0x00 反编译的局限、先决条件和评价指标
反编译技术具有一些局限性,各类反编译工具或者系统,都面临着一些共同的困难,多数困难是由于需要恢复出一些输入的二进制文件中并非显式提供的信息,毕竟编程语言在设计时考虑的不是逆向工程,而是正向编译。这部分是有志反编译技术人士面临的主要技术困难。同时,也是恶意代码编写者常用于对抗反编译的技术手段。
1.反编译技术面临的宏观问题
1)问题
同一机器上,同一语言的不同编译版本存在目标代码结构上的差异,即多编译版本问题;同一机器上,不同语言编译存在目标代码结构上的差异,即多语言问题;不同机器上,同一语言编译存在目标代码上的差异,即多机种(CPU,也就是多体系结构)问题。
2)相应的解决方案
上述这些问题都影响到以程序分析为目的反编译系统的实用性和通用性。对这些问题,某些可能的解决途径是:
最笨但一定可行的方法:针对每一种情况,分别开发各自的反编译系统,这种穷举方法势必使反编译投资庞大,且研制的反编译器时效性差,显然不适合实际需要。
基于同一机型,设计良好的中间语言(针对于特定的体系结构,比如X86固定寄存器表示等,与机器相关!!),开发标准的反编译系统,对各编译版本的影响或者不同语言的差别(目标代码结构上)采用预处理方法分别转换为标准的中间语言形式,这种思路可行(不同前端-相同的中端,相同或者不同的后端),从中间语言转换到高级语言的技术是成熟的,但要覆盖各种情况,因而开发量也很大(仅比第一种方法看上去美些……)。
对于不同的机型和同一种语言,可以设计抽象的中间代码,也就是与体系结构不相关的,寄存器数量不限,采用目标代码预处理方法分别转换到抽象的中间代码,接下来根据不同的后端,进行中间代码的提升,这种方法效果类似2)中所述(是目前常用的方法!)。
2.反编译技术面临的技术性问题
反向编译需要解决如下一些传统的难点问题,在此我们仅仅列出了最难解决的若干问题,而在一款反编译器开发的过程中,开发者往往会遇到更多具体而又琐碎的问题。
1)区分代码和数据
受冯•诺伊曼结构的制约,绝大多数计算机使用的数据和代码是存储在同一段内存空间中的,因此,区分数据和代码的一般解决办法已经被证明等价于停机问题。虽然,多种格式的可执行文件都定义了代码段.text和数据段.data,但这样并不能阻止编译器或程序员把常量数据(如:字符串、switch跳转表)放入代码段中,也无法阻止将可执行代码放入数据段中。因此,代码和数据的区分仍然是一个亟需解决的重要问题。
针对代码和数据的区分问题,对静态反编译而言效果最好的一个方法是数据流制导的递归遍历。此技术根据机器代码从程序的入口点搜索所有可能的程序路径,它依赖于程序的所有路径都是有效的,且入口点是可发现的。最终,它同样依赖于分析间接转移指令以获得其目标地址的能力,间接转移指令包括间接跳转和间接调用指令。
2)处理间接跳转和间接调用指令
对于指令中的每个立即数操作数,都需要选择将这个数值作为常量的值来表示还是作为指向内存中地址的指针来表示。对间接跳转和间接调用的分析面临着一个共同的问题——目标地址的确定。程序切片、表达式复制传播和值域分析等是最有希望解决这一问题的技术,但是这些技术严重依赖于数据流分析,而数据流分析又依赖于完整的控制流图。间接跳转和间接调用问题未得到解决之前,是不可能拥有一个完整的控制流图的。因此,初看起来它就如“鸡跟蛋”问题一样是无法解决的。
当反汇编器或者反编译器面对一个指针尺寸(如:8字节)的立即数时,它们需要判断此立即数到底是常数(属于整形、字符型或者其它数据类型)还是指向某类型数据的指针。
3)自修改代码
自修改代码指的是指令或者预先设定的数据在程序的执行中被修改。用于储存指令的内存空间可能会在程序执行过程中被修改成为了另外的指令或者数据。在上个世纪六七十年代,计算机的内存空间很小,难以运行大的程序。计算机的最大内存为32Kb或64Kb,由于空间的制约,必须以最好的方式对空间进行利用,其中一种方法就是在可执行程序中节省字节,同一内存单元在程序执行中能保存指令,也能在另一时刻保存数据或其他指令。
自修改代码是程序运行时改变自身执行指令的程序代码。自修改代码的编写是非常困难的,因为它要考虑可能对指令缓存造成的不良影响,它的主要用途是:反静态分析、反盗版、病毒利用此方法逃避杀毒软件的查杀等。
4)编译器和链接器包含的子过程
二进制翻译的另外一个问题就是编译器引入的大量子过程以及链接器链接进来的很多过程造成翻译难度和工作量大的问题。编译器总是需要通过start-up子过程来设置环境,而且在需要的时候引入一些运行时的支持过程,这些过程通常是用汇编语言编写的,无法翻译到高级表示。同时,由于多数操作系统不提供共享库机制,因此二进制程序是自包含的,库函数绑定到二进制映像中,而且很多库函数是用汇编语言编写的。这就意味着二进制程序包含的不仅仅是程序员编写的过程,而且还有很多是链接器链接进来的其他过程。二进制翻译本身只对用户编写的过程感兴趣,因此需要能够区分用户自定义过程和库函数。
5) 对难点问题的总结
传统的反编译想要具备一定的实用性,下列问题是不能够回避的:
- 如何区分代码和数据
- 如何处理间接跳转和间接调用指令,以获得间接转移指令的目标地址而完成对代码的完整挖掘
- 如何处理自修改代码
- 如何进行数据类型恢复。如果可以完全恢复源程序的数据和数据类型,那么反编译生成程序就可像源程序一样运行于不同体系结构的机器,从反向编译更加通用
3.反编译的先决条件
反编译的难度要远远大于编译,因为编译后得到的机器代码己将源程序中所有显式的高级语言信息完全丢失了。针对某种语言进行反编译,不但需要较深的关于编译和操作系统以及硬件等方面理论知识的支持,还需要通过大量的实践和摸索获得源——目标对之间的某些对应模式,在此基础上进行研究和实践。
反编译的实践,要以如下的背景知识作为先决条件:
- 反编译所要达到的高级语言的语法描述;反编译过程是由它所翻译到的目标高级语言的语法来制导的。
- 反编译源文件所包含的目标代码集,即编译所对应的机器指令集;只有掌握作为反编译器的输入的机器指令集的规格说明,才能有效地恢复低级代码程序的控制结构和数据流。
- 编译所得到的可执行代码的内存映象:有效地区分数据区和代码区,能减小反编译的工作量。
4.反编译器的评价指标
反编译器的性能评价方面并没有确定的标准,通常人们采用如下几点作为评价依据:
- 反编译自动化程度:反编译器运行过程中人工干预的次数是评定反编译自动化程度的量度;
- 反编译时间:即针对某个应用,反编译器获得结果所需要的运行时间;
- 反编译器开发效率:重新编制程序和通过研制反编译目标程序得到高级语言程序所需工作量的比值;
- 反编译压缩比:反编译生成的高级语言程序与输入的低级语言程序的长度比,比值越小,则压缩比越大,反编译器越优秀。
0x01 常见反编译框架
比起如何使用一款反编译工具,我们这里更关心如何设计和实现一款实用的反编译器以及需要用到哪些技术。在这里,我们还是站在较为宏观的角度列举和认识一下几种常见的反编译器框架。在讨论框架的同时,分析它们各自的优点,进行必要的对比。从整体上学习传统反编译器是如何设计的?能够解决实际问题的新型反编译又是如何设计的?以反编译为核心技术实现的具有二进制翻译功能、同时又具备反编译能力的“翻译器”是怎样设计的?
通过阅读,读者朋友们能够从整体上了解实现不同用途的反编译器的整体设计思路,以及一些具备现代反编译特征的(即多源反编译、多源二进制翻译)新型反编译器的框架设计理念。
1.“I型”反编译器的框架
反编译器在实际使用中,需要一些辅助程序来配合其创建目标高级语言的工作。无论这个反编译器多么简单,至少也要包括能够实现文件装载和可以处理有关库函数在反编译(或者具备二进制翻译特性的反编译工作)过程中的库函数处理程序。接下来我们将介绍经典反编译器在囊括必要辅助程序以后的程序框架和基本功能组成。
1)上下文环境的衔接
一般来说,源二进制程序都有一个重定位的地址表,当程序被装入内存的时候,将在某些地址上进行重定位,通常反编译器会通过装载程序实现这个操作。接着,已经被重定位的(或绝对的)机器码就会被反编译器中的反汇编引擎进行机器码到汇编码的转换,产生该程序的汇编表示。
反汇编引擎在工作中并非将可执行程序中所有01代码翻译成汇编代码,而是需要借助上文提到的“辅助程序”——即借助“编译器签名”和“库签名”两类辅助程序去掉编译器在编译时加入的启动代码(start-up code)和库例程代码,然后再对剩余的由用户编写的代码进行反汇编。
接着,汇编语言程序作为反编译器的输入,输出并产生一个高级语言的目标程序。该目标程序并不是最终反编译的结果,还需要进行进一步的处理,例如:对while()循环做转换以便后期处理器处理等。
当然,“辅助程序”等自动工具不能保证在任何情况下都能进行正确的处理,反编译过程有时需要人为的干预,即使用者也可能作为一个信息提供者,尤其是在确定库例程以及区分数据和指令的时候。经验丰富的反编译程序员比使用自动工具更可靠。
2)dcc反编译器的框架
dcc是用C语言编写的一个适用于DOS操作系统的原型反编译器(昆士兰大学Cristina Cifuentes博士期间进行的反编译研究成果)。dcc最初在一台运行Ultrix的DecStation 3000上开发,后来被移植到运行DOS的PC机体系结构上。dcc把Intel i80286体系结构的.exe文件和.com文件作为输入,并且产生目标C语言和汇编语言程序。这个反编译器严格按照上一节介绍的反编译上下文环境设计实现,它的框架由图所示的几个部分组成。
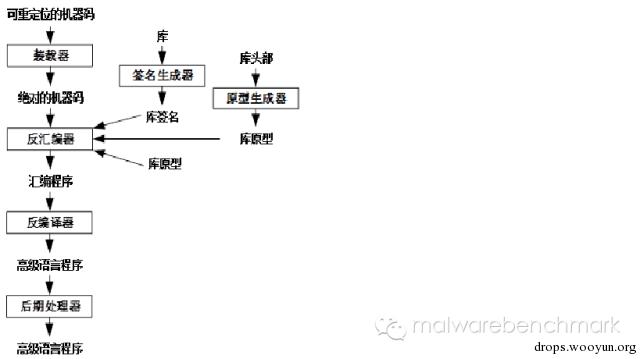
图1 dcc反编译器框架
(1)装载器
装载器是一段程序,它负责将待反编译的目标程序载入内存,并完成目标程序机器码的重定位(如果是可重定位的)。程序装载是反编译的准备阶段的第一步。
(2)签名生成器
签名生成器是编译器的重要“辅助程序”,它存在的目的是简化反编译的目标程序,简化方法就是确定待反编译程序的所使用的编译器版本以及库函数版本(dcc的编制者称其为编译器和库的签名,可以理解为编译器和库的特征信息)。签名生成器可以自动、且唯一地标识每个编译器和库子程序的二进制标本。这些签名的使用试图反向进行链接器的工作——链接器把库和编译器启动代码链接到程序。通过上述处理,被分析的程序就剥离掉非用户程序部分的所有编码,只包含用户当初用高级语言编写的那部分程序。
从Cristina所给出的示例可以看出:显示“hello world”的C程序编译以后,在二进制程序中有26个不同子程序,其中16个子程序是被编译器增加来设置它的环境,9个例程是被链接器加入来实现printf(),1个子程序来自最初的C程序。签名生成器的使用不仅减少了需要分析的子程序个数,也由于使用库函数名称代替任意的子程序名称从而增加了目标程序的可读性。
(3)原型生成器
原型生成器是一个自动确定库子程序参数类型以及函数返回值类型的程序。这些原型来自于函数库的头文件,被反编译器用来确定库子程序的参数以及参数个数。原型生成器所做的工作是所有反编译器必须着重处理的重要目标之一:函数恢复,包括库函数的名称、参数个数、参数类型、返回值类型等等。
(4)反汇编器
反汇编器是一个把机器语言转换成汇编语言的程序。有些反编译器把汇编语言程序转换成一个更高级的表示法(一般是为统一多源目标反编译的高级中间表示)。
(5)库绑定
这一步是用来处理源可执行程序的编制语言与反编译输出的高级语言不一致的问题,例如:用Pascal编写的程序所生成的可执行代码被反编译成C程序。假如产生的目标代码中使用库函数名称 (也就是说能够检测到库签名),由于两种语言使用不同的库例程,所以即使这个程序是正确的也不能再用目标语言编译它了,需要将原来用到的库函数替换成反编译目标语言的库函数。dcc解决这个问题的办法是使用库绑定——在两种语言的库例程之间建立关联。
当然这种类似的方法在反编译或者二进制翻译中被普遍的使用,例如二进制翻译会涉及到夸操作系统使用库函数,这样即便是同一种高级语言也可能因为版本不同而存在库函数的差异,因此这种“库绑定”的处理方式适用面很广。
(6)后期处理器
dcc后期处理器也是一个程序,它把一个高级语言程序转换成同种语言的一个语义等价的高级程序,例如while循环转换成for循环,此处假设目标语言是C语言,以下while循环的代码:
a = 1;
while (a < 50)
{
/* 其它 C代码 */
a =a + 1;
}
可能被后期处理器转换成等价的for循环代码:
for (a = 1; a < 50; a++) { /*其它 C代码 */}
这是一个语义等价的程序,我们知道C语言中使用for作为循环结构具有更好的性能,因此此处后期处理器处理的结果是更适合于C语言的for循环,而不是反编译器直接生成的反编译结果的一般化结构while循环。
2.经典多源反编译框架简介
目前支持多源的反编译框架主要有三种,分别是:基于语义描述和过程抽象描述的可变源、可变目标框架;以商用反汇编软件IDA Pro为前端的、支持可扩展的反编译框架;以及基于第三方代码转换库的多源反编译框架。下面分别以三种框架的典型系统为例,简单介绍和分析一下各种框架的特点。
1)UQBT
在实验型反编译器dcc的研发基础上,毕业后Cristina Cifuentes和Mike van Emmerik等人于1997年提出了UQBT可重定向的二进制翻译系统,该二进制翻译系统是以反编译为主要技术手段实现的。2001年研发者又对其后端作了扩展,在1999年版本的基础上增加了对JVML的支持等功能。
(1)框架结构
UQBT的1999版框架如图所示。
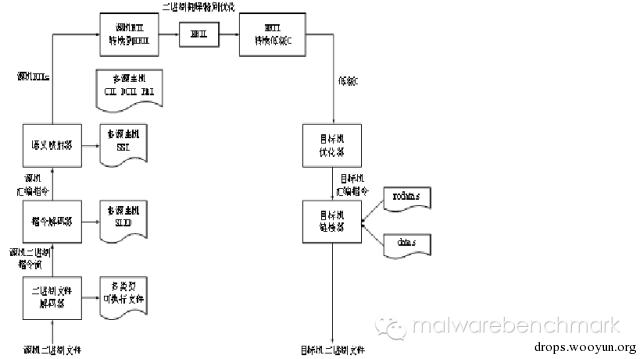
图2 UQBT原始框架
2001年扩展后的框架结构如所示。

图3 UQBT的扩展框架
UQBT框架可以大致被分为三部分:前端、分析和翻译部分、后端。Ms表示给定的源机器,Md表示目标机器,前端负责对源机器Ms上的二进制文件解码,并将其转换为与机器无关的中间语言形式,即RTLs的形式;分析部分负责将源机器上的地址映射为目标机上的地址并完成相关的优化;后端负责将优化过的中间语言形式转换为对应目标机上的可执行文件。由此可见UQBT框架中的前端和分析部分相当于反编译的部分,后端则是代码生成部分,即将反编译后的代码再编译或转换为目标机上的可执行代码。
UQBT是可变源、可变目标的,对于反编译来说只是为了实现从低级代码到高级代码的转换,不需要再转变为目标机器上的可执行代码,因此可以不考虑多目标的问题。UQBT的可变源和目标的特性通过描述语言、API和可插入模块支持。其中几个形式化的描述语言成为UQBT的亮点和精髓,分别是:编解码描述语言SLED、语义描述语言SSL、过程描述语言PAL等。
-
SLED语言
SLED语言是专门用来描述汇编指令与二进制编码之间映射关系的语言,支持RISC和CISC指令架构,已实现对MIPS、SPARC和Pentium的编解码描述。基于SLED描述的指令解析,由NJMC(New JerseyMachine Code)工具集通过匹配语句来驱动,但对于一个特定的SLED描述文件,要为其生成专门的匹配语句,而这个过程要实现自动化非常困难。
-
SSL语言
SSL语言包括两类语义的描述,一类是描述每条汇编指令的语义,另一类则是描述硬件体系架构相关的特征。通过定义constants、registers、flag_fnc、operands、tables、instr等关键词来进行描述。其中constants用来描述常量、registers用来描述寄存器、flag_fnc用来描述标志副作用、operands用来描述复杂操作数、tables用来描述一组指令名称、instr则用来描述一条SSL语句。而一条SSL语句由左部LHS和右部RHS两部分组成,左部对应的是汇编指令的名称,或一组汇编指令对应的表的名称,右部则是表示寄存器转换的语句序列。对SSL语言的解析是由语义描述解码器SRD来完成。由于SSL语言的语法比较复杂,要实现对各种SSL描述的正确解析也是很困难的。
-
PAL语言
PAL语言分别利用FRAME ABSTRACTION、LOCALS、PARAMETERS、RETURNS四种关键字对内存栈的抽象、本地变量的抽象、参数的抽象、返回值的抽象进行描述。其中内存栈的抽象主要描述用于存放内存栈指针的寄存器名称;本地变量抽象主要描述栈帧分配的大小;参数的抽象主要从调用者和被调用者两个角度描述实参和形参所在的可能位置;返回值的抽象则主要描述返回值与存放返回值的寄存器或内存单元之间的对应关系。
-
APIs
UQBT提供了二进制文件格式和控制转移APIs。二进制文件格式有多种(如:Elf,PE等),但是这些表示都有方法可以从可执行程序中提取代码和数据——这种类型的信息可以通过API获得。
对于控制转移API,需要开发者从无条件跳转中识别条件转移,也就是调用和返回。因为这些指令看起来都类似于跳转,但是在语义上具有很小的差别。
(2)中间表示
UQBT应用两种中间表示,低级RTL(Register TransferLists)直接与机器指令映射,高级HRTL(High LevelRegister Transfer Lists)形式与编译器中间代码类似,它应用了控制流的高一级抽象。
RTL是一种基于寄存器的中间语言,它针对机器的汇编指令进行描述,代表了指令间的信息传递。该语言提供了无限个寄存器和内存单元可供使用,不会受限于某种特殊的机器结构。近年来,RTL已经被广泛的应用到各种系统中作为中间表示,例如GNU编译器、编译连接优化器OM、编辑库EEL等等。由于其操作简单并且具有良好的平台无关性,因此我们选用RTL作为IA64到Alpha二进制翻译器的中间表示语言。
在UQBT中,源机器体系结构每一条指令对应一个寄存器传送列表或RTL语句。这种语言能够通过对某一位置的一系列执行效果来捕获机器指令的语义信息。
HRTL是从过程调用、过程内控制流等与机器特性相关的细节中抽象出来的一种高级中间表示语言,由指令和操作符组成。它提供了所有基本控制流指令,例如无条件跳转(JUMP)和条件跳转(JCOND)、应用CALL和RETURN指令的过程调用、N—way分支指令等,为了给内存单元赋值,HRTL定义了ASGN指令。
所有的内存单元和值都由语义串描述,分支指令将它们的跳转目标作为语义串参数。复杂的语义串应用算术、逻辑或字节运算函数递归定义。在ITA翻译器的实现过程中,我们应用该语言表示IA-64指令语义时,需要对它的函数进行扩展,目前HRTL定义了一百多个不同的操作符和函数。
(3)前端模块
前端模块的工作由一系列阶段完成,每一个阶段将源输入文本流变换成高一级的表示形式。
- 二进制文件的解码器:将源二进制文件解码到一种中间表示,该中间表示支持二进制文件格式API。所有的文本段和代码段被拷贝,并将得到的二进制文件信息存放在中间表示中。
- 指令的解码:将文件解码器得到的指令流进行反汇编。在UQBT中主要应用NJMCT提供的匹配文件,结合指令的SLED描述文件完成指令的解码。
- 语义映射模块:将汇编指令映射成与源机器文件代码段相对应的RTL表示,RTL由机器的SSL描述语言提供。这一步在汇编指令匹配之后执行,指令被转换成寄存器传送列表。
- Ms-RTL 到HRTL翻译器,这是二进制翻译中的一个关键阶段,以机器无关性来表示程序代码。该模块将RTL指令转换成HRTL指令,处理控制转移指令,基于PAL描述分析过程信息,添加额外的代码处理源机器指令集的特性,其中机器特定的分析用于将机器相关性进行消除。在UQBT中这部分工作包括SPARC中控制的延迟转移消除,Pentium中将基于栈的浮点代码变换成基于寄存器的代码;在我们的ITA翻译器中这部分工作主要是IA-64体系结构的谓词执行和投机机制等特性优化代码的处理。
(4)后端模块
UQBT框架应用多种后端产生代码,其中比较成功的方法是依赖C编译器作为目标机的优化器和代码产生器。在这种方法中,HRTL代码被翻译到低级C,应用C编译器作为宏汇编器。后来的UQBT版本应用公共域或特性优化器后端,并集成在RTL级。
(5)开发耗时——一个有趣的事实
这里我们讨论一个有趣的事实,但却能够充分说明进行一款实用的反编译器开发需要庞大的工作量,以及使用描述语言对开发效率的提升。在表中我们列出了基于UQBT翻译框架开发其他的二进制翻译器所用的时间和人力,可以看出描述语言的应用使得在UQBT框架上容易实现其他机器的二进制翻译器。写描述文件与写和机器相关的部分源代码相比,无论是时间还是代码数量都少了很多,而且开发者还可以重用本系统提供的机器无关的分析。开发人员需要完成源机器指令的SLED和SSL描述文件,以及应用PAL语言对源操作系统环境进行描述,再针对源机器的机器特性进行处理,结合目标机的特性完成相应的后端,这样就可以有效地缩短二进制翻译系统的开发周期。
UQBT开发时间和人力情况:
| 里程碑 | 人力耗费 | 人力耗费细节 |
|---|---|---|
| (SPARC,Solaris)和(x86,Solaris) 前端;C后端 | 5.7(人-年) | 18(研究员-月),24(工程师-月)3.6(研究员-月),4.8(学生-月)6(学生-月),12(学生-月) |
| (68328,PalmOs) 前端 | 6(人-月) | 3(工程师-月),3(工程师-月) |
| JVML后端(C ver.) | 3(人-月) | 3(学生-月) |
| JVML后端(Java ver.) | 5(人-月) | 3(学生-月),2(工程师-月) |
| 目标代码后端 | 3(人-月) | 3(学生-月) |
| RTL后端 | 7(人-月) | 3(研究员-月)(SPARC)4(工程师-月)(ARM) |
| (PA-RISC,HP-UX)前端 | 10(人-月) | 6(学生-月,)3(工程师-月)1(研究员-月) |
尽管UQBT提供的框架和二次开发方法大大提高了反编译器的编写效率,缩短了开发周期和时间,但是以笔者常年参与以反编译为基础的逆向分析方法的研究经历和研发经验来看——一款可用的反编译器开发仍然会耗费一个10人团队数年的开发时间。
2)Hex-Rays
Hex-Rays是一款商用反编译工具,前端是IDA Pro。Hex-Rays实际上是IDA Pro中的反编译插件,因为IDA Pro支持扩展,且已经支持对大量不同指令集架构下可执行程序的反汇编,因此,Hex-Rays理论上可以实现对所有IDA Pro支持的指令集架构下的所有可执行程序进行反编译,但目前为止,Hex-Rays仅实现了对x86和ARM平台下可执行程序的反编译,扩展缓慢。
与同类工具相比,Hex-Rays能很好的识别复合条件表达式及循环结构,对库函数名及参数的识别率较高。另外Hex-Rays提供有Decompiler SDK,允许开发者以IDA Pro为前端,实现自己的分析方法。目前很多逆向分析人员都是利用IDA提供的接口来编写插件,从而完成漏洞挖掘、软件确认、覆盖分析等。
3)BAP
BAP是由David Brumley在BitBlaze静态分析组建Vine的基础上改进得到的,与BitBlaze相比,BAP对中间语言做了一些扩展,清除了Vine中存在的几个漏洞。其框架如图所示。
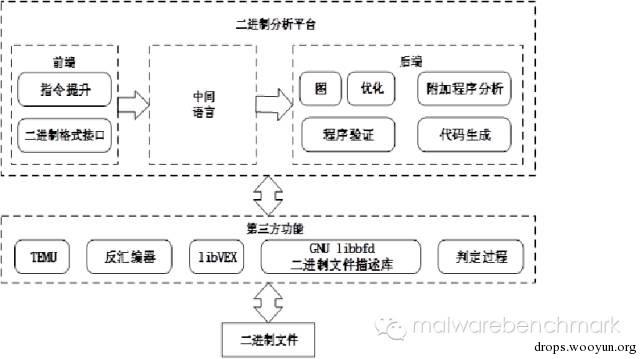
图4 BAP框架
由图中可以看到,BAP分为前端、中间语言、后端三部分。其中前端主要完成二进制文件格式的解析及语义的提升,后端主要完成相关的优化、程序验证、其他的程序分析工作、生成相关的图、代码生成等工作,中间语言代码则是基于libVEX第三方库生成的VEX IR中间语言代码转换得到的。BAP基于第三方的工具集,主要包括:反汇编器、代码转换库、GNU中的二进制文件解析工具libbfd,决策过程等。其中反汇编器BAP主要支持IDA Pro和GNU objdump,代码转换库是libVEX。值得一提的是,BAP支持动态分析,TEMU就是基于QEMU专门针对x86平台的动态分析引擎,TEMU为用户提供了各种语义提取接口以及动态污点分析接口,为用户进行动静态结合的漏洞挖掘及恶意代码分析等工作提供了很好的平台。
由于BAP前端主要依赖于第三方库,只要第三方库支持的平台,BAP就会支持,第三方库不支持的平台BAP也无法进行分析,要实现对新平台的支持,只能依赖第三方库的扩展,因此存在被动扩展的问题。


