -1) {
...
_exit(EXIT_FAILURE);
}
if (req->method == M_POST) {
lseek(req->post_data_fd, SEEK_SET, 0);
dup2(req->post_data_fd, STDIN_FILENO);
close(req->post_data_fd);
}
...
umask(cgi_umask);
if (cgi_log_fd) {
dup2(cgi_log_fd, STDERR_FILENO);
}
if (req->cgi_type) {
...
create_argv(req, aargv);
// 启动cgi进程
execve(req->pathname, aargv, req->cgi_env);
} else {
if (req->pathname[strlen(req->pathname) - 1] == '/')
execl(dirmaker, dirmaker, req->pathname, req->request_uri,
(void *) NULL);
...
}
...
_exit(EXIT_FAILURE);
break;
default:
...
break;
}
return 1;
}
Boa例子:TOTOLink 某款路由器
/bin/boa就为它的整个后端处理程序,前面的初始化都大差不差,有部分自定义的函数如下:
asp_init(argc, argv) // 初始化网口
etopHttpIpHandle(ip) // 初始化服务器ip
etopshm_sem_init(3333); // 检查存储空间
etopChkAutoupdate(); // 检查自动更新
etopChkMib(); // 检查设备闪存配置
根据上节的描述很容易就找到处理请求的函数main -> loop -> process_requests -> read_header -> process_header_end,可以很清楚的看到很多uri
if ( strstr(uri, "active_sessions")
|| strstr(uri, "cgi_ssi_igmp_group_memberships")
|| strstr(uri, "dhcp_clients")
|| strstr(uri, "get_auto_wepkey")
|| strstr(uri, "get_ddns_status")
|| strstr(uri, "get_wifisc_pin")
|| strstr(uri, "interface_stats")
|| strstr(uri, "interface_stats_nowlan")
|| strstr(uri, "ssi_dns_resolve")
...
{
uri_correct = 1;
}
etopAspBypass(req, &uri_correct, &v28);
if ( uri_correct
|| (v11 = is_valid_user(req), v10 = 4784128, v11)
|| (v12 = strstr(uri, ".asp")) == 0
&& !strstr(uri, ".html")
&& !strstr(uri, ".htm")
&& !strstr(uri, "goform")
&& !strstr(uri, "gateway_settings.gws")
&& !strstr(uri, "Gatewaylog.txt") )
{
...
}
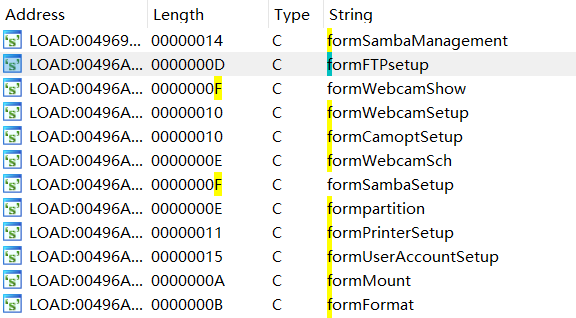
同时在translate_uri中也可以看到uri的前缀,这是Boa的常见接口的uri前缀,后面的接口通常都是以form开头,可以在IDA的Strings窗口搜到
if ( strstr((req + 252), "boafrm") )
OpenWrt中间模块uhttpd/lighttpd➕CGI/Lua
这种组合模式一般都会出现在腾达(Tenda),普联(TP-Link)和水星(MERCURY)的路由器上,TP-Link和水星都同属于一个公司,水星相当于TP-Link的小弟,所以这两家的路由器差不了太多,这种组成模式的WEB框架十分能体现MTV的WEB服务框架的模式,其实也和OpenWrt的开发模式差不多,具体可看《Flask · 从零开始构建一个简易的个人博客》,uhttpd 是一个 OpenWrt/LUCI 开发者从头编写的 Web 服务器, 它着力于实现一个稳定高效的服务器,能够满足嵌入式设备的轻量级任务需求。
uhttpd源码分析:通信模型
当有请求打到uhttpd上,最重要的就是路由,也就是流量最终会走向哪里,怎么定位到请求的资源,在main.c文件当中当中仅仅是对uhttpd服务进行初始化等一系列操作
int main(int argc, char **argv)
{
struct alias *alias;
bool nofork = false;
char *port;
int opt, ch;
int cur_fd;
int bound = 0;
...
BUILD_BUG_ON(sizeof(uh_buf) < PATH_MAX);
//添加cgi_dispatch到dispatch_handlers链表当中
uh_dispatch_add(&cgi_dispatch);
//初始化参数
init_defaults_pre();
//关闭信号量
signal(SIGPIPE, SIG_IGN);
//处理用户参数
while ((ch = getopt(argc, argv, "A:ab:C:c:Dd:E:e:fh:H:I:i:K:k:L:l:m:N:n:O:o:P:p:qRr:Ss:T:t:U:u:Xx:y:")) != -1) {
switch(ch) {
...
return run_server();
}
static int run_server(void)
{
uloop_init();
uh_setup_listeners();
uh_plugin_post_init();
uloop_run();
return 0;
}
当接收到流量之后,最先处理的就是client_parse_header,它是对请求数据包的头部进行简单的解析,如果存在数据就调用client_header_complete
static void client_parse_header(struct client *cl, char *data)
{
struct http_request *r = &cl->request;
char *err;
char *name;
char *val;
if (!*data) {
uloop_timeout_cancel(&cl->timeout);
cl->state = CLIENT_STATE_DATA;
client_header_complete(cl);
return;
}
val = uh_split_header(data);
if (!val) {
cl->state = CLIENT_STATE_DONE;
return;
}
for (name = data; *name; name++)
if (isupper(*name))
*name = tolower(*name);
if (!strcmp(data, "expect")) {
if (!strcasecmp(val, "100-continue"))
r->expect_cont = true;
else {
uh_header_error(cl, 412, "Precondition Failed");
return;
}
} else if (!strcmp(data, "content-length")) {
r->content_length = strtoul(val, &err, 0);
if ((err && *err) || r->content_length < 0) {
uh_header_error(cl, 400, "Bad Request");
return;
}
} else if (!strcmp(data, "transfer-encoding")) {
if (!strcmp(val, "chunked"))
r->transfer_chunked = true;
} else if (!strcmp(data, "connection")) {
if (!strcasecmp(val, "close"))
r->connection_close = true;
} else if (!strcmp(data, "user-agent")) {
char *str;
if (strstr(val, "Opera"))
r->ua = UH_UA_OPERA;
else if ((str = strstr(val, "MSIE ")) != NULL) {
r->ua = UH_UA_MSIE_NEW;
if (str[5] && str[6] == '.') {
switch (str[5]) {
case '6':
if (strstr(str, "SV1"))
break;
/* fall through */
case '5':
case '4':
r->ua = UH_UA_MSIE_OLD;
break;
}
}
}
else if (strstr(val, "Chrome/"))
r->ua = UH_UA_CHROME;
else if (strstr(val, "Safari/") && strstr(val, "Mac OS X"))
r->ua = UH_UA_SAFARI;
else if (strstr(val, "Gecko/"))
r->ua = UH_UA_GECKO;
else if (strstr(val, "Konqueror"))
r->ua = UH_UA_KONQUEROR;
}
blobmsg_add_string(&cl->hdr, data, val);
cl->state = CLIENT_STATE_HEADER;
}
client_header_complete对头部进行校验
static void client_header_complete(struct client *cl)
{
struct http_request *r = &cl->request;
if (!rfc1918_filter_check(cl))
return;
if (!tls_redirect_check(cl))
return;
if (r->expect_cont)
ustream_printf(cl->us, "HTTP/1.1 100 Continue\r\n\r\n");
switch(r->ua) {
case UH_UA_MSIE_OLD:
if (r->method != UH_HTTP_MSG_POST)
break;
/* fall through */
case UH_UA_SAFARI:
r->connection_close = true;
break;
default:
break;
}
uh_handle_request(cl);
}
uh_handle_request中的dispatch_find去分析对应的url,判断出是file-request、cgi-request或lua-request
void uh_handle_request(struct client *cl)
{
struct http_request *req = &cl->request;
struct dispatch_handler *d;
char *url = blobmsg_data(blob_data(cl->hdr.head));
char *error_handler, *escaped_url;
blob_buf_init(&cl->hdr_response, 0);
url = uh_handle_alias(url);
uh_handler_run(cl, &url, false);
if (!url)
return;
req->redirect_status = 200;
d = dispatch_find(url, NULL);
if (d)
return uh_invoke_handler(cl, d, url, NULL);
if (__handle_file_request(cl, url))
return;
if (uh_handler_run(cl, &url, true)) {
if (!url)
return;
uh_handler_run(cl, &url, false);
if (__handle_file_request(cl, url))
return;
}
req->redirect_status = 404;
if (conf.error_handler) {
error_handler = alloca(strlen(conf.error_handler) + 1);
strcpy(error_handler, conf.error_handler);
if (__handle_file_request(cl, error_handler))
return;
}
escaped_url = uh_htmlescape(url);
uh_client_error(cl, 404, "Not Found", "The requested URL %s was not found on this server.",
escaped_url ? escaped_url : "");
if (escaped_url)
free(escaped_url);
}
dispatch_find中的list_for_each_entry会遍历dispatch_handlers里面的链表也就是cgi.c下的cgi_dispatch结构体,通过check_cgi_path检查后,回调cgi_handle_request
static struct dispatch_handler *
dispatch_find(const char *url, struct path_info *pi)
{
struct dispatch_handler *d;
list_for_each_entry(d, &dispatch_handlers, list) {
if (pi) {
if (d->check_url)
continue;
if (d->check_path(pi, url))
return d;
} else {
if (d->check_path)
continue;
if (d->check_url(url))
return d;
}
}
return NULL;
}
cgi_handle_request会创建一个cgi_main进程
static void cgi_handle_request(struct client *cl, char *url, struct path_info *pi)
{
unsigned int mode = S_IFREG | S_IXOTH;
char *escaped_url;
if (!pi->ip && !((pi->stat.st_mode & mode) == mode)) {
escaped_url = uh_htmlescape(url);
uh_client_error(cl, 403, "Forbidden",
"You don't have permission to access %s on this server.",
escaped_url ? escaped_url : "the url");
if (escaped_url)
free(escaped_url);
return;
}
if (!uh_create_process(cl, pi, url, cgi_main)) {
uh_client_error(cl, 500, "Internal Server Error",
"Failed to create CGI process: %s", strerror(errno));
return;
}
return;
}
cgi_main最终去执行响应的cgi文件
static void cgi_main(struct client *cl, struct path_info *pi, char *url)
{
const struct interpreter *ip = pi->ip;
struct env_var *var;
clearenv();
setenv("PATH", conf.cgi_path, 1);
for (var = uh_get_process_vars(cl, pi); var->name; var++) {
if (!var->value)
continue;
setenv(var->name, var->value, 1);
}
if (!chdir(pi->root)) {
if (ip)
execl(ip->path, ip->path, pi->phys, NULL);
else
execl(pi->phys, pi->phys, NULL);
}
printf("Status: 500 Internal Server Error\r\n\r\n"
"Unable to launch the requested CGI program:\n"
" %s: %s\n", ip ? ip->path : pi->phys, strerror(errno));
}
最终调用的/www/cgi-bin/luci即LuCI,同时LuCI在/usr/lib/lua/luci/controller目录下的lua脚本包含请求url的相关路由信息,这些脚本中的index函数,最后启动/usr/lib/lua/luci/sgi/cgi.lua下的run函数
#!/usr/bin/lua
require "luci.cacheloader"
require "luci.sgi.cgi"
luci.dispatcher.indexcache = "/tmp/luci-indexcache"
luci.dispatcher.dataindexcache = "/tmp/luci-dataindexcache"
luci.sgi.cgi.run()
通过dispatch分发对应的.lua文件,再controller下的文件中在根据index()中entry方法对相应的路由进行匹配以及鉴权的判断,返回template模板,索引到对应的资源
function index()
...
entry({ "userrpm", "usermngr_user.htm" }, template("userrpm/usermngr_user")).leaf = true
entry({ "userrpm", "usermngr.htm" }, template("userrpm/usermngr")).leaf = true
entry({ "userrpm", "usermngr_backup.htm" }, template("userrpm/usermngr_backup")).leaf = true
...
end
下面对entry函数进行简单的分析,以某路由器的entry为例
function index()
entry({"admin", "status"}, alias("admin", "status", "overview"), _("Status"), 20).index = true
entry({"admin", "status", "overview"}, template("admin_status/index"), _("Overview"), 1)
entry({"admin", "status", "iptables"}, call("action_iptables"), _("Firewall"), 2).leaf = true
entry({"admin", "status", "processes"}, cbi("admin_status/processes"), _("Processes"), 6)
end
在index()函数中,使用entry函数来完成每个模块函数的注册,官方说明文档如下:
entry(path, target, title=nil, order=nil)
-
path 是一个描述调度树中位置的表:例如 {"foo", "bar", "baz"} 的路径会将您的节点插入 foo.bar.baz
-
target 描述了当用户请求节点时将采取的行动。 有几个预定义的,其中 3 个最重要的类型:调用(call)、模板 (template)、cbi
-
call
用来调用函数,即语句
entry({"admin", "status", "iptables"}, call("action_iptables"), _("Firewall"), 2),为调用action_iptables函数进行处理 -
template
用来调用已有的html模版,模版目录在
lua\luci\view目录下,即语句entry({"admin", "status", "overview"}, template("admin_status/index"), _("Overview"), 1),调用了lua\luci\view\admin_status\index.htm文件来显示 -
cbi
这是使用非常频繁也非常方便的模块,在cbi模块中定义各种控件,Luci系统会自动执行大部分处理工作,其链接目录在
lua\luci\model\cbi下,显然语句entry({"admin", "status", "processes"}, cbi("admin_status/processes"), _("Processes"), 6),调用lua\luci\model\cbi\admin_status\processes.lua来实现模块,这样我们可以发现,cbi模块可能是核心功能模块了,我们看看这个模块的使用 -
title 定义用户在菜单中可见的标题(可选)
-
order 是一个数字,将在菜单中对同一级别的节点进行排序(可选)
uhttpd例子:TP-Link WAR-450L Router
在/usr/lib/lua/luci目录下存在以下子目录,为MTV结构的核心
- Model为预处理数据层
- View为视图文件层
- Controller为路由和数据处理层
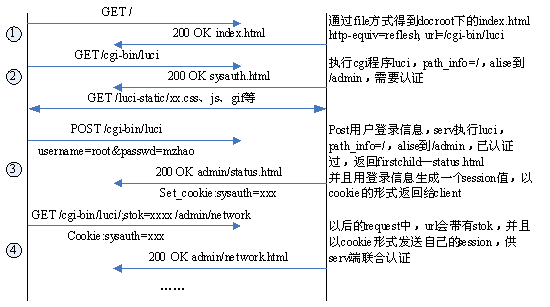
下面是访问某个后台功能时的数据包,/cgi-bin/luci/为启动的脚本,stok=为鉴权,/admin/xxx为请求的uri:
POST /cgi-bin/luci/;stok=.../admin/xxx?form=diag HTTP/1.1
Content-Length: 321
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
Referer: ...
Accept-Encoding: gzip, deflate
Accept-Language: zh-CN,zh;q=0e.9
Cookie: sysauth=...
Connection: close
下图为参考其他师傅的通信全流程: