最近一段时间都在审计 Java 代码,也算是积累了一些各式各样小技巧,但总感觉不够体系化。因此有必要先停下来,跳出业务逻辑并后退一步,更加深入地思考一下漏洞背后的成因。
前言
说到 URL 解析,想必关注 Web 安全的朋友们都看过 Orange 那篇 A New Era of SSRF - Exploiting URL Parser in Trending Programming Languages,其中对不同语言中的 URL Parser 做了较为详尽的分析。该议题主要关注不同 Parser 处理 URL 时的域名部分,以实现针对 SSRF 的绕过和后利用。
本文的关注点则有所不同,主要是针对 URL 解析的路径部分。因为 URL 的路径部分通常涉及到资源和服务的路由,以及对应的鉴权校验。通常我们在漏洞挖掘和渗透测试时都收集过一些鉴权绕过的 “Tricks”,但很多时候并不了解其所以然,每每测试结束后总觉得缺少了些什么。这些绕过的 payload 是否覆盖了所有场景?是否还有其他可能的变种?其实也不能完全肯定。
因此就有了这篇文章,一方面记录和整理笔者遇到过的鉴权绕过技巧,另一方面也尝试分析这些绕过背后的原理,希望对大家有所启发。
威胁模型
本文主要以 JavaEE 的 Web 网络框架举例,这是因为 Java 目前在国内有着庞大的使用率和 Web 生态。不过我相信在许多其他 Web 框架下如 PHP、NodeJS 中也是可以举一反三的。
回顾 Java 安全研究初探 一文中提到的 Java Web 应用的请求流程,大致可以抽象成如下的链路:
Client -> Filter_1 -> Filter_2 -> ... -> Filter_n -> Servlet
即客户端的请求会经过一个或者多个 Filter,然后再到达实际处理请求的 Servlet 中。通常 Filter 以级联方式运作,称为 FilterChain,而出于低耦合的设计模式考虑,开发者一般会将重要的鉴权逻辑放在 Filter 中实现。一旦认证失败,可以提前终止请求,这对于 Servlet 而言是透明的。
因此,所谓的鉴权绕过,很多情况下就是鉴权 Filter 中的逻辑错误。而 Filter 中的鉴权,大部分情况下也是 URL 粒度的鉴权,毕竟在一个网站中总是会有无需认证的前台界面(如登录界面),以及需要认证的后台服务(如管理后台)。
从代码上看,Filter 中鉴权使用的多是 HttpServletRequest.getRequestURI() 接口,判断对应路径是否需要鉴权,如果需要则进行 Session 的判断和认证,对于鉴权失败的请求则返回 403 拒绝访问或者 302 跳转到登录界面。
绕过 Filter 中的 URL 的鉴权认证只是第一步,而更为重要的一步是如何在构造畸形 URL 的同时依然能寻址到正确的 Servlet,从而正确处理业务请求。因此本文也正是从这两方面出发,分别探寻 URL 解析中的隐秘。
Servlet 容器
首先要明确的是,不管构造的 URL 再怎么花里胡哨,如果 URL 路径寻址不到正确的 Servlet,那都是没有意义的,只能获得一个空虚的 404 聊以自慰。因此我们先从 Servlet 的寻址开始,尝试在正常寻址的基础上进行变异。
URL 的路由在不同的 Servlet 容器中的实现各不相同,这里仅选择两个笔者最近在看的容器去进行分析。
Tomcat
首先是最常见的 Tomcat 容器。关于 Tomcat 的源码分析在网上已经有过很多文章了,我们只需要关注其中 URL 到业务代码的路由映射过程。最简单的方式就是使用调试器在 Servlet 中打上一个断点去反向追踪源码的相关部分。业务代码如下:
@WebServlet(name = "flagServlet", value = "/api/flag")
public class FlagServlet extends HttpServlet {
public void doGet(HttpServletRequest request, HttpServletResponse response) throws IOException {
PrintWriter out = response.getWriter();
out.println(String.format("YOU WIN: [%s]", request.getRequestURI()));
}
}
在成功访问后返回请求的 RequestURI 的值。在 doGet 打个断点,请求 /api/flag 后触发的堆栈信息如下:
doGet:17, FlagServlet (com.example.tc)
service:529, HttpServlet (javax.servlet.http)
service:623, HttpServlet (javax.servlet.http)
internalDoFilter:209, ApplicationFilterChain (org.apache.catalina.core)
doFilter:153, ApplicationFilterChain (org.apache.catalina.core)
doFilter:51, WsFilter (org.apache.tomcat.websocket.server)
internalDoFilter:178, ApplicationFilterChain (org.apache.catalina.core)
doFilter:153, ApplicationFilterChain (org.apache.catalina.core)
doFilter:20, AdminFilter (com.example.tc)
doFilter:53, HttpFilter (javax.servlet.http)
internalDoFilter:178, ApplicationFilterChain (org.apache.catalina.core)
doFilter:153, ApplicationFilterChain (org.apache.catalina.core)
invoke:167, StandardWrapperValve (org.apache.catalina.core)
invoke:90, StandardContextValve (org.apache.catalina.core)
invoke:481, AuthenticatorBase (org.apache.catalina.authenticator)
invoke:130, StandardHostValve (org.apache.catalina.core)
invoke:93, ErrorReportValve (org.apache.catalina.valves)
invoke:673, AbstractAccessLogValve (org.apache.catalina.valves)
invoke:74, StandardEngineValve (org.apache.catalina.core)
service:343, CoyoteAdapter (org.apache.catalina.connector)
service:390, Http11Processor (org.apache.coyote.http11)
process:63, AbstractProcessorLight (org.apache.coyote)
process:926, AbstractProtocol$ConnectionHandler (org.apache.coyote)
doRun:1791, NioEndpoint$SocketProcessor (org.apache.tomcat.util.net)
run:52, SocketProcessorBase (org.apache.tomcat.util.net)
runWorker:1191, ThreadPoolExecutor (org.apache.tomcat.util.threads)
run:659, ThreadPoolExecutor$Worker (org.apache.tomcat.util.threads)
run:61, TaskThread$WrappingRunnable (org.apache.tomcat.util.threads)
run:829, Thread (java.lang)
注: 这里使用的 Tomcat 为 9.0.78 版本,是文章编写时 Tomcat9 的最新版本。之所以选择 Tomcat9 而不是 Tomcat10 是因为目前其存量应用相对较多(听说)。
CoyoAdaptor
AdminFilter 是我自己写的一个 Filter,这里先无需在意。Tomcat 在进入第一个 FIlter 之前就已经确定了路由的目标。注意上述调用栈中的 CoyoteAdapter,实际方法为 org.apache.catalina.connector.CoyoteAdapter#service:
@Override
public void service(org.apache.coyote.Request req, org.apache.coyote.Response res) throws Exception {
// ...
postParseSuccess = postParseRequest(req, request, res, response);
if (postParseSuccess) {
// Calling the container
connector.getService().getContainer().getPipeline().getFirst().invoke(request, response);
}
}
postParseRequest 的调用时机是在 TCP 的 HTTP 请求头接收完之后,并且在 Body 读取之前,也正是在其中处理了 URL 的映射。在 Tomcat 中请求对应的路由是存放在 request.mappingData 中的。对于上述请求,会依次调用:
- postParseRequest
- org.apache.catalina.mapper.Mapper#map
- org.apache.catalina.mapper.Mapper#internalMap
internalMap 的关键代码片段如下:
private void internalMap(CharChunk host, CharChunk uri, String version, MappingData mappingData) throws IOException {
if (uri.isNull()) {
// Can't map context or wrapper without a uri
return;
}
uri.setLimit(-1);
// Context mapping
ContextList contextList = mappedHost.contextList;
MappedContext[] contexts = contextList.contexts;
int pos = find(contexts, uri);
if (pos == -1) {
return;
}
// Wrapper mapping
if (!contextVersion.isPaused()) {
internalMapWrapper(contextVersion, uri, mappingData);
}
}
contexts 数组中包含一系列 org.apache.catalina.mapper.Mapper.MappedContext#MappedContext,表示 URL 路由的上下文,说简单点就是 URL 的前缀。一般一个 Context 前缀代表一个 JavaEE 应用,在 Tomcat 中其实还注册了几个默认的应用,对应的前缀(ContextRoot)分别是:
- /docs
- /examples
- /manager
- /host-manager
我们这次请求的 URI 为 /api/flag,且部署的 ContextRoot 为空,因此命中的就是我们的应用。一个完整的 URL 如下所示:
http://host:port/context-root[/url-pattern]
如果 ContextRoot 为 /demo 的话,示例的 Servlet 会映射到 /demo/api/flag。
Mapper
定位到 context 之后,接下来就是在对应 context 下查找具体的路由。这个过程称为 “Wrapper mapping”,Wrapper 可以理解为 Servlet 的封装。所调用的方法为 org.apache.catalina.mapper.Mapper#internalMapWrapper。
关键代码如下:
private void internalMapWrapper(ContextVersion contextVersion, CharChunk path, MappingData mappingData) throws IOException {
// Rule 1 -- Exact Match
MappedWrapper[] exactWrappers = contextVersion.exactWrappers;
internalMapExactWrapper(exactWrappers, path, mappingData);
// Rule 2 -- Prefix Match
MappedWrapper[] wildcardWrappers = contextVersion.wildcardWrappers;
if (mappingData.wrapper == null) {
internalMapWildcardWrapper(wildcardWrappers, contextVersion.nesting, path, mappingData);
}
// Rule 3 -- Extension Match
MappedWrapper[] extensionWrappers = contextVersion.extensionWrappers;
if (mappingData.wrapper == null && !checkJspWelcomeFiles) {
internalMapExtensionWrapper(extensionWrappers, path, mappingData, true);
}
// Rule 4 -- Welcome resources processing for servlets
// Rule 4a -- Welcome resources processing for exact macth
// Rule 4b -- Welcome resources processing for prefix match
// Rule 4c -- Welcome resources processing
/*
* welcome file processing - take 2 Now that we have looked for welcome files with a physical backing, now look
* for an extension mapping listed but may not have a physical backing to it. This is for the case of index.jsf,
* index.do, etc. A watered down version of rule 4
*/
// Rule 7 -- Default servlet
}
在深入代码之前,我们先插播一条关于 JavaEE Servlet 标准的回忆录。
Servlet 标准
在前面的文章也简单提到过,Servlet 映射查找是依据 JSR 340: Java Servlet 3.1 Specification 中的第 12 章 Mapping Requests to Servlets 的介绍而实现的。其中关键的寻址逻辑笔者总结如下:
- 首先尝试查找 Servlet 路由的 精确匹配;
- 递归查找最长前缀匹配,以
/字符为每一级目录树的分隔,即前缀匹配的单位是目录; - 如果 URL 路径的最后一个片段(Segment)包含后缀,容器会尝试使用后缀匹配对应的 Servlet,比如对于
.jsp后缀使用JspServlet; - 如果上述规则都没有成功匹配,容器将会尝试根据请求的 URL 去匹配对应的资源,这通常会使用一个容器自带的默认 Servlet 去处理。
在标准中还提到了几个值得注意的点:
- 在匹配 ContextRoot 的时候也是使用最长前缀匹配;
- 在 URL 进行匹配时候都是 大小写敏感的;
对于配置映射的 <url-pattern>,有以下规则:
- 映射值以
/开头且以/*结尾的用于前缀匹配映射; - 映射值以
*.开头的使用后缀匹配; - 空字符是一个特殊的映射值,指向 context-root;
- 仅包含字符
/的映射值表示对应应用的默认 Servlet; - 其他所有的值都被认为是精确匹配;
因此,对于应用中定义的不同映射,都可以根据寻址逻辑按照顺序找到最佳的匹配。
Wrappers
回忆杀结束,继续回到上述 internalMapWrapper 的代码中。按照查找的顺序,Tomcat 会依次从下面的 Wrapper 中进行匹配:
- exactWrappers: 用于精确匹配的 Wrapper,比如值为
/api/flag的 FlagServlet; - wildcardWrappers: 用于(最长)前缀匹配的通配符 Wrapper,比如值为
/admin/*的 Servlet; - extensionWrappers: 用于后缀匹配的 Wrapper,比如值为
*.txt的 Servlet。在 Tomcat 中默认有两个,分别是jsp和jspx,都对应org.apache.jasper.servlet.JspServlet; - welcomeResources: 如果 URL 的最后一个字符是
/,则会尝试匹配欢迎页面,默认是index.html、index.htm、index.jsp;对于没有物理文件的欢迎页面,比如index.do、index.jsf等,会根据后缀匹配的方式在内置资源文件中查找; - defaultWrapper: 在前面都没有匹配的情况下,使用 Tomcat 的默认 Servlet 去进行处理,对应类是
org.apache.catalina.servlets.DefaultServlet,用于请求磁盘文件或者 jar 包中的文件。
大体来说,每一个 Servlet 对应一个 Wrapper 实例,而根据 URL 查找 Wrapper 的过程也就是对应 Servlet 路由查找的过程。
decodeURI
值得注意的是,在进行 Wrapper 查找的时候,所使用的 uri 是已经进行过处理的,还是在 CoyoteAdapter#postParseRequest 方法中:
protected boolean postParseRequest(){
MessageBytes decodedURI = req.decodedURI();
// Parse (and strip out) the path parameters
parsePathParameters(req, request);
// URI decoding
// %xx decoding of the URL
req.getURLDecoder().convert(decodedURI.getByteChunk(),
connector.getEncodedSolidusHandlingInternal());
// Normalization
if (normalize(req.decodedURI())) {
// Character decoding
convertURI(decodedURI, request);
}
}
decodedURI 只是 req.decodedUriMB 的一个指针(引用),在后续处理中有时没有直接指定 decodeURI 而是使用了 req 进行传参,但效果都是对 decodedURI 进行修改。
首先是第一步,parsePathParameters,该方法会解析 Path Parameter 即路径参数,后面介绍 URL 标准文档的时候会详细说到。路径参数是针对每一级 URL 目录的参数,形如 /api;a=b/flag;c=d,使用 分号 ; 进行指定,并以等号 = 指定 key 和 value。解析路径参数之后会将其使用 Request.addPathParameter 加入到请求信息中,并且将其从 decodeURI 中删除。
第二步,URL Decode,正常的 URL 解码。
第三步,Normalization,主要针对 URL 中包含 "\", "//", "/./" 以及 "/../" 的情况,操作过程如下:
1. 将 \ 替换为 /;
2. 将 // 替换为 /;
3. 对于 /. 或者 /.. 结尾的 URI,先在末尾额外添加一个 /;
4. 递归解析 URI 中的 /./ 字符串,将其替换为 /;
5. 递归解析 URI 中的 /../ 字符串,移动相应的目录;
在解析 /../ 时如果超出了根目录会直接返回 false。此外一些其他的错误也会返回 false,比如 CoyoteAdapter#ALLOW_BACKSLASH 为 false 却包含反斜杠,路径不以 / 或者 \ 开头等。
第四步,Character decoding,使用 convertURI 对路径进行字符解码。因为此时的路径还是以 ByteChunk 的格式进行存储的,这一步会将其转换为 CharChunk;
在依次经过上述处理后,最终的 URI 才会用来进行 Servlet 路由查找。
Bypass Tricks
据此,我们可以得到一系列 “Bypass Tricks”,即用不同的方式路由到同一个 Servlet 中,比如目标路由是 /api/flag 的话,以下请求都能寻址到目标:
/api;a=b/flag: 通过 Path Parameter 路径参数变异;/api/%66%6C%61%67: 通过 URL 编码进行变异;\api\flag: 通过 Normalization 1 变异,当前需要 Tomcat 配置ALLOW_BACKSLASH为true;//api/flag: 通过 Normalization 2/3 变异;/api/./flag: 通过 Normalization 4 变异;/foo/api/../api/flag: 通过 Normalization 5 变异;
这些变异方法可以相互组合进行使用,另外配合 DefaultServlet 针对磁盘文件和资源的路由也可以组合出其他的 URI。
Resin
虽然 Tomcat 相对常用,但实际场景中也有许多其他的 Web 容器实现。正所谓兼听则明,偏信则暗,因此这里选取另外一个 Web 容器 Resin 作为对比,看看二者对 URL 的处理和路由有何异同。之所以选择 Resin 只不过是因为笔者最近正好看到而已。
这里选择的 Resin 版本是 4.0.58
还是老方法,直接在 Servlet 中下断点,观察 Resin 的请求调用栈如下:
doGet:17, FlagServlet (com.example.resin)
service:120, HttpServlet (javax.servlet.http)
service:97, HttpServlet (javax.servlet.http)
doFilter:109, ServletFilterChain (com.caucho.server.dispatch)
doFilter:21, AdminFilter (com.example.resin)
doFilter:127, HttpFilter (javax.servlet.http)
doFilter:89, FilterFilterChain (com.caucho.server.dispatch)
doFilter:156, WebAppFilterChain (com.caucho.server.webapp)
doFilter:95, AccessLogFilterChain (com.caucho.server.webapp)
service:304, ServletInvocation (com.caucho.server.dispatch)
handleRequest:840, HttpRequest (com.caucho.server.http)
dispatchRequest:1367, TcpSocketLink (com.caucho.network.listen)
handleRequest:1323, TcpSocketLink (com.caucho.network.listen)
handleRequestsImpl:1307, TcpSocketLink (com.caucho.network.listen)
handleRequests:1215, TcpSocketLink (com.caucho.network.listen)
handleAcceptTaskImpl:1011, TcpSocketLink (com.caucho.network.listen)
runThread:117, ConnectionTask (com.caucho.network.listen)
run:93, ConnectionTask (com.caucho.network.listen)
handleTasks:175, SocketLinkThreadLauncher (com.caucho.network.listen)
run:61, TcpSocketAcceptThread (com.caucho.network.listen)
runTasks:173, ResinThread2 (com.caucho.env.thread2)
run:118, ResinThread2 (com.caucho.env.thread2)
前部分的调用为 FilterChain 调用,逐个调用已注册的 Filter。进入第一个 Filter 之前的调用为我们关心的路由解析完成之时。其方法为 com.caucho.server.http.HttpRequest#handleRequest,大致调用代码如下:
public boolean handleRequest() throws IOException {
startRequest();
if (! parseRequest()) {
return false;
}
CharSequence host = getInvocationHost();
Invocation invocation = getInvocation(host, _uri, _uriLength);
startInvocation();
invocation.service(requestFacade, getResponseFacade());
}
其中,startRequest 方法会读取 _uri、_headerKeys、_headerValues 等属性;parseRequest 将 buffer 中的请求方法、URI、HTTP 协议以及后续的 HTTP 头逐行解析并保存。
在 readRequest 即 HTTP 的第一行时读取 URI,有相关的代码片段:
// skip 'http:'
if (ch != '/') {
}
// read URI
while (! isHttpWhitespace[ch]) {
uriBuffer[uriLength++] = (byte) ch;
if (readTail <= readOffset) {
uriBuffer = _uri;
uriLength = _uriLength;
}
ch = readBuffer[readOffset++] & 0xff;
}
其中如果第一个字符不是 / 会跳到 URL 路径中进行读取。
Invocation
与 Tomcat 的 Wrapper 对应的数据结构在 Resin 中称为 Invocation,获得了 Invocation 也就获得了对应 Servlet 的路由映射。因此我们重点关注 getInvocation 方法的实现,调用过程如下:
- com.caucho.server.http.AbstractHttpRequest#getInvocation
- com.caucho.server.dispatch.InvocationServer#getInvocation
- com.caucho.util.LruCache#get
- com.caucho.server.http.AbstractHttpRequest#buildInvocation
简单来说,AbstractHttpRequest#getInvocation 会先尝试从 InvocationServer._invocationCache 缓存中获取 Invocation 对象,如果不存在则会使用 buildInvocation 新建一个并放入缓存中。_invocationCache 是个 LRU 缓存,键为 com.caucho.server.http.InvocationKey 类型。InvocationKey 中包含 host、port、uri 三元组以及 isSecure 标志位,这么做的好处是节约路由查找时间,对于大型项目而言路由映射往往成百上千,每次请求都进行查找显然比较耗时。
- com.caucho.server.http.AbstractHttpRequest#buildInvocation
- com.caucho.server.dispatch.InvocationDecoder#splitQueryAndUnescape
splitQueryAndUnescape 中对 Invocation 的 URI 进行了处理和赋值,代码比较重要,所以这里直接把完整的代码贴出来:
public void splitQueryAndUnescape(Invocation invocation,
byte []rawURI, int uriLength)
throws IOException
{
for (int i = 0; i < uriLength; i++) {
if (rawURI[i] == '?') {
i++;
// XXX: should be the host encoding?
String queryString = byteToChar(rawURI, i, uriLength - i,
"ISO-8859-1");
invocation.setQueryString(queryString);
uriLength = i - 1;
break;
}
}
String rawURIString = byteToChar(rawURI, 0, uriLength, "ISO-8859-1");
invocation.setRawURI(rawURIString);
String decodedURI = normalizeUriEscape(rawURI, 0, uriLength, _encoding);
if (_sessionSuffix != null) {
int p = decodedURI.indexOf(_sessionSuffix);
if (p >= 0) {
int suffixLength = _sessionSuffix.length();
int tail = decodedURI.indexOf(';', p + suffixLength);
String sessionId;
if (tail > 0)
sessionId = decodedURI.substring(p + suffixLength, tail);
else
sessionId = decodedURI.substring(p + suffixLength);
decodedURI = decodedURI.substring(0, p);
invocation.setSessionId(sessionId);
p = rawURIString.indexOf(_sessionSuffix);
if (p > 0) {
rawURIString = rawURIString.substring(0, p);
invocation.setRawURI(rawURIString);
}
}
}
else if (_sessionPrefix != null) {
if (decodedURI.startsWith(_sessionPrefix)) {
int prefixLength = _sessionPrefix.length();
int tail = decodedURI.indexOf('/', prefixLength);
String sessionId;
if (tail > 0) {
sessionId = decodedURI.substring(prefixLength, tail);
decodedURI = decodedURI.substring(tail);
invocation.setRawURI(rawURIString.substring(tail));
}
else {
sessionId = decodedURI.substring(prefixLength);
decodedURI = "/";
invocation.setRawURI("/");
}
invocation.setSessionId(sessionId);
}
}
String uri = normalizeUri(decodedURI);
invocation.setURI(uri);
invocation.setContextURI(uri);
}
提炼一下关键点,URI 的处理流程如下:
- 找到第一个
?符号并将之后的设置为 queryString; normalizeUriEscape: 对路径进行 URI 解码;sessionSuffix提取: 如果 URI 末尾的路径参数是对应的后缀,则从中提取并设置 SessionID,默认的后缀是;jsessionid。注意此时 sessionid 参数及其之后的数据都会从rawURI中移除;sessionPrefix提取: 默认为空即不需要操作;normalizeUri: 对路径进行归一化操作,后面细说;
normalizeUriEscape 的 URL 解码除了传统的 %dd 解码,还支持 Resin 特殊的 URL 编码,其实现如下:
private static int scanUriEscape(ByteToChar converter,
byte []rawUri, int i, int len)
throws IOException
{
int ch1 = i < len ? (rawUri[i++] & 0xff) : -1;
if (ch1 == 'u') {
ch1 = i < len ? (rawUri[i++] & 0xff) : -1;
int ch2 = i < len ? (rawUri[i++] & 0xff) : -1;
int ch3 = i < len ? (rawUri[i++] & 0xff) : -1;
int ch4 = i < len ? (rawUri[i++] & 0xff) : -1;
converter.addChar((char) ((toHex(ch1) << 12) +
(toHex(ch2) << 8) +
(toHex(ch3) << 4) +
(toHex(ch4))));
}
else {
int ch2 = i < len ? (rawUri[i++] & 0xff) : -1;
int b = (toHex(ch1) << 4) + toHex(ch2);;
converter.addByte(b);
}
return i;
}
即 %u0067 这种类型的解码。
注意这里处理完后的 URI 除了删除 jsessionid,依然带有其他的 Path Parameter 路径参数,这部分处理要在后面进行操作。不过在此之前还是按顺序先看 normalizeUri 的实现。
normalizeUri
从参数来看,InvocationDecoder.normalizeUri 的实现会根据当前 JVM 运行的操作系统来执行不同的归一化操作,由于这是我们 URI 变异的重点,因此直接将完整的方法实现贴出来:
public String normalizeUri(String uri, boolean isWindows)
throws IOException
{
CharBuffer cb = new CharBuffer();
int len = uri.length();
if (_maxURILength < len)
throw new BadRequestException(L.l("The request contains an illegal URL because it is too long."));
char ch;
if (len == 0 || (ch = uri.charAt(0)) != '/' && ch != '\\')
cb.append('/');
for (int i = 0; i < len; i++) {
ch = uri.charAt(i);
if (ch == '/' || ch == '\\') {
dots:
while (i + 1 < len) {
ch = uri.charAt(i + 1);
if (ch == '/' || ch == '\\')
i++;
else if (ch != '.')
break dots;
else if (len <= i + 2
|| (ch = uri.charAt(i + 2)) == '/' || ch == '\\') {
i += 2;
}
else if (ch != '.')
break dots;
else if (len <= i + 3
|| (ch = uri.charAt(i + 3)) == '/' || ch == '\\') {
int j;
for (j = cb.length() - 1; j >= 0; j--) {
if ((ch = cb.charAt(j)) == '/' || ch == '\\')
break;
}
if (j > 0)
cb.setLength(j);
else
cb.setLength(0);
i += 3;
} else {
throw new BadRequestException(L.l("The request contains an illegal URL."));
}
}
while (isWindows && cb.getLength() > 0
&& ((ch = cb.getLastChar()) == '.' || ch == ' ')) {
cb.setLength(cb.getLength() - 1);
if (cb.getLength() > 0
&& (ch = cb.getLastChar()) == '/' || ch == '\\') {
cb.setLength(cb.getLength() - 1);
// server/003n
continue;
}
}
cb.append('/');
}
else if (ch == 0)
throw new BadRequestException(L.l("The request contains an illegal URL."));
else
cb.append(ch);
}
while (isWindows && cb.getLength() > 0
&& ((ch = cb.getLastChar()) == '.' || ch == ' ')) {
cb.setLength(cb.getLength() - 1);
}
return cb.toString();
}
如无特别说明则认为分隔符是 / 或者 \。 这里实现路径归一化的算法是新建一个 CharBuffer,然后逐字符解析 URI,对于正常字符直接加入到 cb 中,而遇到分隔符后需要考虑特殊的情况。
- 首先如果 URI 首个字母不是分隔符,则会先在 cb 中添加
/; - 对于遇到分隔符的情况:
- 如果后 1 个字符还是分隔符,则往前进 2 个字符;
- 如果后 2 个字符是
.+ 分隔符,则往前进 2 个字符; - 如果后 3 个字符是
..+ 分隔符,则往前进 3 个字符,并且 cb 中回退一级目录,如果超出了根目录会将 cb 置空;如果后 2 个字符是..但第 3 个字符不是分隔符,会直接抛异常; - 其他情况下 cb 中添加一个分隔符
/; 但是在添加之前,对于 Windows 系统,如果 cb 中末尾的字符是.或者空格,会将其删除,同时会删除末尾的分隔符; - 对于其他字符,直接加入 cb 中;
- 遍历完成后,对于 Windows 系统,删除 cb 中末尾的
.和空格;
这里 normallize 方法的实现还是比较特别的,据此我们可以得到一些特殊的变异方式,具体在后文提及。
ServletMapper
前面获取到 Invocation 中的 URI 经过了 URL 解码和路径归一化,随后调用 InvocationServer#buildInvocation 获取对应 Server 的 Invocation 实例。最终会进入到 ServletMapper 的 mapServlet 进行 Servlet 映射查找。其中经过了 Host、Container 以及 WebApp 的查找,调用栈如下:
mapServlet:234, ServletMapper (com.caucho.server.dispatch)
buildInvocation:4154, WebApp (com.caucho.server.webapp)
buildInvocation:798, WebAppContainer (com.caucho.server.webapp)
buildInvocation:753, Host (com.caucho.server.host)
buildInvocation:319, HostContainer (com.caucho.server.host)
buildInvocation:1064, ServletService (com.caucho.server.cluster)
buildInvocation:250, InvocationServer (com.caucho.server.dispatch)
buildInvocation:223, InvocationServer (com.caucho.server.dispatch)
buildInvocation:1610, AbstractHttpRequest (com.caucho.server.http)
getInvocation:1583, AbstractHttpRequest (com.caucho.server.http)
handleRequest:822, HttpRequest (com.caucho.server.http)
mapServlet 是实际进行 Servlet 查找的实现,其大致代码如下:
public FilterChain mapServlet(ServletInvocation invocation) throws ServletException {
String servletName = null;
String contextURI = invocation.getContextURI();
if (_servletMap != null) {
cleanUri = Invocation.stripPathParameters(contextURI);
ServletMapping servletMap = _servletMap.map(cleanUri, vars);
if (servletMap != null) {
servletName = servletMap.getServletName();
}
}
if (servletName == null) {
InputStream is;
is = _webApp.getResourceAsStream(contextURI);
if (is != null) {
is.close();
servletName = _defaultServlet;
}
}
MatchResult matchResult = null;
if (matchResult == null && contextURI.endsWith("j_security_check")) {
servletName = "j_security_check";
}
if (servletName == null) {
servletName = _defaultServlet;
vars.clear();
if (matchResult != null)
vars.add(matchResult.getContextUri());
else
vars.add(contextURI);
addWelcomeFileDependency(invocation);
}
if (servletName == null) {
log.fine(L.l("'{0}' has no default servlet defined", contextURI));
return new ErrorFilterChain(404);
}
String servletPath = vars.get(0);
invocation.setServletPath(servletPath);
invocation.setPathInfo(/*...*/);
if (servletName.equals("invoker"))
servletName = handleInvoker(invocation);
invocation.setServletName(servletName);
ServletConfigImpl newConfig = _servletManager.getServlet(servletName);
if (newConfig != null) config = newConfig;
FilterChain chain = _servletManager.createServletChain(servletName, config, invocation);
if (chain instanceof PageFilterChain) {
PageFilterChain pageChain = (PageFilterChain) chain;
chain = PrecompilePageFilterChain.create(invocation, pageChain);
}
return chain;
}
按照执行顺序,简单总结一下:
- 首先使用
ServletInvocation#stripPathParameters删除前面提到剩下的路径参数,即删除;到/之间或者到 URI 末尾的内容,得到的cleanUri是最终用于路由查找的 URI; - 使用
_servletMap.map查找对应的 Servlet; - 如果没找到,使用
_webApp.getResourceAsStream查找对应磁盘文件或者资源文件是否存在,_defaultServlet为resin-file; - 如果 contextURI 以
j_security_check结尾,则路由到名称为j_security_check的 Servlet; - 最后查找 welcom file,默认包括
index.html、index.jsp和index.php;
_servletMap 是 UrlMap<ServletMapping> 类型,其中有一个 RegexEntry 数组,包含了所有(当前应用)已经注册的 Servlet 映射和路由。
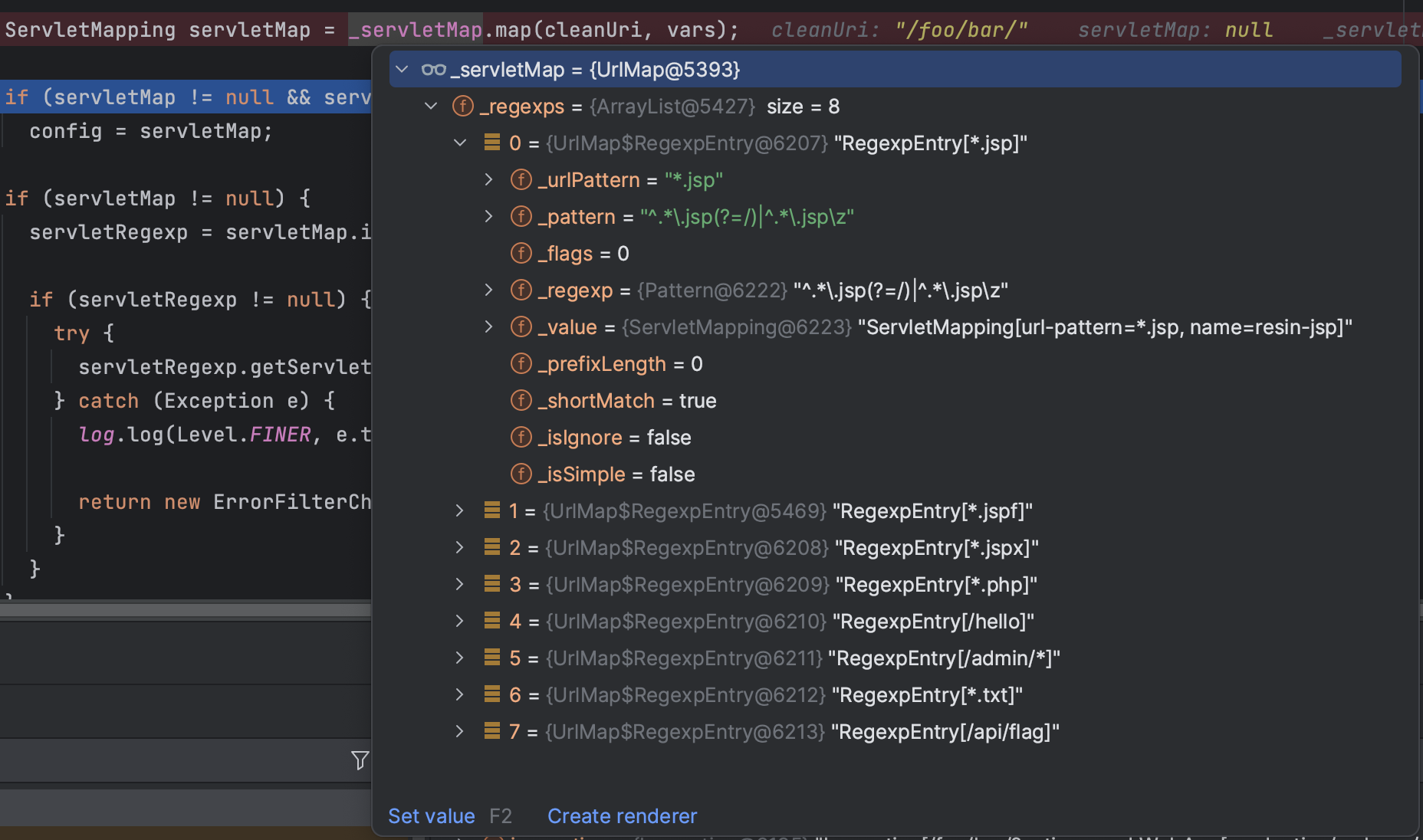
在 Resin 中,每个路由都使用正则表达式来进行匹配,如果多个 Servlet 都匹配中了同一个 URI,则会根据匹配的精度选择最佳结果,从而符合 Java EE Servlet 标准中的路由映射定义。
- 对于精确匹配,比如
/hello,对应的正则是^/hello$; - 对于路径匹配,比如
/admin/*,对应的正则是^/admin(?=/)|^/admin\z; - 对于后缀匹配,比如
*.jsp,对应的正则是^.*\.jsp(?=/)|^.*\.jsp\z;
其中精确匹配的末尾是 $,而后缀匹配的末尾是 \z,这二者有何不同?经过翻阅文档得知,\z 表示字符串末尾,而 $ 表示行末,因此 \z 可以匹配换行符而 $ 不能!
继续往下看,getResourceAsStream 查找磁盘或者资源文件的实现如下:
public InputStream getResourceAsStream(String uripath)
{
Path rootDirectory = getRootDirectory();
Path path = rootDirectory.lookupNative(getRealPath(uripath));
if (path.canRead())
return path.openRead();
else {
String resource = "META-INF/resources" + uripath;
return getClassLoader().getResourceAsStream(resource);
}
}
这和预料中的差不多,后面确定 Servlet 都使用了字符串名称,比如 resin-file、j_security_check,实际查找是通过 _servletManager.getServlet(servletName) 获取对应的 Servlet 实例,由此我们得知 ServletManager#_servlets 字典中保存了所有注册的 Servlet:
- j_security_check -> com.caucho.server.security.FormLoginServlet
- resin-xtp -> com.caucho.jsp.XtpServlet
- resin-jsp -> com.caucho.jsp.JspServlet
- resin-jspx -> com.caucho.jsp.JspServlet
- resin-file -> com.caucho.servlets.FileServlet
- resin-xtp -> com.caucho.jsp.XtpServlet -> com.caucho.quercus.servlet.QuercusServlet
- Hello -> com.example.resin.HelloServlet
- txtServlet -> com.example.resin.TxtServlet
- flagServlet -> com.example.resin.FlagServlet
- adminServlet -> com.example.resin.AdminServlet
后四个是笔者自己写的 Servlet,其他的都是 Resin 默认添加的。默认的 Servlet resin-file 对应 FileServlet,也负责读取静态文件或者资源的 Servlet。至此就完成了 Servlet 的查找和映射,随后只需要构建 FilterChain 并逐级调用 Filter 后即可到达对应的业务代码中。
Bypass Tricks
类似于 Tomcat,根据对上述 Resin 源码的分析,我们也可以得出一些 Bypass Tricks,在原始 URI /api/flag 的基础上进行变异以实现正常路由到相同 Servlet 的目的:
hack/api/flag: 基于readRequest中判断 URI 的第一个字符不为/的变异;/api/fla%67: 基于normalizeUriEscape解码的变异;/api/fla%u0067: 基于scanUriEscape中特殊 URL 编码的变异;/api//flag: 基于normalizeUri2.1 的变异;/api/./flag: 基于normalizeUri2.2 的变异;../api/flag: 基于normalizeUri2.3 的变异;/api\flag: 基于normalizeUri2.4 的变异,对于分隔符都会转换为/;/api/flag%20(空格),/api/flag.: 基于normalizeUri2.4 的变异,仅在 Windows 系统中有效;/api/flag;a=b: 针对stripPathParameters的变异;/api/flag%0a: 基于正则表达式$不匹配换行的变异;
这些变异可以组合使用,从而形成更加丰富的 URI 结果。
小结
通过分析 Tomcat 和 Resin 的 URI 解析流程,我们可以发现很多共同点,比如都会进行 URL Decode、都会进行路径归一化以及删除路径参数。同时值得注意的是不同的 Web 容器实现上又有一定差异,比如 Tomcat 在路径归一化时超出根目录的会报错,而 Resin 则会静默保留到根目录;Tomcat 与 Resin 的路由方式不同,前者严格按照 Servlet 标准实现,而后者则简化成正则表达式实现。因此在分析不同的 Web 容器时,除了尝试常见的 URI 变异方法,还可以针对性地分析对应容器的内部实现,从而找到隐藏更深的问题。
文件系统
在前面分析 Tomcat 和 Resin 容器的时候,可以发现有一个共同点,即路由在查找所有 Servlet 都失败的情况下,会使用默认的 Servlet 去进行处理,这个默认 Servlet 的作用就是读取本地磁盘或者资源中的文件。
因此仅从读文件的情况下看,我们是否可以利用文件系统寻址文件的特性来变异文件名呢?答案是肯定的。按照惯例来说应该查看对应文件系统的实现来看,但是这涉及到内核源码的分析,稍微超出了本 Java Boy 的能力范围,所以这里我直接写了一个简单的 Fuzzer 来进行文件名变异:
private void checkName(int i, String filename) {
File f = new File(filename);
if (f.exists())
System.out.println(String.format("%06x pass: [%s]", i, filename));
}
public void fuzzFilename(String originFile) {
File file = new File(originFile);
if ( !file.exists() ) {
return;
}
System.out.println(originFile + " exists.");
Path filePath = Paths.get(originFile);
String name = filePath.getFileName().toString();
Path parentPath = filePath.getParent();
String dirName = parentPath != null ? parentPath.toString() : "";
System.out.println(String.format("dirName: %s, name: %s", dirName, name));
for (int i = 0; i <= 0x10FFFF; i++) {
// if (!Character.isValidCodePoint(i)) continue;
String fuzzChar = new String(Character.toChars(i));
checkName(i, originFile + fuzzChar);
checkName(i, fuzzChar + originFile);
checkName(i, dirName + fuzzChar + name);
checkName(i, dirName + fuzzChar + File.separator + name);
checkName(i, dirName + File.separator + fuzzChar + name);
}
}
在 Linux/MacOS 中,输出如下:
dirName: /tmp, name: 1.txt
00002f pass: [/tmp/1.txt/]
00002f pass: [//tmp/1.txt]
00002f pass: [/tmp//1.txt]
值得注意的只有第一个,即在文件末尾加上 / 依然可以寻址到文件。
在 Windows 就比较丰富了,输出如下:
test\1.txt exists.
dirName: test, name: 1.txt
000020 pass: [test\1.txt ]
00002e pass: [test.\1.txt]
00002e pass: [test\1.txt.]
00002f pass: [test/1.txt]
00002f pass: [test/\1.txt]
00002f pass: [test\/1.txt]
00002f pass: [test\1.txt/]
00005c pass: [test\1.txt\]
00005c pass: [test\1.txt]
00005c pass: [test\\1.txt]
可以看到,在 Windows 中,文件名末尾加空格,.、/ 以及 \ 都不影响文件的定位,甚至目录末尾也可以加 . 号,这对于请求变异来说无疑增加了许多可能。假设 URL 原本要请求的文件是 /ppp/secret.txt,那么在 Windows 中请求就可以变异成:
- /ppp/SERET.TXT (大小写不敏感)
- /ppp/secret.txt%20
- /ppp.\seret.txt
- /ppp/seret.txt%2e
- /ppp/seret.txt/
- ...
值得一提的是,在 Windows 常用的 NTFS 文件系统中,还有一种特殊的文件表示成为备用数据流(Alternate Data Streams),简称 ADS。NTFS 中每个文件都有至少一个数据流,即主数据流,数据流的完整表示方法为:
<文件名>:<数据流名>:<数据流类型>
默认数据流名称为空,因此对于文件 foo.txt 而言其默认数据流的全称应该是 foo.txt::$DATA,其中数据流名为空,类型为 $DATA。对于目录而言,不存在默认数据流,但是有默认的目录流(directory stream)。目录流类型为 $INDEX_ALLOCATION,默认的流名称为 $I30,因此下面的目录表示都是等价的:
C:\UsersC:\Users:$I30:$INDEX_ALLOCATIONC:\Users::$INDEX_ALLOCATION
该特性可以使我们在 Windows 中寻址文件和目录时候使用更加隐晦的变异方法。
参考文档:
URI 标准
既然上面在讨论的都是 URL,那自然免不了 “官方” 的解释。不管是 Servlet 容器还是 HTTP Server,所遵循的都是同一个标准,即:
关于该标准相信其他师傅多少都有提及过,只是各自的关注点不同。对于本文而言,关注点在路径部分。在 3.3 节中指明,path 以第一个问号 ? 或者井号 # 终止,或者是到 URI 的结尾。各部分的示意图如下所示:
foo://example.com:8042/over/there?name=ferret#nose
\_/ \______________/\_________/ \_________/ \__/
| | | | |
scheme authority path query fragment
| _____________________|__
/ \ / \
urn:example:animal:ferret:nose
所以一般路由寻址的时候是不包含 ? 后面的参数的,但其他的部分实现各有不同,Tomcat 在路径中包含 # 时会报错,但 Resin 则会当成合法的路径一部分去进行路由查找。
路径部分的 ABNF 定义如下:
path = path-abempty ; begins with "/" or is empty
/ path-absolute ; begins with "/" but not "//"
/ path-noscheme ; begins with a non-colon segment
/ path-rootless ; begins with a segment
/ path-empty ; zero characters
path-abempty = *( "/" segment )
path-absolute = "/" [ segment-nz *( "/" segment ) ]
path-noscheme = segment-nz-nc *( "/" segment )
path-rootless = segment-nz *( "/" segment )
path-empty = 0<pchar>
segment = *pchar
segment-nz = 1*pchar
segment-nz-nc = 1*( unreserved / pct-encoded / sub-delims / "@" )
; non-zero-length segment without any colon ":"
pchar = unreserved / pct-encoded / sub-delims / ":" / "@"
路径由段(segments)组成,不同段之间使用斜杠 / 进行分隔。
. 和 .. 称为 dot-segments,在对路径进行路由之前需要先去除这些段,在 5.2 章 Relative Resolution 中详细介绍了如何解析包含 dot-segment 的路径,甚至还给出了伪代码实现。
另外 path segment 中通常可以包含保留字符用来提供一些子组件,比如前面提到过的使用分号 ; 和等号 = 来为每个 segment 提供参数。标准中提到逗号 , 通常也有类似的作用,不过我们之前分析源码的时候发现 Tomcat 和 Resin 都对逗号没有特殊的处理。
鉴权案例
前面提到过,为了降低代码的耦合性,鉴权一般放到 Filter 中实现而不是在 Servlet 中实现。对于一般的开发者而言,可以很简单的写出一个鉴权 Filter,比如:
@WebFilter(filterName = "AdminFilter", urlPatterns = "/*")
public class AdminFilter extends HttpFilter {
@Override
public void doFilter(HttpServletRequest req, HttpServletResponse res, FilterChain chain) throws IOException, ServletException {
String uri = req.getRequestURI();
if (uri.startsWith("/api/flag")) {
res.setStatus(403);
res.getWriter().write("YOU SHALL NOT PASS: " + uri);
} else {
chain.doFilter(req, res);
}
}
}
看了前面的 Bypass Tricks,我们知道仅使用 startsWith 做鉴权是多么地不堪一击,但令人惊讶的是现实中确实存在着许多类似的鉴权代码。不仅有 startsWith,endsWith,甚至还有使用 indexOf 去比较 URI 进行鉴权的。
某 OA
当然,这类应用在红队一次又一次的毒打中逐渐成长了起来,也知道了在对 URI 鉴权之前需要先对其进行一定的清洗和过滤。下面是一个某知名 OA 应用中鉴权部分对 URI 的预处理代码:
public String path(String path) {
path = this.uriDecode(path);
if (path != null && path.indexOf("\\") != -1) {
path = StringUtil.replace(path, "\\", "/", false);
}
if (path != null && path.indexOf("..") != -1) {
path = StringUtil.replace(path, "\\.{2,}", "");
}
if (path != null && path.indexOf("./") != -1) {
path = StringUtil.replace(path, "./", "", false);
}
if (path != null && path.indexOf(";") != -1) {
path = StringUtil.replace(path, ";.*?/", "/");
}
if (path != null && path.indexOf(";") != -1) {
path = StringUtil.replace(path, ";.*", "");
}
if (path != null && path.indexOf("//") != -1) {
path = StringUtil.replace(path, "/{2,}", "/");
}
if (path != null) {
path = StringUtil.replace(path, "\\s", "");
}
if (!path.equals("") && !path.startsWith("/")) {
path = "/" + path;
}
return path;
}
private String uriDecode(String path) {
try {
if (path != null && path.indexOf("%") != -1) {
return URLDecoder.decode(path);
}
} catch (Exception var3) {
this.writeLog("uri decode error:" + path, true);
this.writeError(var3);
}
return path;
}
首先 URI 解码,然后替换反斜杠,也别管 URI 的标准了,.. 直接删掉,路径参数也直接删掉,还有空格、// 之类的都进行了处理,看起来是不是无懈可击?但是其实仔细看一下会发现还是有一些问题,比如:
- uriDecode 中可能会失败,导致根本没解码成功而返回原始的路径;
- URI 解码之后,路径可能会存在大写,如果是 WIndows 中请求 JSP 等文件可以正确路由;
- 路径参数的删除在
./之后,所以.;xxx/处理后依旧存在./; - 删除空格
\s在归一化//之后,所以/%20/依旧可以绕过替换返回//; - ...
可见尽管有时候开发者知道要过滤什么字符,但是手指也不听大脑使唤,导致写出的代码依旧漏洞百出。因此,更为科学的方案是使用知名的、经过检验的鉴权框架,而不是尝试自己处理。
Shiro
Apache Shiro 是一个简单易用的认证和鉴权管理框架,虽然本身支持许多场景,但常用于 Web 应用中的身份认证和路径鉴权。
web.xml 的配置比较简单,只需要引入 ShiroFilter 并将其映射到所有 URL,注意 filter-mapping 一般要在其他 Filter 之前:
<listener>
<listener-class>org.apache.shiro.web.env.EnvironmentLoaderListener</listener-class>
</listener>
<filter>
<filter-name>ShiroFilter</filter-name>
<filter-class>org.apache.shiro.web.servlet.ShiroFilter</filter-class>
</filter>
<filter-mapping>
<filter-name>ShiroFilter</filter-name>
<url-pattern>/*</url-pattern>
<dispatcher>REQUEST</dispatcher>
<dispatcher>FORWARD</dispatcher>
<dispatcher>INCLUDE</dispatcher>
<dispatcher>ERROR</dispatcher>
<dispatcher>ASYNC</dispatcher>
</filter-mapping>
具体的配置通过配置文件实现,默认在 WEB-INF/shiro.ini,一个示例如下:
[main]
authc.loginUrl = /login.jsp
filterChainResolver.globalFilters = null
[urls]
/login/* = anon
/admin/* = authc
/api/flag = authc
[users]
evilpan=111111
urls 中使用优先匹配,而不是最佳匹配,左边指定 URL 模式,右边指定对应的 Filter 名称。Shiro 中支持的 Filter 如下:
- anon: org.apache.shiro.web.filter.authc.AnonymousFilter
- authc: org.apache.shiro.web.filter.authc.FormAuthenticationFilter
- authcBasic: org.apache.shiro.web.filter.authc.BasicHttpAuthenticationFilter
- authcBearer: org.apache.shiro.web.filter.authc.BearerHttpAuthenticationFilter
- invalidRequest: org.apache.shiro.web.filter.InvalidRequestFilter
- logout: org.apache.shiro.web.filter.authc.LogoutFilter
- noSessionCreation: org.apache.shiro.web.filter.session.NoSessionCreationFilter
- perms: org.apache.shiro.web.filter.authz.PermissionsAuthorizationFilter
- port: org.apache.shiro.web.filter.authz.PortFilter
- rest: org.apache.shiro.web.filter.authz.HttpMethodPermissionFilter
- roles: org.apache.shiro.web.filter.authz.RolesAuthorizationFilter
- ssl: org.apache.shiro.web.filter.authz.SslFilter
- user: org.apache.shiro.web.filter.authc.UserFilter
一般常用的是 authc 表示 SESSION 认证的 Filter,anon 表示可匿名访问即无需认证的 Filter。对于配置文件的其他字段及其解释可以参考官方文档,这里就不详细介绍了。
我们这里主要关心的是 Shiro 鉴权之前对 URL 路径做了什么样的处理。篇幅原因这里直接说结论,处理的方法为 org.apache.shiro.web.util.WebUtils#getPathWithinApplication,调用链路回溯如下所示:
getPathWithinApplication:114, WebUtils (org.apache.shiro.web.util)
getPathWithinApplication:105, PathMatchingFilter (org.apache.shiro.web.filter)
pathsMatch:124, PathMatchingFilter (org.apache.shiro.web.filter)
preHandle:195, PathMatchingFilter (org.apache.shiro.web.filter)
doFilterInternal:131, AdviceFilter (org.apache.shiro.web.servlet)
doFilter:154, OncePerRequestFilter (org.apache.shiro.web.servlet)
doFilter:66, ProxiedFilterChain (org.apache.shiro.web.servlet)
executeChain:458, AbstractShiroFilter (org.apache.shiro.web.servlet)
call:373, AbstractShiroFilter$1 (org.apache.shiro.web.servlet)
doCall:90, SubjectCallable (org.apache.shiro.subject.support)
call:83, SubjectCallable (org.apache.shiro.subject.support)
execute:387, DelegatingSubject (org.apache.shiro.subject.support)
doFilterInternal:370, AbstractShiroFilter (org.apache.shiro.web.servlet)
doFilter:154, OncePerRequestFilter (org.apache.shiro.web.servlet)
internalDoFilter:178, ApplicationFilterChain (org.apache.catalina.core)
getPathWithinApplication 的代码为:
public static String getPathWithinApplication(HttpServletRequest request) {
return normalize(removeSemicolon(getServletPath(request) + getPathInfo(request)));
}
主要经过两步,分别是 removeSemicolon 去除分号以及 normalize 路径归一化。removeSemicolon 的实现只考虑路径末尾的分号:
private static String removeSemicolon(String uri) {
int semicolonIndex = uri.indexOf(';');
return (semicolonIndex != -1 ? uri.substring(0, semicolonIndex) : uri);
}
不过 normalize 的实现倒是比较完善,注释中也说明这是从 Tomcat 中 “借鉴” 的:
Normalize operations were was happily taken from org.apache.catalina.util.RequestUtil in Tomcat trunk, r939305
值得注意的是,这里传入的并不是原始的 URI,而是 getServletPath + getPathInfo,二者分别是:
- HttpServletRequest.getServletPath(),在 Tomcat 中对应
mappingData.wrapperPath.toString(); - HttpServletRequest.getPathInfo(),在 Tomcat 中对应
mappingData.pathInfo.toString();
在前面介绍 Tomcat 中路由映射的时候提到,mappingData 中的 wrapper 是在路由之后确定的,也就是说此时 wrapperPath 已经是 Web 容器处理之后的 URI,如果能寻址到 flagServlet,那么其值必然是 /api/flag,优雅地解决了 TOCTOU 不一致的问题。
当然这也不意味着无懈可击,否则 Shiro 也不会再加一层 removeSemicolon 和 normalize。因为 Web 容器具有多样性,不同路由策略的碎片化同样也可能造成 Shiro 的绕过。而现在的 getPathWithinApplication 也不是一开始就是这样的,而是在 CVE-2020-13933 出现之后才改成这样子,详情可以参考: ANNOUNCE CVE-2020-13933 Apache Shiro 1.6.0 released。
在对路径完成这一步过滤后,使用 pathMatches 进行匹配:
// org.apache.shiro.web.filter.mgt.PathMatchingFilterChainResolver#getChain
final String requestURI = getPathWithinApplication(request);
final String requestURINoTrailingSlash = removeTrailingSlash(requestURI);
for (String pathPattern : filterChainManager.getChainNames()) {
if (pathMatches(pathPattern, requestURI)) {
return filterChainManager.proxy(originalChain, pathPattern);
} else {
// 针对 Spring Web 的处理
pathPattern = removeTrailingSlash(pathPattern);
if (pathMatches(pathPattern, requestURINoTrailingSlash)) {
return filterChainManager.proxy(originalChain, pathPattern);
}
}
}
注意这里针对 Spring 应用进行了特殊处理,因为在 Spring 中 /resource/data 和 /resource/data/ 都能路由到同一个资源,但 Shiro 的 /resource/data 无法匹配到后者,因此将路径和 pathPattern 都删除了末尾的 / 去进行二次匹配。这应该是针对 CVE-2021-41303 的补丁,可见即便是成熟的鉴权框架也依然会踩到 URL 鉴权的陷阱。
后记
本文介绍了使用 URL 进行鉴权的一类威胁模型,并以两个符合标准的 Servlet 容器 Tomcat 和 Resin 为例介绍了二者的路由查找方法,根据路由查找的过程提出了一系列可能的 URL 变异方式;然后对几个现实中的鉴权案例进行分析,包括某典型应用手搓的鉴权代码以及成熟的鉴权方案 Shiro,其中都存在或者出现过鉴权绕过的场景,从中我们可以加深对 URL 鉴权的理解,从而写出更加健壮和安全的代码。
另外,本文只是介绍了 Servlet 标准应用的路由特性,而现代 Java Web 应用中更多是基于 Spring 生态的全家桶方案,Spring MVC 包揽了 Web 容器的所有路由并使用自身的寻址实现,且配合 Spring Security 也形成一套 URL 鉴权方案。这部分限于篇幅原因并未在本文中提及,后续有机会的话会另起一篇文章进行介绍。
彩蛋🥚: 在分析 Resin 路由的时候,其实暴露了一个 “0day”,涉及到路径处理的核心顺序错误,不知道读者是否能够发现?





