from:http://yurichev.com/writings/RE_for_beginners-en.pdf
第一章
CPU简介
CPU就是执行所有程序的工作单元。
词汇表:
Instruction:CPU的原指令,例如:将数据在数据区与寄存器之间进行转移操作,对数据进行操作,算术操作。原则上每种CPU会有自己独特的一套指令构架(Instruction Set Architecture(ISA))。
Machine code: CPU的指令码(机器码),每条指令都会被译成指令码。
Assembly Language: 汇编语言,助记码和其他一些例如宏那样的特性组成的便于程序员编写的语言。
CPU register:CPU寄存器,每个CPU都有一些通用寄存器(General Purpose Registers(GPR))。X86有8个,x86-64(amd64)有16个,ARM有16个,最简单去理解寄存器的方法就是,把寄存器想成一个不需要类型的临时变量。想象你在用高级编程语言,并且只有8个32bit的变量。只用这些可以完成非常多的事情。
那么机器码跟程序语言有什么区别那?对于人类来讲,使用例如C/C++, Java, Python这样编程语言会比较简单,但是CPU更喜欢低级抽象的东西。但愿有一天CPU也能直接来执行高级语言的语句,但那肯定会非常的复杂。相反人类使用汇编语言会感觉不很方便,因为它非常的低级。而且很难用它写非常长的代码并不出现错误。有一种将高级语言转换到汇编语言的程序,它被叫做编译器。
第二章
Hello,world!
让我们用最著名的代码例子开始吧:
#include <stdio.h>
int main() {
printf("hello, world");
return 0;
};
2.1 x86
2.1.1 MSVC-x86
在MSVC 2010中编译一下:
cl 1.cpp /Fa1.asm
(/Fa 选项表示生产汇编列表文件)
CONST SEGMENT
$SG3830 DB 'hello, world', 00H
CONST ENDS
PUBLIC _main
EXTRN _printf:PROC
; Function compile flags: /Odtp
_TEXT SEGMENT
_main PROC
push ebp
mov ebp, esp
push OFFSET $SG3830
call _printf
add esp, 4
xor eax, eax
pop ebp
ret 0
_main ENDP
_TEXT ENDS
MSVC生成的是Intel汇编语法。Intel语法与AT&T语法的区别将在后面讨论。
编译器会把1.obj文件连接成1.exe。
在我们的例子当中,文件包含两个部分:CONST(放数据)和_TEXT(放代码)。
字符串“hello,world”在 C/C++ 类型为const char*,然而他没有自己的名称。
编译器需要处理这个字符串,就自己给他定义了一个$SG3830。
所以例子可以改写为:
#include <stdio.h>
const char *$SG3830="hello, world";
int main() {
printf($SG3830);
return 0;
};
我们回到汇编列表,正如我们看到的,字符串是由0字节结束的,这也是 C/C++的标准。
在代码部分,_TEXT,只有一个函数:main()。
函数main()与大多数函数一样都有开始的代码与结束的代码。
函数当中的开始代码结束以后,调用了printf()函数:CALL _printf。
在PUSH指令的帮助下,我们问候语字符串的地址(或指向它的指针)在被调用之前存放在栈当中。
当printf()函数执行完返回到main()函数的时候,字符串地址(或指向它的指针)仍然在堆栈中。
当我们都不再需要它的时候,堆栈指针(ESP寄存器)需要改变。
ADD ESP, 4
意思是ESP寄存器加4。
为什么是4呢?由于是32位的代码,通过栈传送地址刚好需要4个字节。
在64位系统当中它是8字节。
“ADD ESP, 4” 实际上等同于“POP register”。
一些编辑器(如Intel C++编译器)在同样的情况下可能会用 POP ECX代替ADD(例如这样的模式可以在Oracle RDBMS代码中看到,因为它是由Intel C++编译器编译的),这条指令的效果基本相同,但是ECX的寄存器内容会被改写。
Intel C++编译器可能用POP ECX,因为这比ADD ESP, X需要的字节数更短,(1字节对应3字节)。
在调用printf()之后,在C/C++代码之后执行return 0,return 0是main()函数的返回结果。
代码被编译成指令XOR EAX, EAX
XOR事实上就是异或,但是编译器经常用它来代替MOV EAX, 0原因就是它需要的字节更短(2字节对应5字节)。
有些编译器用SUB EAX, EAX就是EXA的值减去EAX,也就是返回0。
最后的指令RET 返回给调用者,他是C/C++代码吧控制返还给操作系统。
2.1.2 GCC-x86
现在我们尝试同样的C/C++代码在linux中的GCC 4.4.1编译
gcc 1.c -o 1
下一步,在IDA反汇编的帮助下,我们看看main()函数是如何被创建的。
(IDA,与MSVC一样,也是显示Intel语法)。
我也可以是GCC生成Intel语法的汇编代码,添加参数
-S -masm=intel
汇编代码:
main proc near
var_10 = dword ptr -10h
push ebp
mov ebp, esp
and esp, 0FFFFFFF0h
sub esp, 10h
mov eax, offset aHelloWorld ; "hello, world"
mov [esp+10h+var_10], eax
call _printf
mov eax, 0
leave
retn
main endp
结果几乎是相同的,“hello,world”字符串地址(保存在data段的)一开始保存在EAX寄存器当中,然后保存到栈当中。
同样的在函数开始我们看到了
AND ESP, 0FFFFFFF0h
这条指令该指令对齐在16字节边界在ESP寄存器中的值。这导致堆栈对准的所有值。
SUB ESP,10H在栈上分配16个字节。 这里其实只需要4个字节。
这是因为,分配堆栈的大小也被排列在一个16字节的边界。
该字符串的地址(或这个字符串指针),不使用PUSH指令,直接写入到堆栈空间。 var_10,是一个局部变量,也是printf()的参数。
然后调用printf()函数。
不像MSVC,当gcc编译不开启优化,它使用MOV EAX,0清空EAX,而不是更短的代码。
最后一条指令,LEAVE相当于MOV ESP,EBP和POP EBP两条指令。
换句话说,这相当于指令将堆栈指针(ESP)恢复,EBP寄存器到其初始状态。
这是必须的,因为我们在函数的开头修改了这些寄存器的值(ESP和EBP)(执行MOV EBP,ESP/AND ESP...)。
2.1.3 GCC:AT&T 语法
我们来看一看在AT&T当中的汇编语法,这个语法在UNIX当中更普遍。
gcc -S 1_1.c
我们将得到这个:
.file "1_1.c"
.section .rodata
.LC0:
.string "hello, world"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushl %ebp
.cfi_def_cfa_offset 8
.cfi_offset 5, -8
movl %esp, %ebp
.cfi_def_cfa_register 5
andl $-16, %esp
subl $16, %esp
movl $.LC0, (%esp)
call printf
movl $0, %eax
leave
.cfi_restore 5
.cfi_def_cfa 4, 4
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Ubuntu/Linaro 4.7.3-1ubuntu1) 4.7.3"
.section .note.GNU-stack,"",@progbits
有很多的宏(用点开始)。现在为了简单起见,我们先不看这些。(除了 .string ,就像一个C字符串编码一个null结尾的字符序列)。然后,我们将看到这个:
.LC0:
.string "hello, world"
main:
pushl %ebp
movl %esp, %ebp
andl $-16, %esp
subl $16, %esp
movl $.LC0, (%esp)
call printf
movl $0, %eax
leave
ret
在Intel与AT&T语法当中比较重要的区别就是:
操作数写在后面
在Intel语法中:<instruction> <destination operand> <source operand>
在AT&T语法中:<instruction> <source operand> <destination operand>
有一个理解它们的方法: 当你面对intel语法的时候,你可以想象把等号放到2个操作数中间,当面对AT&T语法的时候,你可以放一个右箭头(→)到两个操作数之间。
AT&T: 在寄存器名之前需要写一个百分号(%)并且在数字前面需要美元符($)。方括号被圆括号替代。 AT&T: 一些用来表示数据形式的特殊的符号
l long(32 bits)
w word(16bits)
b byte(8 bits)
让我们回到上面的编译结果:它和在IDA里看到的是一样的。只有一点不同:0FFFFFFF0h 被写成了$-16,但这是一样的,10进制的16在16进制里表示为0x10。-0x10就等同于0xFFFFFFF0(这是针对于32位构架)。
外加返回值这里用的MOV来设定为0,而不是用XOR。MOV仅仅是加载(load)了变量到寄存器。指令的名称并不直观。在其他的构架上,这条指令会被称作例如”load”这样的。
2.2 x86-64
2.2.1 MSVC-x86-64
让我们来试试64-bit的MSVC:
$SG2989 DB ’hello, world’, 00H
main PROC
sub rsp, 40
lea rcx, OFFSET FLAT:$SG2923
call printf
xor eax, eax
add rsp, 40
ret 0
main ENDP
在x86-64里,所有被扩展到64位的寄存器都有R-前缀。并且尽量不用栈来传递函数的参数了,大量使用寄存器来传递参数,非常类似于fastcall。
在win64里,RCX,RDX,R8,R9寄存器被用来传递函数参数,如果还有更多就使用栈,在这里我们可以看到printf()函数的参数没用通过栈来传递,而是使用了rcx。 让我们针对64位来看,作为64位寄存器会有R-前缀,并且这些寄存器向下兼容,32位的部分使用E-前缀。
如下图所示,这是RAX/EAX/AX/AL在64位x86兼容cpu里的情况 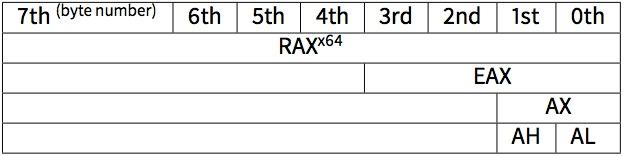
在main()函数会返回一个int类型的值,在64位的程序里为了兼容和移植性,还是用32位的,所以可以看到EAX(寄存器的低32位部分)在函数最后替代RAX被清空成0。
2.2.2 GCC-x86-64
这次试试GCC在64位的Linux里:
.string "hello, world"
main:
sub rsp, 8
mov edi, OFFSET FLAT:.LC0 ; "hello, world"
xor eax, eax ; number of vector registers passed
call printf
xor eax, eax
add rsp, 8
ret
在Linux,*BSD和Mac OS X里使用同一种方式来传递函数参数。头6个参数使用RDI,RSI,RDX,RCX,R8,R9来传递的,剩下的要靠栈。
所以在这个程序里,字串的指针被放到EDI(RDI的低32位部)。为什么不是64位寄存器RDI那?
这是一个重点,在64位模式下,对低32位进行操作的时候,会清空高32位的内容。比如 MOV EAX,011223344h将会把值写到RAX里,并且清空RAX的高32位区域。 如果我们打开编译好的对象文件(object file(.o)),我们会看到所有的指令:
Listing 2.8:GCC 4.4.6 x64
.text:00000000004004D0 main proc near
.text:00000000004004D0 48 83 EC 08 sub rsp, 8
.text:00000000004004D4 BF E8 05 40 00 mov edi, offset format ; "hello, world"
.text:00000000004004D9 31 C0 xor eax, eax
.text:00000000004004DB E8 D8 FE FF FF call _printf
.text:00000000004004E0 31 C0 xor eax, eax
.text:00000000004004E2 48 83 C4 08 add rsp, 8
.text:00000000004004E6 C3 retn
.text:00000000004004E6 main endp
就像看到的那样,在04004d4那行给edi写字串指针的那句花了5个bytes。如果把这句换做给rdi写指针,会花掉7个bytes.就是说GCC在试图节省空间,为此数据段(data segment)中包含的字串不会被分配到高于4GB地址的空间上。
可以看到在printf()函数调用前eax被清空了,这样做事因为要eax被用作传递向量寄存器(vector registers)的个数。
参考【21】 MichaelMatz/JanHubicka/AndreasJaeger/MarkMitchell. Systemvapplicationbinaryinterface.amdarchitecture processor supplement, . Also available as http://x86-64.org/documentation/abi.pdf.
2.3 ARM
根据作者自身对ARM处理器的经验,选择了2款在嵌入式开发流行的编译器,Keil Release 6/2013和苹果的Xcode 4.6.3 IDE(其中使用了LLVM-GCC4.2编译器),这些可以为ARM兼容处理器和系统芯片(System on Chip)(SOC))来进行编码。比如ipod/iphone/ipad,windows8 rt,并且包括raspberry pi。
2.3.1 未进行代码优化的Keil编译:ARM模式
让我们在Keil里编译我们的例子
armcc.exe –arm –c90 –O0 1.c
armcc编译器可以生成intel语法的汇编程序列表,但是里面有高级的ARM处理器相关的宏,对我们来讲更希望看到的是IDA反汇编之后的结果。
Listing 2.9: Non-optimizing Keil + ARM mode + IDA
#!bash
.text:00000000 main
.text:00000000 10 40 2D E9 STMFD SP!, {R4,LR}
.text:00000004 1E 0E 8F E2 ADR R0, aHelloWorld ; "hello, world"
.text:00000008 15 19 00 EB BL __2printf
.text:0000000C 00 00 A0 E3 MOV R0, #0
.text:00000010 10 80 BD E8 LDMFD SP!, {R4,PC}
.text:000001EC 68 65 6C 6C+aHelloWorld DCB "hello, world",0 ; DATA XREF: main+4
针对ARM处理器,我们需要预备一点知识,要知道ARM处理器至少有2种模式:ARM模式和thumb模式,在ARM模式下,所有的指令都被激活并且都是32位的。在thumb模式下所有的指令都是16位的。Thumb模式比较需要注意,因为程序可能需要更为紧凑,或者当微处理器用的是16位内存地址时会执行的更快。但也存在缺陷,在thumb模式下可用的指令没ARM下多,只有8个寄存器可以访问,有时候ARM模式下一条指令就能解决的问题,thumb模式下需要多个指令来完成。
从ARMv7开始引入了thumb-2指令集。这是一个加强的thumb模式。拥有了更多的指令,通常会有误解,感觉thumb-2是ARM和thumb的混合。Thumb-2加强了处理器的特性,并且媲美ARM模式。程序可能会混合使用2种模式。其中大量的ipod/iphone/ipad程序会使用thumb-2是因为Xcode将其作为了默认模式。
在例子中,我们可以发现所有指令都是4bytes的,因为我们编译的时候选择了ARM模式,而不是thumb模式。
最开始的指令是”STMFD SP!, {R4, LR}”,这条指令类似x86平台的PUSH指令,会写2个寄存器(R4和LR)的变量到栈里。不过在armcc编译器里输出的汇编列表里会写成”PUSH {R4, LR}”,但这并不准确,因为PUSH命令只在thumb模式下有,所以我建议大家注意用IDA来做反汇编工具。
这指令开始会减少SP的值,已加大栈空间,并且将R4和LR写入分配好的栈里。
这条指令(类似于PUSH的STMFD)允许一次压入好几个值,非常实用。有一点跟x86上的PUSH不同的地方也很赞,就是这条指令不像x86的PUSH只能对sp操作,而是可以指定操作任意的寄存器。
“ADR R0, aHelloWorld”这条指令将PC寄存器的值与”hello, world”字串的地址偏移相加放入R0,为什么说要PC参与这个操作那?这是因为代码是PIC(position-independet code)的,这段代码可以独立在内存运行,而不需要更改内存地址。ADR这条指令中,指令中字串地址和字串被放置的位置是不同的。但变化是相对的,这要看系统是如何安排字串放置的位置了。这也就说明了,为何每次获取内存中字串的绝对地址,都要把这个指令里的地址加上PC寄存器里的值了。
”BL __2print”这条指令用于调用printf()函数,这是来说下这条指令时如何工作的:
将BL指令(0xC)后面的地址写入LR寄存器;
然后把printf()函数的入口地址写入PC寄存器,进入printf()函数。
当printf()函数完成之后,函数会通过LR寄存器保存的地址,来进行返回操作。
函数返回地址的存放位置也正是“纯”RISC处理器(例如:ARM)和CISC处理器(例如x86)的区别。
另外,一个32位地址或者偏移不能被编码到BL指令里,因为BL指令只有24bits来存放地址,所有的ARM模式下的指令都是4bytes(32bits),所以一条指令里不能放满4bytes的地址,这也就意味着最后2bits总会被设置成0,总的来说也就是有26bits的偏移(包括了最后2个bit一直被设为0)会被编码进去。这也够去访问大约±32M的了。
下面我们来看“MOV R0, #0“这条语句,这条语句就是把0写到了R0寄存器里,这是因为C函数返回了0,返回值当然是放在R0里的。
最后一条指令是”LDMFD SP!, R4,PC“,这条指令的作用跟开始的那条STMFD正好相反,这条指令将栈上的值保存到R4和PC寄存器里,并且增加SP栈寄存器的值。这非常类似x86平台里的POP指令。最前面那条STMFD指令成对保存了R4,和LR寄存器,LDMFD的时候将当时这两个值保存到了R4和PC里完成了函数的返回。
我前面也说过,函数的返回地址会保存到LD寄存器里。在函数的最开始会把他保存到栈里,这是因为main()函数里还需要调用printf()函数,这个时候就会影响LD寄存器。在函数的最后就会将LD拿出栈放入PC寄存器里,完成函数的返回操作。最后C/C++程序的main()函数会返回到类似系统加载器上或者CRT里面。
汇编代码里的DCB关键字用来定义ASCII字串数组,就像x86汇编里的DB关键字。
2.3.2未进行代码优化的Keil编译: thumb模式
让我们用下面的指令讲例程用Keil的thumb模式来编译一下。
armcc.exe –thumb –c90 –O0 1.c
我们可以在IDA里得到下面这样的代码: Listing 2.10:Non-optimizing Keil + thumb mode + IDA
.text:00000000 main
.text:00000000 10 B5 PUSH {R4,LR}
.text:00000002 C0 A0 ADR R0, aHelloWorld ; "hello, world"
.text:00000004 06 F0 2E F9 BL __2printf
.text:00000008 00 20 MOVS R0, #0
.text:0000000A 10 BD POP {R4,PC}
.text:00000304 68 65 6C 6C+aHelloWorld DCB "hello, world",0 ; DATA XREF: main+2
我们首先就能注意到指令都是2bytes(16bits)的了,这正是thumb模式的特征,BL指令作为特例是2个16bits来构成的。只用16bits没可能加载printf()函数的入口地址到PC寄存器。所以前面的16bits用来加载函数偏移的高10bits位,后面的16bits用来加载函数偏移的低11bits位,正如我说过的,所有的thumb模式下的指令都是2bytes(16bits)。但是这样的话thumb指令就没法使用更大的地址。就像上面那样,最后一个bits的地址将会在编码指令的时候省略。总的来讲,BL在thumb模式下可以访问自身地址大于±2M大的周边的地址。
至于其他指令:PUSH和POP,它们跟上面讲到的STMFD跟LDMFD很类似,但这里不需要指定SP寄存器,ADR指令也跟上面的工作方式相同。MOVS指令将函数的返回值0写到了R0里,最后函数返回。
2.3.3开启代码优化的Xcode(LLVM)编译: ARM模式
Xcode 4.6.3不开启代码优化的情况下,会产生非常多冗余的代码,所以我们学习一个尽量小的版本。
开启-O3编译选项
Listing2.11:Optimizing Xcode(LLVM)+ARM mode
__text:000028C4 _hello_world
__text:000028C4 80 40 2D E9 STMFD SP!, {R7,LR}
__text:000028C8 86 06 01 E3 MOV R0, #0x1686
__text:000028CC 0D 70 A0 E1 MOV R7, SP
__text:000028D0 00 00 40 E3 MOVT R0, #0
__text:000028D4 00 00 8F E0 ADD R0, PC, R0
__text:000028D8 C3 05 00 EB BL _puts
__text:000028DC 00 00 A0 E3 MOV R0, #0
__text:000028E0 80 80 BD E8 LDMFD SP!, {R7,PC}
__cstring:00003F62 48 65 6C 6C+aHelloWorld_0 DCB "Hello world!",0
STMFD和LDMFD对我们来说已经非常熟悉了。
MOV指令就是将0x1686写入R0寄存器里。这个值也正是字串”Hello world!”的指针偏移。
R7寄存器里放入了栈地址,我们继续。
MOVT R0, #0指令时将R0的高16bits写入0。这是因为普通情况下MOV这条指令在ARM模式下,只对低16bits进行操作。需要记住的是所有在ARM模式下的指令都被限定在32bits内。当然这个限制并不影响2个寄存器直接的操作。这也是MOVT这种写高16bits指令存在的意义。其实这样写的代码会感觉有点多余,因为”MOVS R0,#0x1686”这条指令也能把高16位清0。或许这就是相对于人脑来说编译器的不足。
“ADD R0,PC,R0“指令把R0寄存器的值与PC寄存器的值进行相加并且保存到R0寄存器里面,用来计算”Hello world!”这个字串的绝对地址。上面已经介绍过了,这是因为代码是PIC(Position-independent code)的,所以这里需要这么做。
BL指令用来调用printf()的替代函数puts()函数。
GCC将printf()函数替换成了puts()。因为printf()函数只有一个参数的时候跟puts()函数是类似的。
printf()函数的字串参数里存在特殊控制符(例如 ”%s”,”\n” ,需要注意的是,程序里字串里没有“\n”,因为在puts()函数里这是不需要的)的时候,两个函数的功效就会不同。
为什么编译器会替换printf()到puts()那?因为puts()函数更快。
puts()函数效率更快是因为它只是做了字串的标准输出(stdout)并不用比较%符号。
下面,我们可以看到非常熟悉的”MOV R0, #0”指令,用来将R0寄存器设为0。
2.3.4 开启代码优化的Xcode(LLVM)编译thumb-2模式
在默认情况下,Xcode4.6.3会生成如下的thumb-2代码
Listing 2.12:Optimizing Xcode(LLVM)+thumb-2 mode
__text:00002B6C _hello_world
__text:00002B6C 80 B5 PUSH {R7,LR}
__text:00002B6E 41 F2 D8 30 MOVW R0, #0x13D8
__text:00002B72 6F 46 MOV R7, SP
__text:00002B74 C0 F2 00 00 MOVT.W R0, #0
__text:00002B78 78 44 ADD R0, PC
__text:00002B7A 01 F0 38 EA BLX _puts
__text:00002B7E 00 20 MOVS R0, #0
__text:00002B80 80 BD POP {R7,PC}
...
__cstring:00003E70 48 65 6C 6C 6F 20+aHelloWorld DCB "Hello world!",0xA,0
BL和BLX指令在thumb模式下情况需要我们回忆下刚才讲过的,它是由一对16-bit的指令来构成的。在thumb-2模式下这条指令跟thumb一样被编码成了32-bit指令。非常容易观察到的是,thumb-2的指令的机器码也是从0xFx或者0xEx的。对于thumb和thumb-2模式来说,在IDA的结果里机器码的位置和这里是交替交换的。对于ARM模式来说4个byte也是反向的,这是因为他们用了不同的字节序。所以我们可以知道,MOVW,MOVT.W和BLX这几个指令的开始都是0xFx。
在thumb-2指令里有一条是”MOVW R0, #0x13D8”,它的作用是写数据到R0的低16位里面。
“MOVT.W R0, #0”的作用类似与前面讲到的MOVT指令,但它可以工作在thumb-2模式下。
还有些跟上面不同的地方,比如BLX指令替代了上面用到的BL指令,这条指令不仅将控制puts()函数返回的地址放入了LR寄存器里,并且讲代码从thumb模式转换到了ARM模式(或者ARM转换到thumb(根据现有情况判断))。这条指令跳转到下面这样的位置(下面的代码是ARM编码模式)。
__symbolstub1:00003FEC _puts ; CODE XREF: _hello_world+E
__symbolstub1:00003FEC 44 F0 9F E5 LDR PC, =__imp__puts
可能会有细心的读者要问了:为什么不直接跳转到puts()函数里面去?
因为那样做会浪费内存空间。
很多程序都会使用额外的动态库(dynamic libraries)(Windows里面的DLL,还有*NIX里面的.so,MAC OS X里面的.dylib),通常使用的库函数会被放入动态库中,当然也包括标准C函数puts()。
在可执行的二进制文件里(Windows的PE里的.exe文件,ELF和Mach-O文件)都会有输入表段。它是一个用来引入额外模块里模块名称和符号(函数或者全局变量)的列表。
系统加载器(OS loader)会加载所有需要的模块,当在主模块里枚举输入符号的时候,会把每个符号正确的地址与相应的符号确立起来。
在我们的这个例子里,__imp__puts就是一个系统加载器加载额外模块的32位的地址值。LDR指令只需要把这个值加载到PC里面去,就可以控制程序流程到puts()函数里去。
所以只需要在系统加载器里的时候,一次性的就能将每个符号所对应的地址确定下来,这是个提高效率的好方式。
外加,我们前面也指出过,我们没办法只用一条指令并且不做内存操作的情况下就将一个32bit的值保存到寄存器里,ARM并不是唯一的模式的情况下,程序里去跳入动态库中的某个函数里,最好的办法就是这样做一些类似与上面这样单一指令的函数(称做thunk function),然后从thumb模式里也能去调用。
在上面的例子(ARM编译的那个例子)中BL指令也是跳转到了同一个thunk function里。尽管没有进行模式的转变(所以指令里不存在那个”X”)。
第三章 函数开始和结束
函数开始的指令,是像下面这样的代码片段:
push ebp
mov ebp, esp
sub esp, X
这些指令做了什么:将寄存器EBP的值入栈,将ESP赋值给EBP,在栈中分配空间, 用来保存局部变量。
在函数执行过程中,EBP是固定的,可以用来访问局部变量和函数参数。也可以使用 ESP,但在函数运行过程中,ESP会变化,使用起来不方便。
mov esp, ebp
pop ebp
ret 0
函数在运行结束时,会释放在栈中所申请的内存,EBP的值出栈,将代码控制权还原 给调用者。
3.1 递归
函数调用开始和结束使递归变得难以理解。
举个例子,有一次我写了一个函数遍历二叉树右侧节点。使用了看起来很高⼤上的递归函数,但由于每次函数调用开始和结束都需要花费很长时间,它运行速度比迭代方 式要慢好多倍。
顺便提一下,这就是尾部调用存在的原因。
第四章 栈
栈在计算科学中是最重要和最基本的数据结构。
严格的来说,它只是在x86中被ESP,或x64中被RSP,或ARM中被SP所指向的一段程序内存区域。  访问栈内存,最常使用的指令是PUSH和POP(在x86和ARM Thumb模式中)。
PUSH指令在32位模式下,会将ESP/RSP/SP的值减去4(在64位系统中,会减去8),然后将操作数写入到ESP/RSP/SP指向的内存地址。
POP是相反的操作运算:从SP指向的内存地址中获取数据,存入操作数(一般为寄存器), 然后将SP(栈指针)加4(或8)。
4.1 为什么栈反向增长?
按正常思维来说,我们会认为像其它数据结构一样,栈是正向增长的,比如:栈指针会指向高地址。

我们知道:
????? ⽤户核心部分的映像文件被合理的分为三个部分,程度代码段在内存空闲部分运行。 在运行过程中,这部分是具有写保护的,所有进程都可以共享访问这个程序。在内存空间 中,程序text区段开始的8k字节是不能共享的可写区段,这个⼤大⼩小可以使⽤用系统函数来扩 ⼤大。在内存⾼高位地址是可以像硬件指针⾃自由活动向下增长的栈区段。 ?????
4.2 栈可以用来做什么?
4.2.1 保存函数返回地址以便在函数执行完成时返回控制权
x86
当使用CALL指令去调用一个函数时,CALL后面一条指令的地址会被保存到栈中,使用无条件跳转指令跳转到CALL中执行。  CALL指令等价于PUSH函数返回地址和JMP跳转。
void f()
{
f();
};
MSVC 2008显示的问题:
c:\tmp6>cl ss.cpp /Fass.asm
Microsoft (R) 32-bit C/C++ Optimizing Compiler Version 15.00.21022.08 for 80x86
Copyright (C) Microsoft Corporation. All rights reserved.
ss.cpp
c:\tmp6\ss.cpp(4) : warning C4717: ’f’ : recursive on all control paths, function will cause
runtime stack overflow
但无论如何还是生成了正确的代码:
?f@@YAXXZ PROC ; f
; File c:\tmp6\ss.cpp
; Line 2
push ebp
mov ebp, esp
; Line 3
call ?f@@YAXXZ ; f
; Line 4
pop ebp
ret 0
?f@@YAXXZ ENDP ; f
如果我们设置优化(/0x)标识,生成的代码将不会出现栈溢出,并且会运行的很好。
?f@@YAXXZ PROC ; f
; File c:\tmp6\ss.cpp
; Line 2
$LL3@f:
; Line 3
jmp SHORT $LL3@f
?f@@YAXXZ ENDP ; f
GCC 4.4.1 在这两种条件下,会生成同样的代码,而且不会有任何警告。
ARM
ARM程序员经常使用栈来保存返回地址,但有些不同。像是提到的“Hello,World!(2.3), RA保存在LR(链接寄存器)。然而,如果需要调用另外一个函数,需要多次使用LR寄存器,它的值会被保存起来。通常会在函数开始的时候保存。像我们经常看到的指令“PUSH R4-R7, LR”,在函数结尾处的指令“POP R4-R7, PC”,在函数中使⽤用到的寄存器会被保存到栈中,包括LR。
尽管如此,如果一个函数从未调用其它函数,在ARM专用术语中被叫称作叶子函数。因此,叶⼦函数不需要LR寄存器。如果一个函数很小并使用了少量的寄存器,可能不会⽤到栈。因此,是可以不使用栈而实现调用叶子函数的。在扩展ARM上不使用栈,这样就会比在x86上运行要快。在未分配栈内存或栈内存不可用的情况下,这种方式是非常有用的。
4.2.2 传递函数参数
在x86中,最常见的传参方式是“cdecl”:
push arg3
push arg2
push arg1
call f
add esp, 4*3
被调用函数通过栈指针访问函数参数。因此,这就是为什么要在函数f()执行之前将数据放入栈中的原因。

来看一下其它调用约定。没有意义也没有必要强迫程序员一定要使用栈来传递参数。
这不是必需的,可以不使用栈,通过其它方式来实现。
例如,可以为参数分配一部分堆空间,存入参数,将指向这部分内存的指针存入EAX,这样就可以了。然而,在x86和ARM中,使用栈传递参数还是更加方便的。
另外一个问题,被调用的函数并不知道有多少参数被传递进来。有些函数可以传递不同个数的参数(如:printf()),通过一些说明性的字符(以%开始)才可以判断。如果我们这样调用函数
printf("%d %d %d", 1234);
printf()会传⼊入1234,然后另外传入栈中的两个随机数字。这就让我们使用哪种方式调用 main()函数变得不重要,像main(),main(int argc, char *argv[])或main(int argc, char *argv[], char *envp[])。
事实上,CRT函数在调⽤main()函数时,使用了下面的指令:  #!bash push envp push argv push argc call main ...
如果你使用了没有参数的main()函数,尽管如此,但它们仍然在栈中,只是无法使用。如果你使用了main(int argc, char *argv[]),你可以使用两个参数,第三个参数对你的函数是“不可见的”。如果你使用main(int argc)这种方式,同样是可以正常运⾏的。
4.2.3 局部变量存放
局部变量存放到任何你想存放的地方,但传统上来说,大家更喜欢通过将栈指针移动到栈底,来存放局部变量,当然,这不是必需的。
4.2.4 x86: alloca() 函数
对alloca()函数并没有值得学习的。
该函数的作用像malloc()一样,但只会在栈上分配内存。
它分配的内存并不需要在函数结束时,调用像free()这样的函数来释放,当函数运行结束,ESP的值还原时,这部分内存会自动释放。对alloca()函数的实现也没有什么值得介绍的。
这个函数,如果精简一下,就是将ESP指针指向栈底,根据你所需要的内存大小将ESP指向所分配的内存块。让我们试一下:
#include <malloc.h>
#include <stdio.h>
void f() {
char *buf=(char*)alloca (600);
_snprintf (buf, 600, "hi! %d, %d, %d\n", 1, 2, 3);
puts (buf);
};
(_snprintf()函数作用与printf()函数基本相同,不同的地方是printf()会将结果输出到的标准输出stdout,⽽_snprintf()会将结果保存到内存中,后面两⾏代码可以使用printf()替换,但我想说明小内存的使用习惯。)
MSVC
让我们来编译 (MSVC 2010):
...
 mov eax, 600 ; 00000258H
call __alloca_probe_16
mov esi, esp
 push 3
push 2
push 1
push OFFSET $SG2672
push 600 ; 00000258H
push esi
call __snprintf
 push esi
call _puts
add esp, 28 ; 0000001cH
...
 这唯一的函数参数是通过EAX(未使用栈)传递。在函数调用结束时,ESP会指向 600字节的内存,我们可以像使用一般内存一样来使用它做为缓冲区。
GCC + Intel格式
GCC 4.4.1不需要调用函数就可以实现相同的功能:
.LC0:
.string "hi! %d, %d, %d\n"
f:
push ebp
mov ebp, esp
push ebx
sub esp, 660
lea ebx, [esp+39]
and ebx, -16 ; align pointer by 16-bit border
mov DWORD PTR [esp], ebx ; s
mov DWORD PTR [esp+20], 3
mov DWORD PTR [esp+16], 2
mov DWORD PTR [esp+12], 1
mov DWORD PTR [esp+8], OFFSET FLAT:.LC0 ; "hi! %d, %d, %d\n"
mov DWORD PTR [esp+4], 600 ; maxlen
call _snprintf
mov DWORD PTR [esp], ebx
call puts
mov ebx, DWORD PTR [ebp-4]
leave
ret
####GCC + AT&T 格式
我们来看相同的代码,但使用了AT&T格式:
.LC0:
.string "hi! %d, %d, %d\n"
f:
pushl %ebp
movl %esp, %ebp
pushl %ebx
subl $660, %esp
leal 39(%esp), %ebx
andl $-16, %ebx
movl %ebx, (%esp)
movl $3, 20(%esp)
movl $2, 16(%esp)
movl $1, 12(%esp)
movl $.LC0, 8(%esp)
movl $600, 4(%esp)
call _snprintf
movl %ebx, (%esp)
call puts
movl -4(%ebp), %ebx
leave
ret
代码与上面的那个图是相同的。
例如:movl $3, 20(%esp)与mov DWORD PTR [esp + 20],3是等价的,Intel的内存地址增加是使用register+offset,而AT&T使用的是offset(%register)。
4.2.5 (Windows) 结构化异常处理
SEH也是存放在栈中的(如果存在的话)。 想了解更多,请等待后续翻译在(51.3)。
4.2.6 缓冲区溢出保护
想了解更多,请等待后续翻译,在(16.2)。
4.3 典型的内存布局
在32位系统中,函数开始时,栈的布局:







