0x00 前言
天下武功,唯快不破。但密码加密不同。算法越快,越容易破。
0x01 暴力破解
密码破解,就是把加密后的密码还原成明文密码。似乎有不少方法,但最终都得走一条路:暴力穷举。
也许你会说还可以查表,瞬间就出结果。虽然查表不用穷举,但表的制造过程仍然需要。查表只是将穷举提前了而已。
只要算法不可逆,那只能穷举。
穷举的原理很简单。只要知道密文是用什么算法加密的,我们也用相同的算法,把常用的词组跑一遍。若有结果和密文一样,那就猜中了。
穷举的速度有多快?这和加密算法有关。加密一次有多快,猜一次也这么快。
例如 MD5 加密是非常快的。加密一次耗费 1 微秒,那破解时随便猜一个词组,也只需 1 微秒(假设机器性能一样,词组长度也差不多)。攻击者一秒钟就可以猜 100 万个,而且这还只是单线程的速度。
所以,加密算法越快,破解起来就越容易。
0x02 慢加密
如果能提高加密时间,显然也能增加破解时间。
如果加密一次提高到 10 毫秒,那么攻击者每秒只能猜 100 个,破解速度就慢了一万倍。
怎样才能让加密变慢?最简单的,就是对加密后的结果再加密,重复多次。
例如,原本 1 微秒的加密,重复一万次,就慢一万倍了:
for i = 0 ~ 10000
x = md5(x)
end
加密时多花一点时间,就可以换取攻击者大量的破解时间。
事实上,这样的「慢加密」算法早已存在,例如bcrypt、scrypt等等。它们都有一个难度系数因子,可以控制加密时间,想多慢就多慢。
加密越慢,破解时间越长。
0x03 慢加密应用
最需要慢加密的场合,就是网站数据库里的密码。
近几年,经常能听到网站被「拖库」的新闻。用户资料都是明文存储,泄露了也无法挽回。唯独密码,还可以和攻击者对抗一下。
然而不少网站,使用的都是快速加密算法,因此轻易就能破解出一堆弱口令账号。
当然,有时只想破解某个特定人物的账号。只要不是特别复杂的密码,跑上几天,很可能就破出来。
但网站用了慢加密,结果可能就不一样了。如果把加密时间提高 100 倍,破解时间就得长达数月,变得难以接受。
即使数据泄露,也能保障「密码」这最后一道隐私。
0x04 慢加密的缺点
不过,慢加密也有明显的缺点:消耗大量计算资源。
使用慢加密的网站,如果同时来了多个用户,服务器 CPU 可能就不够用了。要是遇到恶意用户,发起大量的登录请求,甚至造成资源被耗尽。
所以,性能和安全总是难以兼得。
一些大型网站,甚至为此投入集群,用来处理大量的加密计算。但这需要不少的成本。
有没有什么方法,可以让我们使用算力强劲、同时又免费的计算资源?
0x05 前端加密
在过去,个人电脑和服务器的性能,还是有较大差距的。但如今,随着硬件发展进入瓶颈,这个差距正缩小。在单线任务处理上,甚至不相上下。
客户端拥有强大的算力,能不能分担一些服务器的工作?
尤其像「慢加密」这种算法开源、但计算沉重的任务,为何不交给客户端来完成?
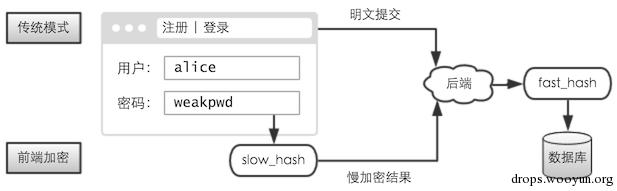
过去,提交的是明文密码;现在,提交的则是明文密码的慢加密结果。无论是注册,还是登陆。
而服务端,无需任何改动。将收到的慢加密结果,当做原来的明文密码就行。以前是怎么保存的,现在还是怎么保存。
这样就算被拖库,攻击者破解出来的也只是慢加密结果,还需再破解一次,才能还原出「明文密码」。
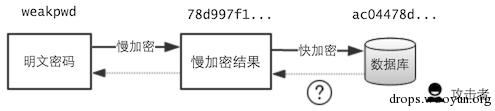
事实上,慢加密结果这个中间值,是不可能破解出来的!
因为它是一个散列值 ———— 毫无规律的随机串,例如 32 位十六进制字符串,而字典都是有意义的词组,几乎不可能跑到它!
除非字节逐个穷举。但这有 16^32 种组合,是个天文数字。
所以「慢加密结果」是无法通过数据库里泄露的密文「逆推」出来的。
或许你在想,即使不知道明文密码,也可以直接用「慢加密结果」来登录。事实上后端储存时再次加密,就无法逆推出这个散列值了。
当然,不能逆推,但可以顺推。把字典里的词组,用前后端的算法各调用一次:
back_fast_hash( front_slow_hash(password) )
然后对比密文,即可判断有没有猜中。这样就可以用跑字典来破解。
但是有 front_slow_hash 这个障碍,破解速度就大幅降低了。
0x06 对抗预先计算
不过,前端的一切都是公开的。所以 front_slow_hash 的算法大家都知道。
攻击者可以用这套算法,把常用词组的「慢加密结果」提前算出来,制作成一个「新字典」。将来拖库后,就可以直接跑这个新字典了。
对抗这种方法,还得用经典的手段:加盐。最简单的,将用户名作为盐值:
front_slow_hash(password + username)
这样,即使相同的密码,对于不同的用户,「慢加密结果」也不一样了。
也许你会说,这个盐值不合理,因为用户名是公开的。攻击者可以对某个重要人物的账号,单独为他建立一个字典。
那么,是否可以提供一个隐蔽的盐值?答案是:不可以。
因为这是在前端。用户还没登录,那返回谁的盐值?登陆前就能获得账号的盐值,这不还是公开的吗。
所以,前端加密的盐值无法隐藏,只能公开。
当然,即使公开,单独提供一个盐值参数,也比用户名要好。因为用户名永远不变,而独立的盐值可以定期更换。
盐值可以由前端生成。例如注册时:
# 前端生成盐值
salt = rand()
password = front_slow_hash(password + salt)
# 提交时带上盐值
submit(..., password, salt)
后端将用户的盐值也储存起来。
登录时,输完用户名,就可以开始查询用户对应的盐值:
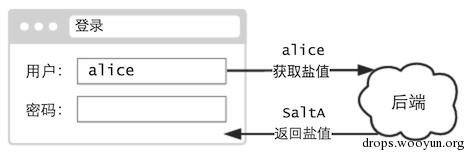
当然要注意的是,这个接口可以测试用户是否存在,所以得有一定的控制。
盐值的更换,也非常简单,甚至可以自动完成:
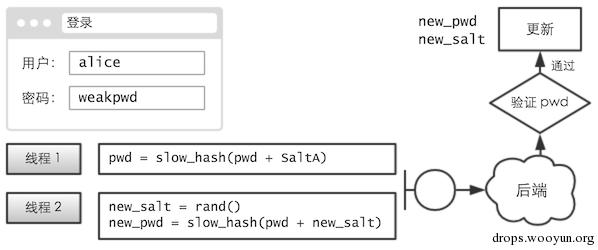
前端在加密当前密码时,同时开启一个新线程,计算新盐值和新密码。提交时,将它们全都带上。
如果「当前密码」验证成功,则用「新密码」和「新盐值」覆盖旧的。
这样更换盐值,还是只用到前端的算力。
这一切都是自动的,相当于:在用户无感知的情况下,定期帮他更换密码!
密文变了,针对「特定盐值」制作的字典,也就失效了。得重新制作一次。
0x07 强度策略
密码学上的问题到此结束,下面讨论实现上的问题。
现实中,用户的算力是不均衡的。有人用的是神级配置,也有的是古董机。这样,加密强度就很难设定。
如果古董机用户登录会卡上几十秒,那肯定是不行的。对于这种情况,只有以下选择:
- 强度固定
- 强度可变
1.强度固定
根据大众的配置,制定一个适中的强度,绝大多数用户都可接受。
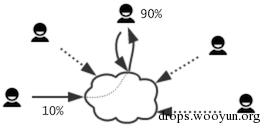
但如果超过规定时间还没完成,就把算到一半的 Hash 和步数提交上来,剩余部分让服务器来完成。
[前端] 完成 70% ----> [后端] 计算 30%
不过,这需要「可序列化」的算法,才能在服务端还原进度。如果计算中会有大量的临时内存,这种方案就不可行了。
相比过去 100% 后端慢加密,这种少量用户「前后参半」的方式,可以节省不少服务器资源。
对于请求协助的用户,也必须有一定的限制,防止恶意透支服务器资源。
2.强度可变
如果后端不提供任何协助,那只能根据自身条件做取舍了。配置差的用户,就少加密一点。
用户注册时,加密算法不限步数放开跑,看看特定时间里能算到多少步:
# [注册阶段] 算力评估(线程 1 秒后终止)
while
x = hash(x)
step = step + 1
end
这个步数,就是加密强度,会保存到他的账号信息里。
和盐值一样,强度也是公开的。因为在登录时,前端加密需要知道这个强度值。
# [登录阶段] 先获得 step
for i = 0 ~ step
x = hash(x)
end
这个方案,可以让高配置的用户享受更高的安全性;低配置的用户,也不会影响基本使用。(用上好电脑还能提升安全性,很有优越感吧~)
但这有个重要的前提:注册和登录,必须在性能相近的设备上。
如果是在高配置电脑上注册的账号,某天去古董机登录,那就悲剧了,可能半天都算不出来。。。
3.动态调整方案
上述情况,现实中是普遍存在的。比如 PC 端注册的账号,在移动端登录,算力可能就不够用。
如果没有后端协助,那只能等。要是经常在低端设备上登陆,那每次都得干等吗?
等一两次就算了,如果每次都等,不如重新估量下自己的能力吧。把加密强度动态调低,更好的适应当前环境。
将来如果不用低端设备了,再自动的调整回来。让加密强度,能动态适应常用的设备的算力。
实现原理,和上一节的自动更换盐值类似。
4.异想天开方案
下面 YY 一个脑洞大开的方案,前提是网站有足够大的访问量。
如果当前有很多在线用户,它们不就是一堆免费的计算节点吗?计算量大的问题,扔给他们来解决。
不过这样做也有一些疑虑,万一正好推送给了坏人怎么办?
显然,不能把太多的敏感数据放出去。节点只管计算,完全不用知道、也不能知道这个任务的最终目的。
但是,如果遇到恶作剧节点,故意把数据算错怎么办?
所以不能只推送给一个节点。多选几个,最终结果一致才算正确。这样风险概率就降低了。
相比 P2P 计算,网站是有中心、实名的,管理起来会容易一些。对于恶作剧用户,可以进行惩罚;参与过帮助的用户,也给予一定奖励。
想象就到此,继续讨论实际的。
0x08 性能优化
1.为什么要优化?
或许你会问,「慢加密」不就是希望计算更慢吗,为什么还要去优化?
假如这是一个自创的隐蔽式算法,并且混淆到外人根本无法读懂,那不优化也没事。甚至可以在里面放一些空循环,故意消耗时间。
但事实上,我们选择的肯定是「密码学家推荐」的公开算法。它们每一个操作,都是有数学上的意义的。
原本一个操作只需一条 CPU 指令,因为不够优化,用了两条指令,那么额外的时间就是内耗。导致用时更久,强度却未提升。
2.前端计算软肋
如果是本地程序,根本不用考虑这个问题,交给编译器就行。
但在 Web 环境里,我们只能用浏览器计算!相比本地程序,脚本要慢的多,因此内耗会很大。
脚本为什么慢?主要还是这几点:
- 弱类型
- 解释型
- 沙箱
3.弱类型
脚本,是用来处理简单逻辑的,并不是用来密集计算的,所以没必要强类型。
不过如今有了一个黑科技:asm.js。它能通过语法糖,为 JS 提供真正的强类型。
这样计算速度就大幅提升了,可以接近本地程序的性能!
但是不支持 asm.js 的浏览器怎么办?例如,国内还有大量的 IE 用户,他们的算力是非常低的。
好在还有个后补方案————Flash,它有各种高性能语言的特征。类型,自然不在话下。
相比 asm.js,Flash 还是要慢一些,但比 IE 还是快多了。
4.解释型
解释型语言,不仅需要语法分析,更是失去了「编译时深度优化」带来的性能提升。
好在 Mozilla 提供了一个可以从 C/C++ 编译成 asm.js 的工具:emscripten。
有了它,就不用裸写了。而且编译时经过 LLVM 的优化,生成的代码质量会更高。
事实上,这个概念在 Flash 里早有了。
曾经有个叫 Alchemy 的工具,能把 C/C++ 交叉编译成 Flash 虚拟机指令,速度比 ActionScript 快不少。
Alchemy 现在改名 FlasCC,还有开源版的 crossbridge
5.沙箱
一些本地语言看似很简单的操作,在沙箱里就未必如此。例如数组操作:
vector[k] = v
虚拟机首先得检查索引是否越界,否则会有严重的问题。
如果「前端慢加密」算法涉及到大量内存随机访问,那就会有很多无意义的内耗,因此得慎重考虑。
不过有些特殊场合,脚本速度甚至能超过本地程序!例如开头提到的 MD5 大量反复计算。
这其实不难解释:
- 首先,MD5 算法很简单。没有查表这样的内存操作,使用的都是局部变量。局部变量的位置都是固定的,避免了越界检查开销。
- 其次,emscripten 的优化能力,并不比本地编译器差。
- 最后,本地程序编译之后,机器指令就不会再变了;而如今脚本引擎,都有 JIT 这个利器。它会根据运行时的情况,实时生成更优化的机器指令。
所以选择加密算法时,还得兼顾实际运行环境,扬长避短,发挥出最大功效。
0x09 对抗 GPU
众所周知,跑密码使用 GPU 可以快很多倍。
GPU 可以想象成一个有几百上千核的处理器,但只能执行一些简单的指令。虽然单核速度不及 CPU,但可以通过数量取胜。
暴力穷举时,可以从字典里取出上千个词汇同时跑,破解效率就提高了。
那能否在算法里添加一些特征,正好命中 GPU 的软肋呢?
1.显存瓶颈
大家听过说「莱特币」吧。不同于比特币,莱特币使用了 scrypt 算法。
这种算法对内存依赖非常大,需要频繁读写一个表。GPU 虽然每个线程都能独立计算,但显存只有一个,大家共享使用。
这意味着,同时只有一个线程能操作显存,其他有需要的只能等待了。这样,就极大遏制了并发的优势。
2.移植难度
山寨币遍地开花的时候,还出现了一个叫 X11Coin 的币,据称能对抗 ASIC。
它的原理很简单,里面掺杂了 11 种不同的加密算法。这样,制造出相应的 ASIC 复杂度大幅增加了。
尽管这不是一个长久的对抗方案,但思路还是可以借鉴的。如果一件事过于复杂,很多攻击者就望而生畏了,不如去做更容易到手的事。
3.其他想法
之所以 GPU 能大行其道,是因为目前的加密算法,都是简单的公式运算。这对 CPU 并没太大的优势。
能否设计一个算法,充分依赖 CPU 的优势?
CPU 有很多隐藏的强项,例如流水线。如果算法中有大量的条件分支,也许 GPU 就不擅长了。
当然,这里只是设想。自己创造加密算法,是非常困难的,也不推荐这么做。
0x0A 「前端慢加密」额外的意义
除了能降低密码破解速度,前端慢加密还有一些其他意义:
1.减少泄露风险
用户输入的明文密码,在前端内存里就已加密。离开浏览器,泄露风险就已结束。
即使链路被窃听,或是服务器上的恶意中间件,都无法拿到明文密码。
除非网页本身有恶意代码,或是用户系统存在恶意软件。
2.无法私藏明文
尽管大部分网站都声称,不会存储用户的明文密码。但这并没有证据,也许私下里仍在悄悄储存。
如果在前端加密,网站就无法拿到用户的明文密码了。
也许正是这一点,很多网站不愿意使用前端加密。
事实上,其实网站不愿意也没关系,我们可以自己做一个单机版的慢加密插件。
当选中网页密码框时,弹出我们插件。在插件里输入密码后,开始慢加密计算。最后将结果填入页面密码框里。
这样,所有的网站都可以使用了。当然,已注册的账号是不行的,得手动调整一下。
3.增加撞库成本
「前端慢加密」需要消耗用户的计算力,这个缺点有时也是件好事。
对于正常用户来说,登录时多等一秒影响并不大。但对于频繁登录的用户来说,这就是一个障碍了。
谁会频繁登录?也许就是撞库攻击者。他们无法拖下这个网站的数据库,于是就用在线登录的方式,不断的测试弱口令账号。
如果通过 IP 来控制频率,攻击者可以找大量的代理 —— 网速有多快,就能试多快。
但使用了前端慢加密,攻击者每试一个密码,就得消耗大量的计算,于是将瓶颈卡在硬件上 —— 能算多快,才能试多快。
所以,这里有点类似 PoW(Proof-of-Work,工作量证明)的意义。关于 PoW,以后我们会详细介绍它。
0x0B 慢加密能否并行计算?
用户的配置越来越好,不少都是四核、八核处理器。能否利用多线程的优势,将慢加密计算进行分解?
如果每一步计算都依赖之前的结果,是无法进行拆解的。例如:
for i = 0 ~ 10000
x = hash(x)
end
这是一个串行的计算。然而只有并行的问题,才能分解成多个小任务。
不过,换一种方式的多线程也是可以的。例如我们使用 4 个线程:
# 线程 1
x1 = password
for i = 0 ~ 2500
x1 = hash(x1 + "salt1")
end
# 线程 2
x2 = password
for i = 0 ~ 2500
x2 = hash(x2 + "salt2")
end
# ...
最终将 4 个结果合并起来,再做一次加密,作为慢加密结果。
但这样会导致强度变低吗?留着给大家思考。
0x0C 总结
前端慢加密,就是让每个用户贡献少量的计算资源,使加密变得更强劲。
即使数据泄露,其中也凝聚了全网站用户的算力,从而大幅增加破解成本。
0xFF 后记
前些年比特币流行时,突发奇想用浏览器来挖矿。虽然没做成,不过获得了一些密码学姿势。
近期重新进行了整理,并添加了一些新想法,于是写篇详细的文章分享一下。
因为密码学属于传统领域,所以结合当下流行 Web 技术,才能更有新意。
如果你对算法有疑惑,可以先仔细看 0x05 这节。
如果你是耐心看完本文的,希望能有收获:)


