0x00 目录
0x01 链接的构成
0x02 浏览器算如何对url进行解析的
0x03 链接真的只能是这样固定的格式么?
0x04 链接真的是你看到的那样么?
0x01 链接的构成
链接真的只能固定成我们常用的格式么?
不知道有多少人思考过这个问题!我们经常输入的格式一般都是www.xxxx.com!
或者再加上协议名 http https 端口以及路径什么的 或者再加上账号密码!如下图: 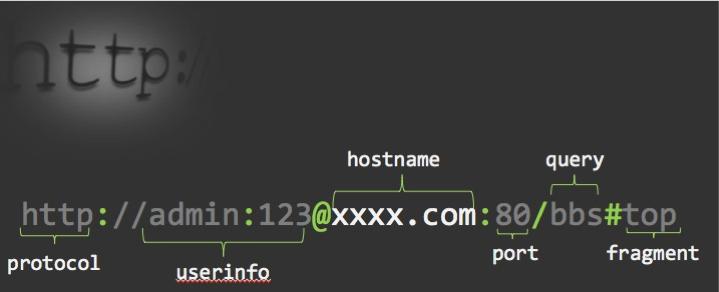
第一部分:协议名(以单个冒号结束)
第二部分:用户信息 也就是账号密码!(登陆ftp时常用)
第三部分:主机名(也就是域名)
第四部分:端口
第五部分:查询,这里有个bug。。。 应该是?号后的内容才是查询!
第六部分:片段ID(是不会发送到服务器的!)
0x02 浏览器是如何对url进行解析的
我们都知道我们访问一个网站是带有协议的比如http ftp https 等等!
首先浏览器会提取我们链接中的协议名,它是如何提取的呢?
(以下为copy web之困上的内容 他写的比较详细!)
1.提取协议名:
他会查找第一个:号在哪,如何找到了 那么:号左边的便是协议名!如果获得的协议名中出现了不该有的字符,那么认为这可能就是个相对的url 获得的并不是协议名!
2.去除层级url标记符:
字符串//应该算跟在协议名后面的 如果发现有该字符 则会跳过该字符 如果没有找到便不管了!所以 http:baidu.com 也是可以访问的! 浏览器中还可以用反斜杠来代替正斜杆\\代替//firefox除外!
3.获取授权信息部分:
依次扫描url,如果这三个符号中 哪个先出现便以哪个为准来截取
/(正斜杠)
?(问号)
#(井号)
从url里提取出来的信息,就算授权部分信息!
除了IE跟safari其他浏览器还接受 ;(分号)也算授权信息部分中可接受的分隔符!
(1)定位登陆信息,如果有的话:
授权部分信息提取出来后,在截取出来的信息里再来查找 @ 如果找到了 那么他前面的部分便是登陆信息!登陆信息再查找 : (冒号) 冒号前面的便是账号 后面便是密码!
(2)提取目标地址
授权信息部分剩下的便是目标地址了 第一个冒号分开的就算主机名跟端口!用方括号括起来的就是ipv6地址,这也是个特例!
结合以上信息 我们分析下以下链接:
ftp://admin:admin@192.168.1.100:21
这样的链接我经常用来登陆ftp!这样便会以admin的身份 密码为:admin
ftp协议去登陆主机192.168.1.100,端口号是21端口!
4.确定路径(如果的确存在)
如果授权部分的结尾跟着一个正斜杆,某些场景里,跟着一个反斜杠或者分号,就像之前提到的,依次扫描下一个? # 或字符串结尾符,那个先出现便以哪个为准!截取出来的部分就是路径信息!最后根据unix路径语义进行规范化整理!
5.提取查询字符串(如果的确存在)
如果在上一条解析里,后面跟着的是一个问号,便继续扫描下一个 # 或到字符串结尾,哪个先出现便以哪个为准!中间的部分便是查询字符串。
6.提取片段ID
如果成功解析完上一条信息,它最后还跟着#号 那么从这个符号到字符串的结尾便算片段ID了,片段ID是不会发送到服务器的!一般用来跳到A标签的锚链接 或者用来js的 location.hash 取值 等等!
如果大家去年跟着wooyun的基友们一块玩烂了基础认证钓鱼的话那么应该能回想起来!当时很多网站在插入图片的地方都判断了后缀名是不是图片的后缀名jpg gif等等!但是hook不是gif 什么结尾的!当时的方法便是在hook后面加上#.jpg!这样便可以成功的来钓鱼了!原理也是一样的!
下面我们拿几个例子来解析一下:
例子1:
http://xss1.com&action=test@www.baidu.com
这样一个链接在普通用户看来 是会认为访问xss1.com的!
但是实际上是去往www.baidu.com 的!为什么呢?结合以上的知识我们分析一下!
首先 协议名提取出来了 然后获得授权部分信息,? / # 都未出现 浏览器便无法获得一个字符串来获得主机地址!我们再往后看@符 @符前面的便认为是登陆信息 并不会当做主机名来解析!所以现在xss1.com&action=test 已经被当做登陆信息了 现在唯一的主机名便只有www.baidu.com了!
而xss1.com&action=test在我们访问网站的时候 被当做了登陆了信息去访问www.baidu.com了!
例子2:
http://xss1.com\@www.baidu.com
首先看下这个链接在chrome中的样子:
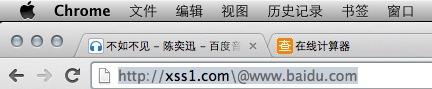
很明显的看到 这样一个链接在chrome中是会去访问xss1.com的!
现在我们来看下在firefox下的样子:
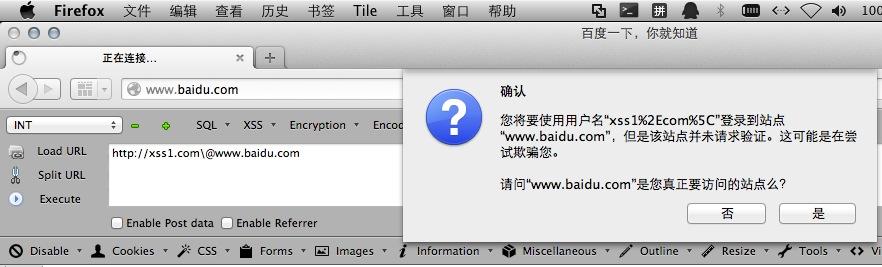
会提示我们是否要用账号为:xss1.com\的信息去访问www.baidu.com!
这是为什么呢?浏览器差异 我们在之前也说了!
因为在除了firefox外,其他的浏览器都会把(反斜杠当做正斜杠来解析!)
而正斜杠的出现就代表授权信息部分结束了!因为提取授权部分信息是用\ ? #
所以授权信息部分结束 那么前面的便当成了主机名!
而firefox是不会把\当成正斜杠的而@符号前面的 便算登陆信息 后面的就是主机名!所以当用firefox去访问这个链接时 才出现了 上图中的提示!
例子3:
http://xss1.com;.baidu.com/
由于机器没有IE 就不上图了吧!
微软浏览器允许主机名称中出现 ; (分号)并成功的解析到了这个地址!当然还需要baidu.com提前做了这样的域名解析设置!
大多数其他浏览器会自动的把url纠正成http://xss1.com/;.baidu.com/
然后用户就访问到了xss1.com(safari除外,它会认为这个语法错误)
0x03 链接真的只能是这样固定的格式么?
不知道有多少人想过这个问题,链接真的只能是这样么!
通过上面的介绍后,相信大家应该会说No了!
我记得之前有篇文章讲,xss加载钩子的时候http://做黑名单内!于是那位兄弟便拆分了http://
var i='http';
var b='://';
这样也是一种办法 但是我们有没有更好的办法呢? 答案肯定是有的 //www.baidu.com 也是可以被加载的!
(当前网页的协议是什么 加载这个钩子便用什么协议来加载! 如在https协议的网页中 这样加载钩子 那么默认就是https去加载钩子了!)
到了这里,我们不得不思考 这样能正常的打开一个网页 我们还有什么方法来加载网页?这时候我们可以fuzz一下!
如下图:

可以看到//后面我们还能输入tab,换行,/ @ \等等!那我们来测试一下!构造如下链接去访问一下!
\\/www.baidu.com
\\@www.baidu.com
\\/@www.baidu.com
\\\\\\\www.baidu.com
///////www.baidu.com
等等全部能正常的访问到百度!大家可以自己试一下!最好的话写在a 标签 或者 img script里把!这样更贴近我们平常所遇到的环境!
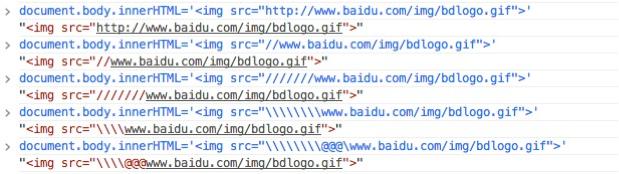
既然我们在文章的标题提到了猥琐 这样够猥琐?No 还不够!这样我们的连接始终还是带着一定的特征!
www .com .net 什么的特征还在,既然说到猥琐 我们就要更加猥琐!比如下面这样的一串字符串!
ⅅʳºℙˢ --> drops
ʷººʸⓊⁿ —> wooyun
Ⓞʳℊ —> org
最后拼凑 :
ⅅʳºℙˢ.ʷººʸⓊⁿ.ºʳℊ
变成这样也是能够访问的 大家可以试试!
那么这样一段字符串是如何得来的呢?
我们可以通过http:/xsser.me/hf.html来fuzz!
在fuzz之前先给科普一下:
针对域名的编码:Punycode
经过Punycode编码后的域名是会被DNS服务器所识别的!
就拿中文域名来说,因为操作系统的核心都是英文组成,DNS服务器的解析也是由英文代码交换,所以DNS服务器上并不支持直接的中文域名解析。 所有中文域名的解析都需要转成punycode码,然后由DNS解析punycode码。最后我们成功的访问到了我们要去网站!只不过今天我们这里punycode编码的解析过程并不是由dns服务器来解析的 而是在浏览器访问时就给解码回来!
在drops中瞌睡龙的文章也提到过!
http://drops.wooyun.org/papers/146
说了这么多,开始把!(也顺便讲一下这个玩意应该怎么用)
首先我们算要测试url 所以要先把 Callback 中的 x.protocol 改成hostname!
然后再把hostname等于的值也改掉,改成我们要测试的主机名!(别带上协议名)
比如drops.wooyun.org
然后再在exp里把A标签的链接改成带有协议名的主机名!(不带的话不能访问)
都设置好 如下图:

下面的小参数可以使用默认的!参数都设置好了,现在我们要标识 我们要测试哪个字符,用:{chr} 代替该字符即可!
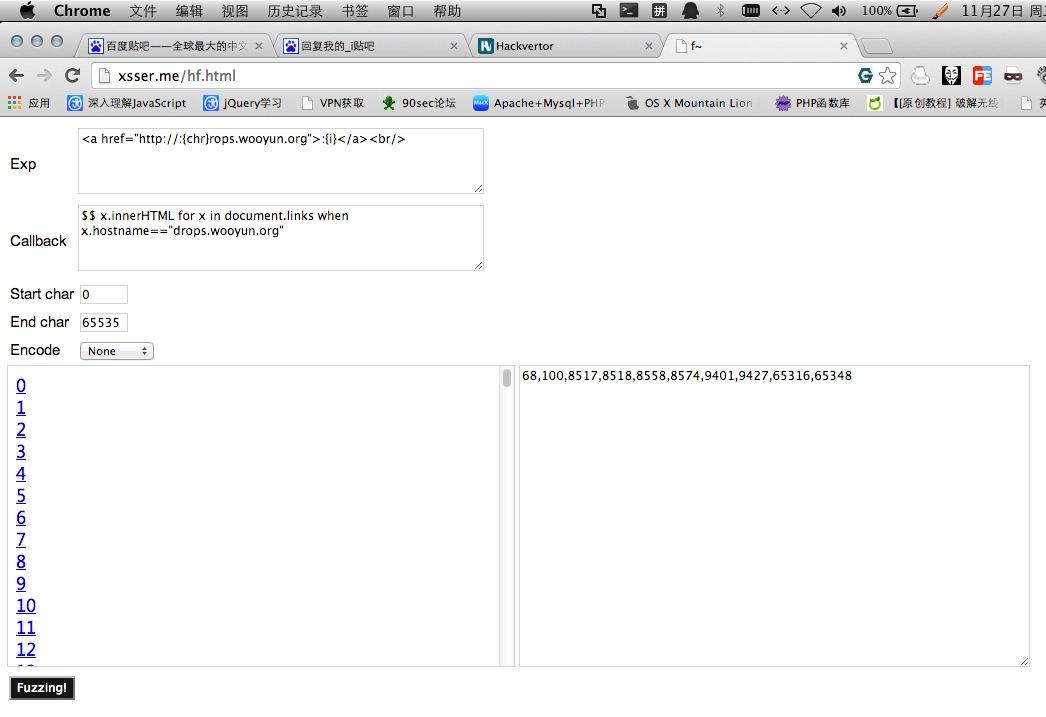
好,现在设置好后点击Fuzzing 枪打出头鸟 我们就先测d吧!
可以看到右边的框里出现了一段数字,这段数字是ASCii码每个字符以逗号分割!
我们可以使用工具把ASCii码给转换回来,不过我比较喜欢chrome 方便!
现在我们复制他们!然后丢chrome里把他们给还原回来!打开控制台(F12)

输入String.fromCharCode(ASCII码) 回车便出来了!
好经过测试我们得出第一个字符 d 可以使用
DdⅅⅆⅮⅾⒹⓓDd
来代替!
这里我就不一一的fuzz给大家看了!我们贴出最后经过fuzz后的字符串吧!
http://ⅅʳºℙˢ.ʷººʸⓊⁿ.ºʳℊ
大家可以复制 然后访问一下!依然是能够访问的到的!
但是这里也局限于需要一个可以解析的中间件才能访问!
如果curl的话就不行了!
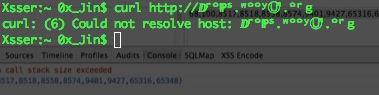
为什么呢?很简单因为没解析 curl他不会去解析这个字符串!
而浏览器为什么能够正常访问 算因为他会对我们编码后的值进行解析再访问!
所以这点也算需要知道的!
可是这种情况我们在哪能用到呢?我们往下看!
如果在插入钩子的时候或其他什么的时候,对方算基于黑名单过滤的www .com .org什么的,那么便可以用这种方式去绕过!
这里的思路大家就去扩散下 有什么更猥琐的思路求交流!
再来个例子吧!
首先拿一个被腾讯认为是危险网站的红X站
可以看到这个链接发出来是会被当做危险网站的!
现在我们对其中的一个字符fuzz!为什么是一个字符?
(因为你fuzz的字符多了 会被当成符号 让腾讯认为这不是一个链接!然后就不 能一点就会打开网页了 比如这样。。。)
可以看到这样带的符号多了 让腾讯这不是一个链接 就不会生成个超链接了!
所以我们一般只fuzz几个字符便好了!
说干就干,我们来开始测试吧!
还是用 http://xsser.me/hf.html 来fuzz

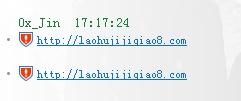
经过fuzz 测试出来 http://laohujijiqiao8.com 的o 可以用以下的字符来代替! 
O o º ℴ Ⓞ ⓞ O o
现在我们来测试一下!
http://laohujijiqiaº8.com
发出去 看还带没带危险网站的标识!上图: 

现在已经没有标识这是个危险网站的 并且还能够正常打开!是不是已经达到我们的目的了呢?
之前用这种方式把一个蓝色标示的网站弄成显示为腾讯官网!链接如下:
http://www.qq.com@xss1.com#
(ps:以前没加#号时 还是蓝色链接 但是加了#号就显示为腾讯的官网了!)
因为前面的链接:www.qq.com 发送出去是会显示为腾讯官方网站的!但是现在好像不行了!
0x04 链接真的是你看到的那样么?
有人在社区里发了这么个帖子:百度URL跳转 绕过腾讯红XX
可是我们真的需要要有url跳转漏洞才能跳转么?
No 任何网站都可以!如下:
http://www.baidu.com@qq.com
把这段地址填入浏览器中 访问会发现去了 www.qq.com了 而并不是平常大家所认为的www.baidu.com 这是为什么,我们可以看看此篇文章的开头!
http:// 后面可以算userinfo 也就算用户信息 账号密码什么的!
结束是以单个@号结束! 所以我们这段链接为什么去qq.com 而不是去baidu.com算因为一个@符 让浏览器认为www.baidu.com 算一段用户信息 而后面的才算主机名 他要去访问的地址!
所以我们有时候伪装找不到跳转漏洞也可以如此实现!
然而在chrome 跟firefox下 还可以这么写:
http:www.baidu.com@qq.com
协议名没有// 也会被认为是http://
没看过web之困或者之前没接触过data uri的基友们!可能看了上面这个小例子就会很惊叹了 原来还可以这样!
在web之困中还讲了其实url地址是可以用进制来代替的!只不过算把ip地址给转换成进制来访问!
十进制 ---||||||> 十六进制 ---||||||> 八进制 然后在访问时 指定协议然后加个0
http://0[八进制] 比如 115.239.210.26 首先用.分割数字 115 239 210 26 然后选择10进制转换16进制!
(要用0来表示前缀,可以是一个0也可以是多个0 跟XSS中多加几个0来绕过过滤一样!)
首先把这四段数字给 转成 16 进制!结果:73 ef d2 1a 然后把 73efd21a 这十六进制一起转换成8进制!

结果:16373751032
然后指定协议 http:// 用0表示前缀 加上结果 链接:
http://0016373751032
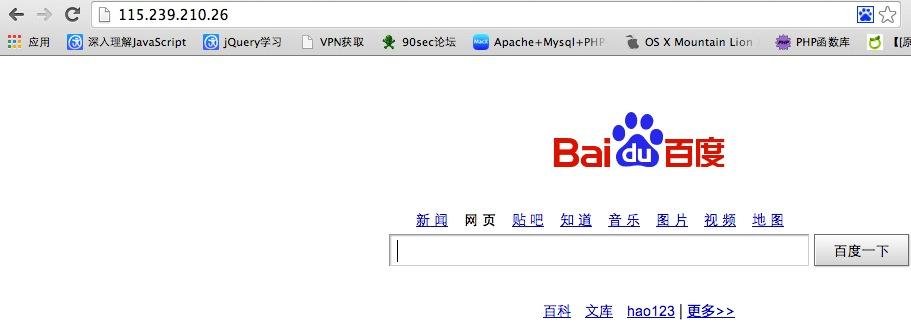
成功解析成我们原来的ip了!
结合最开始的一个例子:
http://xss1.com&action=test@www.baidu.com
后面还带着www.baidu.com 太打眼了,现在把我们上面转换后的地址加在后面 记得带上0前缀!
http://xss1.com&action=test@016373751032
这样就不打眼了 看上去舒服多了 有木有?
既然解析回来了 那我们看看能不能用这个地址来加载一些资源比如图片 js什么的!
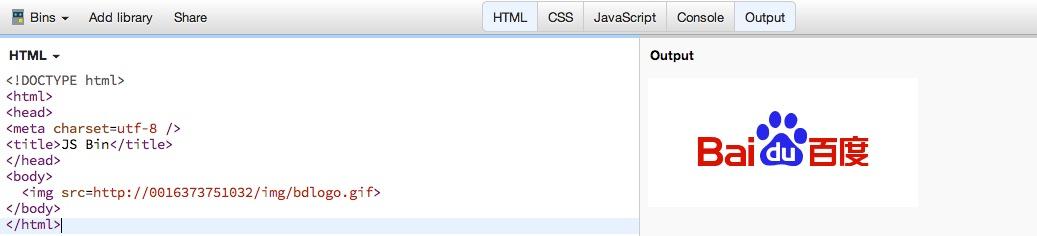
可以看到成功加载了图片!那应该也是加载js等等的!
相信有扩散性的基友们都有想法了,平时用来绕过一些限制等等!
具体的大家去实验吧!web的世界 无穷大啊!



