Author:leonnewton
0x00 前言
DEXLabs发表过题为《Detecting Android Sandboxes》的博客,文章提出了一个检测Android沙箱的方法,并附了PoC。本文对原文的内容进行介绍,并加上笔者自己实际实验的结果及讨论。
0x01 Qemu的二进制翻译机制
看下百度百科对二进制翻译的解释:
二进制翻译(Binary Translation)是一种直接翻译可执行二进制程序的技术,能够把一种处理器上的二进制程序翻译到另外一种处理器上执行。
Qemu使用二进制翻译技术把要翻译的native代码,比如ARM下的代码,翻译到host系统下一样或者不同的指令集,比如x86指令集。跟指令集模拟技术相比,二进制翻译运行速度更快,因为已经翻译的代码块可以进行cache然后直接执行。下面是Qemu二进制翻译过程的流程图:
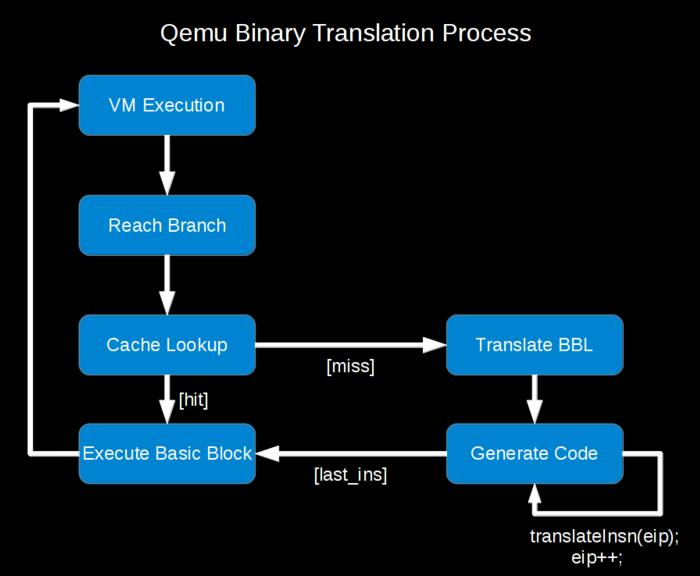
从图中可以看出,当遇到分支指令的时候,就会对后面的代码进行处理。后面的代码地址可以在分支指令里面找到,所以会先去找是否有代码的cache。当命中的时候,代码块已经有cache了,代码已经翻译过,所以直接执行就行了。当没有命中的时候,翻译函数就会去翻译代码,一直翻译到遇到下一个分支指令。然后把翻译好的代码放到cache中接着执行。
0x02 Qemu的一个优化
物理CPU会在每执行一条指令以后,就把程序计数器加一,程序计数器永远都是最新的值。那么对于一个虚拟的CPU来说,也应该是在每执行完代码中的一条指令然后将程序计数器加一,这样来保证程序计数器是最新的值。然而,由于被翻译的代码是在本地执行的,也就是模拟出来的CPU,所以只有在原来代码需要访问程序计数器的时候,才需要返回一个最新的正确的值(因为这不会影响host系统上面正常的运行)。Qemu在遇到需要返回最新值的时候会更新程序计数器,其他时候不会每次都更新,来作为一种优化措施。因此,程序计数器会指向一个代码块的最开始位置,因为每次进行分支跳转的时候才需要更新程序计数器。
0x03 由优化联想到的
试想下在多任务的操作系统中,当有中断发生的时候,上面的优化会导致什么事?由于程序计数器不是每执行一次就更新的,那么虚拟CPU在执行一个代码块的时候是不能被中断的,被中断后就没法恢复正确的程序计数器值。所以在运行一个代码块的时候,一般不会发生任务调度的情况。整个过程如下图所示:

0x04 实验验证
上面说不能中断,不能任务调度,那么实验就人为制造任务调度的情况,然后考察任务调度的情况。记录发生任务调度的地址,然后统计查看这些地址的分布情况。那么在一个真机的环境中,这些地址应该近似是相等的次数,均匀的分布。每个地址发生调度情况的可能性是相等的。在Qemu虚拟的环境中,应该是在一个代码块的最后才会发生任务调度,所以地址分布也不是均匀的,而是变化很大。
具体的实验是通过2个线程。一个线程在一个代码块中对一个全局变量不断地加1,每次循环全局变量都赋值为1。另一个线程也是循环,每次都去读前面的那个全局变量。然后统计读出来每个数字的次数。流程如下:
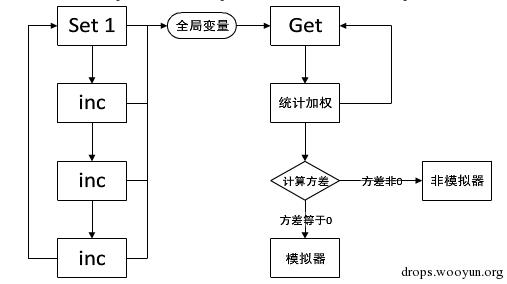
不断加1的线程代码如下:
void* thread1(void * data){
for(;;){
__asm__ __volatile__ ("mov r0, %[global];"
"mov r1, #1;"
"add r1, r1, #1;" "str r1, [r0];"
"add r1, r1, #1;" "str r1, [r0];"
"add r1, r1, #1;" "str r1, [r0];"
"add r1, r1, #1;" "str r1, [r0];"
"add r1, r1, #1;" "str r1, [r0];"
"add r1, r1, #1;" "str r1, [r0];"
"add r1, r1, #1;" "str r1, [r0];"
"add r1, r1, #1;" "str r1, [r0];"
"add r1, r1, #1;" "str r1, [r0];"
"add r1, r1, #1;" "str r1, [r0];"
"add r1, r1, #1;" "str r1, [r0];"
"add r1, r1, #1;" "str r1, [r0];"
"add r1, r1, #1;" "str r1, [r0];"
"add r1, r1, #1;" "str r1, [r0];"
"add r1, r1, #1;" "str r1, [r0];"
"add r1, r1, #1;" "str r1, [r0];"
"add r1, r1, #1;" "str r1, [r0];"
"add r1, r1, #1;" "str r1, [r0];"
"add r1, r1, #1;" "str r1, [r0];"
"add r1, r1, #1;" "str r1, [r0];"
"add r1, r1, #1;" "str r1, [r0];"
"add r1, r1, #1;" "str r1, [r0];"
"add r1, r1, #1;" "str r1, [r0];"
"add r1, r1, #1;" "str r1, [r0];"
"add r1, r1, #1;" "str r1, [r0];"
"add r1, r1, #1;" "str r1, [r0];"
"add r1, r1, #1;" "str r1, [r0];"
"add r1, r1, #1;" "str r1, [r0];"
"add r1, r1, #1;" "str r1, [r0];"
"add r1, r1, #1;" "str r1, [r0];"
"add r1, r1, #1;" "str r1, [r0];"
:
:[global] "r" (&global_value)
:
);
}
}
一共是从2一直加到32。
另一个线程直接读全局变量,并且把读出来的值进行统计
for(i=0;i<50000;i++)
count[global_value]++;
然后计算count数组统计出来的值的方差,看看分布情况的离散程度,这里我尝试了3个计算方式。
- 直接计算原始数据的方差和标准差;
-
对所有数据除以最大值,然后计算方差和标准差;
-
 ,进行离差标准化以后,计算方差和标准差。
,进行离差标准化以后,计算方差和标准差。
0x05 结果与讨论
一共是循环读取50000次。
在模拟器里,3种方式计算出来的方差和标准差如下:
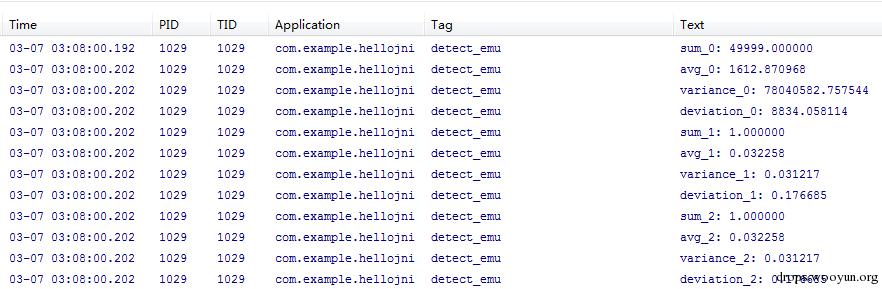
每个数字统计的次数如下:
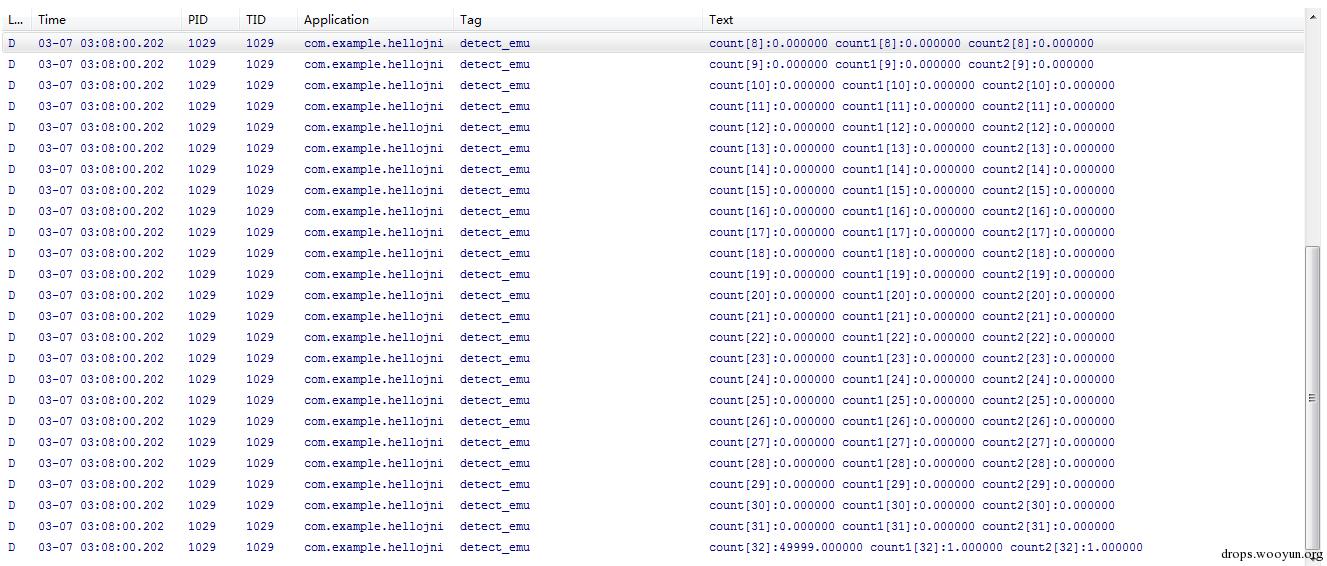
除了count[32]其他都是0。
在真机中,3种方式计算出来的方差和标准差如下:
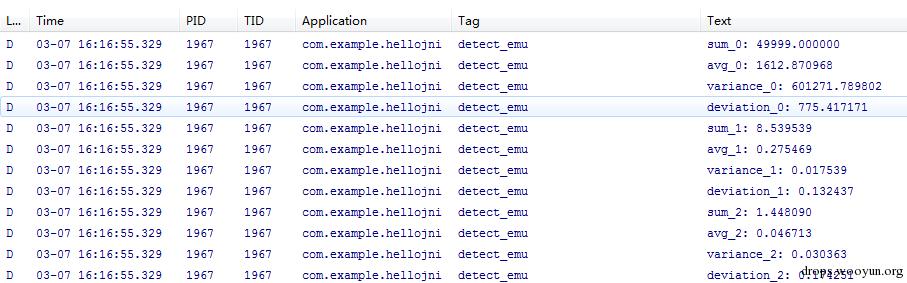
每个数字统计的次数如下:
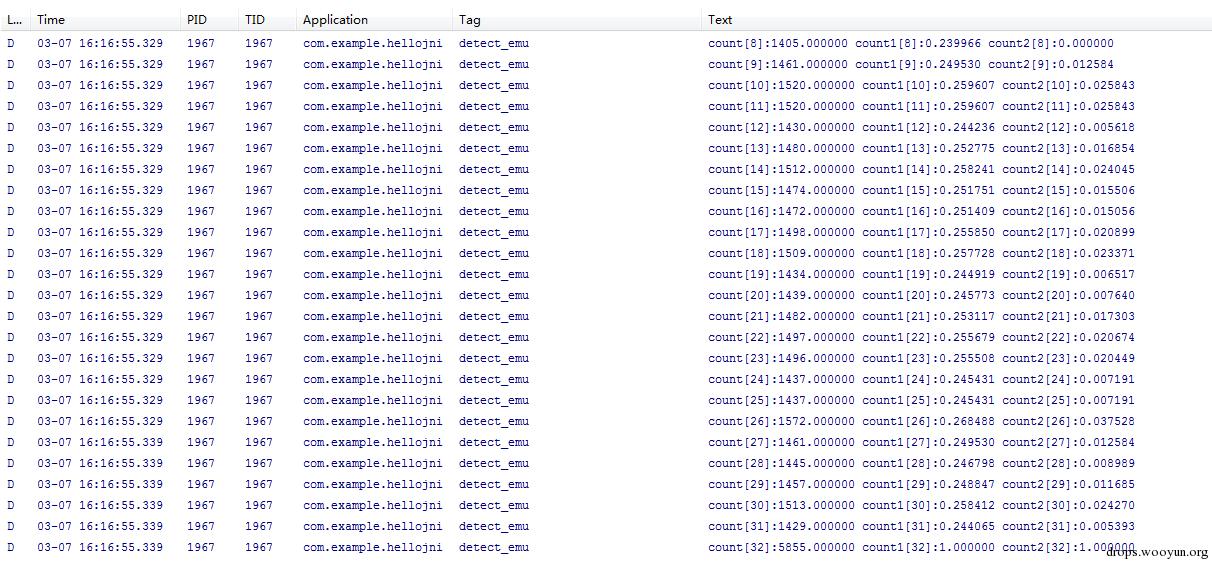
虽然count[32]比其他各个地方都多,但是中间基本都是均匀分布的。
那么实验的含义是什么呢。其实就是在一个线程加1的过程中,另一个线程在什么地方打断了它,然后从读出来的值看是在哪里打断了,也就是进行了任务调度。因此从结果来看,确实符合上面的分析,模拟器只在代码块的最后,有分支指令的时候进行了任务调度。而在真机中,实验中发现也是在这里调度最多,但在上面其他位置是基本均匀分布的。大家可以自己设计反应离散程度的指标来判断是否运行在模拟器。


